Google BigQuery — зачем нужна облачная база данных
Ранее я публиковал цикл материалов о работе с Google BigQuery. В этой статье расскажу о преимуществах и особенностях сервиса, а также о дополнительных инструментах для BigQuery.
Google BigQuery — это облачная база данных с высочайшей скоростью обработки огромных массивов данных.
Как начать работу в Google BigQuery
Войдите в Google Cloud Platform. При первом запуске система предложит активировать бесплатный пробный период и получить кредит $300 на 12 месяцев. Честно говоря, чтобы потратить за год в BigQuery эту сумму, вам придется очень сильно постараться.
Для дальнейшей работы введите платежные данные.
Нажмите «Выбрать проект».
Затем — «Создать проект».
Примите условия использования платформы.
Наконец, назовите проект, задайте настройки уведомлений и еще раз согласитесь с условиями использования платформы.
После подтверждения подождите несколько минут.
Вскоре вы получите оповещение, что проект создан.
Перейдите в раздел оплаты и привяжите платежный аккаунт.
Теперь проект привязан к только что созданному платежному аккаунту.
Перейдите в интерфейс Google BigQuery и напишите свой первый запрос.
Чтобы открыть редактор запросов, нажмите «Compose query» или сочетание клавиш «Ctrl + Space».
Рассмотрим, как написать первый запрос на примере публичных данных в BigQuery. Возьмите первые 15 строк из таблицы project_tycho_reports, которая находится в наборе публичных данных lookerdata.
SELECT *FROM [lookerdata:cdc.project_tycho_reports]LIMIT 25Запрос вернет результат:
Ранее я описывал самые простые способы загрузки собственных данных в Google BigQuery, а в этой статье расскажу, как загрузить данные с помощью языка R. Но перед этим разберем важный вопрос.
{«0»:{«lid»:»1573230077755″,»ls»:»10″,»loff»:»»,»li_type»:»em»,»li_name»:»email»,»li_ph»:»Email»,»li_req»:»y»,»li_nm»:»email»},»1″:{«lid»:»1596820612019″,»ls»:»20″,»loff»:»»,»li_type»:»hd»,»li_name»:»country_code»,»li_nm»:»country_code»}}
Истории бизнеса и полезные фишки
Почему стоит выбрать именно Google BigQuery
Скорость — это основное преимущество BigQuery, но не единственное. BigQuery — облачный сервис. При его использовании не понадобится арендовать сервер и оплачивать поддержку.
BigQuery — облачный сервис. При его использовании не понадобится арендовать сервер и оплачивать поддержку.
Стоимость BigQuery значительно ниже стоимости аренды самого примитивного сервера: даже если вы очень постараетесь и будете ежедневно записывать в эту базу данных миллионы строк, все равно вряд ли сможете потратить более $5.
Следующее преимущество — простота использования. В любой другой системе управления базами данных (СУБД) помимо знания SQL придется долго разбираться с тонкостями администрирования и настройками базы.
И если сам по себе SQL-диалект во всех базах данных очень похожий, то административная часть, как правило, везде устроена по-разному.
У BigQuery всю административную часть на себя взял Google. В этом сервисе нет никаких настроек, индексов, движков таблиц, тайм-аутов или внешних ключей. Реализована поддержка только одной кодировки UTF-8.
Для работы с BigQuery достаточно знать, как загрузить данные в BigQuery, и иметь базовые знания в SQL.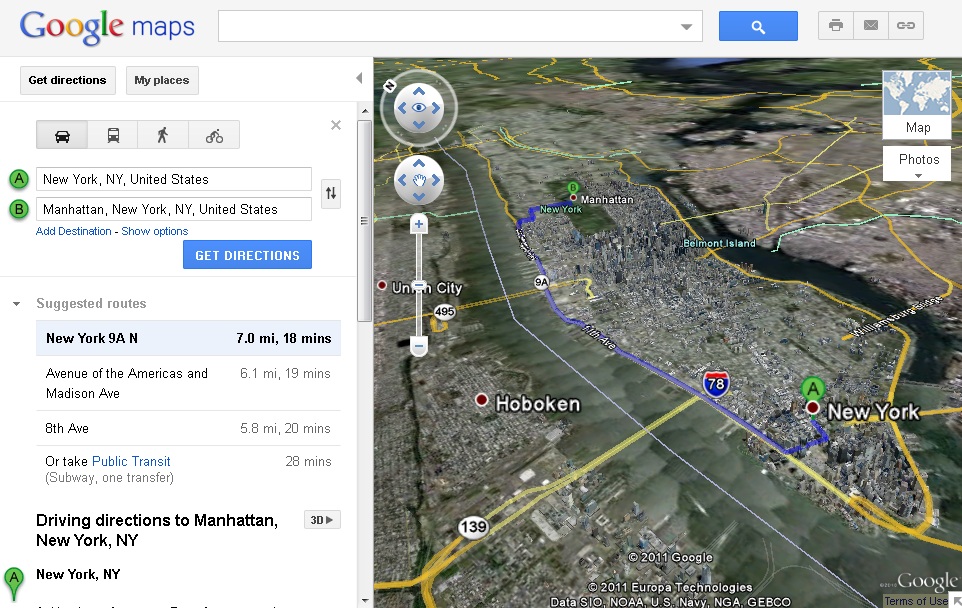
Несмотря на простоту, в BigQuery реализована поддержка практически всех функций СУБД:
Правда, на момент публикации статьи сервис не поддерживает:
- рекурсивные запросы;
- создание хранимых процедур и функций;
- транзакции.
Особенности SQL для Google BigQuery
BigQuery умеет переключаться между стандартным SQL и диалектами.
DML-операции INSERT, UPDATE и DELETE на данный момент поддерживаются только при использовании стандартного SQL.
Еще одно отличие между этими диалектами — способ вертикального объединения таблиц. В стандартном SQL для этого служит оператор UNION и ключевое слов ALL или DISTINCT:
SELECT 12 AS A, 32 AS BUNION ALLSELECT 2 AS A, 29 AS BВ собственном SQL-диалекте функционал для вертикального объединения таблиц значительно шире. Существует специальный набор функций подстановки таблиц (Table Wildcard Functions).
Этот способ объединения таблиц я уже подробно описывал ранее.
Для простого объединения достаточно просто перечислить названия нужных таблиц или подзапросы через запятую. Объединение запросов из примера выше на внутреннем диалекте SQL в BigQuery будет выглядеть так:
Объединение запросов из примера выше на внутреннем диалекте SQL в BigQuery будет выглядеть так:
SELECT *FROM (SELECT 12 AS A, 32 AS B), (SELECT 2 AS A, 29 AS B)Переключатель между SQL-диалектами в BigQuery находится в интерфейсе в блоке опций: нажмите кнопку Show options под редактором запросов.
С помощью галочки «SQL Dialect» переключитесь на нужный диалект.
Инструменты для работы с BigQuery
Мы уже разобрались, как загружать данные в базу и как обращаться к данным SQL запросами. Но вряд ли вы хотите взаимодействовать с данными, ограничившись этими возможностями. Скорее всего, вы загружаете данные для построения дашбордов или чего-то подобного.
Как получить данные в различных BI платформах, я писал в статьях об интеграции с электронными таблицами и Microsoft Power BI.
Microsoft Power BI, как и большинство популярных BI-систем и электронных таблиц, с июля 2017 года поддерживает интеграцию с Google BigQuery из коробки. У коннектора довольно скудные возможности: он не умеет обращаться к сохраненным представлениям или отправлять в BigQuery запросы. Пока что с помощью встроенного коннектора можно вытягивать только плоские таблицы.
У коннектора довольно скудные возможности: он не умеет обращаться к сохраненным представлениям или отправлять в BigQuery запросы. Пока что с помощью встроенного коннектора можно вытягивать только плоские таблицы.
Simba Drivers
Если вам необходимо получить данные из Google BigQuery в электронной таблице или BI-системе, которая из коробки не поддерживает интеграцию, воспользуйтесь бесплатным Simba Drivers.
Этот драйвер поддерживает все необходимые возможности, включая переключения SQL-диалектов. Подробности настройки ищите в моей статье о связке Microsoft Power BI и Google BigQuery.
Язык R
Язык R — один из самых мощных инструментов для работы с данными. Он умеет как получать данные из Google BigQuery, так и записывать их. Для этого удобнее всего пакет bigrquery.
Для начала установите язык R. Также для удобства работы с R я рекомендую установить интегрированную среду разработки RStudio.
Запустите RStudio и с помощью сочетания клавиш «Ctrl+Alt+Shift+0» откройте все доступные в ней панели. Чаще всего понадобятся панели Source и Console.
Чаще всего понадобятся панели Source и Console.
Для установки develop-версии пакета bigrquery из репозитория на GitHub предварительно установите пакет devtools. Введите в окно Source код, затем выделите его (зажмите левой кнопки мыши) и нажмите «Ctrl+Enter» для выполнения команды:
install.packages("devtools")Теперь установите пакет bigrquery:
devtools::install_github("rstats-db/bigrquery")Чтобы в R были доступны функции пакета, после установки подключите их с помощью команды library или require. Например, подключим пакет bigrquery с помощью кода:
library(bigrquery)Структура данных в Google BigQuery состоит из проекта с набором данных, содержащим таблицы. Проект вы уже создали, а теперь для передачи информации создайте набор данных. Выберите в интерфейсе из выпадающего меню «Create new dataset».
Чтобы создать набор данных с помощью языка R, воспользуйтесь командой insert_dataset. Команда требует всего 2 аргумента:
Команда требует всего 2 аргумента:
project — ID проекта (возьмите из URL в BigQuery).
dataset — название нового набора данных.
Давайте создадим первый набор данных с названием myFirstDataSet. Введите в область Source приведенный ниже код, выделите команду с помощью мыши и нажмите «Ctrl+Enter» для выполнения.
insert_dataset(project = "myfirstproject-185308", dataset = "myFirstDataSet")В окне Console в RStudio появится запрос о создании учетных данных, чтобы в дальнейшем не требовалась повторная аутентификация.
Введите на запрос Selection в Console ответ Yes и нажмите Enter. Откроется браузер — разрешите доступ к данным и получите авторизационный код.
Скопируйте сгенерированный код. Затем вставьте его в Console RStudio в ответ на запрос авторизационного кода и нажмите Enter.
Отлично, вы создали набор данных.
Теперь запишите встроенную в R таблицу mtcars в набор данных myFirstDataSet. Для передачи данных из R в BigQuery в пакете bigrquery есть функция insert_upload_job. Она принимает такие аргументы:
Для передачи данных из R в BigQuery в пакете bigrquery есть функция insert_upload_job. Она принимает такие аргументы:
project — ID проекта (смотрите либо в URL проекта, либо в режиме переключения проектов).
dataset — название набора данных, куда вы планируете отправить данные. В нашем случае myFirstDataSet.
table — название таблицы с записанными данными.
values — data frame (таблица данных) в R с данными для передачи в BigQuery.
billing = project аккаунта для оплаты операции. По умолчанию — платежный аккаунт, который привязан к проекту.
create_disposition — опция для определения необходимых действий.
Если в BigQuery нет таблицы с заданным в аргументе table названием, укажите «CREATE_IF_NEEDED» — система создаст новую таблицу.
Если указать «CREATE_NEVER» и таблица с заданным именем не найдется в наборе данных, будет возвращена соответствующая ошибка.
write_disposition — опция для выбора добавления данных в существующую таблицу.
«WRITE_APPEND» — дописать данные в таблицу.
«WRITE_TRUNCATE» — перезаписать данные в таблице.
«WRITE_EMPTY» — записать данные для пустой таблицы.
Код для передачи в BigQuery встроенной в R таблицы mtcars:
insert_upload_job(project = "myfirstproject-185308", dataset = "myFirstDataSet", table = "mtcars_bigquery", values = mtcars, create_disposition = "CREATE_IF_NEEDED", write_disposition = "WRITE_APPEND")При успешном выполнении операции в консоли R появится дополнительная информация, а в интерфейсе BigQuery — созданная таблица mtcars_bigquery.
Для запроса данных из BigQuery в R в пакете bigrquery предназначена функция query_exec. Основные аргументы:
query — текст SQL-запроса, результат которого вы хотите загрузить в R.
project — ID проекта для запроса данных.
page_size — максимальный размер возвращаемого результата в строках (по умолчанию 10 000).
max_pages — максимальное количество страниц возврата запросом (по умолчанию 10).
use_legacy_sql — выбор SQL-диалекта для обработки запроса.
По умолчанию задано значение TRUE с внутренним диалектом BigQuery.
Для стандартного диалекта SQL задайте в этом аргументе значение FALSE.
Для обратного запроса данных, которые вы отправили в BigQuery на прошлом шаге, задайте команду:
bq_mtcars_table <- query_exec(query = "SELECT * FROM myFirstDataSet.mtcars_bigquery", project = "myfirstproject-185308", use_legacy_sql = TRUE)В рабочем окружении (описание которого вы видите в окне Environment) появится новый объект bq_mtcars_table.
Выводы
Google BigQuery — простой и в то же время мощнейший инструмент для хранения и обработки данных. Это облачная база данных с поддержкой большинства функций СУБД.
Это облачная база данных с поддержкой большинства функций СУБД.
Сервис обходится значительно дешевле содержания, поддержки и администрирования сервера для бесплатных баз данных (MySQL или PostgreSQL).
Надеюсь, мой цикл инструкций для начала работы с Google BigQuery упростит ваши будни.
Успехов в работе с большими данными!
Какую базу данных использует Google?
Большой стол
Распределенная система хранения структурированных данных
Bigtable — это распределенная система хранения (созданная Google) для управления структурированными данными, которая рассчитана на масштабирование до очень большого размера: петабайты данных на тысячах обычных серверов.
Многие проекты в Google хранят данные в Bigtable, включая веб-индексацию, Google Earth и Google Finance. Эти приложения предъявляют к Bigtable очень разные требования, как с точки зрения размера данных (от URL-адресов к веб-страницам до спутниковых изображений), так и требований к задержке (от массовой обработки на сервере до обработки данных в реальном времени).
Несмотря на эти разнообразные требования, Bigtable успешно предоставил гибкое, высокопроизводительное решение для всех этих продуктов Google.
Некоторые особенности
- быстрая и чрезвычайно масштабная СУБД
- разреженная, распределенная многомерная отсортированная карта, разделяющая характеристики как ориентированных на строки, так и ориентированных на столбцы баз данных.
- предназначен для масштабирования в петабайтный диапазон
- он работает на сотнях или тысячах машин
- легко добавить больше компьютеров в систему и автоматически начать использовать эти ресурсы без какой-либо реконфигурации
- каждая таблица имеет несколько измерений (одно из которых является полем для времени, позволяющим управлять версиями)
- Таблицы оптимизированы для GFS (файловой системы Google), поскольку они разбиты на несколько планшетов — сегменты таблицы разделены по выбранной строке таким образом, что размер планшета составит ~ 200 мегабайт.
Архитектура
BigTable не является реляционной базой данных. Он не поддерживает объединения и не поддерживает расширенные SQL-подобные запросы. Каждая таблица представляет собой многомерную разреженную карту. Таблицы состоят из строк и столбцов, и каждая ячейка имеет метку времени. Может быть несколько версий ячейки с разными отметками времени. Отметка времени позволяет выполнять такие операции, как «выбрать ‘n’ версии этой веб-страницы» или «удалить ячейки, которые старше определенной даты / времени».
Чтобы управлять огромными таблицами, Bigtable разделяет таблицы по границам строк и сохраняет их как планшеты. Планшет занимает около 200 МБ, а каждая машина экономит около 100 планшетов. Эта настройка позволяет распределять планшеты из одной таблицы между многими серверами. Это также учитывает мелкозернистую балансировку нагрузки. Если одна таблица получает много запросов, она может сбросить другие планшеты или перенести занятую таблицу на другой компьютер, который не так занят.
Таблицы хранятся как неизменяемые SSTables и хвост журналов (один журнал на машину). Когда машине не хватает системной памяти, она сжимает некоторые планшеты, используя собственные методы сжатия Google (BMDiff и Zippy). Незначительные уплотнения включают только несколько планшетов, в то время как крупные уплотнения включают всю систему таблиц и занимают место на жестком диске.
Расположение планшетов Bigtable хранится в клетках. Поиск любого конкретного планшета обрабатывается трехуровневой системой. Клиенты получают точку в таблице META0, из которых только одна. Таблица META0 отслеживает многие планшеты META1, которые содержат местоположения просматриваемых планшетов. В META0 и META1 интенсивно используются предварительная выборка и кэширование, чтобы минимизировать узкие места в системе.
Реализация
BigTable построен на файловой системе Google (GFS), которая используется в качестве резервного хранилища для файлов журналов и данных.
Другим сервисом, который BigTable активно использует, является Chubby , высокодоступный, надежный сервис распределенных блокировок. Chubby позволяет клиентам захватить блокировку, возможно, связав ее с некоторыми метаданными, которые он может обновить, отправив сообщения о том, что они активны, обратно в Chubby. Блокировки хранятся в иерархической структуре именования в виде файловой системы.
В системе Bigtable интерес представляют три основных типа серверов :
- Главные серверы: назначайте планшеты планшетным серверам, отслеживайте расположение планшетов и перераспределяйте задачи по мере необходимости.
- Планшетные серверы: обрабатывают запросы на чтение / запись для планшетов и разделенных планшетов, когда они превышают предельные размеры (обычно 100–200 МБ). Если происходит сбой планшетного сервера, то на 100 планшетных серверах каждый подхватывает 1 новый планшет, и система восстанавливается.
- Блокировка серверов: экземпляры службы распределенной блокировки Chubby. Множество действий в BigTable требует приобретения замков, включая открытие планшетов для записи, обеспечение того, чтобы одновременно было не более одного активного мастера, и проверку контроля доступа.
Пример из исследовательской работы Google:
Часть примера таблицы, в которой хранятся веб-страницы. Имя строки — это обратный URL . Семейство столбцов содержимого содержит содержимое страницы , а семейство столбцов привязки содержит текст любых привязок, которые ссылаются на страницу. На домашнюю страницу CNN ссылаются как домашние страницы Sports Illustrated, так и домашние страницы MY-look, поэтому строка содержит столбцы с именами
anchor:cnnsi.comи anchor:my.look.ca. Каждая якорная ячейка имеет одну версию ; столбец содержание имеет три версии , на временные меткиt3,t5иt6.
API
Типичными операциями для BigTable являются создание и удаление таблиц и семейств столбцов, запись данных и удаление столбцов из строки. BigTable предоставляет эти функции разработчикам приложений в API. Транзакции поддерживаются на уровне строк, но не для нескольких ключей строк.
Вот ссылка на PDF исследовательской работы .
Базы данных в Google Cloud оказались открыты для любых пользователей
Безопасность Интернет | ПоделитьсяВ Google Cloud131 из 2064 баз данных (бакетов) настроены неправильно, поэтому их
содержимое доступно всем желающим.
Более 6% бакетов (баз данных) Google Cloud настроены некорректно, и их содержимое доступно всем желающим, утверждает фирма Comparitech после изучения свыше 2 тыс. таких ресурсов.
Эксперты компании обнаружили более 6 тыс. сканированных документов, включая паспорта, свидетельства о рождении и другие персональные данные детей из Индии. Еще одна общедоступная база данных принадлежала российскому веб-девелоперу; в ней хранились реквизиты доступа к почтовому серверу и чат-логи.
Исследователи также обнаружили в таких бакетах исходный код к ПО, реквизиты доступа к другим ресурсам и другие сугубо конфиденциальные данные.
Как отметил исследователь Comparitech Пол
Бишофф (Paul Bischoff), найти незащищенные базы данных проще простого.
У Google есть
правила наименования для бакетов в облачных ресурсах: они должны содержать от 3
до 63 символов — чисел, прописных букв, дефисов, подчеркиваний и точек.![]() Плюс
названия должны начинаться и заканчиваться с буквы или цифры.
Плюс
названия должны начинаться и заканчиваться с буквы или цифры.
Comparitech воспользовался общедоступным инструментом для сканирования сети для изучения доменных имен 100 топовых сайтов в рейтинге Alexa в комбинации с распространенными словами, которые чаще всего используют для наименования баз данных — «bak», «db», «database» и «users». В итоге за 2,5 часа им удалось обнаружить 2064 базы, из которых 131 оказались уязвимы.
До 6% баз данных в облаке Google пускают всех желающих
«Незащищенные базы данных выявляются регулярно, нередко уже после утечек с последствиями на миллионы валютных единиц, — говорит Дмитрий Кирюхин, эксперт по информационной безопасности компании SEC Consult Services. — Чаще всего страдают базы ElasticSearch и Amazon, но некорректность настройки защиты мало зависит от того, кто разрабатывал базу данных или облачный сервер. Как правило, это именно человеческий фактор».
Роман Георгиев
Какую базу данных использует Google?
С BigTable
Распределенная система хранения структурированных данных
Bigtable-это распределенная система хранения (созданная Google) для управления структурированными данными , которая предназначена для масштабирования до очень большого размера: петабайты данных на тысячах товарных серверов.
Многие проекты в Google хранят данные в Bigtable, включая веб-индексацию, Google Earth и Google Finance. Эти приложения предъявляют очень разные требования к Bigtable, как с точки зрения размера данных (от URLs до web страниц на спутниковые снимки) и требования к задержке (от бэкэнд -массовой обработки до обслуживания данных в режиме реального времени ).
Несмотря на эти разнообразные требования, Bigtable успешно предоставлено гибкое, высокопроизводительное решение для всех этих задач Google продукты.

Некоторые особенности
- быстрый и чрезвычайно масштабный DBMS
- разреженная, распределенная многомерная сортированная карта, разделяющая характеристики как ориентированных на строки, так и ориентированных на столбцы баз данных.
- предназначен для масштабирования в диапазоне петабайт
- он работает на сотнях или тысячах машин
- легко добавить больше машин в систему и автоматически начать использовать эти ресурсы без какой-либо реконфигурации
- каждая таблица имеет несколько измерений (одно из которых является полем для времени, позволяющим управлять версиями)
- таблицы оптимизируются для GFS (файловая система Google) путем разделения на несколько планшетов — сегментов таблицы, разделенных вдоль строки, выбранной таким образом, чтобы размер планшета составлял ~200 мегабайт.

Архитектура
BigTable — это не реляционная база данных. Он не поддерживает соединения и не поддерживает rich SQL-подобные запросы. Каждая таблица представляет собой многомерную разреженную карту. Таблицы состоят из строк и столбцов, и каждая ячейка имеет отметку времени. Существует несколько версий ячейки с разными отметками времени. Отметка времени позволяет выполнять такие операции, как» выбор ‘n’ версий этой веб-страницы » или » удаление ячеек, которые старше определенного date/time.»
Чтобы управлять огромными таблицами, Bigtable разбивает таблицы на границы строк и сохраняет их в виде планшетов. Таблетка составляет около 200 MB, и каждая машина экономит около 100 таблеток. Эта настройка позволяет распределять планшеты с одного стола по многим серверам. Он также позволяет осуществлять мелкозернистую балансировку нагрузки. Если одна таблица получает много запросов, она может сбросить другие планшеты или переместить занятую таблицу на другую машину, которая не так занята. Кроме того, если машина выходит из строя, планшет может быть распределен по многим другим серверам, так что влияние на производительность любой данной машины будет минимальным.
Кроме того, если машина выходит из строя, планшет может быть распределен по многим другим серверам, так что влияние на производительность любой данной машины будет минимальным.
Таблицы хранятся как неизменяемые SSTables и хвост журналов (по одному журналу на машину). Когда у машины заканчивается системная память, она сжимает некоторые планшеты с помощью фирменных методов сжатия Google (BMDiff и Zippy). Незначительные уплотнения включают в себя только несколько таблеток, в то время как основные уплотнения включают в себя всю систему таблиц и восстановление места на жестком диске.
Расположение таблеток Bigtable хранится в ячейках. Поиск любого конкретного планшета осуществляется с помощью трехуровневой системы. Клиенты получают точку в таблице META0, из которой существует только одна. Таблица META0 отслеживает множество таблеток META1, которые содержат местоположения просматриваемых таблеток. И META0, и META1 активно используют предварительную выборку и кэширование, чтобы минимизировать узкие места в системе.
Реализация
BigTable построен на базе файловой системы Google (GFS), которая используется в качестве резервного хранилища для файлов журналов и данных. GFS обеспечивает надежное хранение для SSTables, проприетарного формата файлов Google, используемого для сохранения табличных данных.
Еще одна услуга, которой активно пользуется BigTable, — это Chubby, высокодоступная и надежная служба распределенных блокировок. Chubby позволяет клиентам снимать блокировку, возможно, связывая ее с некоторыми метаданными, которые он может обновить, отправив сообщения keep alive обратно Chubby. Блокировки хранятся в иерархической структуре именования, подобной файловой системе.
В системе Bigtable существует три основных типа серверов , представляющих интерес:
- Мастер-серверы: назначает планшеты на планшетные серверы, отслеживает, где находятся планшеты, и перераспределяет задачи по мере необходимости.
- Планшетные серверы: обрабатывают запросы на чтение/запись для планшетов и разделенных планшетов, когда они превышают предельные размеры (обычно 100 МБ-200 МБ). Если планшетный сервер выходит из строя, то 100 планшетных серверов каждый забирают 1 новый планшет, и система восстанавливается.
- Серверы блокировки: экземпляры службы распределенной блокировки Chubby. Многие действия в BigTable требуют приобретения замков, включая открытие планшетов для записи, обеспечение того, чтобы одновременно было не более одного активного Мастера, и проверку контроля доступа.
Пример из исследовательской работы Google:
Фрагмент примерной таблицы, в которой хранятся веб-страницы. Имя строки — перевернутое URL . Семейство столбцов contents содержит содержимое страницы, а семейство столбцов anchor содержит текст любых якорей , ссылающихся на страницу. Главная страница CNN это ссылается и «Спортс Иллюстрейтед» и MY-посмотрите домашние страницы, чтобы строка содержала столбцы с именем
anchor:cnnsi.иcom
anchor:my.look.ca. Каждая Якорная ячейка имеет одну версию; столбец содержимого имеет три версии, по временным меткамt3,t5,t6, а .
API
Типичными операциями для BigTable являются создание и удаление таблиц и семейств столбцов, запись данных и удаление столбцов из строки. BigTable предоставляет эти функции разработчикам приложений в API. Транзакции поддерживаются на уровне строк, но не через несколько ключей строк.
Вот ссылка на PDF исследовательской работы .
А здесь вы можете найти видео, на котором Джефф Дин из Google выступает с лекцией в Вашингтонском университете, обсуждая систему хранения контента Bigtable, используемую в бэкэнде Google.
Можно ли использовать Google Диск в качестве базы данных? Oh! Android
Могу ли я использовать Google Диск в качестве базы данных пользователей?
Мне нужно личное хранилище базы данных онлайн для каждого пользователя моего приложения.
Например, пользователю 1 необходимо сохранить записи в таблице базы данных со списком его онлайн-собраний.
Пользователь 2 также должен хранить записи в аналогичной таблице. Ни один пользователь не должен видеть записи друг друга.
Google Drive предоставляет разработчикам доступ к папке приложения: https://developers.google.com/drive/android/appfolder
В документации указано, что приложение Folder может использоваться для хранения файлов конфигурации, временных файлов или любых других типов файлов, принадлежащих пользователю, но их не следует подделывать.
Я рад создать файловую базу данных, которая либо имеет один файл, чтобы представлять всю таблицу базы данных (в данном случае все собрания), либо один файл в строке таблицы базы данных (одно собрание).
Это что-то, что я могу хранить в папке приложения Google Диска?
Я понимаю, что в приложении Drive API есть квота, но это кажется очень высоким и не запретительным.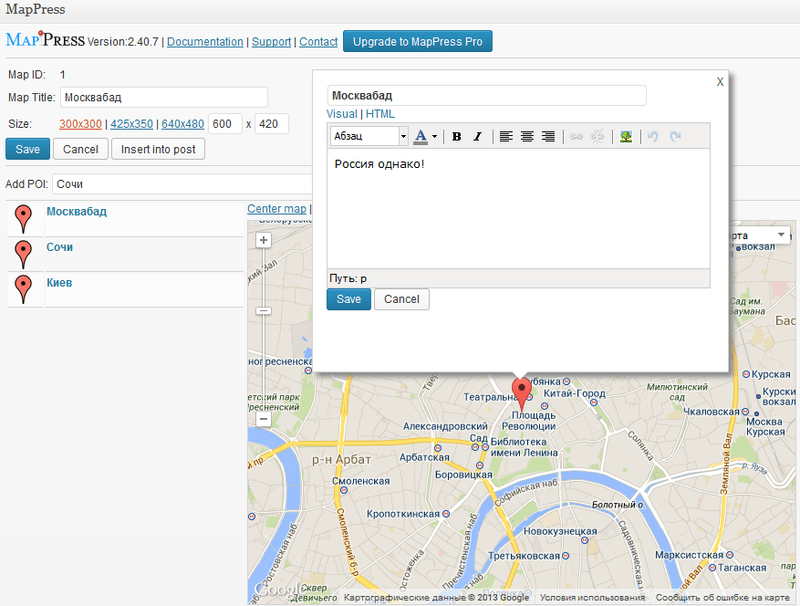 Для хранения файлов, которые мне нужны, у самих пользователей должно быть достаточно онлайн-хранилища на Google Диске. Я также изучаю Firebase, но Google Диск был бы намного более дешевым решением и хорошо понятным для потенциальных пользователей.
Для хранения файлов, которые мне нужны, у самих пользователей должно быть достаточно онлайн-хранилища на Google Диске. Я также изучаю Firebase, но Google Диск был бы намного более дешевым решением и хорошо понятным для потенциальных пользователей.
Да, это возможно. Он будет работать нормально, потому что каждый пользователь имеет свои собственные данные на своем собственном диске. Вы можете хранить как можно больше данных в этой специальной папке, если оно не заполняет всю квоту накопителя.
Лично я сделал это, используя таблицы для моей «базы данных». Я не запрашиваю непосредственно таблицу. Вместо этого я инкрементально синхронизирую его с локальной БД на устройстве и читаю только начиная с последней строки, которую я синхронизировал последним. Очень быстрая синхронизация.
Вы не говорите, где работает ваше приложение, но на рабочем столе Chrome у вас даже есть синхронизация файловой системы Chrome, которая хранится на диске пользователя и автоматически синхронизируется с другими хромированными устройствами.
Кодовая база Google включает 2 млрд. строк и 86 Тбайт
Google, Интернет-гигант и величайшее собрание данных — эти два связанных друг с другом термина раскрывают сущность провайдера поисковой системы и крупнейшей Интернет-компании. Но помимо доменов и поиска, Google распространяет свою деятельность практически на все сферы Интернета. Для того, чтобы объединить всё это, ряд направлений были выделены в Alphabet.
Статистика кодовой базы GoogleПредставлены конкретные цифры, отражающие результаты деятельности Google в цифровой сфере, плодами которой пользуются миллиарды людей. На конференции Scale Engineering их огласила Потвон Рейчел. Все сервисы Google включают кодовую базу из 2 миллиардов строк. Размер данных в базе данных — 86 Tбайт. Кодовая база включает в себя миллиард файлов, среди которых 9 млн. исходных файлов. Ежедневно совершается 45.000 операций Commit, таким образом, всего за всю историю их насчитывается 35 млн. Эти данные получены к январю 2015 года.
Кодовой базой пользуются около 95 процентов сотрудников Google, а это порядка 25.000 инженеров программного обеспечения. Репозиторий Google является самым активно используемым в мире. Для того, чтобы представить, что такое 2 млрд. строк кода, можно сравнить это с ядром Linux, которое включает в себя более 40.000 файлов и 15 млн. строк кода. 45.000 операций Commit ежедневно находят своё отражение в 15 млн. строках кода и изменениях более чем 250.000 файлов. Архив размером 86 Tбайт располагается одновременно в 10 ЦОД Google, которые постоянно синхронизируются друг с другом. Таким образом Google обеспечивает безопасность данных и быстрый доступ для разработчиков — не важно, где бы они не находились.
>Статистика кодовой базы GoogleВ настоящее время экспоненциально растёт не только число Commit, но и размер файлов в репозитории. Google держит общую кодовую базу «под одной крышей» и предоставляет её разработчикам с одной целью: это позволяет связать отдельные части кода Google и поддерживать взаимодействие сервисов. Создавать новые проекты и достигать определённых целей становится легче. Изменения в кодовой базе влияют на все проекты, которые используют её.
Создавать новые проекты и достигать определённых целей становится легче. Изменения в кодовой базе влияют на все проекты, которые используют её.
Google всех посчитает и внесет в базу данных Компания Google запустила один за другим cервисы Google Analytics и Google Base: Интернет и СМИ: Lenta.ru
В середине ноября компания Google запустила один за другим сразу два новых и непохожих друг на друга сервиса — Google Analytics и Google Base. При этом последний широко обсуждался в Сети – за пару недель до его выпуска Google допустил утечку информации, породившую множество слухов и кривотолков о том, каким образом компания хочет достичь своей цели — всемирного информационного господства.
Google Base
Так называемая «База Google», несмотря на внешнее единообразие, на деле представляет собой конгломерат самых разных сервисов, объединенных идеей размещения бесплатных объявлений, картинок и самоценных кусков информации в сети.
Идея, которая заложена в новый сервис, заключается в том, чтобы поделиться с сообществом своей биографией, информацией о товарах, сообщениями о проведении курсов, семинаров, выставок и других мероприятий, и рассказать об интересной страничке, используя возможность составления описания и ключевые слова.
Это очень много, но гораздо меньше, чем можно было ожидать от Google во время утечки информации о Базе. Идеологи Google представляли, что речь пойдет о чем-то, схожим с глобальной библиотекой, дающей возможность разместить в ней все, что захочет человек. При этом в таких рассуждениях речь не заходила о коммерции — предполагалось, что Google будет просто показывать рекламу.
В действительности оказалось, что речь идет о создании скорее не библиотеки, а огромной газеты с объявлениями и интересными публикациями (только в общем случае в базу выкладываются ссылки на интересный ресурс с аннотациями). Google также заявляет, что такие объявления можно использовать в качестве бесплатной рекламы.
Но, конечно, самым хитрым поворотом во всей истории является то, что создатели Базы призывают рекламировать в своей платной системе AdWords бесплатные странички Базы. Что из этого получится — можно только догадываться, ведь тогда рекламодатели фактически будут платить Google за размещение бесплатных объявлений. От оригинальности такой идеи захватывает дух, потому что в случае Google она явно осуществима.
От оригинальности такой идеи захватывает дух, потому что в случае Google она явно осуществима.
Как еще использовать Базу?
Авторы сервиса подразумевали, что поиск в Базе принесет пользу сразу нескольким категориям пользователей. Так, компании и организации смогут размещать пресс-релизы, предприниматели — продавать товары (сейчас поддерживается оплата в долларах, евро и фунта стерлингов), преподаватели — опубликовать информацию о проводимых курсах, вебмастера и журналисты — рассказать об интересных сайтах и статьях…
Позвольте, скажет читатель, — все это я без труда смогу сделать в обычном Интернете — публиковать информацию, продавать товары и уж тем более рассказывать об интересных сайтах. В чем же новизна?
Разница не сразу ощутима, но она есть. Во-первых, по меньшей мере неумно создавать сайт ради размещения нескольких статичных документов — каждый пользователь Google уже имеет в Базе адрес вида base.google.com/base/a/user. Во-вторых, нет никакой гарантии, что ваш сайт появится в Google именно тогда, когда вы захотите и по тем ключевым словам, которые вам нужны. Для этого потребуется помощь колдунов, занимающихся поисковой оптимизацией и «продвижением».
Для этого потребуется помощь колдунов, занимающихся поисковой оптимизацией и «продвижением».
В-третьих, и это концептуальный момент, искать легче структурированную информацию. Степень структурированности записей (items) в Google Base на порядок выше, чем степень структурированности обычной веб-странички, содержащей массу ненужной информации, относящейся к дизайну, навигации, а также не оптимизированной для поисковых систем.
Такая разная информация
Надо думать, что в какой-то момент, когда модель поиска, использующая PageRank, окончательно устарела, возникла необходимость нового подхода к поиску информации. Тогда исследователи Google предположили, что в реальном мире не существует информации вообще – есть информация, выраженная в определенной форме на различных носителях.
Так появилась идея оцифровки книг, создания поисковой системы по видеофайлам, идея поиска адресов, поиска по товарам и печатным каталогам. Ближе всех к универсальной базе данных подошел сервис электронной почты gmail – действительно, его даже использовали в качестве удаленного носителя информации.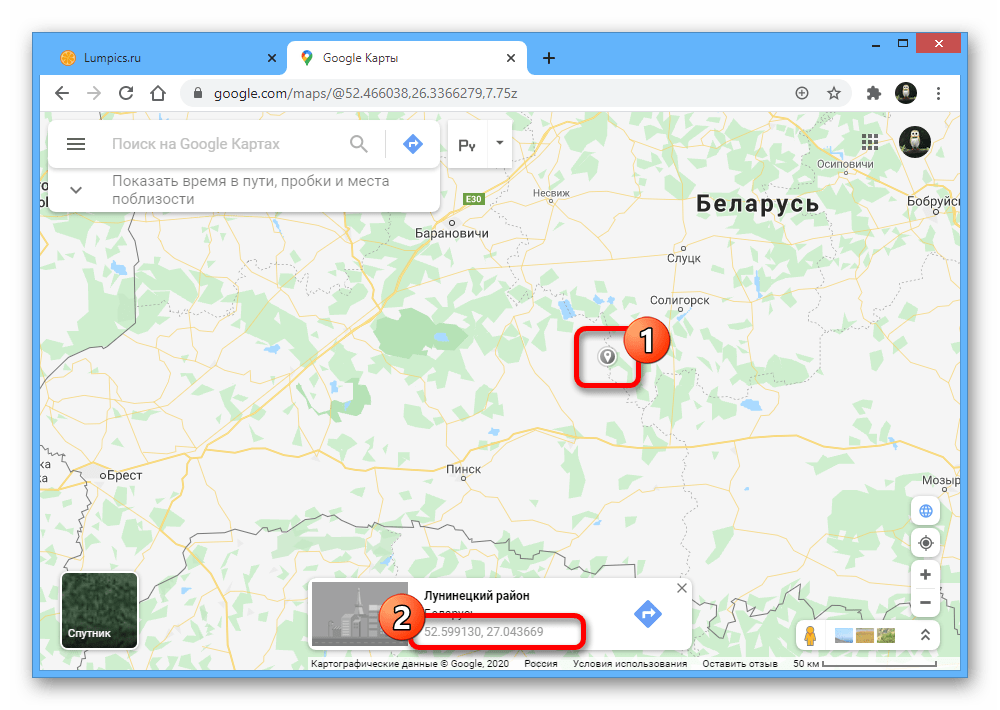 общего диска и общей записной книжки и, например, хостинга для картинок.
общего диска и общей записной книжки и, например, хостинга для картинок.
Следующим шагом стало структурирование содержимого отдельного «почтового ящика» и сведение этого содержимого в единую базу данных. Подобное структурирование позволяет работать в формате, близком к газете бесплатных объявлений и использовать его для эффективного обмена информацией.
В результате этой попытки мухи должны отделиться от котлет — неправильно искать, например, музыку среди базы по автомобильным номерам, а товары — среди объявлений о сдаче квартир.
Плюсы и минусы
К сожалению, в настоящий момент система Google Base почти бесполезна для российских пользователей, так как не поддерживает русские имена категорий и плохо работает с их русским содержимым. Так, например, если в графу education написать «высшее образование», при поиске система встретит вас веселыми квадратиками вместо кириллицы. Нельзя и создать раздел с русским именем.
Google Base пока не позволяет использовать русский язык в полном объеме
Lenta. ru
ru
Кроме того, основа Базы Google состоит в том, чтобы, например, ввести в качестве запроса «hr manager» (кадровик) и получить список вакансий, которые можно отсортировать по типу занятости, удаленности от вашего местоположения (да, База умеет и это), отрасли, в которой предлагается работать. Надо ли говорить, что все это очень плохо работает в русскоязычном варианте Базы.
Есть и еще один недостаток — не всегда можно понять, продается ли, например, автомобиль, внесенный в Базу, или напротив, его хотят купить. К сожалению, уже сейчас в Базе довольно много «мусорных» или малопонятных объявлений, а единственным способом их удаления является ссылка Report Bad Item, которая позволяет пожаловаться на плохую заметку в администрацию. Надо ли говорить, что такие «плохие» заметки могут появляться в будущем сотнями?
Google Analytics
Если Google Base должна принести благо всему человечеству, то сервис Google Analytics, выпущенный поисковиком 14 ноября, должен сэкономить не один доллар рекламодателям и пролиться бальзамом на израненные души вебмастеров – новый сервис представляет собой обыкновенный бесплатный счетчик с необычно большим количеством полезных отчетов по посещаемости сайта.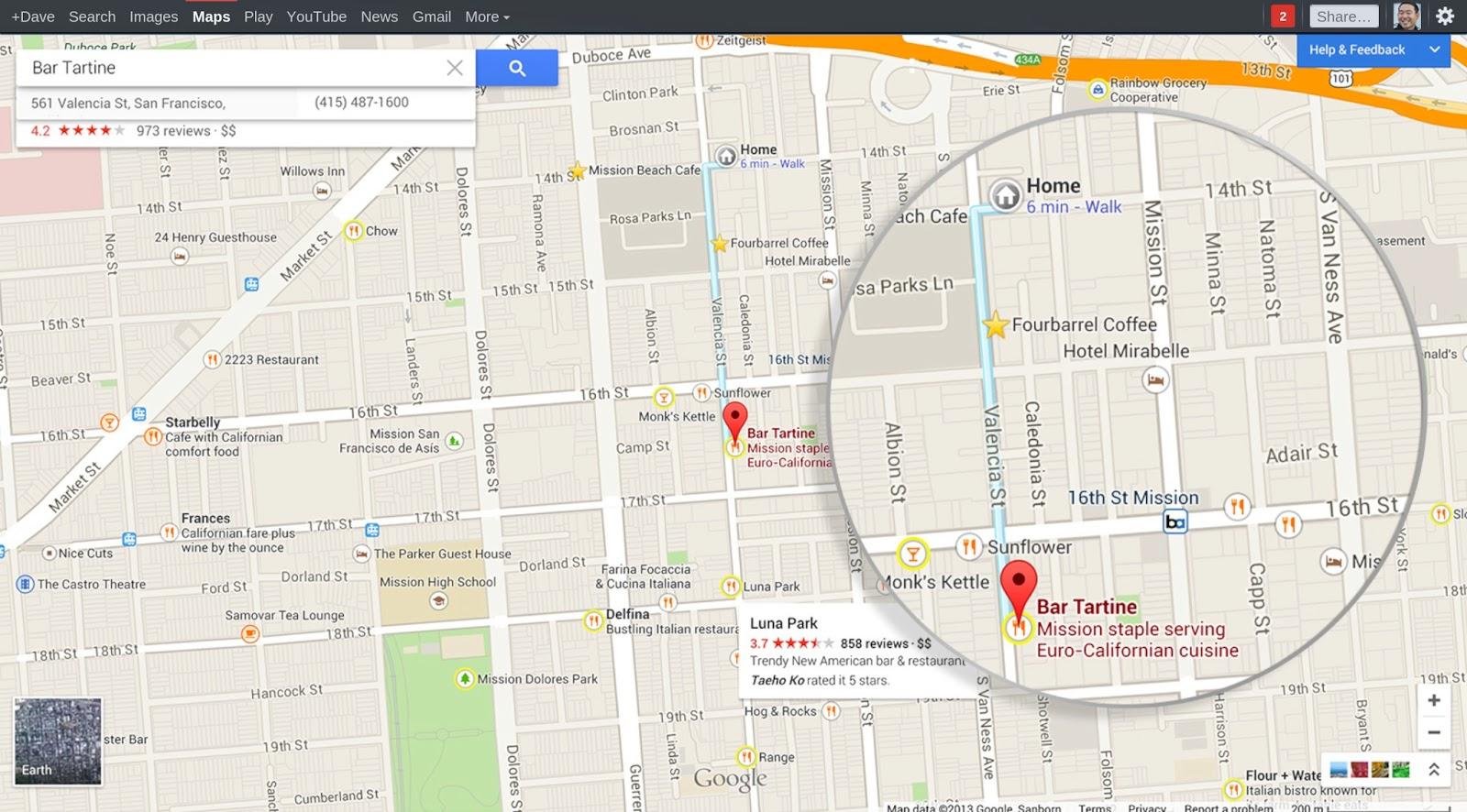
Здесь надо уточнить – Google Analytics должна предоставлять аналитику, однако реально первые отчеты появились лишь ранним утром 17 ноября. В результате среди владельцев сайтов распространились подозрения о том, что новая система будет давать отчеты со значительным опозданием (косвенно это подтверждают и в Google, прося подождать для появления первых отчетов около 12 часов), что значительно снизит ее ценность. Откуда же взялась эта странно неработающая система?
Дело в том, что 28 марта Google приобрел компанию Urchin, предоставлявшую на тот момент платный сервис ведения веб-статистики высокого класса (достаточно сказать, что стоимость подключения к Urchin составляла около 500 долларов). Впоследствии Google снизила стоимость пользования системой до 200 долларов, а вместе с интеграцией в Google Analytics и вовсе сделала ее бесплатной.
Urchin особо известна тем, что ее статистику использовали компании из списка Fortune.
Что же умеет эта система?
Система полностью русифицирована и содержит свыше 50 отчетов, разделенных на три профиля – административный, для специалиста по маркетингу и вебмастера. Из особо интересных отчетов можно упомянуть анализ скорости подключения, наложение посетителей на карту мира (попробовав ее на домашней страничке, вы, например, узнаете, что вас посещал человек из Кемерово), а также интеграцию с рекламной программой Google Adwords, которая позволяет оценить, насколько хорошо работают рекламные объявления (этот отчет обновляется реже остальных – раз в сутки).
Из особо интересных отчетов можно упомянуть анализ скорости подключения, наложение посетителей на карту мира (попробовав ее на домашней страничке, вы, например, узнаете, что вас посещал человек из Кемерово), а также интеграцию с рекламной программой Google Adwords, которая позволяет оценить, насколько хорошо работают рекламные объявления (этот отчет обновляется реже остальных – раз в сутки).
Маркетинговым специалистам будет небезынтересно воспользоваться отчетом «Местоположение в сети», который анализирует, из какого сегмента сети пришел посетитель и сколько денег эта подсеть приносит хозяину сайта в расчете на одно посещение. Ранее возможность получения такой статистики была близка к нулю.
Кроме того, система умеет экспортировать данные посещаемости в текстовый, XML и CSV-форматы. Она в первую очередь нацелена на людей, считающих деньги — в отчетах чаще упоминается не число хостов и хитов, а коэффициент конверсии посетителей в покупателей, отдачи на вложенные средства (ROI) и посещение целевых страниц. Есть даже некий коэффициент «лояльности» посетителей сайта.
Есть даже некий коэффициент «лояльности» посетителей сайта.
Теперь немного о недостатках системы. Во-первых, оценить ее адекватно мешает уже описанное запаздывание с данными. Во-вторых, до сих пор система работает довольно нестабильно — так, некоторым зарегистрированным пользователям не удается в нее войти — их перенаправляют на главную страницу Google (если у вас похожая проблема, есть обходной способ ее решения — нужно войти в любой из сервисов Google, используя свое имя и пароль, а затем перейти на страницу отчетов). Кроме того, на старте были многочисленные проблемы с языками — так, при регистрации не выводился русский вариант пользовательского соглашения, а некоторые части системы помощи просто не находились на сервере.
В целом после Google Analytics, вышедшей не в качестве бета-версии, а готового проекта, остается ощущение сырости и недоработанности. Сейчас она скорее отпугнет рекламодателей, решивших оптимизировать свои расходы.
Заключение
Когда выходит новый продукт от Google, часто можно услышать, что теперь конкуренты знаменитого поисковика должны продавать бизнес, потому что продукт многократно их превосходит по ряду параметров. Несмотря ни на что, пока с рынком ничего страшного не произошло — не закрылись поисковики Yahoo и MSN, поныне здравствуют сотни и тысячи почтовых систем, которым «далеко» до возможностей gmail, живы и здоровы блоггерские сервисы, которых так и не вытеснил принадлежащий Google сайт Blogger.com.
Несмотря ни на что, пока с рынком ничего страшного не произошло — не закрылись поисковики Yahoo и MSN, поныне здравствуют сотни и тысячи почтовых систем, которым «далеко» до возможностей gmail, живы и здоровы блоггерские сервисы, которых так и не вытеснил принадлежащий Google сайт Blogger.com.
Можно предположить, что ничего экстраординарного не произойдет — счетчики, в том числе российские, привязанные к реалиям Рунета, в трубу не вылетят, а Google Base при всех ее достоинствах не заменит российским пользователям газету «Из рук в руки», а американским — знаменитый Craigslist.
Google и раньше выпускал аналоги существующих продуктов — так, например, Google Talk — прямой конкурент более распространенного Skype, а уж, например, перевод страниц целиком существует в Интернете с незапамятных времен.
Чем дальше идет Google по пути захвата рынков, тем чаще у аналитиков возникает вопрос — а требуется ли человечеству упорядочить всю информацию, как это намерен сделать Google?
Успех или провал Google Base подскажут ответ на этот вопрос.
Руководство для начинающих по Google Base / Product Feeds
В мире электронной коммерции, если вы не пользуетесь преимуществами Google Product Feeds / Base, вы упускаете один важный трюк.
Я знаю множество компаний, которым следовало экспериментировать, но они не сделали этого из-за кажущейся сложности системы. Я знаю, что меня сначала оттолкнули.
Кредит изображения
Но это не так уж и плохо, на самом деле мы даже составили руководство для новичков, которое поможет вам осторожно.
Основы
Итак, начнем с самого начала. Google Base — это онлайн-база данных, предоставляемая Google и предоставляющая «значимые структурированные данные». Пользователь может добавлять любой тип онлайн- или офлайн-контента, то есть текст, изображения и структурированную информацию в таких форматах, как XML, PDF, Excel, RTF и Word Perfect.
Если Google сочтет ваш продукт релевантным, он может появиться в поисковой системе покупок, на Картах Google или даже в результатах универсального поиска на обычных страницах веб-поиска Google.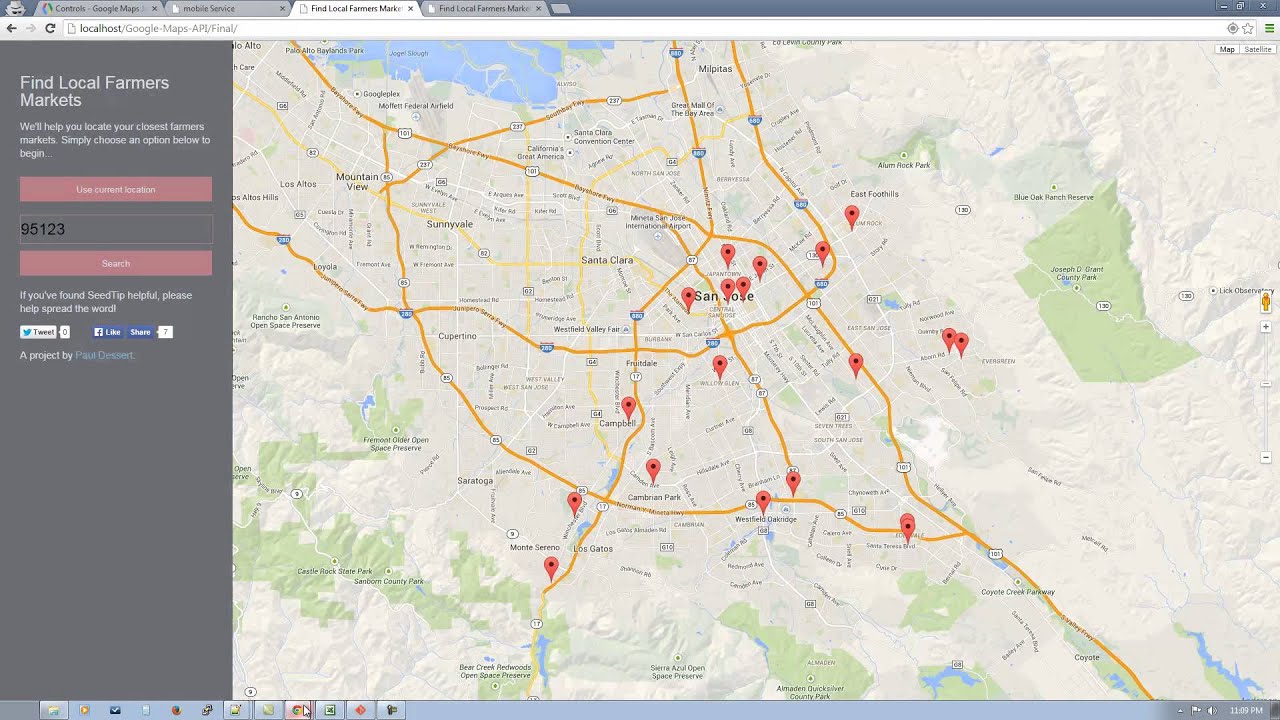
Google Base является бесплатным, а продукты отправляются через каналы данных или API базы данных Google. Недавно он был разделен на Google Base и Google Merchant Center. Google Base теперь используется для мероприятий, вакансий и транспортных средств, а Google Merchant Center — для всего остального.
Чем вам могут помочь Google Base и Google Merchant Center?
Обычно поиск может вызвать небольшое количество списков продуктов Google, и люди могут либо перейти прямо на сайт продавца, либо просмотреть больше похожих продуктов.Если они просматривают больше, они попадают на страницу, где они могут уточнить свой поиск на основе ряда атрибутов, которые пользователи могут указать для продуктов.
Как правило, чем больше информации вы предоставите о продукте, тем лучше. Не каждая компания приложила усилия для того, чтобы представить свои продукты, поэтому часто это может быть отличным способом увеличить объем страницы результатов и расширить бизнес через ваш сайт электронной коммерции.
Если вы занимаетесь производством товаров, вам необходимо зарегистрировать учетную запись Google Merchant Center, чтобы они могли загружать товары.
Здесь можно создать учетную запись
Атрибуты продукта
Вам нужно будет создать список атрибутов для связи с вашими продуктами. Google Merchant Center предоставляет список атрибутов, которые можно связать с любым продуктом, а также вы можете создавать свои собственные атрибуты.
Популярные атрибуты
- название
- марка
- цвет
- номер модели
- состояние
- описание
- id
- ссылка на изображение
- ссылка
- цена
- product_type
- payment_accepted
- расположение
- payment_notes
Вы также можете создать свой собственный таможенный атрибут, вам нужно начинать атрибут с «c:»
Дополнительную информацию об атрибутах можно найти в Google
.
После того, как вы выбрали атрибуты и описали все свои продукты таким образом, вам необходимо загрузить их.
Хотя есть несколько форматов, которые вы можете использовать, XML-документ обычно является самым простым (на самом деле ваша CMS может генерировать его автоматически, поэтому спросите своих разработчиков).
И это основные основы, это может быть намного сложнее, но, надеюсь, это будет хороший 101 урок, который поможет вам начать работу.
Google Base — это бесплатная служба Google , которая помогает публиковать практически любую информацию.Просто опишите свои товары на Base, чтобы людям было как можно проще их находить при поиске. Вы можете использовать фид данных AbleCommerce для импорта всех своих товаров с помощью функции массовой загрузки. Для использования Google Base вам понадобится учетная запись Google. Учетная запись Google позволяет вам входить в Google Base и большинство других сервисов Google. Теперь доступна более новая версия Google Feed. Инструкции по загрузке и установке Обзор процесса подачи данныхКаналы данных — это удобный способ создания нескольких элементов в Google Base. Фидам назначается тип элемента, который классифицирует фид в зависимости от того, какие элементы он содержит. Создав файл, вы загрузите его в Google Base. После обработки файла ваши товары будут добавлены в Google Base. Создать и отправить свой канал с помощью AbleCommerce можно всего за два простых шага: Шаг 1 — Зарегистрируйте поток данных Зарегистрируйте канал в своей учетной записи Google Base.Это позволяет системе Google Base знать, какой файл должен ожидать ваш файл, и какой это тип элемента. Шаг 2. Создайте и загрузите файл фида Google Base После регистрации файла вам необходимо создать и загрузить его в свою учетную запись Google Base. Это делается из AbleCommerce. Ваши элементы будут добавлены в Google Base и появятся в нем после того, как ваш файл будет успешно загружен и обработан. Обычно это занимает до 24 часов. Зарегистрируйте свой фид данныхВыполните следующие действия, чтобы зарегистрировать фид данных.После того, как вы зарегистрируете свой канал, вы можете создать и загрузить его. Google Base будет использовать предоставленную здесь информацию для обработки вашего фида. Ваши товары будут отображаться в Google в зависимости от их релевантности.
Создайте и загрузите файл канала Google BaseПосле того, как вы зарегистрируете свой Google Base Feed, вы можете создать и загрузить его прямо из AbleCommerce.
Для получения дополнительной информации о процессе отправки фида данных посетите Справку Google Base. Устранение проблем с фидом
Обязательные атрибутыАтрибутыопределяют характеристики или качества ваших товаров в Google Base. Каждый атрибут состоит из имени и одного или нескольких значений. Требуемые атрибуты зависят от типа отправляемой информации.AbleCommerce отправляет следующие обязательные и рекомендуемые атрибуты для фида типа Product.
|

Как отслеживать Google Base / Google Product Search с помощью Google Analytics
Google Base и Google Product Search — отличные инструменты, которые могут привлечь релевантный и бесплатный трафик на ваши списки продуктов.
Хотя мы уверены, что все, кто читает, знакомы с потенциальной ценностью этих услуг, мои разговоры с продавцами любого размера заставили меня поверить в то, что существует определенная путаница в отношении наилучшего способа отслеживания трафика из Базы и Поиска товаров с помощью Google Analytics.
Путаница, похоже, не ограничивается только веб-мастерами. Собственная команда Google Base разместила в своем блоге в прошлом году запись, предлагающую следующее:
На первый взгляд может показаться, что отслеживать списки из Google Base было просто.Однако, поскольку базовые списки часто появляются в обычных результатах поиска в Google, бывает сложно различить трафик из двух источников. Один из способов дифференцировать трафик — создать уникальные целевые страницы на вашем веб-сайте специально для базовых списков. Вы можете сделать это, просто создав две версии одной и той же страницы на своем веб-сайте, но дав одной из них немного другое имя. Вот пример:
Обычная целевая страница: http://example.com/page1.html
Уникальная базовая целевая страница: http: // example.ru / page2.html
Создавая две версии одной и той же страницы на вашем веб-сайте и отправив уникальные URL-адреса целевой страницы в Base, Google Analytics может показать вам, сколько именно трафика отправляется на ваш веб-сайт из Base.
Создание отдельных страниц для базового трафика? Это не только займет очень много времени, особенно для продавцов с большим количеством списков продуктов, но и является прямым нарушением рекомендаций Google для веб-мастеров согласно Google и в конечном итоге приведет к снижению естественного поискового трафика / релевантности —
Так что же делать торговцу? К счастью, инженеры, работающие над продуктом Google Analytics, хорошо предвидели и имеют очень простой метод создания пользовательской атрибуции источника в Google Analytics.Просто добавьте эту строку:
&? Utm_source = googlebase & utm_medium = compareshopping
до конца ваших URL-адресов, и Google Analytics сможет отслеживать любой входящий трафик, исходящий из Google Base.
Для получения дополнительной информации о том, как работает UTM Attribution, ознакомьтесь с документацией Google Analytics по вопросам и ответам.
Удачного отслеживания!
| Свойство | Тип | Описание |
|---|---|---|
GOOGLE_APPS_SCRIPT | Enum | Представление типа MIME для проекта скрипта Google Apps. |
GOOGLE_DRAWINGS | Enum | Представление типа MIME для файла Google Drawings. |
GOOGLE_DOCS | Enum | Представление типа MIME для файла Google Документов. |
GOOGLE_FORMS | Enum | Представление типа MIME для файла Google Forms. |
GOOGLE_SHEETS | Enum | Представление типа MIME для файла Google Таблиц. |
GOOGLE_SITES | Enum | Представление типа MIME для файла Сайтов Google. |
GOOGLE_SLIDES | Enum | Представление типа MIME для файла Google Slides. |
FOLDER | Enum | Представление типа MIME для папки Google Диска. |
SHORTCUT | Enum | Представление типа MIME для ярлыка Google Диска. |
BMP | Enum | Представление типа MIME для файла изображения BMP (обычно .bmp). |
GIF | Enum | Представление типа MIME для файла изображения GIF (обычно .gif). |
JPEG | Enum | Представление типа MIME для файла изображения JPEG (обычно .jpg). |
PNG | Enum | Представление типа MIME для файла изображения PNG (обычно.png). |
SVG | Enum | Представление типа MIME для файла изображения SVG (обычно .svg). |
PDF | Enum | Представление типа MIME для файла PDF (обычно .pdf). |
CSS | Enum | Представление типа MIME для текстового файла CSS (обычно .css). |
CSV | Enum | Представление типа MIME для текстового файла CSV (обычно.csv). |
HTML | Enum | Представление типа MIME для текстового файла HTML (обычно .html). |
JAVASCRIPT | Enum | Представление типа MIME для текстового файла JavaScript (обычно .js). |
PLAIN_TEXT | Enum | Представление типа MIME для обычного текстового файла (обычно .txt). |
RTF | Enum | Представление типа MIME для файла с форматированным текстом (обычно .rtf). |
OPENDOCUMENT_GRAPHICS | Enum | Представление типа MIME для графического файла OpenDocument (обычно .odg). |
OPENDOCUMENT_PRESENTATION | Enum | Представление типа MIME для файла презентации OpenDocument (обычно.odp). |
OPENDOCUMENT_SPREADSHEET | Enum | Представление типа MIME для файла электронной таблицы OpenDocument (обычно .ods). |
OPENDOCUMENT_TEXT | Enum | Представление типа MIME для файла текстового процессора OpenDocument (обычно .odt). |
MICROSOFT_EXCEL | Enum | Представление типа MIME для файла электронной таблицы Microsoft Excel (обычно.xlsx). |
MICROSOFT_EXCEL_LEGACY | Enum | Представление типа MIME для устаревшего файла Microsoft Excel (обычно .xls). |
MICROSOFT_POWERPOINT | Enum | Представление типа MIME для файла презентации Microsoft PowerPoint (обычно .pptx). |
MICROSOFT_POWERPOINT_LEGACY | Enum | Представление типа MIME для устаревшего файла Microsoft PowerPoint (обычно.ppt). |
MICROSOFT_WORD | Enum | Представление типа MIME для файла документа Microsoft Word (обычно .docx). |
MICROSOFT_WORD_LEGACY | Enum | Представление типа MIME для устаревшего файла Microsoft Word (обычно .doc). |
ZIP | Enum | Представление типа MIME для файла архива ZIP (обычно.zip). |
Google Base: Фактически вся ваша база принадлежит нам
Я не мог не пошутить с названием, потому что оно, казалось бы, идет по деньгам. Видите ли, Google готовится снять оболочку с новой службы под названием Google Base . Если бы его можно было опубликовать в Интернете, казалось бы, они фактически предпочли бы, чтобы он принадлежал им. По крайней мере, они сохранят его для вас и сделают доступным для поиска.
«Yahoo: Что ты говоришь?»
Слухи вокруг этой службы распространились в течение последних нескольких дней, и горстке людей удалось обнаружить сайт, когда он работает (в настоящее время он не работает). Неизвестно, когда Google официально запустит сервис, хотя сегодня они проводят специальное мероприятие только по приглашениям. Вот текст с первой страницы сайта:
Google Base — это база данных Google, в которую вы можете добавлять все типы контента.Мы бесплатно разместим ваш контент и сделаем его доступным для поиска в Интернете.
Примеры товаров, которые можно найти в Google Base:
• Описание вашей службы планирования вечеринок
• Статьи о текущих событиях с вашего сайта
• Объявление вашего подержанного автомобиля на продажу
• База данных белковых структурВы можете описать любой публикуемый вами элемент с помощью атрибутов, которые помогут людям найти его при поиске в базе данных Google. Фактически, в зависимости от релевантности ваших товаров, они также могут быть включены в основной поисковый индекс Google и другие продукты Google, такие как Froogle и Google Local.
Что имеет в виду Google? Последнее предложение действительно говорит о том, что им нужно: eBay, Craigslist и тематические объявления. Пользователи смогут загружать всевозможные товары для продажи, и вы сможете определять их местоположение, сравнивать и искать через Google. Подумай об этом. При использовании eBay или Craigslist, как часто вы думаете: «Хотел бы я поискать это в Google»? Напомним также, что у Google в разработке есть платежный сервис.
РекламаЕсли мы это допустим, то давайте подумаем о следующем уровне: своего рода API Google Base.Если Google останется посредником, это будет здорово для Google. Следовательно, API, который позволит другим сайтам использовать Google Base, действительно может генерировать большой трафик.
Есть еще один уровень. Разрешив людям публиковать практически все, Google получит в свои руки огромную базу данных элементов, которым были присвоены атрибуты, созданные пользователем. Затем Google может использовать эти данные, чтобы попытаться создать своего рода универсальную схему тегов для информации и элементов, которую затем можно было бы использовать для классификации информации в сети.Далеко за уши? Google уже пытается сделать это с помощью размещения информации через Google Site Maps.
Google кратко прокомментировал Google Base в заявлении:
«Это ранний этап тестирования продукта, который позволяет владельцам контента легко отправлять свой контент в Google. Подобно нашему веб-сканированию и недавно выпущенной программе Google Sitemaps, мы работаем над тем, чтобы предоставить владельцам контента простой способ предоставить нам доступ к их содержанию. Мы постоянно изучаем новые возможности для расширения наших предложений, но в настоящее время нам не о чем анонсировать.«
Итак, ожидание и спекуляции начинаются.
На данный момент там особо не на что посмотреть, но Воутер Шут не только смог увидеть сервис вживую (я видел первую страницу, но это все), но и рискнул и сделал дополнительные скриншоты.
ЗапущеноGoogle Base. Фу. — TechCrunch
Блог Google официально объявляет о запуске Google Base. Ранее мы ожидали запуска Google Base (вместе со всеми остальными) в конце октября.
Итог : Это не очень интересное приложение в его нынешнем виде. Кейт Тир говорит, что это похоже на файл dBASE 1985 года с меньшей функциональностью. Это ужасно. Это централизованный контент с меньшей функциональностью, чем на ebay или craigslist. Контент не интегрируется напрямую в результаты поиска Google, но «релевантность» может подтолкнуть его к основному и локальному поиску (и обману).
Роб Хоф на Business Week тоже превозносит это. Он говорит, что «eBay и другим, возможно, пока нечего опасаться»
Дополнительная информация и ответы на часто задаваемые вопросы о Google Base в разделе «О программе».
Характеристики:
- Стоимость: Бесплатно
- Допустимые типы элементов: Все типы онлайн- и офлайн-информации и изображений
- Языки: Вы можете подавать информацию на многих языках; однако интерфейс Google Base, включая справочную информацию, в настоящее время доступен только на английском, британском и немецком языках.
- Reach : элементы, которые вы отправляете в Google Base, можно найти в Google Base и, в зависимости от их актуальности, также могут появиться в таких ресурсах Google, как Google, Froogle и Google Local.
- Чем отличается: Google Base позволяет добавлять атрибуты, которые лучше описывают ваш контент, чтобы пользователи могли легко его найти. Чем популярнее становятся определенные атрибуты, тем чаще мы будем предлагать их, когда другие публикуют те же элементы. Точно так же элементы, которые становятся более популярными, будут отображаться как предлагаемые типы элементов в раскрывающемся меню «Выбрать существующий тип элемента».
Есть два способа загрузки данных — веб-интерфейс для одного элемента за раз и вариант массовой загрузки для отправки контента в XML.
Я протестировал Google Base. Общая идея состоит в том, что вы выбираете категорию для своего сообщения. Существуют предлагаемые категории — календари курсов, события и мероприятия, вакансии, отзывы, требуемые объявления и т. Д. Вы также можете создать свою собственную категорию.
Каждая категория имеет свои собственные поля для облегчения ввода данных. Например, категория «автомобили» включает поля для типа транспортного средства, года выпуска, марки и т. Д. Вы заполняете любое или все из этих полей, добавляете дополнительные поля (называемые «атрибутами»), если хотите, и добавляете заголовок, описание и ключевые слова (теги).Вы также можете загрузить изображение или указать на изображение в Интернете.
Я обнаружил несколько ошибок в этой форме. Например, не удалось добавить «techcrunch» в качестве тега, потому что он был «написан с ошибкой» и просто не включил его.
Как только я удалил тег techcrunch, я смог добавить дату истечения срока действия и опубликовать свой тестовый контент, который публикуется с небольшой задержкой, вместе с постоянным URL-адресом (это всего лишь быстрый тест).
Как только контент опубликован, его можно редактировать с панели управления.
Контент также можно искать в Google Base. На приведенном выше снимке экрана выполняется поиск «рецептов». При нажатии на конкретный элемент открывается его постоянный URL-адрес (пример), где можно просмотреть полную информацию и связаться с опубликованным по электронной почте.
У Брайана Бензингера здесь более положительный отзыв. И посмотрите, что говорит Дэйв Винер («Это микроконтент без схем»).
Google Base и SEO | Позиция²
Google Base — еще одна скрытая жемчужина в волшебной шкатулке Google.Вы не слышите о них каждый день, но похоже, что это дает издателям новый способ распространения и продвижения контента.
Что это?
Google Base — это бесплатная онлайн-база данных, в которой вы можете бесплатно размещать любую информацию, если она соответствует правилам программы Google. Товары и услуги, рецепты, тематические объявления — вы можете разместить практически все, о чем только можете подумать. Однако это страна мечты для тех, у кого есть список хороших вещей для продажи и нет форума для сбыта.
Как это работает?
Это действительно очень просто. Просто откройте учетную запись или используйте существующую учетную запись, если она у вас есть. Выберите отправку фида и просмотрите различные варианты типов фидов. Если у вас уже есть RSS-канал для вашего продукта, вы можете отправить его, но некоторая информация все равно будет отсутствовать, поэтому рекомендуется создать текстовый файл в соответствии с шаблоном поля Google. Это позволяет вам продумать и включить ключевые слова и ключевые фразы для подходящего поиска. После того, как контент будет готов, отправьте его.
Что удивительно, так это то, что вы можете зарегистрировать до 10 фидов данных в своей учетной записи Google Base и почти один миллион элементов, равномерно распределенных между 10 фидами.
Google Base и SEO
Отправка вашего контента в Google Base на самом деле помогает вам получить дополнительный органический трафик из поисковых систем.
Алгоритм ранжирования продуктов Google Base более буквален в Google Base. Он не такой сложный, как алгоритм поиска Google. Это следует учитывать при приготовлении товарного корма.Такие моменты, как включение факторов, относящихся к вашему продукту, особенно названия продукта, модели и т. Д., В заголовке и описании продукта, становятся решающими. Ключевые слова, на которые вы нацелены, также должны появиться в заголовке и описании. Первые 10-15 слов очень важны, поэтому их нужно использовать с умом. Но будьте осторожны; не набивайте описание большим количеством ключевых слов, так как это может привести к штрафу в отношении вашего объявления.
Добавление релевантных изображений в ленту может повысить рейтинг кликов.Это еще один важный совет по оптимизации, который вы можете использовать. Это поможет вам занять высокие позиции в Google Base. Наконец, поиск продуктов Google использует рейтинги продавцов; клиенты оставляют отзывы о своем опыте покупки в компании, как и на любом портале онлайн-покупок. Так что постарайтесь получить как можно более высокий рейтинг, поскольку это только положительно повлияет на ваш рейтинг в Google Base.
Предоставил Шрути Кекре
.