Выбор алгоритма машинного обучения — Azure Machine Learning
- Чтение занимает 6 мин
В этой статье
Распространенный вопрос: «какой алгоритм машинного обучения следует использовать?».A common question is “Which machine learning algorithm should I use?” Выбранный алгоритм зависит главным образом от двух различных аспектов сценария обработки и анализа данных:The algorithm you select depends primarily on two different aspects of your data science scenario:
Что вы хотите сделать с данными?What you want to do with your data? В частности, каков бизнес-вопрос, который вы хотите ответить, обучение из прошлых данных?Specifically, what is the business question you want to answer by learning from your past data?
Каковы требования к сценарию обработки и анализа данных?What are the requirements of your data science scenario? В частности, Какова точность, время обучения, линейность, количество параметров и число функций, поддерживаемых решением?Specifically, what is the accuracy, training time, linearity, number of parameters, and number of features your solution supports?
Бизнес-сценарии и лист Машинное обучение Algorithm Памятка поBusiness scenarios and the Machine Learning Algorithm Cheat Sheet
С помощью памятка по машинное обучение Azureного алгоритма вы будете в первую очередь: что нужно сделать с данными
 On the Machine Learning Algorithm Cheat Sheet, look for task you want to do, and then find a Azure Machine Learning designer algorithm for the predictive analytics solution.
On the Machine Learning Algorithm Cheat Sheet, look for task you want to do, and then find a Azure Machine Learning designer algorithm for the predictive analytics solution.Машинное обучение Designer предоставляет комплексный портфель алгоритмов, таких как лес решений в многоклассовых решениях, системы рекомендаций, регрессия нейронных сетей, Многоклассовая нейронная сетьи кластеризация на основе K-средних.Machine Learning designer provides a comprehensive portfolio of algorithms, such as Multiclass Decision Forest, Recommendation systems, Neural Network Regression, Multiclass Neural Network, and K-Means Clustering. Каждый алгоритм предназначен для решения различных типов проблем машинного обучения.Each algorithm is designed to address a different type of machine learning problem. Полный список, а также описание работы каждого алгоритма и настройки параметров для оптимизации алгоритма см. в справочнике по алгоритму конструктора машинное обучение и модулю .See the Machine Learning designer algorithm and module reference for a complete list along with documentation about how each algorithm works and how to tune parameters to optimize the algorithm.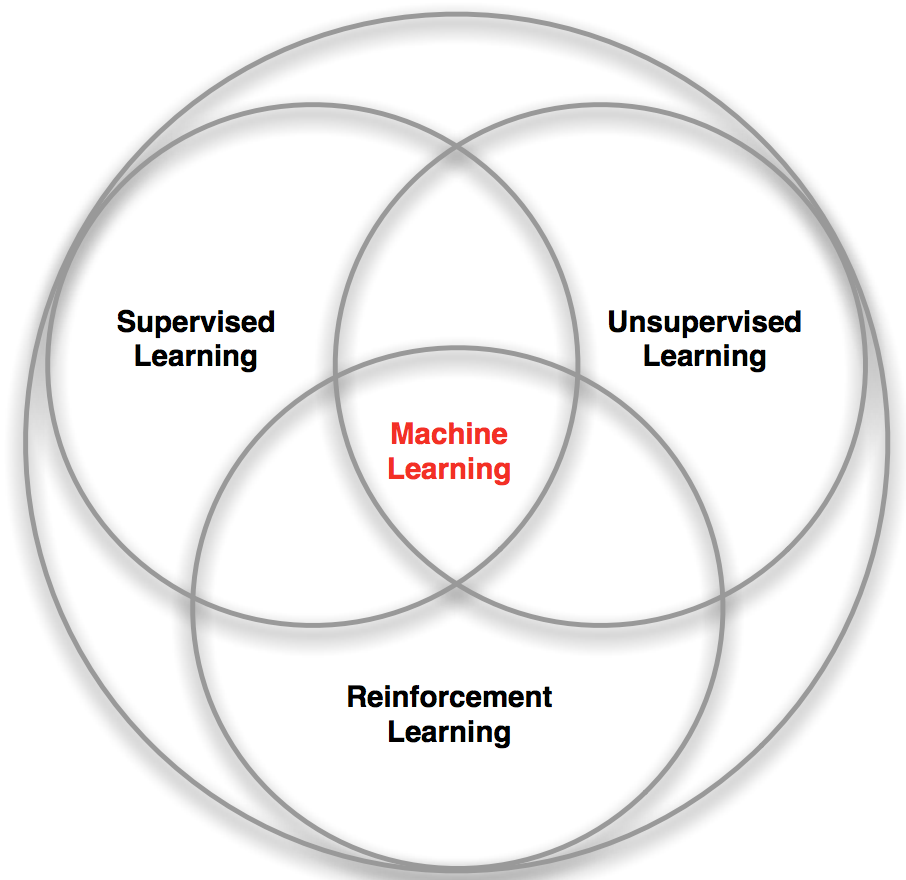
Примечание
Чтобы скачать таблицу алгоритма машинного обучения Памятка по, перейдите на
Четыре проекта, где Machine Learning приносит пользу
Машинное обучение — одно из направлений в разработке искусственного интеллекта. Про него много говорят, и уже есть первые заметные результаты его работы. Мы собрали проекты, где машинное обучение приносит пользу.
Почти все эти проекты используют Python — оказывается, этот язык идеально подходит для машинного обучения. Про Python у нас есть отдельная статья, и там не только про искусственный интеллект.
Здравоохранение, IBM и Watson
Чтобы сделать мир здоровее, IBM сделал Ватсона. Это нейросеть, которая следит за медицинскими показателями пациентов и на их основе делает выводы об их здоровье. Программа уже работает в нескольких госпиталях и медцентрах, где Ватсон смог распознать рак намного раньше врачей.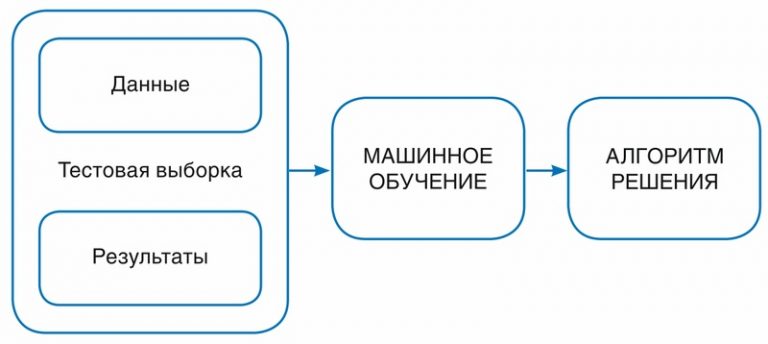
Одна из главных проблем в современной медицине — большое количество разрозненных данных о пациенте. Ватсон как раз и занимается тем, что ищет закономерности в данных, которые не видит человек.
Преобразование текста в голос и распознавание речи
В основе технологий распознавания и преобразования речи лежит машинное обучение: система составляет речь из отдельных звуков, которые есть у неё в базе. Чем больше база и примеров произношения — тем точнее преобразование и тем естественнее звучит компьютерная речь.
Так как алгоритмы работают по одному принципу, но в разных направлениях, их часто используют вместе. У Яндекса и у Гугла есть свои голосовые движки, но Яндекс точнее работает с русским языком, а Гугл говорит с заметным акцентом.
С помощью этой технологии можно делать, например, роботизированные автоответчики и автоинформаторы. Можно распознавать данные клиента и сразу заносить их в письменном виде в базу данных. Можно сразу получать протоколы планерок и переговоров. Можно готовить конспекты лекций, записав лектора на диктофон.
Обратный вариант — озвучивание сайтов и книг для слепых и слабовидящих и создание голосового интерфейса. Главное в них — распознавать команды на слух и отвечать тоже голосом, а это как раз и умеют голосовые движки.
Распознавание лиц
Как говорят специалисты, Face Recognition — самый простой в мире API для распознавания лиц для Python. Точность распознавания — 99,38% в тесте Labeled Faces in the Wild. Тест моделирует реальное использование технологии, смотрит, как она распознаёт людей на фото и даже с экранов телефонов.
Нейросеть работает в режиме реального времени и на лету разпознаёт несколько лиц, одновременно попавших в кадр. Если сюда подключить соцсети, то система сможет распознать каждого, кто входит в магазин. Или может вывести на экран историю прошлых покупок человека и дать рекомендации по продажам.
Восстановление испорченных изображений
Deep-image-prior — программа для восстановление изображений с помощью нейронных сетей, автор — Дмитрий Ульянов из Сколково. Звучит скучно, но вот, что она умеет:
Звучит скучно, но вот, что она умеет:
- убирает артефакты от чрезмерного сжатия картинки
- повышает чёткость
- восстанавливает фото до целого, достраивая недостающие фрагменты
- убирает пыль и помехи с картинок
- полностью убирает текст с изображения
Машинное обучение для людей
Машинное обучение — как секс в старших классах. Все говорят о нем по углам, единицы понимают, а занимается только препод. Статьи о машинном обучении делятся на два типа: это либо трёхтомники с формулами и теоремами, которые я ни разу не смог дочитать даже до середины, либо сказки об искусственном интеллекте, профессиях будущего и волшебных дата-саентистах.
Материал опубликован на портале vas3k.ru.
Решил сам написать пост, которого мне не хватало. Большое введение для тех, кто хочет наконец разобраться в машинном обучении — простым языком, без формул-теорем, зато с примерами реальных задач и их решений.
Погнали.
Зачем обучать машины
Снова разберём на Олегах.
Предположим, Олег хочет купить автомобиль и считает сколько денег ему нужно для этого накопить. Он пересмотрел десяток объявлений в интернете и увидел, что новые автомобили стоят около $20 000, годовалые — примерно $19 000, двухлетние — $18 000 и так далее.
В уме Олег-аналитик выводит формулу: адекватная цена автомобиля начинается от $20 000 и падает на $1000 каждый год, пока не упрётся в $10 000.
Олег сделал то, что в машинном обучении называют регрессией — предсказал цену по известным данным. Люди делают это постоянно, когда считают почём продать старый айфон или сколько шашлыка взять на дачу (моя формула — полкило на человека в сутки).
Да, было бы удобно иметь формулу под каждую проблему на свете. Но взять те же цены на автомобили: кроме пробега есть десятки комплектаций, разное техническое состояние, сезонность спроса и еще столько неочевидных факторов, которые Олег, даже при всём желании, не учел бы в голове.
Люди тупы и ленивы — надо заставить вкалывать роботов. Пусть машина посмотрит на наши данные, найдёт в них закономерности и научится предсказывать для нас ответ. Самое интересное, что в итоге она стала находить даже такие закономерности, о которых люди не догадывались.
Так родилось машинное обучение.
Три составляющие обучения
Цель машинного обучения — предсказать результат по входным данным. Чем разнообразнее входные данные, тем проще машине найти закономерности и тем точнее результат.
Итак, если мы хотим обучить машину, нам нужны три вещи:
Данные. Хотим определять спам — нужны примеры спам-писем, предсказывать курс акций — нужна история цен, узнать интересы пользователя — нужны его лайки или посты. Данных нужно как можно больше. Десятки тысяч примеров — это самый злой минимум для отчаянных.
Данных нужно как можно больше. Десятки тысяч примеров — это самый злой минимум для отчаянных.
Данные собирают как могут. Кто-то вручную — получается дольше, меньше, зато без ошибок. Кто-то автоматически — просто сливает машине всё, что нашлось, и верит в лучшее. Самые хитрые, типа гугла, используют своих же пользователей для бесплатной разметки. Вспомните ReCaptcha, которая иногда требует «найти на фотографии все дорожные знаки» — это оно и есть.
За хорошими наборами данных (датасетами) идёт большая охота. Крупные компании, бывает, раскрывают свои алгоритмы, но датасеты — крайне редко.
Признаки. Мы называем их фичами (features), так что ненавистникам англицизмов придётся страдать. Фичи, свойства, характеристики, признаки — ими могут быть пробег автомобиля, пол пользователя, цена акций, даже счетчик частоты появления слова в тексте может быть фичей.
Машина должна знать, на что ей конкретно смотреть. Хорошо, когда данные просто лежат в табличках — названия их колонок и есть фичи.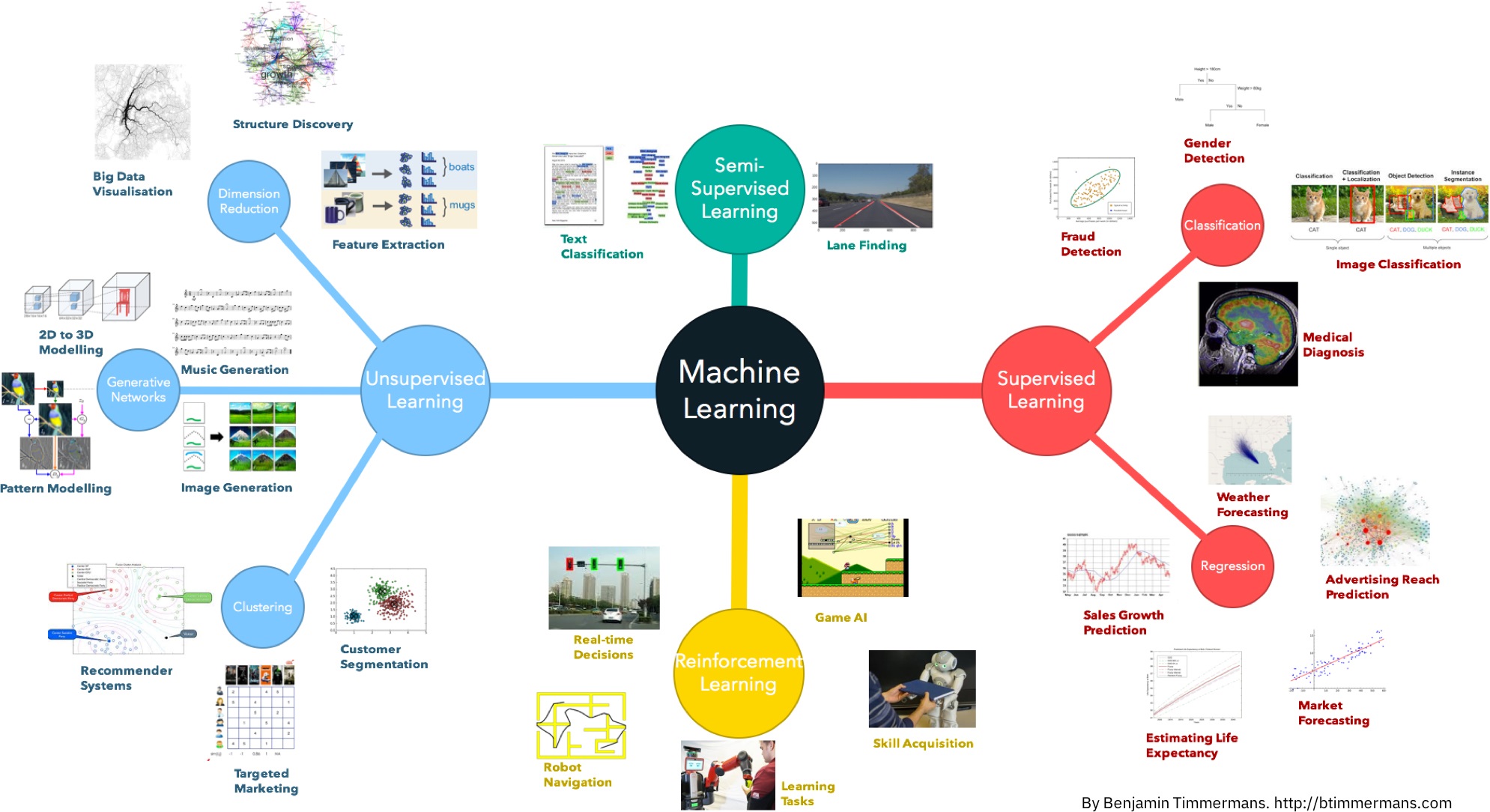 А если у нас сто гигабайт картинок с котами? Когда признаков много, модель работает медленно и неэффективно. Зачастую отбор правильных фич занимает больше времени, чем всё остальное обучение. Но бывают и обратные ситуации, когда кожаный мешок сам решает отобрать только «правильные» на его взгляд признаки и вносит в модель субъективность — она начинает дико врать.
А если у нас сто гигабайт картинок с котами? Когда признаков много, модель работает медленно и неэффективно. Зачастую отбор правильных фич занимает больше времени, чем всё остальное обучение. Но бывают и обратные ситуации, когда кожаный мешок сам решает отобрать только «правильные» на его взгляд признаки и вносит в модель субъективность — она начинает дико врать.
Алгоритм. Одну задачу можно решить разными методами примерно всегда. От выбора метода зависит точность, скорость работы и размер готовой модели. Но есть один нюанс: если данные плохие, даже самый лучший алгоритм не поможет. Не зацикливайтесь на процентах, лучше соберите побольше данных.
Обучение vs Интеллект
Однажды в одном хипстерском издании я видел статью под заголовком «Заменят ли нейросети машинное обучение». Пиарщики в своих пресс-релизах обзывают «искусственным интеллектом» любую линейную регрессию, с которой уже дети во дворе играют. Объясняю разницу на картинке, раз и навсегда.
Искусственный интеллект — название всей области, как биология или химия.
Машинное обучение — это раздел искусственного интеллекта. Важный, но не единственный.
Нейросети — один из видов машинного обучения. Популярный, но есть и другие, не хуже.
Глубокое обучение — архитектура нейросетей, один из подходов к их построению и обучению. На практике сегодня мало кто отличает, где глубокие нейросети, а где не очень. Говорят название конкретной сети и всё.
Сравнивать можно только вещи одного уровня, иначе получается полный буллщит типа «что лучше: машина или колесо?» Не отождествляйте термины без причины, чтобы не выглядеть дурачком.
Карта мира машинного обучения
Лень читать лонгрид — повтыкайте хотя бы в картинку, будет полезно.
Думаю потом нарисовать полноценную настенную карту со стрелочками и объяснениями, что где используется, если статья зайдёт.
И да. Классифицировать алгоритмы можно десятком способов. Я выбрал этот, потому что он мне кажется самым удобным для повествования. Надо понимать, что не бывает так, чтобы задачу решал только один метод. Я буду упоминать известные примеры применений, но держите в уме, что «сын маминой подруги» всё это может решить нейросетями.
Я буду упоминать известные примеры применений, но держите в уме, что «сын маминой подруги» всё это может решить нейросетями.
Начну с базового обзора. Сегодня в машинном обучении есть всего четыре основных направления.
Часть 1. Классическое обучение
Первые алгоритмы пришли к нам из чистой статистики еще в 1950-х. Они решали формальные задачи — искали закономерности в циферках, оценивали близость точек в пространстве и вычисляли направления.
Сегодня на классических алгоритмах держится добрая половина интернета. Когда вы встречаете блок «Рекомендованные статьи» на сайте, или банк блокирует все ваши деньги на карточке после первой же покупки кофе за границей — это почти всегда дело рук одного из этих алгоритмов.
Да, крупные корпорации любят решать все проблемы нейросетями. Потому что лишние 2% точности для них легко конвертируются в дополнительные 2 миллиарда прибыли. Остальным же стоит включать голову. Когда задача решаема классическими методами, дешевле реализовать сколько-нибудь полезную для бизнеса систему на них, а потом думать об улучшениях. А если вы не решили задачу, то не решить её на 2% лучше вам не особо поможет.
А если вы не решили задачу, то не решить её на 2% лучше вам не особо поможет.
Знаю несколько смешных историй, когда команда три месяца переписывала систему рекомендаций интернет-магазина на более точный алгоритм, и только потом понимала, что покупатели вообще ей не пользуются. Большая часть просто приходит из поисковиков.
При всей своей популярности, классические алгоритмы настолько просты, что их легко объяснить даже ребёнку. Сегодня они как основы арифметики — пригождаются постоянно, но некоторые всё равно стали их забывать.
Обучение с учителем
Классическое обучение любят делить на две категории — с учителем и без. Часто можно встретить их английские наименования — Supervised и Unsupervised Learning.
В первом случае у машины есть некий учитель, который говорит ей как правильно. Рассказывает, что на этой картинке кошка, а на этой собака. То есть учитель уже заранее разделил (разметил) все данные на кошек и собак, а машина учится на конкретных примерах.
В обучении без учителя, машине просто вываливают кучу фотографий животных на стол и говорят «разберись, кто здесь на кого похож». Данные не размечены, у машины нет учителя, и она пытается сама найти любые закономерности. Об этих методах поговорим ниже.
Очевидно, что с учителем машина обучится быстрее и точнее, потому в боевых задачах его используют намного чаще. Эти задачи делятся на два типа: классификация — предсказание категории объекта, и регрессия — предсказание места на числовой прямой.
Классификация
«Разделяет объекты по заранее известному признаку. Носки по цветам, документы по языкам, музыку по жанрам»
Сегодня используют для:
• Спам-фильтры
• Определение языка
• Поиск похожих документов
• Анализ тональности
• Распознавание рукописных букв и цифр
• Определение подозрительных транзакций
Популярные алгоритмы: Наивный Байес, Деревья Решений, Логистическая Регрессия, K-ближайших соседей, Машины Опорных Векторов
Классификация вещей — самая популярная задача во всём машинном обучении. Машина в ней как ребёнок, который учится раскладывать игрушки: роботов в один ящик, танки в другой. Опа, а если это робот-танк? Штош, время расплакаться и выпасть в ошибку.
Машина в ней как ребёнок, который учится раскладывать игрушки: роботов в один ящик, танки в другой. Опа, а если это робот-танк? Штош, время расплакаться и выпасть в ошибку.
Для классификации всегда нужен учитель — размеченные данные с признаками и категориями, которые машина будет учиться определять по этим признакам. Дальше классифицировать можно что угодно: пользователей по интересам — так делают алгоритмические ленты, статьи по языкам и тематикам — важно для поисковиков, музыку по жанрам — вспомните плейлисты Спотифая и Яндекс.Музыки, даже письма в вашем почтовом ящике.
Раньше все спам-фильтры работали на алгоритме Наивного Байеса. Машина считала сколько раз слово «виагра» встречается в спаме, а сколько раз в нормальных письмах. Перемножала эти две вероятности по формуле Байеса, складывала результаты всех слов и бац, всем лежать, у нас машинное обучение!
Позже спамеры научились обходить фильтр Байеса, просто вставляя в конец письма много слов с «хорошими» рейтингами. Метод получил ироничное название Отравление Байеса, а фильтровать спам стали другими алгоритмами. Но метод навсегда остался в учебниках как самый простой, красивый и один из первых практически полезных.
Метод получил ироничное название Отравление Байеса, а фильтровать спам стали другими алгоритмами. Но метод навсегда остался в учебниках как самый простой, красивый и один из первых практически полезных.
Возьмем другой пример полезной классификации. Вот берёте вы кредит в банке. Как банку удостовериться, вернёте вы его или нет? Точно никак, но у банка есть тысячи профилей других людей, которые уже брали кредит до вас. Там указан их возраст, образование, должность, уровень зарплаты и главное — кто из них вернул кредит, а с кем возникли проблемы.
Да, все догадались, где здесь данные и какой надо предсказать результат. Обучим машину, найдём закономерности, получим ответ — вопрос не в этом. Проблема в том, что банк не может слепо доверять ответу машины, без объяснений. Вдруг сбой, злые хакеры или бухой админ решил скриптик исправить.
Для этой задачи придумали Деревья Решений. Машина автоматически разделяет все данные по вопросам, ответы на которые «да» или «нет». Вопросы могут быть не совсем адекватными с точки зрения человека, например «зарплата заёмщика больше, чем 25934 рубля?», но машина придумывает их так, чтобы на каждом шаге разбиение было самым точным.
Так получается дерево вопросов. Чем выше уровень, тем более общий вопрос. Потом даже можно загнать их аналитикам, и они навыдумывают почему так.
Деревья нашли свою нишу в областях с высокой ответственностью: диагностике, медицине, финансах.
Два самых популярных алгоритма построения деревьев — CART и C4.5.
В чистом виде деревья сегодня используют редко, но вот их ансамбли (о которых будет ниже) лежат в основе крупных систем и зачастую уделывают даже нейросети. Например, когда вы задаете вопрос Яндексу, именно толпа глупых деревьев бежит ранжировать вам результаты.
Но самым популярным методом классической классификации заслуженно является Метод Опорных Векторов (SVM). Им классифицировали уже всё: виды растений, лица на фотографиях, документы по тематикам, даже странных Playboy-моделей. Много лет он был главным ответом на вопрос «какой бы мне взять классификатор».
Идея SVM по своей сути проста — он ищет, как так провести две прямые между категориями, чтобы между ними образовался наибольший зазор. На картинке видно нагляднее:
На картинке видно нагляднее:
У классификации есть полезная обратная сторона — поиск аномалий. Когда какой-то признак объекта сильно не вписывается в наши классы, мы ярко подсвечиваем его на экране. Сейчас так делают в медицине: компьютер подсвечивает врачу все подозрительные области МРТ или выделяет отклонения в анализах. На биржах таким же образом определяют нестандартных игроков, которые скорее всего являются инсайдерами. Научив компьютер «как правильно», мы автоматически получаем и обратный классификатор — как неправильно.
Сегодня для классификации всё чаще используют нейросети, ведь по сути их для этого и изобрели.
Правило буравчика такое: сложнее данные — сложнее алгоритм. Для текста, цифр, табличек я бы начинал с классики. Там модели меньше, обучаются быстрее и работают понятнее. Для картинок, видео и другой непонятной бигдаты — сразу смотрел бы в сторону нейросетей.
Лет пять назад еще можно было встретить классификатор лиц на SVM, но сегодня под эту задачу сотня готовых сеток по интернету валяются, чо бы их не взять. А вот спам-фильтры как на SVM писали, так и не вижу смысла останавливаться.
Регрессия
«Нарисуй линию вдоль моих точек. Да, это машинное обучение»
Сегодня используют для:
• Прогноз стоимости ценных бумаг
• Анализ спроса, объема продаж
• Медицинские диагнозы
• Любые зависимости числа от времени
Популярные алгоритмы: Линейная или Полиномиальная Регрессия
Регрессия — та же классификация, только вместо категории мы предсказываем число. Стоимость автомобиля по его пробегу, количество пробок по времени суток, объем спроса на товар от роста компании и.т.д. На регрессию идеально ложатся любые задачи, где есть зависимость от времени.
Регрессию очень любят финансисты и аналитики, она встроена даже в Excel. Внутри всё работает, опять же, банально: машина тупо пытается нарисовать линию, которая в среднем отражает зависимость. Правда, в отличии от человека с фломастером и вайтбордом, делает она это математически точно — считая среднее расстояние до каждой точки и пытаясь всем угодить.
Когда регрессия рисует прямую линию, её называют линейной, когда кривую — полиномиальной. Это два основных вида регрессии, дальше уже начинаются редкоземельные методы. Но так как в семье не без урода, есть Логистическая Регрессия, которая на самом деле не регрессия, а метод классификации, от чего у всех постоянно путаница. Не делайте так.
Схожесть регрессии и классификации подтверждается еще и тем, что многие классификаторы, после небольшого тюнинга, превращаются в регрессоры. Например, мы можем не просто смотреть к какому классу принадлежит объект, а запоминать, насколько он близок — и вот, у нас регрессия.
Обучение без учителя
Обучение без учителя (Unsupervised Learning) было изобретено позже, аж в 90-е, и на практике используется реже. Но бывают задачи, где у нас просто нет выбора.
Размеченные данные, как я сказал, дорогая редкость. Но что делать если я хочу, например, написать классификатор автобусов — идти на улицу руками фотографировать миллион сраных икарусов и подписывать где какой? Так и жизнь вся пройдёт, а у меня еще игры в стиме не пройдены.
Когда нет разметки, есть надежда на капитализм, социальное расслоение и миллион китайцев из сервисов типа Яндекс.Толока, которые готовы делать для вас что угодно за пять центов. Так обычно и поступают на практике. А вы думали где Яндекс берёт все свои крутые датасеты?
Либо, можно попробовать обучение без учителя. Хотя, честно говоря, из своей практики я не помню чтобы где-то оно сработало хорошо.
Обучение без учителя, всё же, чаще используют как метод анализа данных, а не как основной алгоритм. Специальный кожаный мешок с дипломом МГУ вбрасывает туда кучу мусора и наблюдает. Кластеры есть? Зависимости появились? Нет? Ну штош, продолжай, труд освобождает. Тыж хотел работать в датасаенсе.
Кластеризация
«Разделяет объекты по неизвестному признаку. Машина сама решает как лучше»
Сегодня используют для:
• Сегментация рынка (типов покупателей, лояльности)
• Объединение близких точек на карте
• Сжатие изображений
• Анализ и разметки новых данных
• Детекторы аномального поведения
Популярные алгоритмы: Метод K-средних, Mean-Shift, DBSCAN
Кластеризация — это классификация, но без заранее известных классов. Она сама ищет похожие объекты и объединяет их в кластеры. Количество кластеров можно задать заранее или доверить это машине. Похожесть объектов машина определяет по тем признакам, которые мы ей разметили — у кого много схожих характеристик, тех давай в один класс.
Отличный пример кластеризации — маркеры на картах в вебе. Когда вы ищете все крафтовые бары в Москве, движку приходится группировать их в кружочки с циферкой, иначе браузер зависнет в потугах нарисовать миллион маркеров.
Более сложные примеры кластеризации можно вспомнить в приложениях iPhoto или Google Photos, которые находят лица людей на фотографиях и группируют их в альбомы. Приложение не знает как зовут ваших друзей, но может отличить их по характерным чертам лица. Типичная кластеризация.
Правда для начала им приходится найти эти самые «характерные черты», а это уже только с учителем.
Сжатие изображений — еще одна популярная проблема. Сохраняя картинку в PNG, вы можете установить палитру, скажем, в 32 цвета. Тогда кластеризация найдёт все «примерно красные» пиксели изображения, высчитает из них «средний красный по больнице» и заменит все красные на него. Меньше цветов — меньше файл.
Проблема только, как быть с цветами типа Cyan ◼︎ — вот он ближе к зеленому или синему? Тут нам поможет популярный алгоритм кластеризации — Метод К-средних (K-Means). Мы случайным образом бросаем на палитру цветов наши 32 точки, обзывая их центроидами. Все остальные точки относим к ближайшему центроиду от них — получаются как бы созвездия из самых близких цветов. Затем двигаем центроид в центр своего созвездия и повторяем пока центроиды не перестанут двигаться. Кластеры обнаружены, стабильны и их ровно 32 как и надо было.
Искать центроиды удобно и просто, но в реальных задачах кластеры могут быть совсем не круглой формы. Вот вы геолог, которому нужно найти на карте схожие по структуре горные породы — ваши кластеры не только будут вложены друг в друга, но вы ещё и не знаете сколько их вообще получится.
Хитрым задачам — хитрые методы. DBSCAN, например. Он сам находит скопления точек и строит вокруг кластеры. Его легко понять, если представить, что точки — это люди на площади. Находим трёх любых близко стоящих человека и говорим им взяться за руки. Затем они начинают брать за руку тех, до кого могут дотянуться. Так по цепочке, пока никто больше не сможет взять кого-то за руку — это и будет первый кластер. Повторяем, пока не поделим всех. Те, кому вообще некого брать за руку — это выбросы, аномалии. В динамике выглядит довольно красиво.
Как и классификация, кластеризация тоже может использоваться как детектор аномалий. Поведение пользователя после регистрации резко отличается от нормального? Заблокировать его и создать тикет саппорту, чтобы проверили бот это или нет. При этом нам даже не надо знать, что есть «нормальное поведение» — мы просто выгружаем все действия пользователей в модель, и пусть машина сама разбирается кто тут нормальный.
Работает такой подход, по сравнению с классификацией, не очень. Но за спрос не бьют, вдруг получится.
Уменьшение Размерности (Обобщение)
«Собирает конкретные признаки в абстракции более высокого уровня»
Сегодня используют для:
• Рекомендательные Системы (★)
• Красивые визуализации
• Определение тематики и поиска похожих документов
• Анализ фейковых изображений
• Риск-менеджмент
Популярные алгоритмы: Метод главных компонент (PCA), Сингулярное разложение (SVD), Латентное размещение Дирихле (LDA), Латентно-семантический анализ (LSA, pLSA, GLSA), t-SNE (для визуализации)
Изначально это были методы хардкорных Data Scientist’ов, которым сгружали две фуры цифр и говорили найти там что-нибудь интересное. Когда просто строить графики в экселе уже не помогало, они придумали напрячь машины искать закономерности вместо них. Так у них появились методы, которые назвали Dimension Reduction или Feature Learning.
Для нас практическая польза их методов в том, что мы можем объединить несколько признаков в один и получить абстракцию. Например, собаки с треугольными ушами, длинными носами и большими хвостами соединяются в полезную абстракцию «овчарки». Да, мы теряем информацию о конкретных овчарках, но новая абстракция всяко полезнее этих лишних деталей. Плюс, обучение на меньшем количестве размерностей идёт сильно быстрее.
Инструмент на удивление хорошо подошел для определения тематик текстов (Topic Modelling). Мы смогли абстрагироваться от конкретных слов до уровня смыслов даже без привлечения учителя со списком категорий. Алгоритм назвали Латентно-семантический анализ (LSA), и его идея была в том, что частота появления слова в тексте зависит от его тематики: в научных статьях больше технических терминов, в новостях о политике — имён политиков. Да, мы могли бы просто взять все слова из статей и кластеризовать, как мы делали с ларьками выше, но тогда мы бы потеряли все полезные связи между словами, например, что батарейка и аккумулятор, означают одно и то же в разных документах.
Точность такой системы — полное дно, даже не пытайтесь.
Нужно как-то объединить слова и документы в один признак, чтобы не терять эти скрытые (латентные) связи. Отсюда и появилось название метода. Оказалось, что Сингулярное разложение (SVD) легко справляется с этой задачей, выявляя для нас полезные тематические кластеры из слов, которые встречаются вместе.
Для понимания рекомендую статью Как уменьшить количество измерений и извлечь из этого пользу, а практическое применение хорошо описано в статье Алгоритм LSA для поиска похожих документов.
Другое мега-популярное применение метода уменьшения размерности нашли в рекомендательных системах и коллаборативной фильтрации (у меня был пост про их виды). Оказалось, если абстрагировать ими оценки пользователей фильмам, получается неплохая система рекомендаций кино, музыки, игр и чего угодно вообще.
Полученная абстракция будет с трудом понимаема мозгом, но когда исследователи начали пристально рассматривать новые признаки, они обнаружили, что какие-то из них явно коррелируют с возрастом пользователя (дети чаще играли в Майнкрафт и смотрели мультфильмы), другие с определёнными жанрами кино, а третьи вообще с синдромом поиска глубокого смысла.
Машина, не знавшая ничего кроме оценок пользователей, смогла добраться до таких высоких материй, даже не понимая их. Достойно. Дальше можно проводить соцопросы и писать дипломные работы о том, почему бородатые мужики любят дегенеративные мультики.
На эту тему есть неплохая лекция Яндекса — Как работают рекомендательные системы.
Поиск правил (ассоциация)
«Ищет закономерности в потоке заказов»
Сегодня используют для:
• Прогноз акций и распродаж
• Анализ товаров, покупаемых вместе
• Расстановка товаров на полках
• Анализ паттернов поведения на веб-сайтах
Популярные алгоритмы: Apriori, Euclat, FP-growth
Сюда входят все методы анализа продуктовых корзин, стратегий маркетинга и других последовательностей.
Предположим, покупатель берёт в дальнем углу магазина пиво и идёт на кассу. Стоит ли ставить на его пути орешки? Часто ли люди берут их вместе? Орешки с пивом, наверное да, но какие ещё товары покупают вместе? Когда вы владелец сети гипермаркетов, ответ для вас не всегда очевиден, но одно тактическое улучшение в расстановке товаров может принести хорошую прибыль.
То же касается интернет-магазинов, где задача еще интереснее — за каким товаром покупатель вернётся в следующий раз?
По непонятным мне причинам, поиск правил — самая плохо продуманная категория среди всех методов обучения. Классические способы заключаются в тупом переборе пар всех купленных товаров с помощью деревьев или множеств. Сами алгоритмы работают наполовину — могут искать закономерности, но не умеют обобщать или воспроизводить их на новых примерах.
В реальности каждый крупный ритейлер пилит свой велосипед, и никаких особых прорывов в этой области я не встречал. Максимальный уровень технологий здесь — запилить систему рекомендаций, как в пункте выше. Хотя может я просто далёк от этой области, расскажите в комментах, кто шарит?
Часть 2. Обучение с подкреплением
«Брось робота в лабиринт и пусть ищет выход»
Сегодня используют для:
• Самоуправляемых автомобилей
• Роботов пылесосов
• Игр
• Автоматической торговли
• Управления ресурсами предприятий
Популярные алгоритмы: Q-Learning, SARSA, DQN, A3C, Генетический Алгоритм
Наконец мы дошли до вещей, которые, вроде, выглядят как настоящий искусственный интеллект. Многие авторы почему-то ставят обучение с подкреплением где-то между обучением с учителем и без, но я не понимаю чем они похожи. Названием?
Обучение с подкреплением используют там, где задачей стоит не анализ данных, а выживание в реальной среде.
Средой может быть даже видеоигра. Роботы, играющие в Марио, были популярны еще лет пять назад. Средой может быть реальный мир. Как пример — автопилот Теслы, который учится не сбивать пешеходов, или роботы-пылесосы, главная задача которых — напугать вашего кота с максимальной эффективностью.
Знания об окружающем мире такому роботу могут быть полезны, но чисто для справки. Не важно сколько данных он соберёт, у него всё равно не получится предусмотреть все ситуации. Потому его цель — минимизировать ошибки, а не рассчитать все ходы. Робот учится выживать в пространстве с максимальной выгодой: собранными монетками в Марио, временем поездки в Тесле или количеством убитых кожаных мешков хихихих.
Выживание в среде и есть идея обучения с подкреплением. Давайте бросим бедного робота в реальную жизнь, будем штрафовать его за ошибки и награждать за правильные поступки. На людях норм работает, почему бы на и роботах не попробовать.
Умные модели роботов-пылесосов и самоуправляемые автомобили обучаются именно так: им создают виртуальный город (часто на основе карт настоящих городов), населяют случайными пешеходами и отправляют учиться никого там не убивать. Когда робот начинает хорошо себя чувствовать в искусственном GTA, его выпускают тестировать на реальные улицы.
Запоминать сам город машине не нужно — такой подход называется Model-Free. Конечно, тут есть и классический Model-Based, но в нём нашей машине пришлось бы запоминать модель всей планеты, всех возможных ситуаций на всех перекрёстках мира. Такое просто не работает. В обучении с подкреплением машина не запоминает каждое движение, а пытается обобщить ситуации, чтобы выходить из них с максимальной выгодой.
Помните новость пару лет назад, когда машина обыграла человека в Го? Хотя незадолго до этого было доказано, что число комбинаций физически невозможно просчитать, ведь оно превышает количество атомов во вселенной. То есть если в шахматах машина реально просчитывала все будущие комбинации и побеждала, с Го так не прокатывало. Поэтому она просто выбирала наилучший выход из каждой ситуации и делала это достаточно точно, чтобы обыграть человека.
Эта идея лежит в основе алгоритма Q-learning и его производных (SARSA и DQN). Буква Q в названии означает слово Quality, то есть робот учится поступать наиболее качественно в любой ситуации, а все ситуации он запоминает как простой марковский процесс.
Машина прогоняет миллионы симуляций в среде, запоминая все сложившиеся ситуации и выходы из них, которые принесли максимальное вознаграждение. Но как понять, когда у нас сложилась известная ситуация, а когда абсолютно новая? Вот самоуправляемый автомобиль стоит у перекрестка и загорается зелёный — значит можно ехать? А если справа мчит скорая помощь с мигалками?
Ответ — никак, магии не бывает, исследователи постоянно этим занимаются, изобретая свои костыли. Одни прописывают все ситуации руками, что позволяет им обрабатывать исключительные случаи типа проблемы вагонетки. Другие идут глубже и отдают эту работу нейросетям, пусть сами всё найдут. Так вместо Q-learning’а у нас появляется Deep Q-Network (DQN).
Reinforcement Learning для простого обывателя выглядит как настоящий интеллект. Потому что ух ты, машина сама принимает решения в реальных ситуациях! Он сейчас на хайпе, быстро прёт вперёд и активно пытается в нейросети, чтобы стать еще точнее (а не стукаться о ножку стула по двадцать раз).
Потому если вы любите наблюдать результаты своих трудов и хотите популярности — смело прыгайте в методы обучения с подкреплением (до чего ужасный русский термин, каждый раз передёргивает) и заводите канал на ютюбе! Даже я бы смотрел.
Помню, у меня в студенчестве были очень популярны генетические алгоритмы (по ссылке прикольная визуализация). Это когда мы бросаем кучу роботов в среду и заставляем их идти к цели, пока не сдохнут. Затем выбираем лучших, скрещиваем, добавляем мутации и бросаем еще раз. Через пару миллиардов лет должно получиться разумное существо. Теория эволюции в действии.
Так вот, генетические алгоритмы тоже относятся к обучению с подкреплением, и у них есть важнейшая особенность, подтвержденная многолетней практикой — они никому не нужны.
Человечеству еще не удалось придумать задачу, где они были бы реально эффективнее других. Зато отлично заходят как студенческие эксперименты и позволяют кадрить научруков «достижениями» особо не заморачиваясь. На ютюбе тоже зайдёт.
Часть 3. Ансамбли
«Куча глупых деревьев учится исправлять ошибки друг друга»
Сегодня используют для:
• Всего, где подходят классические алгоритмы (но работают точнее)
• Поисковые системы (★)
• Компьютерное зрение
• Распознавание объектов
Популярные алгоритмы: Random Forest, Gradient Boosting
Теперь к настоящим взрослым методам. Ансамбли и нейросети — наши главные бойцы на пути к неминуемой сингулярности. Сегодня они дают самые точные результаты и используются всеми крупными компаниями в продакшене. Только о нейросетях трещат на каждом углу, а слова «бустинг» и «бэггинг», наверное, пугают только хипстеров с теккранча.
При всей их эффективности, идея до издевательства проста. Оказывается, если взять несколько не очень эффективных методов обучения и обучить исправлять ошибки друг друга, качество такой системы будет аж сильно выше, чем каждого из методов по отдельности.
Причём даже лучше, когда взятые алгоритмы максимально нестабильны и сильно плавают от входных данных. Поэтому чаще берут Регрессию и Деревья Решений, которым достаточно одной сильной аномалии в данных, чтобы поехала вся модель. А вот Байеса и K-NN не берут никогда — они хоть и тупые, но очень стабильные.
Ансамбль можно собрать как угодно, хоть случайно нарезать в тазик классификаторы и залить регрессией. За точность, правда, тогда никто не ручается. Потому есть три проверенных способа делать ансамбли.
Стекинг. Обучаем несколько разных алгоритмов и передаём их результаты на вход последнему, который принимает итоговое решение. Типа как девочки сначала опрашивают всех своих подружек, чтобы принять решение встречаться с парнем или нет.
Ключевое слово — разных алгоритмов, ведь один и тот же алгоритм, обученный на одних и тех же данных не имеет смысла. Каких — ваше дело, разве что в качестве решающего алгоритма чаще берут регрессию.
Чисто из опыта — стекинг на практике применяется редко, потому что два других метода обычно точнее.
Беггинг. Он же Bootstrap AGGregatING. Обучаем один алгоритм много раз на случайных выборках из исходных данных. В самом конце усредняем ответы.
Данные в случайных выборках могут повторяться. То есть из набора 1-2-3 мы можем делать выборки 2-2-3, 1-2-2, 3-1-2 и так пока не надоест. На них мы обучаем один и тот же алгоритм несколько раз, а в конце вычисляем ответ простым голосованием.
Самый популярный пример беггинга — алгоритм Random Forest, беггинг на деревьях, который и нарисован на картинке. Когда вы открываете камеру на телефоне и видите как она очертила лица людей в кадре желтыми прямоугольниками — скорее всего это их работа. Нейросеть будет слишком медлительна в реальном времени, а беггинг идеален, ведь он может считать свои деревья параллельно на всех шейдерах видеокарты.
Дикая способность параллелиться даёт беггингу преимущество даже над следующим методом, который работает точнее, но только в один поток. Хотя можно разбить на сегменты, запустить несколько… ах кого я учу, сами не маленькие.
Бустинг. Обучаем алгоритмы последовательно, каждый следующий уделяет особое внимание тем случаям, на которых ошибся предыдущий.
Как в беггинге, мы делаем выборки из исходных данных, но теперь не совсем случайно. В каждую новую выборку мы берём часть тех данных, на которых предыдущий алгоритм отработал неправильно. То есть как бы доучиваем новый алгоритм на ошибках предыдущего.
Плюсы — неистовая, даже нелегальная в некоторых странах, точность классификации, которой позавидуют все бабушки у подъезда. Минусы уже названы — не параллелится. Хотя всё равно работает быстрее нейросетей, которые как гружёные камазы с песком по сравнению с шустрым бустингом.
Нужен реальный пример работы бустинга — откройте Яндекс и введите запрос. Слышите, как Матрикснет грохочет деревьями и ранжирует вам результаты? Вот это как раз оно, Яндекс сейчас весь на бустинге. Про Google не знаю.
Сегодня есть три популярных метода бустинга, отличия которых хорошо донесены в статье CatBoost vs. LightGBM vs. XGBoost.
Часть 4. Нейросети и глубокое обучение
«У нас есть сеть из тысячи слоёв, десятки видеокарт, но мы всё еще не придумали где это может быть полезно. Пусть рисует котиков!»
Сегодня используют для:
• Вместо всех вышеперечисленных алгоритмов вообще
• Определение объектов на фото и видео
• Распознавание и синтез речи
• Обработка изображений, перенос стиля
• Машинный перевод
Популярные архитектуры: Перцептрон, Свёрточные Сети (CNN), Рекуррентные Сети (RNN), Автоэнкодеры
Если вам хоть раз не пытались объяснить нейросеть на примере якобы работы мозга, расскажите, как вам удалось спрятаться? Я буду избегать этих аналогий и объясню как нравится мне.
Любая нейросеть — это набор нейронов и связей между ними. Нейрон лучше всего представлять просто как функцию с кучей входов и одним выходом. Задача нейрона — взять числа со своих входов, выполнить над ними функцию и отдать результат на выход. Простой пример полезного нейрона: просуммировать все цифры со входов, и если их сумма больше N — выдать на выход единицу, иначе — ноль.
Связи — это каналы, через которые нейроны шлют друг другу циферки. У каждой связи есть свой вес — её единственный параметр, который можно условно представить как прочность связи. Когда через связь с весом 0.5 проходит число 10, оно превращается в 5. Сам нейрон не разбирается, что к нему пришло и суммирует всё подряд — вот веса и нужны, чтобы управлять на какие входы нейрон должен реагировать, а на какие нет.
Чтобы сеть не превратилась в анархию, нейроны решили связывать не как захочется, а по слоям. Внутри одного слоя нейроны никак не связаны, но соединены с нейронами следующего и предыдущего слоя. Данные в такой сети идут строго в одном направлении — от входов первого слоя к выходам последнего.
Если сделать достаточное количество слоёв и правильно расставить веса в такой сети, получается следующее — подав на вход, скажем, изображение написанной от руки цифры 4, чёрные пиксели активируют связанные с ними нейроны, те активируют следующие слои, и так далее и далее, пока в итоге не загорится самый выход, отвечающий за четвёрку. Результат достигнут.
В реальном программировании, естественно, никаких нейронов и связей не пишут, всё представляют матрицами и считают матричными произведениями, потому что нужна скорость. У меня есть два любимых видео, в которых весь описанный мной процесс наглядно объяснён на примере распознавания рукописных цифр. Посмотрите, если хотите разобраться.
Такая сеть, где несколько слоёв и между ними связаны все нейроны, называется перцептроном (MLP) и считается самой простой архитектурой для новичков. В боевых задачах лично я никогда её не встречал.
Когда мы построили сеть, наша задача правильно расставить веса, чтобы нейроны реагировали на нужные сигналы. Тут нужно вспомнить, что у нас же есть данные — примеры «входов» и правильных «выходов». Будем показывать нейросети рисунок той же цифры 4 и говорить «подстрой свои веса так, чтобы на твоём выходе при таком входе всегда загоралась четвёрка».
Сначала все веса просто расставлены случайно, мы показываем сети цифру, она выдаёт какой-то случайный ответ (весов-то нет), а мы сравниваем, насколько результат отличается от нужного нам. Затем идём по сети в обратном направлении, от выходов ко входам, и говорим каждому нейрону — так, ты вот тут зачем-то активировался, из-за тебя всё пошло не так, давай ты будешь чуть меньше реагировать на вот эту связь и чуть больше на вон ту, ок?
Через тысяч сто таких циклов «прогнали-проверили-наказали» есть надежда, что веса в сети откорректируются так, как мы хотели. Научно этот подход называется Backpropagation или «Метод обратного распространения ошибки». Забавно то, что чтобы открыть этот метод понадобилось двадцать лет. До него нейросети обучали как могли.
Второй мой любимый видос более подробно объясняет весь процесс, но всё так же просто, на пальцах.
Хорошо обученная нейросеть могла притворяться любым алгоритмом из этой статьи, а зачастую даже работать точнее. Такая универсальность сделала их дико популярными. Наконец-то у нас есть архитектура человеческого мозга, говорили они, нужно просто собрать много слоёв и обучить их на любых данных, надеялись они. Потом началась первая Зима ИИ, потом оттепель, потом вторая волна разочарования.
Оказалось, что на обучение сети с большим количеством слоёв требовались невозможные по тем временам мощности. Сейчас любое игровое ведро с жифорсами превышает мощность тогдашнего датацентра. Тогда даже надежды на это не было, и в нейросетях все сильно разочаровались.
Пока лет десять назад не бомбанул диплёрнинг.
На английской википедии есть страничка Timeline of machine learning, где хорошо видны всплески радости и волны отчаяния.
В 2012 году свёрточная нейросеть порвала всех в конкурсе ImageNet, из-за чего в мире внезапно вспомнили о методах глубокого обучения, описанных еще в 90-х годах. Теперь-то у нас есть видеокарты!
Отличие глубокого обучения от классических нейросетей было в новых методах обучения, которые справлялись с большими размерами сетей. Однако сегодня лишь теоретики разделяют, какое обучение можно считать глубоким, а какое не очень. Мы же, как практики, используем популярные «глубокие» библиотеки типа Keras, TensorFlow и PyTorch даже когда нам надо собрать мини-сетку на пять слоёв. Просто потому что они удобнее всего того, что было раньше. Мы называем это просто нейросетями.
Расскажу о двух главных на сегодняшний момент.
Свёрточные Нейросети (CNN)
Свёрточные сети сейчас на пике популярности. Они используются для поиска объектов на фото и видео, распознавания лиц, переноса стиля, генерации и дорисовки изображений, создания эффектов типа слоу-мо и улучшения качества фотографий. Сегодня CNN применяют везде, где есть картинки или видео. Даже в вашем айфоне несколько таких сетей смотрят на ваши фотографии, чтобы распознать объекты на них.
Проблема с изображениями всегда была в том, что непонятно, как выделять на них признаки. Текст можно разбить по предложениям, взять свойства слов из словарей. Картинки же приходилось размечать руками, объясняя машине, где у котика на фотографии ушки, а где хвост. Такой подход даже назвали «handcrafting признаков» и раньше все так и делали.
Проблем у ручного крафтинга много.
Во-первых, если котик на фотографии прижал ушки или отвернулся — всё, нейросеть ничего не увидит.
Во-вторых, попробуйте сами сейчас назвать хотя бы десять характерных признаков, отличающих котиков от других животных. Я вот не смог. Однако когда ночью мимо меня пробегает чёрное пятно, даже краем глаза я могу сказать котик это или крыса. Потому что человек не смотрит только на форму ушей и количество лап — он оценивает объект по куче разных признаков, о которых сам даже не задумывается. А значит, не понимает и не может объяснить машине.
По
Визуальное введение в машинное обучение
Поиск лучших границ
Давайте еще раз вернемся к предложенной ранее границе отметки 73 м, чтобы увидеть, как мы можем улучшить нашу интуицию.
Очевидно, это требует другой точки зрения.
Преобразуя нашу визуализацию в гистограмму , мы можем лучше увидеть, как часто дома появляются на каждой отметке.
Хотя высота самого высокого дома в Нью-Йорке составляет 73 метра, большинство из них, кажется, находятся на гораздо более низкой высоте.
Ваша первая вилка
В дереве решений используются операторы «если-то» для определения закономерностей в данных.
Например, , если дом выше некоторого числа, тогда дом, вероятно, находится в Сан-Франциско.
В машинном обучении эти операторы называются ветвями , и они разделяют данные на две ветви на основе некоторого значения.
Это значение между ветвями называется точкой разделения .Дома слева от этой точки классифицируются одним способом, а дома справа — другим. Точка разделения — это версия границы дерева решений.
Компромиссы
Выбор точки разделения требует компромиссов. Наш первоначальный раскол (~ 73 м) неправильно классифицирует некоторые дома в Сан-Франциско как нью-йоркские.
Посмотрите на тот большой участок зеленого цвета на левой круговой диаграмме, это все дома в Сан-Франциско, которые неправильно классифицированы. Они называются ложноотрицательными .
Однако точка разделения, предназначенная для захвата каждого дома в Сан-Франциско, будет включать и многие дома в Нью-Йорке. Это называется ложных срабатываний .
Лучший сплит
В best split результаты каждой ветви должны быть как можно более однородными (или чистыми). Вы можете выбрать один из нескольких математических методов, чтобы рассчитать наилучший сплит.
Как мы видим здесь, даже лучшее разделение по одному признаку не полностью отделяет дома в Сан-Франциско от домов в Нью-Йорке.
Рекурсия
Чтобы добавить еще одну точку разделения, алгоритм повторяет описанный выше процесс для подмножеств данных. Это повторение называется рекурсией , и это понятие часто встречается в обучающих моделях.
Гистограммы слева показывают распределение каждого подмножества, повторенное для каждой переменной.
Наилучшее разбиение будет зависеть от того, на какую ветвь дерева вы смотрите.
Для домов на более низкой высоте цена за квадратный фут составляет 1061 доллар за квадратный фут, что является наилучшей переменной для следующего утверждения «если-то».Для домов на возвышенности это цена 514 500 долларов США
.Обучение Машинное обучение | Учебники и ресурсы для энтузиастов машинного обучения и анализа данных
В предыдущем посте я рассмотрел код для реализации общей программы нейронной сети прямого распространения на Python. В этом посте показана программа в действии, примененная к двум задачам классификации. Весь код для этого сообщения доступен здесь.
Первая проблема — отделить красный и синий классы в наборе данных, изображенном ниже.Код для создания и построения набора данных находится здесь. Это простой пример, но он прекрасно демонстрирует возможности нейронных сетей.
Пользоваться программой очень просто. Сначала необходимо загрузить данные и инициализировать нейронную сеть.
импортный рассол
% запустить NeuralNet2.ipynb
train_x = pickle.load (open ("nn_donutballdata_train_x.pkl", "rb"))
train_y = pickle.load (open ("nn_donutballdata_train_y.pkl", "rb"))
test_x = pickle.load (open ("nn_donutballdata_test_x.пкл »,« рб »))
test_y = pickle.load (open ("nn_donutballdata_test_y.pkl", "rb"))
net = NeuralNet ((2,4,1), QuadraticCost, SigmoidActivation,
Сигмовидная активация)
net.initialize_variables ()
Небольшое отступление о форматировании данных для использования с этой программой. Любые обучающие или тестовые данные должны быть организованы как двумерная матрица чисел с плавающей запятой размером mxn , где m — количество примеров, а n — количество функций (для входных данных) или меток (для выходные данные).Итак, в этом примере в train_x и test_x каждый столбец представляет функцию, а каждая строка представляет отдельный пример. train_y и test_y — это векторы, в которых каждый элемент представляет класс соответствующего примера со значением 1 для положительного класса и 0 для отрицательного класса. train_x — это 1400 x 2 , так как есть две входные функции: координаты данных x и y , а также обучающие примеры 1400 . train_y — это 1400 x 1 , поскольку есть одна интересующая метка вывода. Для набора тестов зарезервировано 372 примера.
В последних двух строках происходит вся работа. Сначала инициализируется трехслойная нейронная сеть с одним входным слоем из 2 узлов, по одному для каждой входной функции, одним скрытым слоем из 4 узлов и одним выходным слоем с 1 узлом, поскольку мы заинтересованы в прогнозировании вероятности точки данных. принадлежащий к положительному классу. Функция стоимости, которую сеть минимизирует, — это квадратичная стоимость.Функция активации в скрытом слое — это сигмоид (со второго по последний параметр, он устанавливает функцию активации для всех скрытых слоев), как и функция активации в выходном слое (последний параметр). Затем последняя строка инициализирует все сетевые переменные, веса и смещения.
Все, что сейчас нужно, — это установить гиперпараметры и вызвать функцию SGD, которая обучает сеть через стохастический градиентный спуск.
Learning_rate = 0.1
batch_size = 10
lmda = 0
эпох = 1001
report_rate = 200
учебная_ стоимость, допустимая_ стоимость = чистая. SGD (поезд_x, поезд_y,
test_x, test_y,
Learning_rate,
эпохи
report_rate,
lmda,
размер партии)
На приведенном ниже рисунке показана производительность сети в процессе обучения.Все точки внутреннего шара должны быть красного цвета, а все точки внешнего шара — синего цвета.
Начнем с того, что сеть не очень хорошо работает, и все точки синие. Однако после 960 эпох сеть достигает 100% точности как на обучающем, так и на тестовом наборе данных. Этого и следовало ожидать, поскольку существует граница, которая четко разделяет два класса по дизайну.
Интересно, что за первые 300 эпох мало что происходит. Затем к 480-й эпохе стоимость значительно упала, а точность подскочила примерно до 80%. После этого точность держится на уровне около 80% в течение следующих 300 или около того эпох. Однако построение набора данных показывает, что за кулисами многое меняется. Изображения эпох 480 и 640 показывают, что за это время граница принятия решения сместилась с конуса на полосу. Наконец, к 800-й эпохе точность возрастает до 100%, и граница принятия решения сходится на правильной — круге.
Отсутствие прогресса в начале — довольно частая картина обучения. Часто обучение какое-то время идет очень медленно, затем производительность начинает улучшаться, затем снова выходит на плато, затем улучшается. Предполагается, что сеть перемещается между плоскими областями пространства параметров стоимости, где достигнут незначительный прогресс, и крутыми областями, где возможно значительное уменьшение функции стоимости. В результате иногда бывает сложно определить, находится ли сеть в плоском регионе, но в конечном итоге она начнет учиться или вообще ничего не узнает.
Один из способов решения этой проблемы — начать с небольшого подмножества обучающих данных и достаточно небольшой сети, чтобы сеть выполнялась всего за 15–30 секунд за период. Это позволяет быстро перебирать различные гиперпараметры, пока сеть не начнет чему-то учиться. Как только вы установили, что сеть действительно может чему-то научиться, с этой точки зрения становится намного проще вносить дополнительные улучшения.
Существует множество возможных настроек гиперпараметров, с которыми можно поиграть, и они существенно влияют на скорость обучения нейронной сети.Или вообще чему-нибудь научится. Ниже приведен пример, в котором единственными отличиями от сети, представленной выше, являются функция стоимости и методология инициализации параметров сети. Однако он учится разделять эти данные примерно на 80% быстрее, и требуется всего 150 эпох, чтобы достичь 100% точности при той же скорости обучения и размере пакета.
net = NeuralNet ((2,4,1), CrossEntropyCost, SigmoidActivation, SigmoidActivation)
net.initialize_variables_normalized ()
Learning_rate = 0.1
batch_size = 10
lmda = 0
эпох = 150
report_rate = 200
учебная_ стоимость, допустимая_ стоимость = чистая. SGD (поезд_x, поезд_y,
test_x, test_y,
Learning_rate,
эпохи
report_rate,
lmda,
размер партии)
Этот блокнот jupyter содержит множество примеров, которые подчеркивают влияние различных настроек на производительность сети.Они ни в коем случае не являются исчерпывающими, но демонстрируют, насколько чувствительны сети к различным стратегиям инициализации параметров, функциям стоимости, размерам пакетов и функциям активации.
Помимо настройки гиперпараметров, необходимо также учитывать архитектуру сети. Поскольку это очень простая задача классификации с простой нелинейной границей, я предположил, что достаточно нейронной сети с одним скрытым слоем из нескольких узлов. Однако выбор четырех узлов был несколько произвольным.Более строгий подход заключался бы в рассмотрении преобразования данных, необходимого для того, чтобы классы были линейно разделимы. Преобразование, проецирующее координаты x и y в трех измерениях,
где z = 1, если,
и z = 0 в противном случае было бы достаточно. (a, b) — центр круга из красных точек, а r — радиус круга с началом (a, b) , достаточно большой, чтобы чисто содержать красные точки и исключить синие точки.Результатом этой проекции является поднятие всех точек в круге (красные точки) над синими точками при визуализации в трех измерениях. Тогда плоскость, указанная как z = 0,5, разделит два класса. Такой подход к данным предполагает, что необходимы как минимум 3 узла в скрытом слое, но, вероятно, также будет достаточно. Этот блокнот показывает, что это действительно так.
В большинстве случаев не так просто рассуждать об архитектуре нейронной сети.На практике поиск лучшей архитектуры обычно является результатом проб и ошибок. Однако общая эвристика состоит в том, что по мере того, как проблемы становятся более сложными, вероятно, будет полезно больше уровней, поскольку это упрощает для сети изучение сложных преобразований данных.
Второй пример — классический набор данных MNIST. Это большой набор изображений в градациях серого размером 28 x 28 , состоящих из рукописных цифр от 0 до 9, каждое из которых имеет соответствующую метку. Задача состоит в том, чтобы правильно классифицировать каждую цифру.
импортный рассол
% запустить NeuralNet2.ipynb
train_x = pickle.load (open ("MNIST_train_x.pkl", 'rb'))
train_y = pickle.load (open ("MNIST_train_y.pkl", 'rb'))
test_x = pickle.load (open ("MNIST_test_x.pkl", 'rb'))
test_y = pickle.load (open ("MNIST_test_y.pkl", 'rb'))
short_train_x = train_x [0: 5000 ,:]
short_train_y = train_y [0: 5000 ,:]
net2 = NeuralNet ((784,100,10), LogLikelihoodCost, ReluActivation, SoftmaxActivation)
net2.initialize_variables ()
learning_rate = 0,001
эпох = 61
Reporting_rate = 20
lmda = 0
batch_size = 200
тренировочная_ стоимость, действительная_ стоимость = net2.SGD (короткий_поезд_x, короткий_поезд_y,
test_x, test_y,
Learning_rate,
эпохи
report_rate,
lmda,
размер партии,
verbose = False)
Данные загружаются как двумерные массивы numpy, примеров x функции . Обратите внимание, что изображения были сведены из матрицы 28 x 28 в вектор в 784 измерениях, так что одна строка может представлять одно изображение, а каждый столбец соответствует одному пикселю.Даже такая небольшая сеть требует много времени, чтобы обучаться на ноутбуке с полным набором данных. Итак, чтобы ускорить обучение для множества различных сетей, я выбрал первые 5000 примеров из данных обучения. Несмотря на свою простоту, обучение нейронной сети с одним скрытым слоем из 100 узлов всего с 5000 примеров дает удивительно хорошие результаты с точностью 90% на тестовых данных.
Сеть инициализирована с тремя уровнями; 784 входных узла, по одному на каждый пиксель изображения, 100 скрытых узлов и 10 выходных узлов, по одному для каждого класса.Функция активации ReLU используется в скрытом слое, а softmax — в выходном слое. Выходной слой softmax имеет преимущество вывода распределения вероятностей по каждому из выходных классов. Таким образом, значение любого выходного узла для конкретного примера можно интерпретировать как вероятность того, что этот пример принадлежит соответствующему классу. Softmax лучше всего использовать с функцией стоимости логарифма правдоподобия, поскольку она «отменяет» экспоненту в функции softmax.
Всего через 61 эпоху при относительно большом размере пакета эта сеть достигает 99.Точность 5% на тренировочных данных и 90,54% на тестовых данных. Обратите внимание, что эта конкретная сеть переобладает обучающими данными, поскольку производительность на тестовых данных на 9% ниже, чем на обучающих данных. Этого следовало ожидать, учитывая, что обучающие данные содержат только 5000 примеров и нет регуляризации (lmda = 0). См. Здесь, здесь и здесь для некоторых записных книжек, которые экспериментируют с различной стоимостью, функциями активации, размерами пакетов, скоростью обучения и стратегиями инициализации. Есть огромное разнообразие исполнений.
Интересно поэкспериментировать с разным количеством и размерами слоев. Теория глубокого обучения говорит нам, что должна быть возможность аппроксимировать функцию с той же точностью, используя меньше узлов и больше слоев. Результаты этих экспериментов подтверждают это. Что меня больше всего интересовало, так это то, что при прочих равных условиях изменение размера и количества слоев не оказывало значительного влияния на производительность. Почти все различные сети достигли точности на тестовом наборе с точностью до 1% друг от друга.Я подозреваю, что это связано с тем, что набор обучающих данных был таким маленьким и был ограничивающим фактором. Я оставляю читателю возможность поэкспериментировать с этими сетями, используя больше данных. Исключением стала 5-слойная нейронная сеть с на 40 узлов меньше по сравнению с базовой. Эта сеть может выиграть от обучения большему количеству эпох.
Мой лучший результат с использованием трех слоев и всего 20 000 обучающих примеров был с этой сетью.
short_train_x = train_x [0: 20000 ,:]
short_train_y = train_y [0: 20000 ,:]
net2 = NeuralNet ((784,100,10), LogLikelihoodCost, ReluActivation,
SoftmaxАктивация)
net2.initialize_variables_alt ()
скорость обучения = 0,0001
эпох = 101
Reporting_rate = 20
lmda = 0,5
batch_size = 100
учебная_ стоимость, допустимая_ стоимость = net2.SGD (поезд_x, поезд_y,
test_x, test_y,
Learning_rate,
эпохи
report_rate,
lmda,
размер партии,
verbose = False)
Достигло 96.Погрешность 19% на тестовых данных после 101 эпохи. Регуляризация также сократила разницу в производительности между обучающим и тестовым набором всего до 1,43%. Неплохо.
Я надеюсь, что вам понравился этот пост и он оказался полезным. Если у вас есть отзывы, отправьте мне электронное письмо по адресу contact [at] learningmachinelearning [dot] org.
10 лучших фреймворков машинного обучения
@Jack Jack
SysBunny — ведущая компания по разработке мобильных приложений в США.
Машинное обучение (ML) — одна из самых быстро развивающихся технологий сегодня.Разработчики машинного обучения ищут подходящую структуру для своих различных проектов по разработке приложений машинного обучения. Перечисленные здесь 10 лучших фреймворков машинного обучения удовлетворяют современные потребности разработчиков экономически эффективным способом. Давай узнаем об этом.
Машинное обучение (ML) согласно Википедии — это научное исследование статистических моделей и алгоритмов, помогающих вычислительной системе выполнять поставленные задачи эффективно и независимо, полагаясь исключительно на выводы и закономерности, извлеченные из обучающих или полученных данных.Это часть технологии искусственного интеллекта. Таким образом, он автоматически наклоняется и улучшает производительность с учетом темпа времени, взаимодействия и опыта, а также, что наиболее важно, сбора полезных данных, относящихся к назначенным задачам.
Почему фреймворк машинного обучения?
В индустрии программного обеспечения мы знаем, что без интерфейса, библиотек и организованных инструментов разработка программного обеспечения становится кошмаром. Когда мы объединяем эти основные элементы, он становится основой или платформой для легкой, быстрой и значимой разработки программного обеспечения.
Фреймворки машинного обучения помогают разработчикам машинного обучения определять модели машинного обучения точным, прозрачным и лаконичным способом. Фреймворки машинного обучения, используемые для предоставления предварительно созданных и оптимизированных компонентов, помогающих в построении моделей и других задачах.
Когда мы собираемся выбрать правильный фреймворк машинного обучения для нашего следующего проекта, мы должны иметь в виду следующие вещи.
Фреймворк должен быть ориентирован на производительность.
Он должен всегда обеспечивать традицию создания моделей и предоставлять удобный инструмент для разработчиков.
Он должен быстро понимать и кодировать.
Надо нестандартно, а не черный ящик кабины пилота!
Он должен предлагать распараллеливание для распределения вычислительного процесса.
У него должна быть отличная база пользователей и поддерживающее сообщество, чтобы помочь.
Введение в машинное обучение — CodeProject
Что такое машинное обучение?
«Машинное обучение — это область обучения, которая дает компьютерам возможность учиться без явного программирования» Артур Смауэль.
Машинное обучение можно рассматривать как подход к автоматизации таких задач, как прогнозирование или моделирование. Например, рассмотрите систему фильтрации спама в электронной почте, вместо того чтобы заставлять программистов вручную просматривать электронные письма и придумывать правила для спама. Мы можем использовать алгоритм машинного обучения и передавать ему входные данные (электронные письма), и он автоматически обнаруживает правила, достаточно мощные, чтобы различать спам-письма.
Машинное обучение в настоящее время используется во многих приложениях, таких как обнаружение спама в электронных письмах или системы рекомендаций фильмов, которые подсказывают вам фильмы, которые могут вам понравиться, на основе вашей истории просмотров.Хорошая и мощная вещь в машинном обучении: Оно обучается, когда получает больше данных, и, следовательно, оно становится все более мощным, чем больше данных мы им даем .
Типы машинного обучения
Существует три различных типа машинного обучения: обучение с учителем, обучение без учителя и обучение с подкреплением.
Обучение с учителем
Цель обучения с учителем — изучить модель на основе помеченных обучающих данных, которая позволяет нам делать прогнозы относительно будущих данных.Чтобы контролируемое машинное обучение работало, нам нужно передать в алгоритм две вещи: входные данные и наши знания о них.
Пример спам-фильтра, упомянутый ранее, является хорошим примером контролируемого обучения; у нас есть куча электронных писем (данные), и мы знаем, является ли каждое электронное письмо спамом (ярлыки).
Обучение с учителем можно разделить на две подкатегории:
1. Классификация: используется для прогнозирования категорий или обозначений классов на основе прошлых наблюдений i.е. у нас есть дискретная переменная, которую вы хотите разделить на дискретный категориальный результат. Например, в системе фильтрации спама в электронной почте вывод будет дискретным «спам» или «не спам».
2. Регрессия: используется для прогнозирования непрерывного результата. Например, чтобы определить цену домов и как на нее влияет количество комнат в этом доме. Входные данные — это характеристики дома (количество комнат, местоположение, размер в квадратных футах и т. Д.), А выходные данные — цена (непрерывный результат).
Обучение без учителя
Целью обучения без учителя является обнаружение скрытой структуры или закономерностей в немаркированных данных, и его можно разделить на две подкатегории.
1. Кластеризация: используется для организации информации в значимые кластеры (подгруппы) без предварительного знания их значения. Например, на рисунке ниже показано, как мы можем использовать кластеризацию для организации немаркированных данных в группы на основе их характеристик.
2.Уменьшение размерности (сжатие): используется для уменьшения данных более высокого измерения в данные более низкого измерения. Чтобы выразиться более наглядно, рассмотрим этот пример. Телескоп содержит терабайты данных, и не все эти данные могут быть сохранены, поэтому мы можем использовать уменьшение размерности для извлечения наиболее информативных характеристик этих данных для сохранения. Снижение размерности также является хорошим кандидатом для визуализации данных, потому что, если у вас есть данные в более высоких измерениях, вы можете сжать их до 2D или 3D, чтобы легко построить и визуализировать их.
Обучение с подкреплением
Целью обучения с подкреплением является разработка системы, улучшающей ее производительность на основе взаимодействия с динамической средой и отложенной обратной связи, которая действует как вознаграждение. то есть обучение с подкреплением — это обучение на практике с отложенным вознаграждением. Классическим примером обучения с подкреплением является игра в шахматы, в которой компьютер определил серию ходов, а награда — «победа» или «поражение» в конце игры.
Вы можете подумать, что это похоже на контролируемое обучение, где вознаграждение в основном является ярлыком для данных, но основное отличие состоит в том, что эта обратная связь / вознаграждение не соответствует действительности, а является мерой того, насколько хорошо действия для достижения определенной цели.
Предварительная обработка данных
Качество данных и количество содержащейся в них полезной информации сильно влияют на то, насколько хорошо алгоритм может обучаться. Следовательно, важно предварительно обработать набор данных перед его использованием. Наиболее распространенные шаги предварительной обработки: удаление пропущенных значений , преобразование категориальных данных в форму, подходящую для алгоритма машинного обучения и масштабирования функций .
Отсутствующие данные
Иногда в выборках набора данных отсутствуют некоторые значения, и мы хотим обработать эти отсутствующие значения перед передачей их алгоритму машинного обучения.Есть несколько стратегий, которым мы можем следовать
1. Удаление выборок с пропущенными значениями: этот подход, безусловно, наиболее удобный, но в конечном итоге мы можем удалить слишком много выборок, что приведет к потере ценной информации, которая может помочь алгоритму машинного обучения.
2. Подстановка пропущенных значений: вместо удаления всей выборки мы используем интерполяцию для оценки недостающих значений. Например, мы могли бы заменить отсутствующее значение средним значением для всего столбца.
Категориальные данные
В общем, характеристики могут быть числовыми (например, цена, длина, ширина и т. Д.) Или категориальными (например, цвет, размер и т. Д.). Категориальные признаки далее делятся на номинальных и порядковых признаков.
Порядковые элементы можно сортировать и заказывать. Например, размер (маленький, средний, большой), мы можем заказать эти размеры большой> средний> маленький. Хотя у номинальных характеристик нет порядка, например цвета, нет смысла говорить, что красный больше синего.
Большинство алгоритмов машинного обучения требуют, чтобы вы преобразовывали категориальные признаки в числовые значения. Одно из решений — присвоить каждому значению различное число, начиная с нуля. (например, маленький по 0, средний по 1, большой по 2)
Это хорошо работает для порядковых элементов, но может вызвать проблемы с номинальными характеристиками (например, синий = 0, белый = 1, желтый = 2), потому что даже если цвета не упорядочены, алгоритм обучения будет предполагать, что белый больше синего, а желтый больше чем белый, и это неправильно.
Чтобы обойти эту проблему, нужно использовать горячее кодирование , идея состоит в том, чтобы создать новую функцию для каждого уникального значения номинальной характеристики.
Использование моделирования для обучения и тестирования приложений машинного обучения
Одной из проблем при обучении и тестировании алгоритмов машинного обучения является получение данных высокого качества: оперативные данные, с которыми будут работать ваши алгоритмы, часто недоступны с самого начала и даже если да, то он может не содержать всех функций, на которых вы хотите обучить свой алгоритм.
Один из подходов к решению этой проблемы — создание данных с использованием моделирования — это дает вам полный контроль как над функциями, содержащимися в данных, так и над объемом и частотой данных.
В этом посте мы покажем вам, как отслеживать давно существующие симуляции и использовать данные для целей машинного обучения без необходимости развертывания на собственном оборудовании — и с использованием как можно меньшего количества кода! В этом примере используются данные моделирования, созданные с помощью нашей собственной платформы BPTK-Py.Мы используем различные приложения Amazon Web Services, чтобы сосредоточиться на аналитике и машинном обучении, а не на коде и аппаратном / программном обеспечении.
Вызов
В предыдущих сообщениях вы узнали, как мы разработали движок моделирования на основе Python для системной динамики и агентного моделирования. Он позволяет запускать сложные симуляции в среде Jupyter и получать доступ к результатам симуляции для дальнейшего анализа.
Алгоритмы машинного обучения (ML) становятся частью нашей повседневной жизни.Владельцы рекламы улучшают свой таргетинг, используя поведение потенциальных клиентов при просмотре веб-страниц. Компании используют все больше и больше источников данных — как внутренних, так и внешних — для прогнозирования будущих продаж и изменения своей стратегии, и все это поддерживается машинным обучением. Производители хотят прогнозировать производительность машин и отказы, чтобы сократить простои производства или даже несчастные случаи.
Выбрать правильный алгоритм машинного обучения сложно. Это требует большого количества реальных данных и тестирования. Но наличие таких данных не всегда указывается.Кто-нибудь из отдела продаж может предоставить вам данные о продажах за прошлый год. Но у кого есть эти исследования рынка? Можете ли вы получить доступ к необработанным данным аналитики веб-сайта? Эти данные могут потребоваться на уровне потока кликов. Но DWH может хранить их только предварительно обработанными как подробные данные — или обогащенные другими — для вашей проблемы — бесполезной информацией.
С помощью BPTK вы можете разрабатывать модели и быстро их тестировать. Что, если совместить моделирование и быстрое прототипирование алгоритмов машинного обучения? Таким образом, вы избегаете бесконечного поиска реальных данных.С его подходом вы сможете:
- Моделирование данных, близких к реальным
- Протестируйте различные алгоритмы машинного обучения для решения вашей проблемы
- Узнайте, какие источники данных помогают решить вашу проблему
- Поделитесь своими знаниями с лицами, принимающими решения, и докажите преимущества использования методов машинного обучения в контексте вашего бизнеса
Далее мы хотели бы представить вам небольшой пример того, как мы использовали моделирование на основе агентов для нескольких случаев использования машинного обучения.
Amazon Web Services (AWS)
Amazon Web Services (AWS) — это мощный сервис для развертывания масштабируемых онлайн-сервисов вычислений и хранения.AWS обслуживает оборудование и программное обеспечение, что означает, что вы можете развернуть конвейеры данных всего несколькими щелчками мыши, доступными со многих
Почему мы использовали AWS в этой витрине? Потому что это позволяет нам сосредоточиться на алгоритмах и методах машинного обучения, а не на подключении инфраструктуры и написании большого количества кода, прежде чем мы сможем даже протестировать машинное обучение. Мы более подробно рассмотрим конкретные службы, которые мы использовали, позже в этом сообщении в блоге.
Имитационная модель
Мы используем симуляцию электромобиля.Это классический вариант использования IOT (Интернета вещей). В настоящее время автомобили постоянно отправляют статистику на серверы производителей, чтобы помочь улучшить продукт. Данные обрабатываются в режиме реального времени. В симуляции каждая машина действует как агент и имеет аккумулятор. Мы не моделировали двигатель или какие-либо другие компоненты, чтобы сделать модель как можно более простой. Давайте быстро рассмотрим имитационные модели и измеряемые нами переменные. На рисунке 1 показано состояние автомобиля, с которым мы собираемся работать.
Рисунок 1: Диаграмма состояний для моделирования автомобильного аккумулятораВ каждом раунде симуляции автомобиль либо едет, либо заряжается, либо заменяется аккумулятор. Аккумулятор может выйти из строя. При отказе батареи требуется еще один временной шаг моделирования для замены батареи. В этой простой модели батарея выйдет из строя, если ее емкость упадет ниже 14 000 ампер при расчетной емкости 20 000 ампер. Емкость уменьшается с каждым раундом из-за вождения и подзарядки, как в реальном мире. Состояние батареи хранится в поле «battery \ _state».Во время движения автомобиль потребляет 39,7 А на километр, что дает около 500 км на полную зарядку (когда полная мощность еще доступна). Количество километров, пройденных во временном шаге моделирования, является случайным значением в определенных пределах, заданных стратегией вождения. Замена будет происходить только в том случае, если аккумулятор ранее перешел в неисправное состояние. Каждый раз, когда автомобиль едет, в поле «distance \ _in \ _period» хранится километраж, пройденный за заданный период моделирования. По умолчанию при зарядке устанавливается на ноль. Поле «заряд» ‘измеряет текущий заряд аккумулятора.Поле «cylces» увеличивается на единицу при полной перезарядке. Автомобиль заряжается, если достигнут нижний предел заряда. Эта нижняя граница также определяется стратегией.
Выбор стратегии случаен при инициализации модели. Мы определяем три стратегии вождения:
| Имя | Макс. километров за период | Нижняя граница начисления | Нижняя граница начисления |
| тяжелый | 60 | 20% | Тяжелый водитель, который заряжается только при необходимости.Часто ездит |
| Город | 25 | 60% | Водитель, который живет в городе и не проезжает слишком много километров |
| Среднее значение | 35 | 40% | часто ездит и заряжается немного позже, чем городской водитель, но не совершает очень дальние поездки |
В этой статье мы сосредоточимся на емкости аккумулятора. Емкость определяет необходимость замены батареи.Было бы здорово иметь возможность спрогнозировать это значение. Следовательно, мы должны смотреть на емкость батареи с течением времени для одного агента. На рисунке 2 показаны результаты моделирования, которое длилось 100 000 шагов. Мы ясно видим довольно простую схему: емкость начинается с 20 000 ампер и — почти линейно — уменьшается до 14 000, прежде чем будет заменена батарея и возобновлен режим. Если вы более внимательно посмотрите на один цикл, вы заметите, что уменьшение емкости не является действительно линейным. Это связано с тем, что автомобиль проезжает определенные километры в рамках стратегии, а не фиксированное количество километров на каждом временном шаге.Однако можно легко построить функцию для оценки события отказа батареи.
Рисунок 2: Емкость аккумулятора с течением времени для моделирования автомобиля. Шагов: 100,000Эта модель может быть довольно простой, но достаточно хорошей для наших целей, чтобы протестировать методы прогнозирования неисправности батареи. В реальном мире механизм прогнозирования неисправности аккумулятора полезен, чтобы сообщить водителю о назначении встречи в ближайшей мастерской — до того, как он сломается посреди дороги.
Для прогнозирования таких проблем производители автомобилей могут использовать методы науки о данных.Автомобиль может отправлять собственные данные телеметрии на серверы производителя, которые используют обученную модель, основанную на миллионах других автомобилей. В ответ он может получить предупреждение, если в ближайшем будущем прогнозируется отказ батареи.
Технологии, использованные в этой пробной версии
На рис. 3 показана структура нашей среды машинного обучения, используемой в этом Proof-of-Concept. Хотя моделирование может выполняться в любой среде Python, остальная часть нашего конвейера данных обрабатывается различными приложениями Amazon Web Services.Для крупномасштабных задач моделирования мы используем экземпляр EC2. В следующих разделах рассматривается конвейер AWS и используемые технологии.
Рисунок 3: Конвейер данныхAWS Kinesis (поток, аналитика, пожарный шланг)
AWS Kinesis предоставляет очереди сообщений или потоки данных. У каждого потока может быть один или несколько производителей и потребителей. Производители отправляют данные, а потребители извлекают их для дальнейшей обработки. Kinesis обеспечивает распространение данных среди всех потребителей и хранит их до момента использования.Для вычисления агрегатов мы использовали Kinesis Analytics.Эта служба обращается к потокам Kinesis и обеспечивает доступ к данным, подобный SQL. Поскольку мы имеем дело с потоковой передачей данных, которая никогда не заканчивается, каждому запросу требуется окно для обработки агрегатов. Окна являются либо окнами подсчета, либо окнами времени. Окно подсчета занимает фиксированное количество записей, например 1000 записей и вычисляет агрегат (AVG, MIN, MAX и т. Д.). Временное окно на другой стороне собирает записи определенного временного интервала. Кроме того, окно может быть скользящим или опрокидывающимся. Окно счетчика в 100 срабатываний при поступлении 100 событий.Скользящее окно того же размера срабатывает всякий раз, когда приходит новое событие, и принимает все предыдущие 99 элементов этого конкретного события.
Мы реализовали следующие три запроса, чтобы продемонстрировать возможности Kinesis Analytics:
- Среднее количество километров в пути за период за последние 10 периодов: быстро отслеживайте среднее количество километров, которые проезжает каждый агент за период
- Среднее количество километров до выхода из строя батареи за последний час: отслеживайте количество километров до выхода из строя батареи.«1 час» описывает время, когда события прибыли, а не когда они были сгенерированы в BPTK
- Обнаружение аномалий: обнаружение аномалий в потоковых данных и их измерение с помощью оценки аномалий.
Выходные данные запросов AWS Kinesis Analytics перетекают в другой поток Kinesis Stream. Эти данные используются AWS Kinesis Firehose. Firehose — еще один компонент Kinesis. Он принимает поток Kinesis в качестве входных данных и выводит их в структурированном виде в другие приложения AWS. Использование Firehose позволяет избежать кодирования вашего собственного потребителя потока.Он передает потоковые данные в целевые приложения без особой настройки. Здесь Firehose используется для вывода данных в S3, масштабируемое хранилище данных — подробнее об этом в следующем разделе.
AWS Lambda
Для прогнозирования мы используем AWS Lambda. Lambda — это служба, которая позволяет выполнять произвольный код, называемый функцией , всякий раз, когда запускается триггер. Функция не имеет состояния, что означает, что все переменные теряются после завершения выполнения.Код запускается всякий раз, когда применяется условие. В этом примере мы используем поток Kinesis в качестве триггера. Мы настроили Lambda для выполнения нашей функции при поступлении 100 событий.
Сама функция представляет собой небольшой скрипт Python, который получает записи, вычисляет прогнозы для каждого агента и передает данные в другой поток Kinesis. Виртуальная среда, в которой выполняется код, поставляется только с самыми основными пакетами Python. Следовательно, вам нужно будет загрузить пакеты Linux для всех требований и добавить их в пакет кода.Обратите внимание, что некоторые пакеты, такие как numpy и pandas, необходимо скомпилировать. Мы использовали виртуальную машину Amazon Linux и выполнили следующие команды в виртуальной среде:
pip3.6 install - обновить pip wheel pip3.6 install --no-binary numpy numpy == 1.16 pip3.6 установить scipy pip3.6 установить --no-binary pandas pandas pip3.6 install --no-binary statsmodels statsmodels pip3.6 install boto # Для доступа к ресурсам AWS в функции Lambda
Просто скопируйте содержимое site-packages виртуальной среды в zip-файл вместе с функцией .py . Затем мы скопировали zip в корзину S3 (S3 — это служба хранения, предоставляемая AWS) и настроили функцию Lambda для извлечения файла из местоположения S3.
Для прогнозирования емкости аккумулятора мы используем авторегрессионное моделирование. Этот метод создает функцию, которая взвешивает влияние предыдущих наблюдений на будущие значения. Альтернативой является использование скользящей средней. Оба метода широко используются для прогнозирования. Расширения, такие как ARIMA (объединяющие оба метода), также распространены.Для обучения моделей мы используем пакет statsmodels python, простой в использовании пакет для статистического моделирования. Базовый код обучения и прогнозирования довольно прост и понятен. Для отличного примера ознакомьтесь с этим сообщением в блоге.Большая часть кода, который нам пришлось написать, касается декодирования входящих потоковых данных и подготовки их для обучения модели. Структура данных очень интуитивно понятна. Лямбда-функция получает словарь со списком записей . Каждый элемент списка хранит словарь с именем kinesis , который включает метаданные для данной записи и необработанные данные.Обратите внимание, что данные из потока кинезиса прибывают в кодировке base64 с помощью лямбда-функции. Это связано с тем, что кинезис не зависит от типа поступающих данных. Это означает, что вам понадобится пакет base64 для декодирования строки JSON. Функция извлекает поле емкости для каждой записи и записывает их в список. Сама подгонка модели требует всего нескольких команд:
из statsmodels.tsa.ar_model import AR горизонт = 100 # количество периодов для прогноза model = AR (данные) model_fit = модель.поместиться() прогноз = model_fit.predict (len (данные), len (данные) + горизонт)
AWS S3
AWS Simple Storage Service или обычно именуемый «S3» — это масштабируемое онлайн-хранилище объектов. Он позволяет хранить любые данные, которые потребляют другие приложения. Данные организованы в сегменты. Каждую корзину можно настроить отдельно, включая права доступа, видимость и разрешения на чтение / запись. Каждый из наших процессов Firehose (по одному для каждого запроса) записывает данные результатов в отдельную корзину S3.S3 не ограничивает объем памяти, который вы можете использовать. Вы предпочитаете платить за то, что вы используете, и сколько вы это используете. Это делает S3 масштабируемым. Кроме того, он отличается высокой доступностью и производительностью. Как и все другие услуги, Amazon обеспечивает оборудование и программное обеспечение, необходимое для использования ресурсов, без необходимости использования вашего собственного физического оборудования. Библиотеки для S3 доступны для многих языков программирования. Таким образом, даже приложения, не относящиеся к AWS, могут получить доступ к данным из S3.
AWS Quicksight
Последний инструмент в нашей цепочке — AWS Quicksight.Quicksight — это система бизнес-аналитики, которая может подключаться ко многим источникам данных для графического анализа. Интерфейс очень интуитивно понятен и прост. Чтобы получить данные из S3, просто нажмите «Добавить источник данных» и выберите «S3». Quicksight требуется файл JSON, в котором указаны сегменты S3 и подпапки, из которых предполагается извлекать данные. Давайте посмотрим на пример:
{"fileLocations": [
{
"URIPrefixes": [
"s3: // the-bucket / subfolder /",
]}], "globalUploadSettings": {
"формат": "JSON",}.} Поле URIPrefixes устанавливает каталог (и) для поиска данных. Quicksight анализирует все записи и извлекает все подпапки и файлы префикса. В данном примере он анализирует все файлы и подпапки в s3: // the-bucket / subfolder /. Поле globalUploadSettings содержит информацию о данных. Поручаем Quicksight анализировать найденные данные как файлы JSON. После добавления всех источников данных мы можем создавать графики и анализировать результаты.
Визуализация и анализ
На рис. 4 показано среднее количество километров, которое каждый агент проехал за период.Здесь мы провели моделирование для четырех агентов. Мы можем легко выделить две группы агентов с различным поведением вождения. Агенты с более агрессивной стратегией вождения также больше управляют, в то время как консервативные агенты — конечно же — меньше. В моделировании с множеством агентов вы можете использовать данные ряда в качестве входных данных для обучения различных алгоритмов кластеризации или классификации.
Рисунок 4: Среднее количество километров на агента за периодДалее идет оценка аномалий — встроенная функция, использующая случайные деревья для обнаружения аномалий в полученном потоке.Вы видите график аномалий на рисунке 5 для первых 50 временных шагов моделирования. Гистограмма на левой оси Y отображает заряд за временной шаг. Линейный график показывает оценку аномалии для каждого временного шага. Аномалия вычисляется по всем числовым полям, получаемым потоком. Значение колеблется около 1, что очень мало. Это неудивительно, поскольку функция не показывает больших аномалий. Мы наблюдаем очень четкую картину на графике заряда. Он разряжается, пока агент не перезарядит аккумулятор. При каждой перезарядке мы наблюдаем небольшой пик в оценке аномалий.Оценка аномалии вычисляется в окне, которое вы можете настроить в запросе. Вы можете использовать окна разных размеров, чтобы улучшить обнаружение аномалий. Слишком большое окно может привести к очень медленной реакции на аномалии, в то время как слишком маленькое окно может привести к множеству ложных срабатываний, поскольку прошлые наблюдения с аналогичными паттернами не принимаются во внимание.
Рисунок 5: Оценка аномалийТеперь давайте посмотрим на наиболее интересный график, прогноз емкости батареи, который представлен на рисунке 6.Мы видим, насколько прогноз похож на картину реального развития мощностей. Очевидно, что для этого цикла хорошо подходит метод AR. Алгоритм всегда использует последние 100 наблюдений для прогнозирования следующих 100 шагов. Прогноз смог успешно предсказать тенденцию, и мы могли использовать это как предупреждение о неисправности батареи. Цифры не будут точными на 100%, но прогноз не обязательно должен соответствовать точному количеству, но должен быть похож на тенденцию, чтобы можно было принять меры по предотвращению отказа батареи.
Рисунок 6. Прогноз с использованием модели авторегрессии, рассчитанный с помощью AWS LambdaОбучение
Целью этого экспериментального проекта была разработка масштабируемого приложения для анализа данных с использованием данных моделирования. Такой подход поддерживает проекты машинного обучения на ранней стадии, когда реальных данных мало или их трудно найти. Благодаря использованию облачной инфраструктуры сложные приложения машинного обучения легко развертывать. Благодаря облаку мы могли легко расширить это с помощью приложений, которые потребляют поток данных моделирования.Кроме того, мы показали, что использование данных моделирования полезно для создания прототипов машинного обучения.
Как специалист по данным, я теперь мог тестировать другие методы прогнозирования, такие как скользящее среднее, ARIMA или даже глубокое обучение, используя те же данные, которые мы только что сгенерировали при моделировании. И даже протестируйте их бок о бок и сравните результаты в Quicksight.
Мы считаем, что на ранних этапах проектов машинного обучения / науки о данных моделирование может поддержать принятие решений в отношении выбора источников данных, методов искусственного интеллекта и составления бюджета.
.