Разбираемся, в чем разница между Data Mining и Data Extraction / Блог компании SkillFactory / Хабр
Два этих модных слова, связанных с Data Science, сбивают с толку многих людей. Data Mining часто неправильно понимают как извлечение и получение данных, но на самом деле все намного сложнее. В этом посте давайте расставим точки над Mining и выясним разницу между Data Mining и Data Extraction.
Что такое Data Mining?
Data mining, также называемый Обнаружение знаний в базе данных (KDD), представляет собой метод, часто используемый для анализа больших массивов данных с помощью статистических и математических методов для поиска скрытых закономерностей или тенденций и извлечения из них ценности.
Что можно сделать с помощью Data Mining?
Автоматизируя процесс, инструменты data mining могут просматривать базы данных и эффективно выявлять скрытые закономерности. Для предприятий data mining часто используется для выявления закономерностей и взаимосвязей в данных, помогающих принимать оптимальные решения в бизнесе.
Примеры применения
После того, как в 1990-х годах data mining получил широкое распространение, компании в широком спектре отраслей, включая розничную торговлю, финансы, здравоохранение, транспорт, телекоммуникации, электронную коммерцию и т.д., начали использовать методы data mining для получения информации на основе данных. Data mining может помочь сегментировать клиентов, выявить мошенничество, прогнозировать продажи и многое другое.
Сегментация клиентов
Благодаря анализу данных о клиентах и выявлению черт целевых клиентов, компании могут выстраивать их в отдельную группу и предоставлять отвечающие их потребностям специальные предложения.
Анализ рыночной корзины
Эта методика основана на теории, что если вы покупаете определенную группу товаров, вы, скорее всего, купите другую группу товаров. Один известный пример: когда отцы покупают подгузники для своих младенцев, они, как правило, покупают пиво вместе с подгузниками.
Прогнозирование продаж
Это может показаться похожим на анализ рыночной корзины, но на этот раз анализ данных используется для прогнозирования того, когда покупатель снова купит продукт в будущем. Например, тренер покупает банку протеина, которой должно хватит на 9 месяцев. Магазин, продающий этот протеин, планирует выпустить новый через 9 месяцев, чтобы тренер снова его купил.
Обнаружение мошенничества
Data mining помогает в построении моделей для обнаружения мошенничества. Собирая образцы мошеннических и правдивых отчетов, предприятия получают право определять, какие операции являются подозрительными.
Обнаружение паттернов в производстве
В обрабатывающей промышленности data mining используется, чтобы помочь в проектировании систем, путем выявления взаимосвязи между архитектурой продукта, профилем и потребностями клиентов. Добыча данных также может предсказать сроки разработки продукции и затраты.
И это лишь несколько сценариев использования data mining.
Этапы Data Mining
Data mining — это целостный процесс сбора, отбора, очистки, преобразования и извлечения данных для оценки закономерностей и, в конечном итоге, для извлечения ценности.
Как правило, весь процесс добычи данных можно обобщить до 7 этапов:
Очистка данных
В реальном мире данные не всегда очищаются и структурируются. Часто они шумные, неполные и могут содержать ошибки. Чтобы удостовериться, что результат data mining точный, сначала необходимо очистить данные. Некоторые методы очистки включают заполнение недостающих значений, автоматический и ручной контроль и т.д.
Интеграция данных
Это этап, на котором данные из разных источников извлекаются, комбинируются и интегрируются. Источниками могут быть базы данных, текстовые файлы, электронные таблицы, документы, многомерные массивы данных, интернет и так далее.
Выборка данных
Обычно не все интегрированные данные необходимы в data mining. Выборка данных — это этап, в котором из большой базы данных выбираются и извлекаются только полезные данные.
Преобразование данных
После выбора данных они преобразуются в подходящие для добычи формы. Этот процесс включает в себя нормализацию, агрегирование, обобщение и т.д.
Интеллектуальный анализ данных
Здесь наступает самая важная часть data mining — использование интеллектуальных методов для поиска закономерностей в них. Процесс включает регрессию, классификацию, прогнозирование, кластеризацию, изучение ассоциаций и многое другое.
Оценка модели
Этот этап направлен на выявление потенциально полезных, простых в понимании шаблонов, а также шаблонов, подтверждающих гипотезы.
Представление знаний
На заключительном этапе полученная информация представлена в привлекательном виде с применением методов представления знаний и визуализации.
Недостатки Data Mining
Большие вложения времени и труда
Поскольку добыч данных — это длительный и сложный процесс, он требует большой работы продуктивных и квалифицированных людей. Специалисты по интеллектуальному анализу данных могут воспользоваться мощными инструментами добычи данных, однако им требуются специалисты для подготовки данных и понимания результатов. В результате на обработку всей информации может потребоваться некоторое время.
Приватность и безопасность данных
Поскольку data mining собирает информацию о клиентах с помощью рыночных методов, она может нарушить конфиденциальность пользователей. Кроме того, хакеры могут получить данные, хранящиеся в системах добычи данных. Это представляет угрозу для безопасности данных клиентов. Если украденные данные используются не по назначению, это может легко навредить другим.
Выше приведено краткое введение в data mining. Как я уже упоминала, data mining содержит процесс сбора и интеграции данных, который включает в себя процесс извлечения данных (data extraction). В этом случае можно с уверенностью сказать, что data extraction может быть частью длительного процесса data mining.
Что такое Data Extraction?
Также известное как «извлечение веб-данных» и «веб-скрепинг», этот процесс представляет собой акт извлечения данных из (обычно неструктурированных или плохо структурированных) источников данных в централизованные места и централизацию в одном месте для хранения или дальнейшей обработки. В частности, к неструктурированным источникам данных относятся веб-страницы, электронная почта, документы, файлы PDF, отсканированный текст, отчеты мейнфреймов, катушечные файлы, объявления и т.д. Централизованные хранилища могут быть локальными, облачными или гибридными. Важно помнить, что извлечение данных не включает в себя обработку или другой анализ, который может произойти позже.
Что можно сделать с помощью Data Extraction?
В основном цели извлечения данных делятся на 3 категории.
Архивация
Извлечение данных может преобразовать данные из физических форматов: книг, газет, счетов-фактур в цифровые форматы, например, базы данных для хранения или резервного копирования.
Изменение формата данных
Когда вы хотите перенести данные с вашего текущего сайта на новый, находящийся в стадии разработки, вы можете собрать данные с вашего собственного сайта, извлекая их.
Анализ данных
Распространен дополнительный анализ извлеченных данных для получения представления о них. Это может показаться похожим на анализ данных при data mining, но учтите, что анализ данных — это цель их извлечения, но не его часть. Более того, данные анализируются иначе. Один из примеров: владельцы интернет-магазинов извлекают информацию о продукте с сайтов электронной коммерции, таких как Amazon, для мониторинга стратегий конкурентов в режиме реального времени. Как и data mining, data extraction — это автоматизированный процесс, имеющий множество преимуществ. Раньше люди копировали и вставляли данные вручную из одного места в другое, что занимало очень много времени. Извлечение данных ускоряет сбор и значительно повышает точность извлекаемых данных.
Подобно data mining, извлечение данных широко используется в различных отраслях промышленности. Помимо мониторинга цен в электронной коммерции, извлечение данных может помочь в собственном исследовании, агрегировании новостей, маркетинге, в работе с недвижимостью, путешествиях и туризме, в консалтинге, финансах и во многом другом.
Лидогенерация
Компании могут извлекать данные из каталогов: Yelp, Crunchbase, Yellowpages и генерировать лидов для развития бизнеса. Вы можете посмотреть видео ниже, чтобы узнать, как извлечь данные из Yellowpages с помощью шаблона веб-скрепинга.
Агрегация контента и новостей
Агрегирующие контент веб-сайты могут получать регулярные потоки данных из нескольких источников и поддерживать свои сайты в актуальном состоянии.
Анализ настроений
После извлечения обзоров, комментариев и отзывов из социальных сетей, таких как Instagram и Twitter, специалисты могут проанализировать лежащие в их основе взгляды и получить представление о том, как воспринимается бренд, продукт или некое явление.
Шаги Data Extraction
Извлечение данных — первый этап ETL (аббревиатура Extract, Transform, Load: извлечение, преобразование, загрузка) и ELT (извлечение, загрузка и преобразование). ETL и ELT сами по себе являются частью завершенной стратегии интеграции данных. Другими словами, извлечение данных может быть частью их добычи. Извлечение, преобразование, загрузка
В то время как data mining — это получение информации из больших массивов данных, data extraction — это гораздо более короткий и простой процесс. Его можно свести к трем этапам:
Выбор источника данных
Выберите источник, данные из которого вы хотите извлечь, например, веб-сайт.
Сбор данных
Отправьте «GET» запрос на сайт и проанализируйте полученный документ HTML с помощью языков программирования, таких как Python, PHP, R, Ruby и др.
Хранение данных
Сохраните данные в своей локальной базе данных или в облачном хранилище для будущего использования. Если вы опытный программист, который хочет извлечь данные, вышеуказанные шаги могут показаться вам простыми. Однако, если вы не программируете, есть короткий путь — использовать инструменты извлечения данных, например Octoparse. Инструменты data extraction, так же как и инструменты data mining, разработаны для того, чтобы сэкономить энергию и сделать обработку данных простой для всех. Эти инструменты не только экономичны, но и удобны для начинающих. Они позволяют пользователям собирать данные в течение нескольких минут, хранить их в облаке и экспортировать их во многие форматы: Excel, CSV, HTML, JSON или в базы данных на сайте через API.
Недостатки Data Extraction
Сбой сервера
При извлечении данных в больших масштабах веб-сервер целевого сайта может быть перегружен, что может привести к поломке сервера. Это нанесет ущерб интересам владельца сайта.
Бан по IP
Когда человек слишком часто собирает данные, веб-сайты могут заблокировать его IP-адрес. Ресурс может полностью запретить IP-адрес или ограничить доступ, сделав данные неполными. Чтобы извлекать данные и избегать блокировки, нужно делать это с умеренной скоростью и применять некоторые методы антиблокировки.
Проблемы с законом
Извлечение данных из веба попадает в серую зону, когда дело касается законности. Крупные сайты, такие как Linkedin и Facebook, четко заявляют в своих условиях использования, что любое автоматическое извлечение данных запрещено. Между компаниями было много судебных исков из-за деятельности ботов.
Ключевые различия между Data Mining и Data Extraction
Data mining также называется обнаружением знаний в базах данных, извлечением знаний, анализом данных/шаблонов, сбором информации. Data extraction используется взаимозаменяемо с извлечением веб-данных, сканированием веб-страниц, сбором данных и так далее.
Исследования data mining в основном основаны на структурированных данных, тогда как при извлечении данных они обычно извлекаются из неструктурированных или плохо структурированных источников.
Цель data mining — сделать данные более полезными для анализа. Data extraction — это сбор данных в одно место, где они могут быть сохранены или обработаны.
Анализ при data mining основан на математических методах выявления закономерностей или тенденций. Data extraction базируется на языках программирования или инструментах извлечения данных для обхода источников.
Цель data mining — найти факты, которые ранее не были известны или игнорировались, тогда как data extraction имеет дело с существующей информацией.
Data mining сложнее и требует больших вложений в обучение людей. Data extraction при использовании подходящего инструмента может быть чрезвычайно простым и экономичным.
Мы помогаем начинающим не запутаться в Data. Специально для хабравчан мы сделали промокод HABR, дающий дополнительную скидку 10% к скидке указанной на баннере.
Рекомендуемые статьи
Технология Data mining, её применение и характеристики
1. Определение
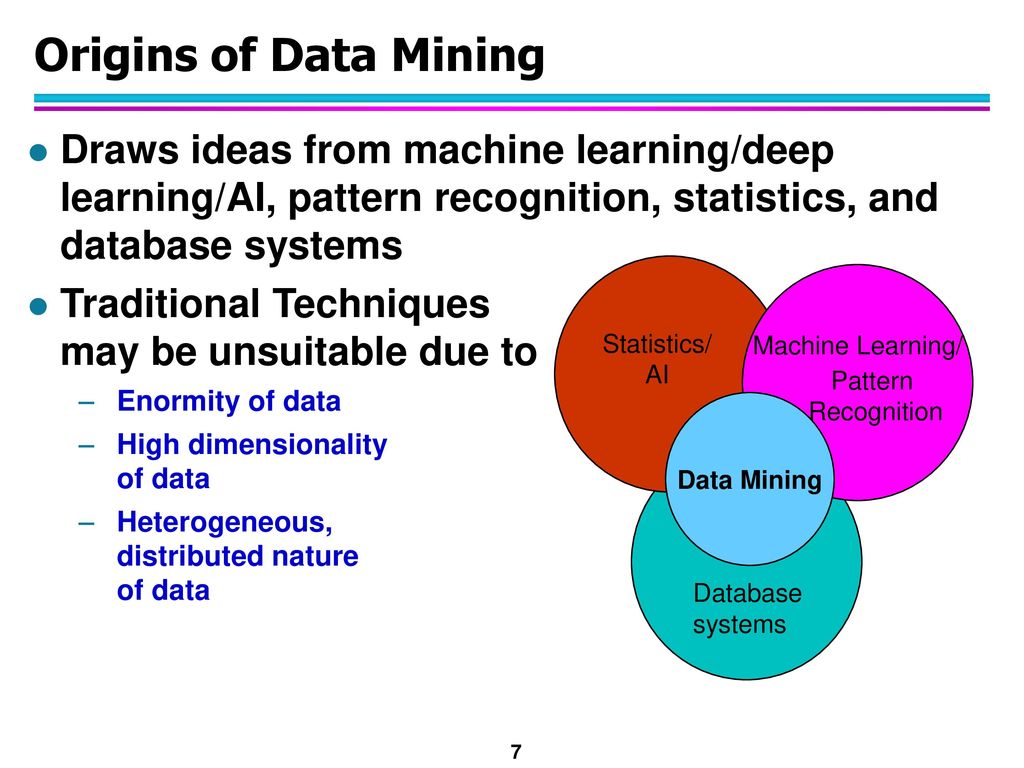
Технология Data mining – интеллектуальная обработка данных с использованием методов машинного обучения, математической статистики и теории баз данных.
2. История создания и развития
Термин «data mining» появился в 1990-х годах, но как таковая обработка данных возникла в 18 веке, основываясь на теореме Байеса, чуть позже на регрессионном анализе.
По мере того как количество данных росло, изобретались новые технологии в области информатики (нейронные сети, генетические алгоритмы, метод деревьев решений и т.д.), появлялась возможность хранения большого количества данных и увеличение скорости обработки информации компьютерами интерес к data mining стремительно рос и вскоре обработка данных стала считаться отдельной дисциплиной. Сейчас data mining включает в себя обработку не только текстовых данных (text data mining), но и графических и мультимедийных(web mining).
Устоявшегося перевода словосочетания «data mining» на русский язык нет, дословно это переводится как «добыча данных». Но чаще всего используют формулировку «интеллектуальная обработка данных».
В настоящее время data mining является частью большего понятия – Big data, которое помимо обработки данных включает в себя их сбор и хранение.
3. Технические характеристики
Фундаментально data mining основывается на 3-х понятиях:
Математическая статистика – является основой большинства технологий, используемых для data mining, например, кластерный анализ, регрессионный анализ, дискриминирующий анализ и пр.;
Искусственный интеллект – воспроизведение нейронной сети мышления человека в цифровом виде;
Машинное обучение – совокупность статистики и искусственного интеллекта, способствующая пониманию компьютерами данных, которые они обрабатывают для выбора наиболее подходящего метода или методов анализа.
В data mining используются следующие основные классы задач:·
обнаружение отклонений – выявление данных, отличающихся по каким-либо параметрам из общей массы;
обучение ассоциациям – поиск взаимосвязей между событиями;
кластеризация – группирование наборов данных, без заранее известных шаблонов;
классификация – обобщение известного шаблона для применения к новым данным;
регрессия – поиск функции, отображающей набор данных с наименьшим отклонением;
подведение итогов – отображение в сжатом виде исходной информации, включая предоставление отчетов и визуализацию.
4. Кейсы применения
Сегодня data mining широко используется в бизнесе, науке, технике,
медицине, телекоммуникациях и т.п. Анализ данных по операциям с кредитными
картами, анализ данных ЖКХ, программы карт лояльности в магазинах с учетом
предпочтения покупателей, национальная безопасность (обнаружение вторжений), исследование
генома человека – всего лишь небольшая часть возможных вариантов применения data mining.
5. Полезные ссылки
Big Data и Data Mining в 1С:Предприятие
В 2008 году Клиффорд Линч ввел понятие Big Data, это название он предложил по аналогии с Большой Нефтью, которая дала толчок развитию и обогатила нефтеперерабатывающие компании несколько десятилетий назад.
Сегодня новой большой нефтью являются данные. Эти данные уже научились обрабатывать и исследовать. Данные теперь добывают из больших массивов информации, как раньше добывали нефть из месторождений. В IT-среде появился устойчивый термин — Data Mining.
Возможно Вы думаете, что в обычной «1С:Бухгалтерии» или «1С:Управление небольшой фирмой» таких ценных данных нет, и это ни какой ни Big Data, а добывать там особо и нечего.
Но давайте посмотрим на данные обычного Российского предприятия под другим углом – обычно у предприятия в наличии не одна база данных, а несколько, например есть «1С:Бухгалтерия», «1С:Управление торговлей» и «1С:Зарплата и управление персоналом». Возможно, каждая из этих баз уже изучена и исследована полностью, возможно Вы даже помните все данные из последнего отчета по продажам или зарплатной ведомости филиала.
Но, используя дополнительный инструмент – программу «Бизнес-аналитика и KPI» Вы можете получить ряд новых, ценных данных из уже существующего «месторождения» — ваших баз данных.
Попробуем «пробурить» его и добыть ценность.
Например, Вы можете свести вместе и проанализировать данные о росте посещаемости страницы о товаре на веб-сайте и рост количества новых клиентов в базе данных «1С:Бухгалтерия». Или сопоставить увеличение количества запросов от новых клиентов из региона в электронной почте и увеличение времени в командировках (информация из «1С:Документооборот»).
Также можно своевременно заметить незначительный спад в продажах определенной услуги и проанализировать причину такого спада. Ведь данные всех баз предприятия у Вас будут под рукой, и вы сможете сопоставить различные показатели, посмотреть их динамику и т. д.
Таким образом, Вы добываете ценные, но глубоко скрытые данные из вашего «месторождения» Big Data.
И последнее, о чем мы хотели поговорить в плане Data Mining в 1С — большие данные сейчас часто характеризуются аббревиатурой VVV – volume (объем), velocity (скорость), variety (изменчивость). Все эти характеристики есть и у Ваших баз данных «1С:Предприятие».
Желаем Вам успешного «бурения» на платформе «1С:Предприятие 8», и готовы помочь с инструментом — программой «Бизнес-аналитика и KPI»
Смотрите также:
Скачать статью в pdf
Курс Big Data — ПОДГОТОВКА ДАННЫХ ДЛЯ DATA MINING НА PYTHON (DPREP)
1. ПРОДВИНУТЫЕ ВОЗМОЖНОСТИ БИБЛИОТЕК ЯЗЫКА PYTHON ДЛЯ ОБРАБОТКИ И ВИЗУАЛИЗАЦИИ ДАННЫХ
Цель: познакомить участников с продвинутыми возможностями основных библиотек языка Python для обработки и визуализации данных и сформировать необходимые навыки по работе с данными в рассматриваемых библиотеках
Теоретическая часть:
изучение возможностей библиотек языка Python для обработки (Pandas, NumPy, SciPy, Sklearn) и визуализации (matplotlib, seaborn) данных.
обзор основных приемов по работе с данными:
первичный анализ данных
получение описательных статистик
изменение типа данных
построение сводных таблиц
визуализация статистических характеристик данных (гистограммы, графики плотностей распределений, тепловые карты, «ящики с усами» и «виолончели»)
Практическая часть: решение практических задач обработки и визуализации данных на примере табличных данных.
2. БИБЛИОТЕКИ PYTHON В КОРРЕКТИРОВАНИИ ТИПИЧНЫХ ОСОБЕННОСТЕЙ В ДАННЫХ
Цель: познакомить участников с основными особенностями в данных, с которыми приходится сталкиваться в реальных задачах, и научить успешно их корректировать с использованием библиотек языка Python. Продемонстрировать применение указанных подходов в случае промышленного варианта подготовки данных на примере использования Apache Spark (PySpark).
Теоретическая часть:
обзор типичных особенностей в данных и подходов к их корректировке:
отсутствующие значения
выбросы
дубликаты
подготовка данных для использования в алгоритмах машинного обучения:
нормализация числовых данных
преобразование категориальных значений
работа с текстовыми данными
Практическая часть: подготовка «сырых» данных для использования в алгоритме машинного обучения с подробным анализом влияния каждой особенности датасета на конечный результат работы алгоритма
3. ПОДХОДЫ К ПОСТРОЕНИЮ ДОПОЛНИТЕЛЬНОГО ПРИЗНАКОВОГО ПРОСТРАНСТВА НА ОСНОВЕ ИСХОДНЫХ ДАННЫХ
Цель: познакомить участников с основными подходами получения дополнительных и наиболее значимых характеристик из исходных данных. Продемонстрировать влияние дополнительных признаков на улучшение метрик качества работы алгоритмов машинного обучения с использованием библиотеки Sklearn
Теоретическая часть:
обзор подходов формирования дополнительного признакового пространства и выбора наиболее значимых характеристик
увеличение размерности исходного признакового пространства
постановка задачи в случае обучения с учителем – с использованием целевой переменной
постановка задачи в случае обучения без учителя
уменьшение размерности исходного признакового пространства
подробный анализ задачи увеличения размерности исходного признакового пространства в случае обучения с учителем:
статистические методы фильтрации признаков в задачах классификации и регрессии
методы машинного обучения как инструменты для получения наиболее значимых признаков в данных
Практическая часть: решение прикладной задачи построения дополнительного признакового пространства и получения наиболее значимых признаков с подробным анализом влияния рассмотренных теоретических подходов на конечный результат работы алгоритмов машинного обучения
4. ПРОЕКТНАЯ РАБОТА
Цель: закрепить полученные слушателями курса знания по подготовке данных.
Теоретическая часть: краткий обзор пройденного материала со ссылками на рабочие блокноты, в которых решалась та или иная задача подготовки данных.
Практическая часть: самостоятельное решение задачи подготовки датасета для машинного обучения с использованием собственной базы данных или на лабораторном наборе от организаторов курса. Итоговый разбор работ слушателей курса.
Использование Big Data и Data Mining в сфере культуры – ключевая тема Деловой площадки VII СПБМКФ | Forbes Agenda
Диалог на одну из самых актуальных тем современного состояния культуры станет по-настоящему международным. В дискуссии примут участие эксперты и лидеры мнений из Соединенных Штатов Америки, Великобритании, Германии и России, среди которых digital-директор Политехнического музея Майя Стравинская, исследователь отдела креативной и цифровой экономики фонда глобальных инноваций Nesta (Великобритания) Джон Дэвис, эксперт по теории новых медиа, директор американской «Cultural Analytics Lab» Лев Манович, старший преподаватель программы «Большие данные в культуре и обществе» департамента цифровых гуманитарных наук Королевского Колледжа Лондона Марк Котэ, заместитель директора ГМИИ им. Пушкина Ольга Шишко, генеральный директор британского агентства «The Audience» Энн Торрегиани, специалист по визуализации данных, эксперт программы «Будущие и развивающиеся технологии» Европейской комиссии (Германия) Моритц Стефанер.
«В бизнес-среде работа с данными (большими или маленькими – неважно) становится не просто данью моде, а потребностью, серьезным конкурентным преимуществом тех, кто научился принимать решения или предугадывать желания и поведение потребителей на основе анализа данных. Данные сегодня способны приносить бизнесу вполне ощутимую прибыль. В культурных институциях такой зрелой осознанности использования системной аналитики, потоковых данных, поведенческих моделей пока не возникло. Да и компетенций нужного уровня тоже не много. Данные и в роли объекта, и в роли инструмента культурной активности – это пока единичные истории. Культура у бизнеса должна научиться прагматично смотреть через аналитические линзы на посетителя, зрителя, читателя как на покупателя. Научиться умно и тонко управлять его эмоциями, намерениями и действиями в гуманитарно-культурных целях», – отметила Светлана Миронюк, академический директор программы «Big Data и цифровой маркетинг» Московской школы управления «Сколково», исполнительный директор PWC Audit.
О наработках в области Big Data и о реализованных проектах расскажет в рамках дискуссии директор кластера ПАО «Мегафон» Вадим Меркулов. «Сегодня огромные объемы данных появляются в самых разных направлениях деятельности человека. Их использование открывает новые возможности в абсолютно всех сферах жизни общества, включая, конечно, и культуру. Сегодня мы говорим о Big Data не как о каком-то направлении бизнеса, а о глобальной технологии, которая позволяет проводить подробные исследования, оценивать и анализировать состояние дел в той или иной отрасли, строить модели поведения людей и многое-многое другое. Оцифровка имеющихся данных и знаний о культуре открывает огромные возможности для исследователей и ученых, располагая нас на пороге новых открытий и сенсаций. Поэтому Big Data можно и нужно использовать и в культуре», – подчеркнул он.
VII Санкт-Петербургский международный культурный форум пройдет в Северной столице с 15 по 17 ноября. Актуальное расписание мероприятий Деловой площадки VII Санкт-Петербургского международного культурного форума доступно на официальном сайте: www.culturalforum.ru.
Разница между большими данными и интеллектуальным анализом данных
Разница между большими данными и интеллектуальным анализом данных
Большие данные: Это огромные, большие или объемные данные, информация или соответствующая статистика, полученные крупными организациями и предприятиями. Создано и подготовлено много программного обеспечения и хранилищ данных, поскольку трудно вычислить большие данные вручную. Он используется для обнаружения закономерностей и тенденций и принятия решений, связанных с человеческим поведением и технологиями взаимодействия.
Data Mining: Data Mining — это метод извлечения важной и жизненно важной информации и знаний из огромного набора / библиотек данных. Он получает понимание путем тщательного извлечения, анализа и обработки огромных данных, чтобы выявить закономерности и взаимосвязи, которые могут быть важны для бизнеса. Это аналогично золотодобыче, когда золото добывается из горных пород и песков.
Ниже представлена таблица различий между Big Data и Data Mining:
Data Mining
Big Data
Это один из методов в конвейере больших данных.
Большие данные — это метод сбора, хранения и обработки огромной информации. Это объясняет взаимосвязь данных.
Интеллектуальный анализ данных — это часть процесса обнаружения данных. Это пристальный взгляд на данные.
Речь идет об извлечении важной и ценной информации из огромного количества данных. Это метод отслеживания и выявления тенденций в сложных наборах данных. Это общий вид данных.
Цель такая же, как и у больших данных, поскольку это один из инструментов больших данных.
Цель состоит в том, чтобы сделать данные более важными и удобными, то есть путем извлечения только важной информации из огромных данных в рамках существующих традиционных аспектов.
Это ручной, а также автоматизированный характер.
Это только автоматизировано, поскольку вычисление огромных данных затруднено.
Он фокусируется только на одной форме данных. то есть структурированный.
Он фокусируется и работает со всеми формами данных, то есть структурированными, неструктурированными или полуструктурированными.
Он используется для создания определенных бизнес-идей.Data Mining является менеджером шахты.
Он в основном используется для деловых целей и удовлетворения запросов потребителей. Большие данные — это шахта.
Это часть больших данных. то есть один из инструментов.
Это супер набор интеллектуального анализа данных.
Это инструмент для извлечения важной информации из больших данных. Данные могут быть как большими, так и маленькими.
Он больше связан с процессами обработки объемных данных. Данные могут быть только большими.
Что такое интеллектуальный анализ данных и большие данные? Простое руководство
Данные питают почти все вокруг нас и влияют на большинство аспектов нашей повседневной жизни, включая важные бизнес-решения.
Это часто делается на основе информации, которая может быть автоматизирована или оценена вручную. Эта информация получается несколькими способами, например, от клиентов или извлекается из рыночной информации, а затем используется для определения наилучшего курса для производственных линий, цепочек поставок и т. Д.
Многие современные предприятия, возможно, были бы менее успешными или конкурентоспособными, если бы не данные, которые в огромной степени способствуют способности адаптироваться к постоянно меняющимся рыночным условиям или потребностям потребителей.
Тем не менее, данные в исходном, необработанном виде используются мало. Чтобы обеспечить ценность, он требует анализа и просеивания ключевых идей. Благодаря облачным вычислениям большие объемы данных могут быть освобождены от ограничений сервера с ограниченным хранилищем и сохранены в нужном масштабе, а анализ в реальном времени доступен круглосуточно и без выходных. Однако еще важнее то, что эти огромные объемы данных необходимо оценивать с молниеносной скоростью, чтобы отсеять нужную информацию — задача, которая не может быть выполнена с использованием вычислительной мощности человека.
Что такое интеллектуальный анализ данных?
Интеллектуальный анализ данных определяется путем тщательного изучения больших объемов данных с целью выявления закономерностей и нарушений в наборах данных. С помощью интеллектуального анализа данных вы можете создать независимый прогноз будущего своего бизнеса и спрогнозировать сценарии потенциальных возможностей, а также проблем.
Существует множество различных способов майнинга, и предприятие, перегруженное данными, может использовать эту возможность для расширения бизнеса, оптимизации затрат, снижения рисков и укрепления отношений с клиентами
Аналитический гигант SAS считает, что интеллектуальный анализ данных жизненно важен, потому что он не только позволяет организация должна находить лучшие данные для любых целей, которых она пытается достичь, но она также преобразует наиболее релевантные данные в значимую информацию, которая имеет гораздо большую ценность.
Интеллектуальный анализ данных позволяет предприятиям отсеивать весь хаотичный и повторяющийся шум в своих данных и понимать, что имеет значение, а затем эффективно использовать эту информацию для оценки вероятных результатов. Этот процесс выявляет закономерности и идеи, которые нельзя найти где-либо еще, и, используя автоматизированные процессы для поиска конкретной информации, он не только сокращает время, необходимое для поиска данных, но и повышает надежность данных.
После того, как данные собраны, их можно проанализировать и смоделировать, чтобы преобразовать их в полезные идеи для использования в бизнесе.
Интеллектуальный анализ больших данных
Интеллектуальный анализ больших данных — это форма анализа, которая включает извлечение огромных объемов данных (больших данных) и их превращение в значимую информацию.
Этот подход чаще всего используется как часть стратегии бизнес-аналитики, которая направлена на создание целевых аналитических данных для организации, включая данные о системах, процессах и всем остальном, что включает последовательный сбор данных в течение длительного периода времени.
Большие данные по своей природе обычно собирают гораздо дольше и часто хранятся в неструктурированном формате, поэтому требуется некоторое структурирование, прежде чем их можно будет полностью проанализировать.
Сопутствующие ресурсы
Создание предприятия будущего, основанного на данных
Пять основных тенденций, которые будут определять будущее организационной устойчивости и эффективности
Загрузить сейчас
Майнинг обычно включает поиск в базе данных, уточнение, а затем извлечение этих данных для последующего заказа в осмысленную структуру, обычно основанную на общих чертах или типах, с использованием алгоритма.
Поскольку интеллектуальный анализ больших данных — это, по сути, интеллектуальный анализ данных в гораздо большем масштабе, для его эффективного выполнения требуются гораздо большие вычислительные мощности.В некоторых случаях с этой задачей справляется только специализированное оборудование, такое как исследовательские компьютеры.
Однако основные принципы интеллектуального анализа данных остаются неизменными независимо от размера набора данных.
Методы интеллектуального анализа данных
К методам, параметрам и задачам интеллектуального анализа данных относятся:
Обнаружение аномалий: выявлено необычных записей данных, которые могут представлять интерес в случае ошибок, требующих дополнительного изучения.
Моделирование зависимостей : поиск взаимосвязей между переменными.Например, супермаркет будет собирать информацию о покупательских привычках своих клиентов. Используя изучение правил ассоциации, супермаркет может определить, какие продукты покупаются вместе, и использовать это для маркетинга.
Кластеризация : поиск похожих структур и групп данных без использования известных структур данных.
Классификация : поиск закономерностей в новых данных с использованием известных структур. Например, когда почтовый клиент классифицирует сообщения как спам или законные.
Регрессия: поиск функций, моделирующих данные с наименьшим количеством ошибок.
Обобщение: создание компактного представления набора данных. Это включает в себя визуализацию и создание отчетов.
Прогноз: Прогнозная аналитика ищет закономерности в данных, которые можно использовать для составления обоснованных прогнозов на будущее.
Association: более простой подход к интеллектуальному анализу данных, этот метод позволяет выполнять простые корреляции между двумя или более наборами данных.Например, соответствие покупательским привычкам людей, например, люди, которые покупают бритвы, как правило, покупают пену для бритья одновременно, что позволило бы создать простые предложения о покупке, предназначенные для покупателей.
Деревья решений: , относящиеся к большинству вышеперечисленных методов, модель дерева решений может использоваться как средство выбора данных для анализа или поддержки использования дополнительных данных в структуре интеллектуального анализа данных. Дерево решений, по сути, начинается с вопроса, который имеет два или более результата, которые, в свою очередь, соединяются с другими вопросами, что в конечном итоге приводит к действию, например, отправить предупреждение или инициировать сигнал тревоги, если проанализированные данные приводят к конкретным ответам.
Преимущества интеллектуального анализа данных
Есть несколько способов, которыми организации могут извлечь выгоду из интеллектуального анализа данных.
Прогнозирование тенденций: Поиск прогнозной информации в больших наборах данных можно автоматизировать с помощью интеллектуального анализа данных. На вопросы, которые раньше требовали тщательного анализа, теперь можно более эффективно отвечать прямо из данных.
Помощь в принятии решений: По мере того, как организации все больше ориентируются на данные, принятие решений становится более сложным.Используя интеллектуальный анализ данных, организации могут объективно анализировать имеющиеся данные для принятия решений.
Прогнозирование продаж: предприятий с постоянными клиентами могут отслеживать покупательские привычки этих потребителей, используя интеллектуальный анализ данных для прогнозирования будущих моделей покупок, чтобы они могли предложить наилучшее обслуживание клиентов. Интеллектуальный анализ данных отслеживает, когда их клиенты что-то купили, и предсказывает, когда они будут покупать снова.
Обнаружение неисправного оборудования: Применение методов интеллектуального анализа данных к производственным процессам может помочь им быстро обнаружить неисправное оборудование и подобрать оптимальные параметры управления.Интеллектуальный анализ данных можно использовать для регулирования этих параметров, чтобы уменьшить количество ошибок во время производства и улучшить качество готовой продукции.
Лучшая лояльность клиентов: низкие цены и хорошее обслуживание клиентов должны гарантировать повторение обычаев. Компании могут уменьшить отток клиентов с помощью интеллектуального анализа данных, особенно данных в социальных сетях.
Откройте для себя свежие идеи: интеллектуальный анализ данных может помочь вам обнаружить закономерности, укрепляющие ваши бизнес-практики и стратегии, но он также может дать неожиданную информацию о вашей компании, клиентах и операциях.Это может привести к новым тактикам и подходам, которые могут открыть новые потоки доходов или найти недостатки в вашем бизнесе, которые вы никогда бы не заметили и не подумали бы искать иначе.
Недостатки интеллектуального анализа данных
Как и все в жизни, хотя есть много преимуществ, связанных с использованием интеллектуального анализа данных, есть также несколько недостатков.
Проблемы с конфиденциальностью: Предприятия собирают информацию о своих клиентах разными способами, чтобы понять тенденции их покупательского поведения, но такие предприятия не существуют вечно, они могут обанкротиться или быть приобретены другой компанией в любое время, что обычно бывает привести к продаже или утечке личной информации клиентов, которой они владеют.
Проблемы безопасности: Безопасность — большая проблема как для компаний, так и для их клиентов, особенно из-за огромного количества случаев взлома, когда большие данные клиентов были украдены. Это возможность, о которой должен знать каждый.
Неправильное использование информации : Информация, собранная с помощью интеллектуального анализа данных по этическим причинам, может быть использована не по назначению, например, для использования людьми или предприятиями для извлечения выгоды из уязвимых групп или для дискриминации группы людей.
Не всегда точен : Собранная информация не всегда на 100% точна, и ее использование для принятия решений может привести к серьезным последствиям.
Будущее данных и интеллектуального анализа данных
Объем данных, собираемых компаниями, значительно увеличился за последние несколько лет, и этот рост не показывает никаких признаков замедления в ближайшем будущем. Это может привести к тому, что некоторые организации столкнутся с лавиной информации, которая в случае неправильного управления может создать больше проблем, чем решений.
Вот почему предприятиям следует инвестировать в аналитику данных, которая помогает обеспечить конкурентное преимущество благодаря решениям, принимаемым на основе высокоточных аналитических данных. Фактически, передовые технологии, доступные в настоящее время, позволяют предприятиям обрабатывать данные в реальном времени без необходимости переносить их в центр обработки данных или облако. Так обстоит дело с периферийными вычислениями, которые помогают анализировать мельчайшие объемы данных в режиме реального времени. Хотя интеллектуальный анализ больших данных по-прежнему в основном ограничивается центрами обработки данных и облаком, исследования Gartner показывают, что к 2025 году 75% данных, генерируемых предприятиями, будут создаваться и обрабатываться вне традиционного центра обработки данных, а будущее аналитики больших данных лежит в основе. твердо на краю.
В сочетании с преимуществами 5G граничные вычисления позволяют обрабатывать данные в том месте, где они собираются, со сверхбыстрой скоростью передачи. Сектор, который получает исключительную выгоду от этого прогресса, — это экосистема Интернета вещей (IoT), которая пережила бум с начала пандемии. Поскольку многие по-прежнему работают удаленно и проводят больше времени дома, умные устройства стали способом сделать простые повседневные задачи более эффективными. Однако эта тенденция также может иметь неприятные последствия для бизнеса из-за лазеек в кибербезопасности.
Машинное обучение в равной степени обещает повлиять на будущее аналитики данных, поскольку с каждым годом все больше компаний развертывают такие приложения. Это связано с тем, что технология становится все более доступной, и многие инструменты так же легко доступны для малого бизнеса, как и для специалистов по данным. Некоторые из новейших инструментов машинного обучения могут предоставить предприятиям любого размера возможности для анализа сложных наборов данных и получения полезной информации, при этом производительность этих систем будет только улучшаться.
В эпоху безудержной цифровой трансформации не только данные становятся более важными, но и скорость и точность обработки этих данных, а также качество информации, которую могут получить организации.
Рекомендуемые ресурсы
Технология доверия
Как защитить свой самый ценный товар
Загрузить сейчас
Преобразование бизнес-операций с помощью ИИ, данных Интернета вещей и периферийных вычислений
Отчет Pathfinder об окупаемости инвестиций в ИИ, Интернет вещей и периферийных вычислений
Загрузить сейчас
Создание предприятия будущего, основанного на данных
Пять основных тенденций, которые будут определять будущее устойчивости и эффективности организации
Загрузить сейчас
Руководство по резервному копированию и восстановлению горячего облачного хранилища
Что такое облачное хранилище объектов, почему он на подъеме, и какой вариант выбрать?
Загрузить сейчас
Big Data vs Business Intelligence vs Data Mining
В последнее время в технологическом ландшафте бизнеса произошли огромные сдвиги. Достижения в облачных технологиях и мобильных приложениях позволили предприятиям и ИТ-пользователям взаимодействовать совершенно по-новому. Одной из самых быстрорастущих технологий в этой сфере является бизнес-аналитика и связанные с ней концепции, такие как большие данные и интеллектуальный анализ данных.
Сравните лидеров по программному обеспечению бизнес-аналитики
Чтобы помочь вам понять различные процессы обработки бизнес-данных с целью использования инструментов бизнес-аналитики, важно знать различия между большими данными, интеллектуальным анализом данных и бизнес-аналитикой.Мы изложили определения каждого из них и подробно рассказали, как они соотносятся и сравниваются друг с другом.
Что такое бизнес-аналитика (BI)?
Business Intelligence включает анализ данных с целью выявления тенденций, закономерностей и аналитических данных. Выводы, основанные на данных, дают точное и проницательное представление о процессах вашей компании и результатах, которые они приносят. Помимо стандартных показателей, таких как финансовые показатели, углубленная бизнес-аналитика выявляет влияние текущих практик на производительность сотрудников, общую удовлетворенность компании, конверсии, охват СМИ и ряд других факторов.
Помимо представления информации о текущем состоянии вашей организации, использование бизнес-аналитики позволяет прогнозировать будущую производительность. Благодаря анализу прошлых и текущих данных надежные системы бизнес-аналитики отслеживают тенденции и демонстрируют, как эти тенденции будут продолжаться с течением времени.
Бизнес-аналитика — это больше, чем просто наблюдение. BI выходит за рамки анализа, когда на основе результатов предпринимаются действия. Возможность видеть реальные, поддающиеся количественной оценке результаты политики и ее влияние на будущее вашего бизнеса — это мощный инструмент для принятия решений.
Визуализации бизнес-аналитики, созданные в Exago BI.
Что такое большие данные?
Термин «большие данные» можно определить просто как большие наборы данных, которые перерастают простые базы данных и архитектуры обработки данных. Например, данные, которые нельзя легко обработать в электронных таблицах Excel, могут называться большими данными.
Большие данные включают в себя процесс хранения, обработки и визуализации данных. Очень важно найти правильные инструменты для создания наилучшей среды для успешного получения ценной информации из ваших данных.
Создание эффективной среды больших данных включает использование инфраструктурных технологий, которые обрабатывают, хранят и упрощают анализ данных. Хранилища данных, программы на языке моделирования и кубы OLAP — это лишь некоторые примеры. Сегодня предприятия часто используют несколько инфраструктурных развертываний для управления различными аспектами своих данных.
Большие данные часто дают компаниям ответы на вопросы, которые они не знали, они хотели задать: как новое программное обеспечение для управления персоналом повлияло на производительность сотрудников? Как недавние отзывы клиентов связаны с продажами? Анализ источников больших данных позволяет выявить взаимосвязи между всеми аспектами вашего бизнеса.
Таким образом, информация, собираемая в больших данных, является полезной. Компании должны установить соответствующие цели и параметры, чтобы извлекать ценную информацию из больших данных.
Что такое интеллектуальный анализ данных?
Интеллектуальный анализ данных относится к процессу просмотра больших наборов данных для выявления релевантной или относящейся к делу информации. Однако лицам, принимающим решения, также необходим доступ к более мелким и конкретным фрагментам данных. Компании используют интеллектуальный анализ данных для бизнес-аналитики и для выявления конкретных данных, которые могут помочь их компаниям принимать более эффективные решения в области руководства и управления.
Интеллектуальный анализ данных — это процесс поиска ответов на вопросы, о которых вы не знали заранее. Например, изучение новых источников данных может привести к обнаружению причин финансовых недостатков, неудовлетворительной работы сотрудников и многого другого. Поддающиеся количественной оценке данные проливают свет на информацию, которая может быть не очевидна при стандартном наблюдении.
Информационная перегрузка заставляет многих аналитиков полагать, что они упускают из виду ключевые моменты, которые могут помочь их компаниям работать лучше.Эксперты по интеллектуальному анализу данных просматривают большие наборы данных, чтобы выявить тенденции и закономерности.
Для интеллектуального анализа данных можно использовать различные программные пакеты и аналитические инструменты. Процесс может быть автоматизирован или выполнен вручную. Интеллектуальный анализ данных позволяет отдельным работникам отправлять определенные запросы информации в архивы и базы данных, чтобы они могли получить целевые результаты.
Сравните лучших лидеров программного обеспечения для анализа больших данных
BI против больших данных
Бизнес-аналитика — это совокупность систем и продуктов, которые были реализованы в различных бизнес-практиках, но не информация, полученная из систем и продуктов.
С другой стороны, большие данные стали значить для разных людей разные вещи. При сравнении больших данных и бизнес-аналитики некоторые люди используют термин большие данные, когда речь идет о размере данных, в то время как другие используют этот термин в отношении конкретных подходов к аналитике.
Итак, как соотносятся и сравниваются бизнес-аналитика и большие данные? Большие данные могут предоставлять информацию за пределами собственных источников данных компании, выступая в качестве обширного ресурса. Следовательно, это компонент бизнес-аналитики, предлагающий всестороннее представление о ваших процессах.Большие данные часто представляют собой информацию, которая позволяет получить представление о бизнес-аналитике.
Опять же, большие данные существуют в рамках бизнес-аналитики. Это означает, что они различаются по количеству и типу данных, которые они включают. Поскольку бизнес-аналитика является общим термином, данные, которые считаются частью бизнес-аналитики, гораздо более всеобъемлющи, чем данные, относящиеся к большим данным. Бизнес-аналитика охватывает все данные, от отчетов о продажах, размещенных в таблицах Excel, до крупных онлайн-баз данных. С другой стороны, большие данные состоят только из этих больших наборов данных.
Инструменты, задействованные в процессах больших данных и бизнес-аналитики, также различаются. Программное обеспечение бизнес-аналитики базового уровня способно обрабатывать стандартные источники данных, но может не быть оборудовано для управления большими данными. Другие, более совершенные системы, специально разработаны для обработки больших данных.
Конечно, в обсуждении больших данных и бизнес-аналитики есть некоторое совпадение, связанное с использованием комплексных систем бизнес-аналитики, предназначенных для обработки больших наборов данных.Большинство поставщиков программного обеспечения для бизнес-аналитики предлагают многоуровневые модели затрат, которые увеличивают функциональность в зависимости от цены. Возможности больших данных также могут быть предложены в качестве дополнения к программной системе бизнес-аналитики. И это бизнес-аналитика против больших данных.
Аналитика больших данных от Alteryx.
BI против интеллектуального анализа данных
Как указывалось ранее, бизнес-аналитика определяется как методы и инструменты, используемые организациями для получения аналитических выводов из данных. Он также включает в себя то, как компании могут получать информацию из больших данных и интеллектуального анализа данных.Это означает, что бизнес-аналитика не ограничивается технологиями — она включает бизнес-процессы и процедуры анализа данных, которые облегчают сбор больших данных.
Интеллектуальный анализ данных подпадает под общий термин «бизнес-аналитика» и может рассматриваться как форма бизнес-аналитики. Интеллектуальный анализ данных можно рассматривать как функцию бизнес-аналитики, используемую для сбора соответствующей информации и получения аналитических сведений. Более того, бизнес-аналитику можно рассматривать как результат интеллектуального анализа данных. Как уже говорилось, бизнес-аналитика предполагает использование данных для получения информации.Бизнес-аналитика интеллектуального анализа данных — это сбор необходимых данных, которые в конечном итоге приведут к ответам на основе глубокого анализа.
Связь между интеллектуальным анализом данных и бизнес-аналитикой можно рассматривать как причинно-следственную связь. Интеллектуальный анализ данных ищет «что» (соответствующие наборы данных), а процессы бизнес-аналитики раскрывают «как» и «почему» (идеи). Аналитики используют интеллектуальный анализ данных для поиска необходимой информации и используют бизнес-аналитику, чтобы определить, почему это важно.
Доступ к кубам данных через BOARD.
Большие данные против интеллектуального анализа данных
Большие данные и интеллектуальный анализ данных отличаются как две отдельные концепции, описывающие взаимодействие с обширными источниками данных. Конечно, большие данные и интеллектуальный анализ данных по-прежнему связаны и относятся к сфере бизнес-аналитики. Хотя определение больших данных действительно различается, обычно его называют элементом или концепцией, в то время как интеллектуальный анализ данных считается скорее действием. Например, интеллектуальный анализ данных в некоторых случаях может включать анализ больших источников данных.
Большие данные, по некоторым определениям, включают в себя действие по обработке больших наборов данных. И наоборот, интеллектуальный анализ данных — это скорее сбор и идентификация данных. Интеллектуальный анализ данных обычно является шагом перед доступом к большим данным или действием, необходимым для доступа к источнику больших данных. Эти два компонента бизнес-аналитики работают в тандеме, чтобы определить наилучшие наборы данных, чтобы дать ответы на вопросы вашей организации. Следуя процессам, связанным с интеллектуальным анализом данных по сравнению с большими данными, аналитики могут начать оценку данных и в конечном итоге предложить предложения по улучшению бизнес-процедур на основе своих выводов.
Практика бизнес-аналитики — это не пошаговая операция. Это не так просто, как у меня, для данных, выполнить функцию обработки больших данных и выполнить анализ бизнес-аналитики. Анализ данных с целью использования этих данных для оказания влияния на бизнес-решения — это непрерывный, взаимосвязанный процесс. Во время анализа вы можете обнаружить, что вам нужны новые данные или что ваш текущий подход неэффективен. Необходимые корректировки, вносимые в ваши планы бизнес-аналитики по ходу дела, обеспечат точный и действительно глубокий анализ.
Кроме того, поскольку одной из целей бизнес-аналитики является предоставление информации в реальном времени, этот проект будет продолжаться. Вашей компании необходимо будет постоянно собирать и исследовать данные, чтобы получать самые актуальные информационные портреты.
Сравните лидеров по программному обеспечению бизнес-аналитики
Вкратце
Бизнес-аналитика, большие данные и интеллектуальный анализ данных — это три разные концепции, существующие в одной сфере. Бизнес-аналитику можно считать всеобъемлющей категорией, в которой существуют эти концепции, поскольку ее можно просто определить как анализ деловой практики на основе данных.Большие данные добываются и анализируются, что приводит к повышению эффективности бизнес-аналитики. Хотя эти три концепции различаются, бизнес-аналитика, большие данные и интеллектуальный анализ данных работают вместе, чтобы предоставлять аналитическую информацию на основе данных. Это инструменты, которые могут привести к лучшему пониманию вашего бизнеса и, в конечном итоге, к более оптимизированным процессам, которые увеличивают производительность и финансовую отдачу.
Как ваша организация использует бизнес-аналитику, большие данные и интеллектуальный анализ данных? Оставьте комментарий ниже.
7 основных различий между анализом данных и интеллектуальным анализом данных
С каждой секундой, которую мы проводим в сети, генерируются горы данных.Для каждой публикации в социальных сетях, поиска Google и нажатой ссылки существует способ сбора данных о нашей активности. Эксперты в области науки о данных могут использовать это, создавая значимую информацию для бизнеса. Компании могут использовать эти бесценные данные для развития своей клиентской базы. Это позволяет им осваивать новые технологии и платформы — они могут закрывать продажи, используя только социальные сети, или использовать ИИ, чтобы избежать отказа от корзины. Как? С помощью Data Analytics и Data Mining .
Хотя интеллектуальный анализ данных и аналитика данных являются подмножеством Business Intelligence , это почти все, что у них общего. Одно из ключевых различий между аналитикой данных и интеллектуальным анализом данных заключается в том, что последний является этапом процесса анализа данных. Действительно, аналитика данных имеет дело с каждым этапом процесса модели, управляемой данными, включая интеллектуальный анализ данных. Оба подпадают под сферу науки о данных.
Наука о данных для бизнес-аналитики
Для владельцев бизнеса знание поведения своей целевой аудитории и возможность извлекать выгоду из этой информации похоже на золотую пыль.
Вот где приходит на помощь наука о данных. Специалисты могут дать истинное представление о клиентах компании — они могут копнуть глубже и глубже, чем любой традиционный метод маркетинга. Это потому, что они могут основывать свое понимание на существенных доказательствах, а не на предположениях о том, чего может хотеть потребитель. Наука о данных использует обширные исследования, чтобы точно спрогнозировать, какие шаги может потребоваться предпринять бизнесу, чтобы привлечь свою аудиторию и улучшить удержание клиентов.
Как интеллектуальный анализ данных, так и аналитика данных необходимы, чтобы помочь бизнесу разработать стратегию своих следующих шагов.Оба демонстрируют свою ценность для Business Intelligence, но в чем именно заключаются основные различия между ними?
7 различий между анализом данных и интеллектуальным анализом данных
Размер команды
Интеллектуальный анализ данных может выполняться одним специалистом с отличными технологическими навыками. С правильным программным обеспечением они могут собирать данные , готовые для дальнейшего анализа. На данном этапе большая команда просто не требуется. Отсюда специалист по интеллектуальному анализу данных обычно сообщает о своих выводах клиенту, оставляя следующие шаги в чьих-то руках.
Однако, когда дело доходит до data analytics , может потребоваться команда специалистов. Им необходимо оценить данные, выяснить закономерности и сделать выводы. Они могут использовать машинное обучение или прогнозную аналитику, чтобы помочь с обработкой, но в этом все еще есть человеческий фактор.
Команды аналитики данных должны знать правильные вопросы, которые нужно задавать — например, если они работают в телефонной компании, они могут захотеть узнать ответ на вопрос, «как VoIP используется в бизнесе».Специалист по интеллектуальному анализу данных может предоставить доказательства того, где он используется и как часто, но аналитика данных раскрывает, как и почему.
Их цель — работать вместе, чтобы раскрыть информацию и выяснить, как собранные данные могут быть использованы для ответа на вопросы и решения проблем для бизнеса.
Искусственный интеллект достижений, вероятно, внесут серьезные изменения в процесс аналитики. Система искусственного интеллекта может анализировать сотни наборов данных и прогнозировать различные результаты, предлагая информацию о предпочтениях клиентов, разработке продуктов и возможностях маркетинга.
Системы на базе искусственного интеллекта скоро смогут выполнять второстепенные задачи для групп анализа данных, освобождая их время для более важной работы. Он может значительно повысить продуктивность специалистов по обработке данных, помогая автоматизировать элементы процесса анализа данных.
Структура данных
Когда дело доходит до интеллектуального анализа данных, исследования проводятся в основном на структурированных данных. Специалист будет использовать программы анализа данных для исследования и добычи данных.Они сообщают о своих выводах клиенту в виде графиков и таблиц. Часто это очень наглядное объяснение из-за сложного характера данных. Клиенты, как правило, не являются экспертами по интеллектуальному анализу данных, и не утверждают, что таковыми являются!
Итак, данные нужно довольно просто интерпретировать в графики или гистограммы. Как и в предыдущем примере с телефонной компанией, если клиенту необходимо знать данные о том, сколько людей щелкают ссылку «что такое номер VoIP» на своем веб-сайте, это должно быть отображено в легко читаемых диаграммах, а не в сложных документах.
Специалист по интеллектуальному анализу данных создает алгоритмы для определения структуры данных , которые затем можно интерпретировать. Он основан на математических и научных концепциях, что позволяет предприятиям собирать четкие и точные данные.
В этом отличие от аналитики данных, которая может выполняться на структурированных, полуструктурированных или неструктурированных данных . Они также не несут ответственности за создание алгоритмов, как специалисты по интеллектуальному анализу данных. Вместо этого им поручают выявлять закономерности в данных и использовать их, чтобы проинформировать клиента о его следующих шагах.
Затем это можно применить к бизнес-модели компании . Маркетинговая команда может захотеть, чтобы перед ними были выложены данные о своих клиентах и отрасли. Если они могут понять поведение потребителей конкурента, они могут применить это в своих собственных стратегиях.
Качество данных
Способ представления данных для интеллектуального анализа данных по сравнению с аналитикой данных различается. В то время как Data Mining используется для сбора данных и поиска закономерностей, Data Analytics проверяет гипотезу и преобразует полученные данные в доступную информацию.Это означает, что качество данных, с которыми они работают, может отличаться.
Специалист по майнинговому майнингу будет использовать большие наборы данных и извлекать из них наиболее полезные данные. Следовательно, поскольку они используют обширные и иногда бесплатные наборы данных, качество данных, с которыми они работают, не всегда будет на высшем уровне. Их работа состоит в том, чтобы извлекать из этого наиболее полезные данные и сообщать о своих выводах в понятной для бизнеса форме.
Однако аналитика данных включает в себя сбор данных и проверку их качества .Как правило, член группы аналитики данных будет работать с необработанными данными хорошего качества, которые являются настолько чистыми, насколько это возможно. Низкое качество данных может негативно повлиять на результаты, даже если процесс такой же, как и с чистыми данными. Это жизненно важный шаг в аналитике данных, поэтому команда должна проверить, достаточно ли качество данных для начала.
Проверка гипотез в области анализа и анализа данных
Гипотеза, по сути, является отправной точкой, требующей дальнейшего исследования, например, идея о том, что облачные базы данных — это путь вперед.Идея строится на ограниченных доказательствах, а затем исследуется дальше.
Ключевое различие между аналитикой данных и интеллектуальным анализом данных заключается в том, что интеллектуальный анализ данных не требует каких-либо предвзятых гипотез или представлений перед обработкой данных. Он просто компилирует его в полезные форматы. Однако для анализа данных нужна гипотеза, поскольку он ищет ответы на конкретные вопросы.
Интеллектуальный анализ данных — это выявление и обнаружение закономерностей. Специалист построит математическую или статистическую модель на основе полученных данных.Поскольку они не выдвигают гипотезы, специалисты по интеллектуальному анализу данных обычно работают с большими наборами данных, чтобы получить как можно более широкую сеть возможных полезных данных. Это дает им возможность сократить объем данных, гарантируя, что данные, которые у них остались в конце процесса, будут пригодными для использования и надежными. Этот процесс работает как воронка, начиная с больших наборов данных и фильтруя их в более ценные данные.
В отличие от этого, аналитика данных проверяет гипотезы, извлекая значимые идеи в рамках своих исследований.Это помогает в доказательстве гипотезы и может использовать открытия интеллектуального анализа данных в процессе. Например, бизнес может начинаться с такой гипотезы, как «Наличие бесплатного образца ссылки при оформлении заказа приведет к повышению коэффициента конверсии на 15%». Затем это можно реализовать и протестировать на веб-сайте.
Команда аналитиков данных будет работать над проверкой гипотезы, анализируя каждое посещение веб-сайта. Они могут даже провести сплит-тестов в A / B для размещения ссылок, где «A» оставляет образец ссылки вверху страницы, а «B» — внизу.Это дает еще более точное представление о поведении потребителей при покупке товаров и позволяет компании узнать, где лучше всего разместить ссылку на бесплатный образец.
Прогнозирование
Одна из задач специалиста по интеллектуальному анализу данных — прогнозировать , что можно интерпретировать на основе данных. Они находят шаблоны данных и отмечают, к чему они могут привести, используя разумные прогнозы на будущее.
Понимание того, как рынок может реагировать на определенные продукты или технологии, может быть важным для брендов и предприятий во многих секторах.Внедрение новой технологии, такой как номеронабиратель TCPA, приносит как риски, так и преимущества, а данные могут помочь бизнесу решить, подходит ли это решение для них.
Таким образом, работа, проводимая в процессе интеллектуального анализа данных, может оказаться важной для предприятий, которые полагаются на прогнозирование тенденций.
Кроме того, специалист по интеллектуальному анализу данных разбирается в данных, анализируя:
Кластеризация — исследование и запись групп данных, которые затем анализируются на основе сходства.
Отклонения — обнаружение аномалий в данных, а также как и почему это могло произойти.
Корреляции — изучение близости двух или более переменных, определение того, как они связаны друг с другом.
Классификация — поиск новых закономерностей в данных.
Все это помогает предприятиям принимать разумные решения на основе достоверных данных, полученных от их потребителей и рынка, на котором они работают.
С другой стороны, аналитика данных — это больше о , делающем выводы из данных .Частично он работает в сочетании с прогнозами интеллектуального анализа данных, помогая применять методы, основанные на его выводах. Прогнозирование не является частью процесса анализа данных, поскольку оно больше фокусируется на имеющихся данных. Они собирают, обрабатывают и анализируют данные. Затем они могут подготовить подробные отчеты, сделав собственные выводы.
Прогнозирование
не следует путать с прогнозным анализом , который учитывает различные входные данные для последующего прогнозирования будущего поведения. Он дает общее представление о прошлом, настоящем и будущем поведении потребителей.Таким образом, это также может быть применено к уже произошедшим событиям.
Прогностическая аналитика больше фокусируется на статистике для прогнозирования результатов. Это может быть полезно для предприятий, которые хотят оптимизировать маркетинговые кампании, хотя это не дает более глубокого понимания рынка.
Это отличается от прогнозирования, которое концентрируется на прогнозировании будущих тенденций на рынке на долгие годы.
Обязанности
Ожидания от результатов анализа данных и интеллектуального анализа данных различаются, потому что у обоих разные обязанности.
В то время как интеллектуальный анализ данных отвечает за обнаружение и извлечение закономерностей и структуры данных, аналитика данных разрабатывает модели и проверяет гипотезы с помощью аналитических методов.
Специалисты
Data Mining будут работать с тремя типами данных: метаданными, транзакционными и неоперационными. Это отражает их обязанности в процессе анализа данных. Данные о транзакциях производятся ежедневно для каждой «транзакции», отсюда и название. Сюда входят данные о кликах клиентов на веб-сайте.Например, если вы компания-разработчик программного обеспечения, вы можете отслеживать, сколько клиентов переходят по ссылкам с такими запросами, как «лучшие поставщики UCaaS».
Неоперационные данные — это данные, производимые сектором, которые могут быть использованы в интересах компании. Это включает в себя исследование данных для понимания, а затем прогнозирование на будущее. Более того, метаданные относятся к структуре базы данных и к тому, как в ней хранятся другие данные. Это включает разбиение данных на категории, такие как имена полей, длина, тип и т. Д.Поскольку она организована таким образом, специалистам легче извлекать, интерпретировать или использовать эту информацию.
Обязанности специалиста по интеллектуальному анализу данных часто связаны со способом сбора и представления данных. Вот пример того, как метаданные используются для организации информации и ее представления:
Однако в области анализа данных обязанности команды связаны не столько с алгоритмами, сколько с интерпретацией. Они предсказывают урожайность и интерпретируют базовое частотное распределение для непрерывных данных.Это делается для того, чтобы затем они могли сообщать соответствующие данные при выполнении своих задач.
Компании обычно обращаются к командам аналитиков данных за помощью в принятии важных стратегических решений. Это одна из их самых больших обязанностей. Вот различные типы данных, которые команда может проанализировать:
Взаимодействие с контентом в социальных сетях и активность в социальных сетях
Отзывы клиентов по электронной почте, опросам и фокус-группам
Посещения страниц и данные о посещениях в Интернете
Результаты этих исследований могут привести к новым возможностям получения дохода, а также к повышению эффективности внутри бизнес.В их обязанности входит обеспечение стабильных результатов, которые можно использовать в качестве руководства для будущего.
Специализация
Если вы планируете карьеру в области интеллектуального анализа данных или анализа данных, вам необходимо знать о различных областях знаний, необходимых для выполнения этой работы.
Data Mining — это сочетание машинного обучения, статистики и баз данных. Специалистам по интеллектуальному анализу данных необходимо освоить:
Опыт работы с такими операционными системами, как LINUX
Знание публичных выступлений
Языки программирования, такие как Javascript и Python
Инструменты анализа данных, такие как NoSQL и SAS
Знание отраслевых тенденций
Машинное обучение
Это уникальное сочетание технических, личных и деловых навыков делает специалиста по интеллектуальному анализу данных востребованным в отрасли.
Аналитика данных требует другого набора навыков, а именно в области информатики, математики, машинного обучения и статистики. Тем, кто хочет сделать карьеру в области анализа данных, необходимо иметь:
Хорошие отраслевые знания
Хорошие коммуникативные навыки
Инструменты анализа данных, такие как NoSQL и SAS, а также машинное обучение
Математические навыки для обработки числовых данных
Навыки критического мышления
Используя тех, у кого есть набор навыков, как Как описано выше, команды должны иметь возможность собирать и анализировать данные и предоставлять подробный отчет с использованием инструментов планирования проекта для процесса.Для того, чтобы собрать команду из людей, обладающих сильными навыками анализа данных, может потребоваться время в связи с особыми требованиями.
Использование аналитики и интеллектуального анализа данных для бизнес-планирования
Мы рассмотрели семь основных различий между анализом данных и анализом данных. Теперь важно понять, почему оба этих метода необходимы для бизнес-планирования .
Новое предприятие может обратиться к специалистам по интеллектуальному анализу данных и командам аналитиков, чтобы получить дополнительные знания о рынке, на который они хотят выйти.Эта информация может использоваться как часть их бизнес-плана и может даже помочь им в обеспечении инвестиций. Неудивительно, что бизнес-план, основанный на данных, привлекает инвесторов.
Он также может постоянно помогать бизнесу. Тот факт, что анализ данных может использоваться для прогнозирования будущих тенденций, не означает, что интеллектуальный анализ данных и анализ данных следует использовать только один раз. Компаниям может быть полезно продолжать анализировать свои данные, особенно в случае изменения экономики или потребительских привычек.Используя эту информацию, они могут следить за обслуживанием веб-сайтов электронной коммерции.
Известные компании также могут использовать анализ данных для оживления своего бренда. Аналитика может помочь брендам лучше понять, чего хочет их аудитория. Это может быть особенно полезно, если бренд чувствует, что его присутствие изменилось, или если они столкнулись с тем, что конкурент стал более успешным, чем они.
Хороший тому пример — факсимильные аппараты. До появления электронной почты факсимильные аппараты были актуальны и были на пике популярности.С появлением Интернета люди стали использовать их гораздо реже. Компании с сильной наукой о данных, возможно, опередили эту тенденцию, сосредоточившись на том, как отправлять факсы с компьютера, а не на выделенные машины. Это позволяет им оставаться актуальными и развиваться в соответствии с текущим рынком.
Несмотря на то, что между аналитикой данных и интеллектуальным анализом данных есть много различий, предприятиям следует использовать и то, и другое, если они хотят досконально понять, как они могут улучшить свой бренд и привлечь больше потребителей.
Аналитика больших данных: что это такое и почему это важно
Машинное обучение. Машинное обучение, особая разновидность ИИ, которая обучает машину обучению, позволяет быстро и автоматически создавать модели, которые могут анализировать более крупные и сложные данные и предоставлять более быстрые и точные результаты — даже в очень большом масштабе. А благодаря построению точных моделей у организации появляется больше шансов определить прибыльные возможности или избежать неизвестных рисков.
Управление данными. Данные должны быть высокого качества и хорошо управляемыми, прежде чем их можно будет надежно проанализировать. Поскольку данные постоянно поступают в организацию и исходят из нее, важно установить повторяемые процессы для создания и поддержания стандартов качества данных. Как только данные станут надежными, организациям следует разработать программу управления основными данными, которая объединит все предприятие на одной странице.
Интеллектуальный анализ данных. Технология интеллектуального анализа данных помогает исследовать большие объемы данных для выявления закономерностей в данных — и эту информацию можно использовать для дальнейшего анализа, чтобы помочь ответить на сложные бизнес-вопросы.С помощью программного обеспечения для интеллектуального анализа данных вы можете отсеивать весь хаотический и повторяющийся шум в данных, точно определять, что имеет значение, использовать эту информацию для оценки вероятных результатов, а затем ускорять темпы принятия обоснованных решений.
Hadoop. Эта программная среда с открытым исходным кодом может хранить большие объемы данных и запускать приложения на кластерах стандартного оборудования. Она стала ключевой технологией для ведения бизнеса из-за постоянного увеличения объемов и разновидностей данных, а ее модель распределенных вычислений быстро обрабатывает большие данные.Дополнительным преимуществом является то, что платформа с открытым исходным кодом Hadoop бесплатна и использует обычное оборудование для хранения больших объемов данных.
Аналитика в памяти. Анализируя данные из системной памяти (а не из жесткого диска), вы можете немедленно извлечь из своих данных информацию и быстро действовать в соответствии с ними. Эта технология позволяет устранить задержки при подготовке данных и аналитической обработке для тестирования новых сценариев и создания моделей; это не только простой способ для организаций оставаться гибкими и принимать более обоснованные бизнес-решения, он также позволяет им запускать итеративные и интерактивные сценарии аналитики.
Прогнозная аналитика. Технология прогнозной аналитики использует данные, статистические алгоритмы и методы машинного обучения для определения вероятности будущих результатов на основе исторических данных. Все дело в том, чтобы дать наилучшую оценку того, что произойдет в будущем, чтобы организации могли быть более уверены в том, что они принимают наилучшее бизнес-решение. Некоторые из наиболее распространенных приложений прогнозной аналитики включают обнаружение мошенничества, риски, операции и маркетинг.
Анализ текста. С помощью технологии интеллектуального анализа текста вы можете анализировать текстовые данные из Интернета, поля комментариев, книги и другие текстовые источники, чтобы раскрыть идеи, которых вы раньше не замечали. Интеллектуальный анализ текста использует машинное обучение или технологию обработки естественного языка для анализа документов — электронных писем, блогов, каналов Twitter, опросов, конкурентной разведки и т. Д. — чтобы помочь вам анализировать большие объемы информации и открывать новые темы и взаимосвязи между терминами.
Что такое интеллектуальный анализ данных? Типы и примеры
Популярная аналогия провозглашает, что данные — это «новая нефть», поэтому думайте о интеллектуальном анализе данных как о бурении и переработке нефти: интеллектуальный анализ данных — это средство, с помощью которого организации извлекают ценность из своих данных.
Говоря более практическим языком, интеллектуальный анализ данных включает в себя анализ данных для поиска закономерностей, корреляций, тенденций и аномалий, которые могут иметь значение для конкретного бизнеса. Таким образом, он тесно связан с большими данными, более широким термином, который охватывает множество вариантов использования программного обеспечения для анализа данных (например, распространенных приложений, таких как Zoho Analytics) для понимания тенденций.
Например, интеллектуальный анализ данных может помочь компаниям определить своих лучших клиентов. Организации могут использовать методы интеллектуального анализа данных, чтобы проанализировать предыдущую покупку конкретного клиента и спрогнозировать, что клиент, вероятно, купит в будущем.Он также может выделять необычные для покупателя покупки, которые могут указывать на мошенничество.
Компании могут использовать для поиска неэффективных производственных процессов, потенциальных дефектов в продуктах или слабых мест в цепочке поставок. Хорошая стратегия управления основными данными включает интеллектуальный анализ данных.
Часто методы интеллектуального анализа данных используются для анализа структурированных данных, находящихся в хранилищах данных. Однако компании также используют интеллектуальный анализ данных для извлечения информации из своих хранилищ неструктурированных данных, которые могут находиться в Hadoop или другом типе репозитория данных.
Сегодня интеллектуальный анализ всех типов данных стал частью нескончаемого стремления к достижению конкурентного преимущества.
Перейти к:
История интеллектуального анализа данных
Одна из первых статей, в которых использовалась фраза «интеллектуальный анализ данных», была опубликована Майклом С. Ловеллом в 1983 году. В то время Ловелл и многие другие экономисты довольно негативно относились к этой практике, полагая, что статистика может привести к неверным выводам. если не осведомлен о знании предмета.
Но к 1990-м годам идея извлечения ценности из данных путем выявления закономерностей стала гораздо более популярной. Поставщики баз данных и хранилищ данных начали использовать это модное слово для продвижения своего программного обеспечения. И компании начали осознавать потенциальные преимущества этой практики.
В 1996 году группа компаний, в которую входили Teradata и NCR, возглавила проект по стандартизации и формализации методологий интеллектуального анализа данных. Результатом их работы стал межотраслевой стандартный процесс интеллектуального анализа данных (CRISP-DM).Этот открытый стандарт разбивает процесс интеллектуального анализа данных на шесть этапов:
Деловое понимание
Понимание данных
Подготовка данных
Моделирование
Оценка
Развертывание
Такие компании, как IBM, продолжают продвигать модель CRISP-DM по сей день, и в 2015 году IBM выпустила обновленную версию, расширяющую базовую модель.
В начале 2000-х веб-компании начали осознавать силу интеллектуального анализа данных, и эта практика стала действительно популярной.Хотя фраза «интеллектуальный анализ данных» с тех пор была вытеснена другими модными словами, такими как «аналитика данных», «большие данные» и «машинное обучение», этот процесс остается неотъемлемой частью деловой практики. Фактически, будет справедливо сказать, что интеллектуальный анализ данных стал де-факто частью ведения современного бизнеса.
Типы интеллектуального анализа данных
Специалисты по обработке данных и аналитики используют множество различных методов интеллектуального анализа данных для достижения своих целей. Вот некоторые из наиболее распространенных:
Кластеризация включает поиск групп со схожими характеристиками.Например, маркетологи часто используют кластеризацию для определения групп и подгрупп на своих целевых рынках. Кластеризация полезна, когда вы не знаете, какие сходства могут существовать в ваших данных.
Классификация сортирует элементы (или отдельных лиц) по категориям на основе ранее изученной модели. Классификация часто происходит после кластеризации (хотя вы также можете обучить систему классификации данных на основе категорий, определяемых специалистом по данным или аналитиком). Кластеризация идентифицирует потенциальные группы в существующем наборе данных, а классификация помещает новые данные в соответствующую группу.Системы компьютерного зрения также используют системы классификации для идентификации объектов на изображениях.
Ассоциация определяет фрагменты данных, которые обычно находятся рядом друг с другом. Это метод, который управляет большинством систем рекомендаций, например, когда Amazon предлагает, что если вы купили один товар, вам может понравиться и другой товар.
Обнаружение аномалий ищет фрагменты данных, которые не соответствуют обычному шаблону. Эти методы очень полезны для обнаружения мошенничества.
Регрессия — это более продвинутый статистический инструмент, который широко используется в прогнозной аналитике. Это может помочь разработчикам социальных сетей и мобильных приложений повысить вовлеченность, а также помочь спрогнозировать будущие продажи и минимизировать риски. Регрессию и классификацию также можно использовать вместе в древовидной модели, которая полезна во многих различных ситуациях.
Анализ текста анализирует, как часто люди используют определенные слова. Это может быть полезно для анализа настроений или личности, а также для анализа сообщений в социальных сетях в маркетинговых целях или для выявления потенциальных утечек данных от сотрудников.
Суммирование помещает группу данных в более компактную и понятную форму. Например, вы можете использовать суммирование для создания графиков или вычисления средних значений по заданному набору данных. Это одна из самых привычных и доступных форм интеллектуального анализа данных.
Общие методы интеллектуального анализа данных
См. Полную таблицу
Метод интеллектуального анализа данных
Определение
Пример использования
Кластеризация
Поиск групп и подгрупп в данных
Целевой маркетинг
Классификация
Сортировка данных по категориям
Распознавание изображений
Ассоциация
Определение связанных частей данных
Рекомендация двигателя
Обнаружение аномалий
Поиск данных, которые не соответствуют обычным шаблонам
Обнаружение мошенничества
Регрессия
Прогнозирование наиболее вероятного результата по заданным переменным
Прогнозная аналитика и прогнозирование
Анализ текста
Анализ письменных слов
Анализ настроений
Обобщение
Уплотнение данных для облегчения понимания
Графики
Метод интеллектуального анализа данных
Определение
Пример использования
Кластеризация
Поиск групп и подгрупп в данных
Целевой маркетинг
Классификация
Сортировка данных по категориям
Распознавание изображений
Ассоциация
Определение связанных частей данных
Рекомендация двигателя
Обнаружение аномалий
Поиск данных, которые не соответствуют обычным шаблонам
Обнаружение мошенничества
Регрессия
Прогнозирование наиболее вероятного результата по заданным переменным
Прогнозная аналитика и прогнозирование
Анализ текста
Анализ письменных слов
Анализ настроений
Обобщение
Уплотнение данных для облегчения понимания
Графики
Концепции, относящиеся к интеллектуальному анализу данных
Интеллектуальный анализ данных пересекается с несколькими связанными терминами, и люди иногда используют эти термины в отношении схожих понятий.Вот некоторые из наиболее распространенных связанных идей:
Data Mining против KDD
В конце 1980-х — начале 1990-х годов ученые часто обсуждали открытие знаний в базах данных (KDD). Формальное определение процесса KDD включало пять этапов:
Выбор
Предварительная обработка
Преобразование
Интеллектуальный анализ данных
Устный перевод / оценка
Согласно этой структуре интеллектуальный анализ данных является эквивалентом анализа данных и является подкомпонентом KDD.Однако на практике люди часто использовали интеллектуальный анализ данных и KDD как синонимы. Со временем интеллектуальный анализ данных стал предпочтительным термином для обоих процессов, и сегодня большинство людей используют «интеллектуальный анализ данных» и «обнаружение знаний» для обозначения одного и того же.
Интеллектуальный анализ данных и машинное обучение
Машинное обучение — это отрасль глубокого обучения и искусственного интеллекта, цель которой — дать компьютерам возможность учиться без программирования. Некоторые методы, используемые в интеллектуальном анализе данных, в частности кластеризация, классификация и регрессия, также используются в машинном обучении.Таким образом, некоторые люди считают машинное обучение разновидностью интеллектуального анализа данных.
Однако другие люди утверждают, что между ними есть тонкие различия. Они говорят, что интеллектуальный анализ данных находит закономерности в данных, а затем машинное обучение использует результаты интеллектуального анализа данных, чтобы узнать что-то новое о данных.
Какую бы перспективу вы ни предпочли, эти две концепции явно перекрывают друг друга.
Интеллектуальный анализ данных против анализа больших данных
Люди часто используют термины «интеллектуальный анализ данных» и «анализ больших данных» или «анализ данных», чтобы означать одно и то же.Некоторые люди считают, что интеллектуальный анализ данных может выполняться как на небольших наборах данных, так и на «больших данных». А другие говорят, что аналитика данных может включать в себя методы, отличные от интеллектуального анализа данных, поэтому интеллектуальный анализ данных является подмножеством аналитики.
На практике эти термины почти взаимозаменяемы. Просто «интеллектуальный анализ данных» был популярным модным словом в 1990-х и начале 2000-х годов, в то время как «аналитика» стало более популярным модным словом сегодня.
Примеры интеллектуального анализа данных
Практически каждая компания на планете использует интеллектуальный анализ данных, поэтому примеров почти бесконечное количество.Один очень знакомый способ, которым розничные продавцы используют интеллектуальный анализ данных, — это анализировать покупки клиентов и затем отправлять покупателям купоны на товары, которые они могут захотеть приобрести в будущем.
Розничная торговля: В одном широко разрекламированном примере Target начала рассылать девочкам-подросткам купоны на детские товары, такие как подгузники, детское питание, смеси и т. Д. Ее разгневанный отец позвонил в компанию, чтобы пожаловаться, и фирма извинилась. Однако спустя несколько недель девочка обнаружила, что на самом деле беременна.В данном случае Target знала о своем состоянии раньше, чем она сама, основываясь исключительно на изменениях в ее покупательских привычках в отношении предметов, явно не связанных с уходом за ребенком.
Носитель: Вы также сталкиваетесь с результатами интеллектуального анализа данных каждый раз, когда смотрите шоу в потоковом сервисе, таком как Netflix или Hulu. Эти службы не только используют данные зрителей, чтобы рекомендовать шоу и фильмы, которые вы, возможно, хотели бы посмотреть, они также анализировали свои базы данных, чтобы выявить характеристики особенно популярных программ, а затем создать больше контента с этими атрибутами.Некоторые отраслевые обозреватели утверждают, что благодаря такому интеллектуальному анализу данных Netflix стал более успешным, чем голливудские студии, в определении и создании того контента, который нужен зрителям.
Публикация в Интернете: Такие компании, как Facebook и Google, также используют интеллектуальный анализ данных, чтобы помочь своим рекламодателям привлечь потребителей с помощью целевого контента. Этот процесс наиболее очевиден, когда вы делаете покупки на розничном сайте, а затем видите рекламу того же товара на Facebook. Однако рекламодатели также используют интеллектуальный анализ данных гораздо более тонкими способами, которые не всегда могут быть очевидны для посетителей сайта.Например, Facebook подвергается резкой критике за то, как рекламодатели могут нацеливать на избирателей сообщения, связанные с выборами. Эти скандалы вызвали большую обеспокоенность проблемами конфиденциальности интеллектуального анализа данных.
Проблемы конфиденциальности интеллектуального анализа данных
Все более изощренное использование компанией
интеллектуального анализа данных вызывает дискомфорт у многих потребителей. В США Конгресс и Федеральная торговая комиссия (FTC) созвали слушания по конфиденциальности данных, хотя эти усилия еще не привели к принятию всеобъемлющего законодательства.
Europe было необходимо быстрее решать проблемы конфиденциальности данных. В мае прошлого года вступил в силу Общий регламент по защите данных (GDPR), который затрагивает каждую организацию с любыми данными, относящимися к гражданам ЕС.
Среди прочего, закон требует, чтобы организации получали согласие на обработку данных, удаляли данные субъекта, если они запрашивали это, принимали адекватные меры безопасности для защиты данных и незамедлительно уведомляли людей, если их данные были задействованы в данные нарушения.
Несоблюдение требований может привести к штрафам в размере до 4% от общей глобальной выручки компании. Специалисты по отрасли прогнозируют, что GDPR и другие законы окажут серьезное влияние на интеллектуальный анализ данных, и ЕС уже оштрафовал Google на 50 миллионов евро за ненадлежащее соблюдение закона.
Инструменты интеллектуального анализа данных
Организациям доступен широкий спектр проприетарных и открытых инструментов интеллектуального анализа данных. Эти инструменты включают в себя хранилища данных, инструменты ELT, инструменты очистки данных, информационные панели, инструменты аналитики, инструменты анализа текста, инструменты бизнес-аналитики и другие.
История больших данных, науки о данных и интеллектуального анализа данных
Мы живем в мире, где объем данных в различных областях значительно увеличился. Веб-сайты отслеживают действия пользователей, маркетологи собирают историю покупок клиентов, так называемые «Quantified-Selfers» собирают данные о режиме сна и частоте пульса пользователя и т. Д.
При наличии огромных объемов данных большинство отраслей начали сосредотачиваться на извлечении из них ценной информации. Эти идеи могут дать предприятиям конкурентное преимущество на рынке и даже раннее обнаружение определенных заболеваний в области медицины.Способ проникновения в суть данных высвобождается из данных — это систематический анализ, который включает в себя различные этапы. Но прежде чем перейти к этому, давайте оглянемся назад, чтобы понять, с чего все это началось.
Еще в 1890-е
Появление огромных данных привело к вопросу « Как эффективно организовать и управлять большими наборами данных ». Одной из таких проблем с данными были данные переписи населения США 1890-х годов, вероятно, первая проблема с данными в Северной Америке. Для более эффективного управления данными переписи в США американский изобретатель Герман Холлерит использовал перфокарты, на которых хранятся данные о каждом человеке, и разработал машину, которая может считывать данные с перфокарт.
Успех машины Холлерита привел к созданию его собственной компании, The Tabulating Machine Company , которая слилась с двумя другими компаниями и позже стала известна как International Business Machines Corporation (IBM).
20 век
Закон о социальном обеспечении 1935 года, принятый правительством США под руководством Франклина Д. Рузвельта, был одним из таких масштабных проектов по сбору данных. Подрядчиком-победителем Закона о социальном обеспечении стала IBM.IBM собрала трудовые книжки 23 миллионов сотрудников и сохранила информацию на перфокартах.
Позже, в 1943 году в Блетчли-парке, на британском предприятии, отвечавшем за расшифровку нацистского кода во время Второй мировой войны, была разработана первая программируемая электронно-цифровая машина под названием «Колосс». Хотя Colossus был разработан для конкретной задачи криптоанализа, он обеспечивал надежные высокоскоростные вычисления и тем самым сокращал время с недель до часов.
Информационный взрыв
До 1950 года большинство проблем, связанных с данными, было связано с объемом, пока Агентство национальной безопасности США (АНБ) не признало второй ключевой компонент больших данных — скорость.Во время холодной войны криптологи в АНБ боролись с огромной информационной перегрузкой из-за автоматизированного сбора данных.
В 1961 году Дерек Прайс описал экспоненциальную скорость роста научных журналов и статей в своей публикации « Science Since Babylon ». Работа Прайса подчеркнула тот факт, что большие данные — это не только объем, но и скорость.
Для управления растущим объемом данных Гарри Дж. Грей и Генри Растон представили рекомендации в своей статье « Методы борьбы с информационным взрывом в 1964 году ».
В качестве альтернативы ограничению объема данных B. A Marron и P.A.D. де Мэн представил автоматическое сжатие данных, систему, которая может автоматически сжимать данные и декодировать их, когда это необходимо.
В 1974 году термин « data science » свободно использовал Питер Наур, датский ученый-компьютерщик и лауреат премии Тьюринга, в его книге под названием Краткий обзор компьютерных методов в Швеции и США . Наур определил науку о данных как: « Наука о работе с данными после того, как они были установлены, в то время как связь данных с тем, что они представляют, делегируется другим областям и наукам. ”
Вслед за этим в 1977 году была основана Международная ассоциация статистических вычислений (IASC) для преобразования данных в форму знаний и информации путем объединения традиционной статистической методологии, компьютерных технологий и экспертных знаний в предметной области. Постепенно наука о данных получила признание в отрасли. Будущее значение науки о данных было признано на конференциях Международной федерации классификационных обществ (IFCS) в 1996 году на конференции под названием «Наука о данных, классификация и связанные с ними методы».Поскольку целью IFCS является поддержка широкого диапазона разработок в области классификации и другого связанного с ними упорядочивания знаний, в их публикациях стали появляться термины «анализ данных», «наука о данных» и «интеллектуальный анализ данных».
1997 год стал годом появления больших данных и интеллектуального анализа данных. Журнал «Обнаружение знаний и интеллектуальный анализ данных» исследовал теорию, методы и соответствующие практики для извлечения знаний из больших баз данных. В том же году Майкл Кокс и Дэвид Эллсуорт ввели термин « big data » в своей статье « Управляемая приложениями подкачка запросов для визуализации вне ядра ».
Внедрение Hadoop оказало значительное влияние на революцию в области больших данных и изменило динамику и экономику крупномасштабных вычислений. Первоначально Hadoop был разработан для проекта поисковой системы Nutch Майклом Дж. Кафареллой и Дугом Каттингом. В конце концов, Hadoop позволил распределенную обработку больших наборов данных по кластерам серверов с высокой отказоустойчивостью.
С годами информационные технологии постоянно развивались. Так что и технологии баз данных тоже.Как и технологии хранилищ данных, появились и многие другие. Можно сказать, что эти большие наборы данных приводят к ситуации: данных богато, но мало информации .
Большие данные
Ниже приведены некоторые определения больших данных:
Дуг Лэйни в 2001 году описал большие данные как
«Задача трехмерных данных, связанная с увеличением объема, скорости и разнообразия данных».
Позже, в 2010 году, Apache Hadoop определил большие данные следующим образом:
«наборы данных, которые не могут быть захвачены, обработаны и обработаны обычными компьютерами в приемлемых пределах.”
Аналогичным образом Фонд TechAmerica определил большие данные как
«термин, описывающий большие объемы высокоскоростных, сложных и переменных данных, для которых требуются передовые методы и технологии, позволяющие осуществлять сбор, хранение, распространение, управление и анализ информации».
Дело в том, что большие данные относятся к массивным комплексным наборам данных, которые трудно хранить, анализировать и визуализировать для дальнейших процессов или результатов. Аналитика больших данных или Обнаружение знаний на основе данных (KDD) — это операции, предназначенные для получения информации и знаний из больших наборов данных.Корпоративные данные представляют собой пример больших наборов данных, которые включают данные из различных бизнес-функций, таких как производство, запасы, продажи, финансы и так далее. Влияние выполнения аналитики на большие наборы данных может привести предприятия к деятельности, основанной на данных, и принятию решений. Другой распространенный пример больших данных можно найти в парадигме Интернета вещей (IoT). Данные от различных типов датчиков приводят к большим скоплениям данных.
Как уже говорилось, характеристики больших данных делают чрезвычайно трудным получение полезных сведений.Чтобы лучше понять основные проблемы больших данных, рассмотрите следующую точку зрения:
Представьте, что несколько слепых пытаются исследовать гигантского слона — в этом контексте слон указывает на большие данные. Цель каждого слепого — нарисовать изображение слона на основе исследуемой части. Поскольку точка зрения каждого человека ограничена, их независимые выводы заканчиваются предвзятыми решениями, такими как веревка, стена, дерево или змея — как показано на рисунке ниже:
Слепые и гигантский слон: локализованный (ограниченный) взгляд каждого слепого человека приводит к необъективному выводу.
В этом случае, чтобы нарисовать лучшее изображение слона, необходимо агрегировать разнородную информацию из разных источников (слепых).
Три составляющих больших данных
Определение больших данных указывает на три основные характеристики больших данных: Volume , Velocity и Variety .
Объем указывает на размер данных — многие терабайты или петабайты.
Скорость указывает скорость, с которой генерируются данные, и насколько быстро эти сгенерированные данные обрабатываются.
Разновидность определяет структурную неоднородность набора данных. Наборы данных могут быть структурированными, частично структурированными и неструктурированными. Данные в табличной форме, которые можно увидеть в электронных таблицах и в реляционных базах данных, являются примерами структурированных данных, тогда как видео, аудио, текст и изображения неструктурированы. Примером полуструктурированных данных является Extensible Markup Language (XML).
Есть ли бенчмарки по этим характеристикам? № .
И это единственные характеристики большого набора данных? И снова ответ — нет .
Универсального эталона для объема, разнообразия и скорости не существует, поскольку пределы для этих характеристик зависят от размера, сектора, а также местоположения фирмы. Самое главное, что размеры больших данных не независимы друг от друга. Это означает, что изменение одного измерения, вероятно, приведет к изменению и другого измерения.
В дополнение к основным трем V появились еще три измерения. Это Veracity , Variability и Value .
Верность : Верность была придумана IBM и представляет качество, надежность и неопределенность данных. Например, настроения пользователей в социальных сетях неопределенны по своей природе.
Изменчивость (и сложность) : Изменчивость и сложность — два других измерения больших данных, добавленных SAS. Вариабельность означает изменение скорости потока данных. Чаще всего скорость больших данных непостоянна и имеет периодические пики и спады. Сложность указывает на большие данные, которые генерируются из множества источников, что может стать серьезной проблемой.
Значение : значение считается определяющим атрибутом больших данных, введенным Oracle. Значение указывает на открытие практических знаний. Часто большие данные в их первоначальном виде рассматриваются как относительно «малоценная плотность». Более высокое значение получается при анализе больших объемов таких данных.
Наука о данных
Термин наука обозначает систематическое изучение для получения знаний. Точно так же термин наука о данных подразумевает исследование для обобщаемого извлечения знаний из данных.Провост и Фосетт (2013) описали науку о данных как
«набор фундаментальных принципов, которые поддерживают и направляют принципиальное извлечение информации и знаний из данных».
Как говорится в определении, наука о данных — это больше о ключевых принципах, лежащих в основе процесса анализа данных, а не полагаться на какой-либо конкретный алгоритм или метод. Схема Data science — краткий набор фундаментальных принципов для систематического и принципиального извлечения информации и знаний из данных.Чаще всего наука о данных пересекается с аналитикой больших данных. Это означает, что анализ наборов больших данных требует применения фундаментальных принципов науки о данных.
Один из знакомых примеров использования науки о данных в контексте больших данных — Amazon, хранящий поисковые запросы пользователей. Сохраненные поисковые запросы пользователей соотносятся с «, что конкретный пользователь ищет для » с «, что другие пользователи ищут по запросу », и тем самым выдает удивительно подходящие рекомендации. Другой аналогичный сценарий — поиск и рекомендации Google на YouTube.Не только Google и Amazon эффективно используют данные: многие другие компании, включая Facebook, Twitter и LinkedIn, осознали потенциальное влияние аналитики данных.
Когда дело доходит до науки о данных, мы можем сказать, что это улучшение процесса принятия решений в общем смысле. Такое принятие решений часто называют Принятие решений на основе данных , процесс принятия решений на основе анализа данных. В случае поиска на Amazon результатом является компьютеризированное решение по мерчандайзингу.
Существует несколько принципов и концепций науки о данных, которые хорошо изучены как теоретически, так и эмпирически. Одна из фундаментальных концепций науки о данных, упомянутых Провостом и Фосеттом (2013), заключается в следующем: При оценке результатов науки о данных следует тщательно учитывать контекст . Эта концепция указывает на то, что применимость решения, предлагаемого по результатам, зависит от бизнес-вопроса. Для рекомендаций Amazon оценка этих рекомендаций должна выполняться, задавая соответствующие вопросы следующим образом:
Приводит ли рекомендация к увеличению продаж, чем некоторые другие возможные альтернативы?
Насколько хорошо одна рекомендация продалась бы случайно?
Наука о данных — это многопрофильная область.Следовательно, наука о данных включает в себя методы и теории, взятые из многих дисциплин, таких как информатика, статистика, а также знания в предметной области. Чтобы продемонстрировать взаимосвязь науки о данных с другими дисциплинами, американский специалист по данным Дрю Конвей построил диаграмму Венна, как показано ниже.
Наука о данных — диаграмма Венна
Жизненный цикл науки о данных
Помимо этого разнообразия дисциплин, наука о данных включает в себя различные процессы на протяжении жизненного цикла аналитики, часто известного как жизненный цикл науки о данных .
Жизненный цикл науки о данных
Можно сказать, что жизненный цикл науки о данных начинается с бизнес-задачи, которую необходимо решить. Очень редко бизнес-проблема имеет прямую корреляцию с набором данных. Следовательно, мы должны разложить проблему на подзадачи. Начиная с исследования данных для решения бизнес-задачи, затем следует подготовка набора данных. Стадия подготовки данных часто включает обработку данных , процесс итеративного исследования и преобразования данных, позволяющий проводить анализ.Другими словами, обработка данных — это процесс улучшения качества данных перед анализом.
После подготовки данных следующим этапом является планирование модели. На высоком уровне моделирование данных — это фундаментальный процесс, который сопоставляет данные с решением бизнес-задач. По сути, планирование модели определяет, какие алгоритмы и функции использовать для построения модели. Эти алгоритмы могут включать в себя статистику и методы машинного обучения.
Элементы — это основные строительные блоки моделей, которые представляют отдельное свойство или атрибут набора данных.Мы вводим характеристики в модель, чтобы генерировать результаты. Следовательно, качество функций имеет большое влияние на качество результатов модели. В результате большинство проектов в области науки о данных включает процесс, известный как , разработка функций для улучшения результатов модели. При разработке функций данные агрегируются в некую каноническую форму, так называемые функции, которые лучше представляют основную проблему для моделей.
Следующим этапом является разработка модели, которая включает в себя реализацию и проверку модели.Цель этого этапа — повысить точность результатов, полученных с помощью модели. После этого результаты модели должны быть эффективно представлены, что включает в себя визуализацию результатов. Наконец, модель должна быть развернута.
На протяжении всего жизненного цикла науки о данных главный момент, который следует учитывать, — это то, что каждая фаза жизненного цикла науки о данных одинаково важна, и ее не следует пропускать при рассмотрении применения методов науки о данных для решения бизнес-задачи.
Интеллектуальный анализ данных
Во многих источниках термины «интеллектуальный анализ данных» и «« Обнаружение знаний из данных »(KDD) упоминаются как взаимозаменяемые. В то время как другие рассматривают интеллектуальный анализ данных как подпроцесс обнаружения знаний из данных. Обычно используемое определение KDD Fayyad et al. выглядит следующим образом:
«Нетривиальный процесс выявления достоверных, новых, потенциально полезных и в конечном итоге понятных закономерностей в данных».
Являясь важным этапом KDD, а также рассматриваемым как общий процесс KDD, интеллектуальный анализ данных определяется как процесс, который включает «обнаружение интересных, неожиданных или ценных структур в больших наборах данных».Следующая диаграмма процесса KDD иллюстрирует интеллектуальный анализ данных как подпроцесс KDD. Как вы можете видеть на этой диаграмме, входом в этот общий процесс KDD являются данные, а результатом — знания. Предположим, что данные состоят из данных о продажах организации за предыдущие годы, тогда одно из полезных знаний, которые можно извлечь из данных, — это прогноз продаж в наступающем году.
Процесс обнаружения знаний из данных (KDD)
Перед интеллектуальным анализом данных необработанные данные подвергаются предварительной обработке, и после завершения процесса интеллектуального анализа данных должна быть проведена оценка / интерпретация результатов интеллектуального анализа.Затем извлеченные знания должны быть четко переданы посредством визуализации.
Когда дело доходит до методов и алгоритмов, интеллектуальный анализ данных уходит корнями в машинное обучение и статистику. Таким образом, мы можем сказать, что интеллектуальный анализ данных частично совпадает с машинным обучением и статистическими методами. Например, кластеризация — это метод машинного обучения, который также используется в качестве метода интеллектуального анализа данных для группировки данных по категориям.
Самая большая неразбериха…
Какое-то время я занимался исследованием данных и пытался понять, что на самом деле означает интеллектуальный анализ данных.Я скажу почему. В Интернете есть много сообщений и статей, в которых утверждается, что интеллектуальный анализ данных и наука о данных — это одно и то же. Некоторые говорят, что наука о данных — это новое модное слово для интеллектуального анализа данных. Как я уже упоминал ранее, термины интеллектуальный анализ данных и обнаружение знаний из данных используются в некоторых местах как синонимы, тогда как некоторые другие рассматривают интеллектуальный анализ данных как подпроцесс KDD. Помимо KDD, существует несколько других терминов, которые имеют такое же значение, что и интеллектуальный анализ данных, а именно: извлечение знаний из данных, извлечение знаний, анализ данных / шаблонов, археология данных и извлечение данных.
Теперь вы видите путаницу…
После небольшого исследования этих тем я хотел бы придерживаться точки зрения, упомянутой Вил М. П. ван дер Аалстом в его книге «Процесс интеллектуального анализа данных: наука о данных в действии». Науку о данных можно рассматривать как новую развивающуюся дисциплину в последние годы, и Алст предложил следующее определение науки о данных:
«Наука о данных — это междисциплинарная область, цель которой — превратить данные в реальную ценность. Данные могут быть структурированными или неструктурированными, большими или маленькими, статическими или потоковыми.Ценность может быть предоставлена в форме прогнозов, автоматизированных решений, моделей, извлеченных из данных, или любого типа визуализации данных, обеспечивающего понимание. Наука о данных включает в себя извлечение данных, подготовку данных, исследование данных, преобразование, хранение и поиск данных, вычислительную инфраструктуру, различные типы интеллектуального анализа данных и обучения, представление объяснений и прогнозов, а также использование результатов с учетом этических, социальных, юридических и Деловые аспекты »
Согласно определению, наука о данных может рассматриваться как объединение классических дисциплин, таких как статистика, интеллектуальный анализ данных, базы данных и распределенные системы.В то время как интеллектуальный анализ данных можно рассматривать как важную часть дисциплины науки о данных.
Baldassarre, M., 2016. Мыслите масштабно: контексты обучения, алгоритмы и …
Бихлер, М., Хайнцл, А. и ван дер Аалст, У.М., 2017. Бизнес-аналитика …
Чен, М., Мао, С. и Лю, Ю., 2014. Большие данные: обзор. Мобильная сеть …
Коенен, Ф., 2011. Интеллектуальный анализ данных: прошлое, настоящее и будущее. Знание …
Дхар, В., 2012. Наука о данных и прогнозирование.
Файяд, У., Пятецкий-Шапиро, Г., Смит, П., 1996. Из данных mi …
Гандоми, А. и Хайдер, М., 2015. Помимо шумихи: концепция больших данных …
Хан, Дж., Пей, Дж. И Камбер, М., 2011. Интеллектуальный анализ данных: концепции и те …
Провост, Ф. и Фосетт, Т., 2013. Наука о данных и ее взаимосвязи …
Родригес П., Паломино Н. и Мондака Дж., 2017. Использование больших данных и …
Песня, И. и Чжу Ю., 2016. Большие данные и наука о данных: что делать …
Van Der Aalst, W., 2016. Наука о данных в действии. В процессе добычи …
White, T., 2012. Hadoop: Полное руководство. «O’Reilly Media, In …
Wu, X., Zhu, X., Wu, G.Q. and Ding, W., 2014. Интеллектуальный анализ данных с …
Сарате Сантовена, А., 2013. Большие данные: эволюция, компоненты, вызовы …
История больших данных, науки о данных и интеллектуального анализа данных Арьи Налинкумар находится под лицензией Creative Commons Attribution-NonCommercial 4.


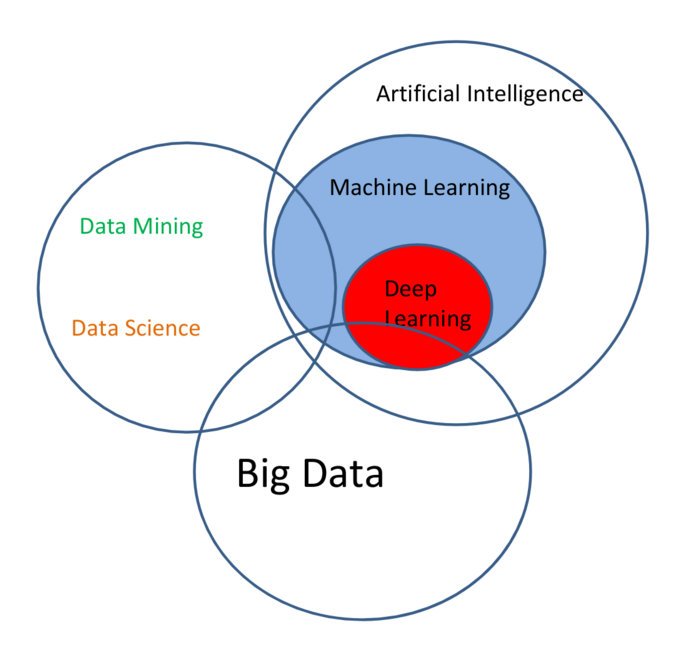
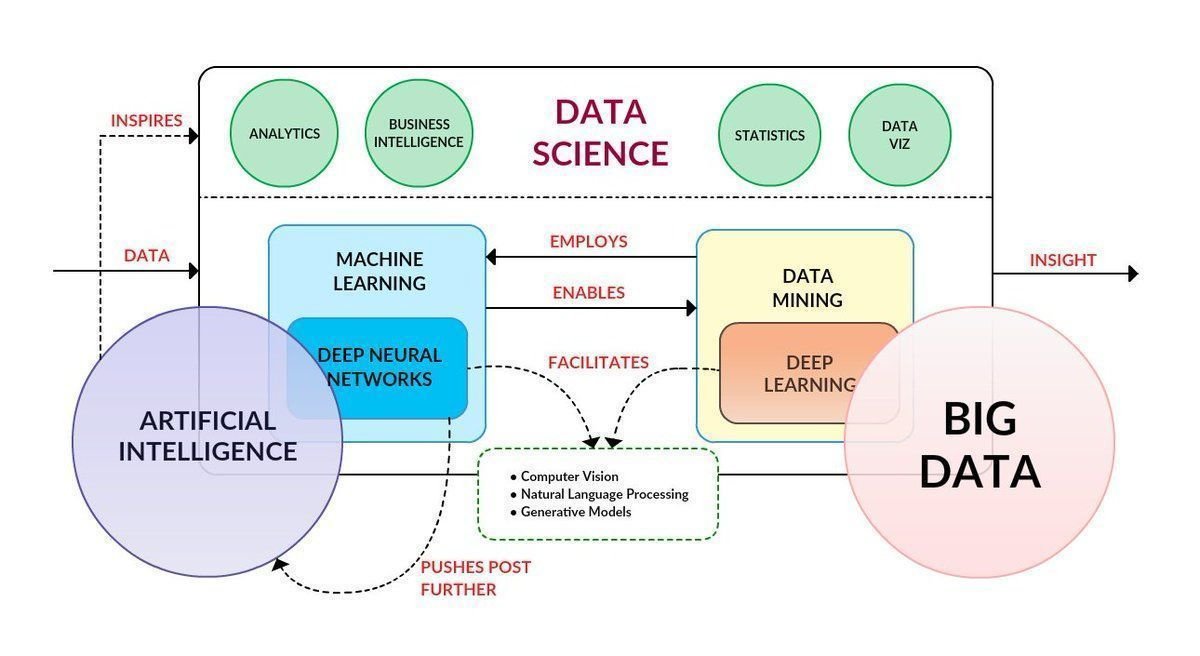 Выборка данных — это этап, в котором из большой базы данных выбираются и извлекаются только полезные данные.
Выборка данных — это этап, в котором из большой базы данных выбираются и извлекаются только полезные данные. Специалисты по интеллектуальному анализу данных могут воспользоваться мощными инструментами добычи данных, однако им требуются специалисты для подготовки данных и понимания результатов. В результате на обработку всей информации может потребоваться некоторое время.
Специалисты по интеллектуальному анализу данных могут воспользоваться мощными инструментами добычи данных, однако им требуются специалисты для подготовки данных и понимания результатов. В результате на обработку всей информации может потребоваться некоторое время.


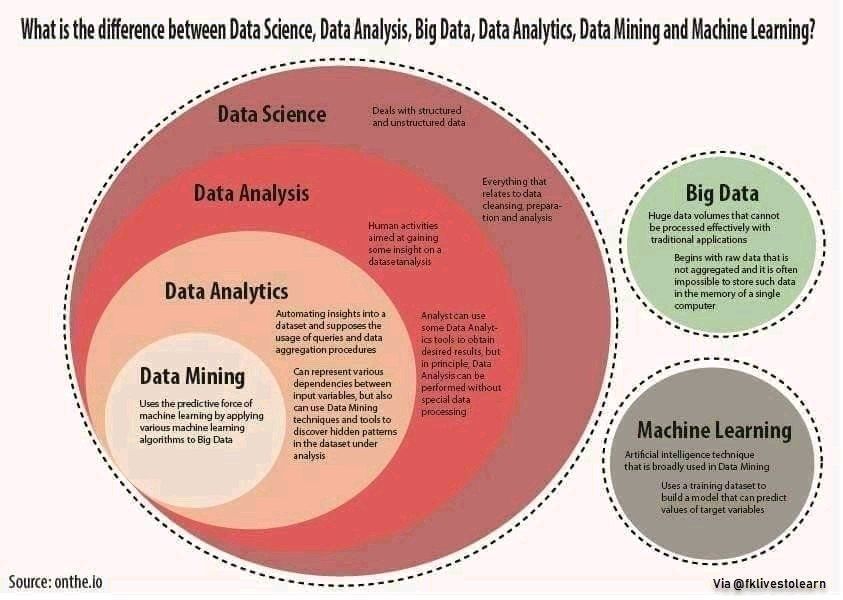
 Если вы опытный программист, который хочет извлечь данные, вышеуказанные шаги могут показаться вам простыми. Однако, если вы не программируете, есть короткий путь — использовать инструменты извлечения данных, например Octoparse. Инструменты data extraction, так же как и инструменты data mining, разработаны для того, чтобы сэкономить энергию и сделать обработку данных простой для всех. Эти инструменты не только экономичны, но и удобны для начинающих. Они позволяют пользователям собирать данные в течение нескольких минут, хранить их в облаке и экспортировать их во многие форматы: Excel, CSV, HTML, JSON или в базы данных на сайте через API.
Если вы опытный программист, который хочет извлечь данные, вышеуказанные шаги могут показаться вам простыми. Однако, если вы не программируете, есть короткий путь — использовать инструменты извлечения данных, например Octoparse. Инструменты data extraction, так же как и инструменты data mining, разработаны для того, чтобы сэкономить энергию и сделать обработку данных простой для всех. Эти инструменты не только экономичны, но и удобны для начинающих. Они позволяют пользователям собирать данные в течение нескольких минут, хранить их в облаке и экспортировать их во многие форматы: Excel, CSV, HTML, JSON или в базы данных на сайте через API. Ресурс может полностью запретить IP-адрес или ограничить доступ, сделав данные неполными. Чтобы извлекать данные и избегать блокировки, нужно делать это с умеренной скоростью и применять некоторые методы антиблокировки.
Ресурс может полностью запретить IP-адрес или ограничить доступ, сделав данные неполными. Чтобы извлекать данные и избегать блокировки, нужно делать это с умеренной скоростью и применять некоторые методы антиблокировки.
 Определение
Определение
 В IT-среде появился устойчивый термин — Data Mining.
В IT-среде появился устойчивый термин — Data Mining. Или сопоставить увеличение количества запросов от новых клиентов из региона в электронной почте и увеличение времени в командировках (информация из «1С:Документооборот»).
Или сопоставить увеличение количества запросов от новых клиентов из региона в электронной почте и увеличение времени в командировках (информация из «1С:Документооборот»). ПРОДВИНУТЫЕ ВОЗМОЖНОСТИ БИБЛИОТЕК ЯЗЫКА PYTHON ДЛЯ ОБРАБОТКИ И ВИЗУАЛИЗАЦИИ ДАННЫХ
ПРОДВИНУТЫЕ ВОЗМОЖНОСТИ БИБЛИОТЕК ЯЗЫКА PYTHON ДЛЯ ОБРАБОТКИ И ВИЗУАЛИЗАЦИИ ДАННЫХ
 ПОДХОДЫ К ПОСТРОЕНИЮ ДОПОЛНИТЕЛЬНОГО ПРИЗНАКОВОГО ПРОСТРАНСТВА НА ОСНОВЕ ИСХОДНЫХ ДАННЫХ
ПОДХОДЫ К ПОСТРОЕНИЮ ДОПОЛНИТЕЛЬНОГО ПРИЗНАКОВОГО ПРОСТРАНСТВА НА ОСНОВЕ ИСХОДНЫХ ДАННЫХ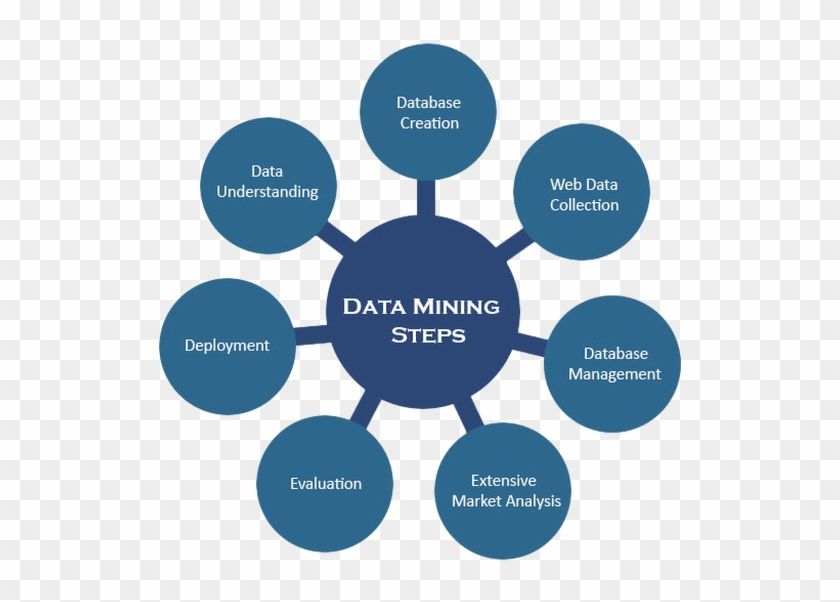 ПРОЕКТНАЯ РАБОТА
ПРОЕКТНАЯ РАБОТА Пушкина Ольга Шишко, генеральный директор британского агентства «The Audience» Энн Торрегиани, специалист по визуализации данных, эксперт программы «Будущие и развивающиеся технологии» Европейской комиссии (Германия) Моритц Стефанер.
Пушкина Ольга Шишко, генеральный директор британского агентства «The Audience» Энн Торрегиани, специалист по визуализации данных, эксперт программы «Будущие и развивающиеся технологии» Европейской комиссии (Германия) Моритц Стефанер. Научиться умно и тонко управлять его эмоциями, намерениями и действиями в гуманитарно-культурных целях», – отметила Светлана Миронюк, академический директор программы «Big Data и цифровой маркетинг» Московской школы управления «Сколково», исполнительный директор PWC Audit.
Научиться умно и тонко управлять его эмоциями, намерениями и действиями в гуманитарно-культурных целях», – отметила Светлана Миронюк, академический директор программы «Big Data и цифровой маркетинг» Московской школы управления «Сколково», исполнительный директор PWC Audit. Поэтому Big Data можно и нужно использовать и в культуре», – подчеркнул он.
Поэтому Big Data можно и нужно использовать и в культуре», – подчеркнул он. Он получает понимание путем тщательного извлечения, анализа и обработки огромных данных, чтобы выявить закономерности и взаимосвязи, которые могут быть важны для бизнеса. Это аналогично золотодобыче, когда золото добывается из горных пород и песков.
Он получает понимание путем тщательного извлечения, анализа и обработки огромных данных, чтобы выявить закономерности и взаимосвязи, которые могут быть важны для бизнеса. Это аналогично золотодобыче, когда золото добывается из горных пород и песков.
 Данные могут быть как большими, так и маленькими.
Данные могут быть как большими, так и маленькими.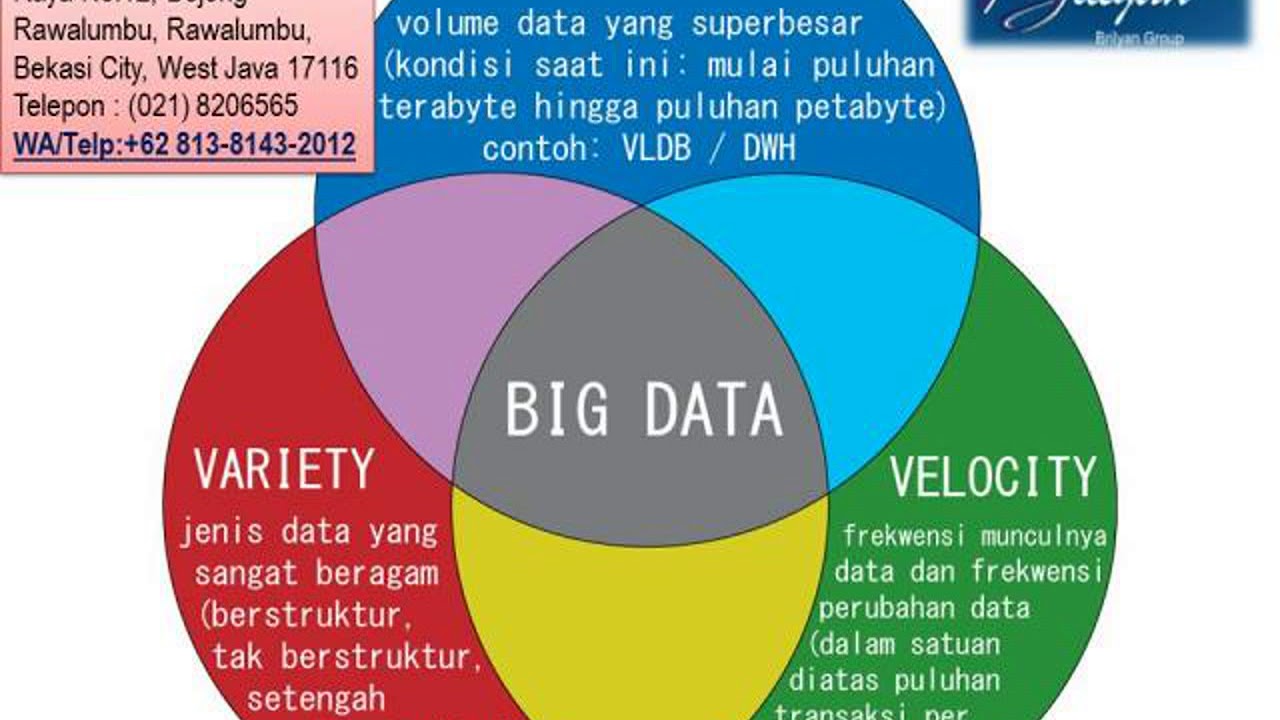


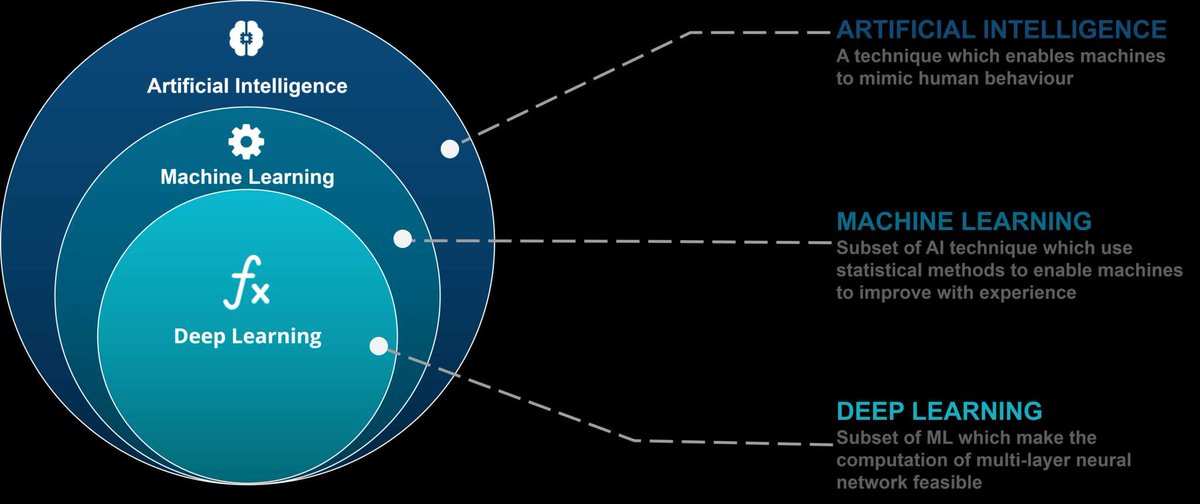
 Дерево решений, по сути, начинается с вопроса, который имеет два или более результата, которые, в свою очередь, соединяются с другими вопросами, что в конечном итоге приводит к действию, например, отправить предупреждение или инициировать сигнал тревоги, если проанализированные данные приводят к конкретным ответам.
Дерево решений, по сути, начинается с вопроса, который имеет два или более результата, которые, в свою очередь, соединяются с другими вопросами, что в конечном итоге приводит к действию, например, отправить предупреждение или инициировать сигнал тревоги, если проанализированные данные приводят к конкретным ответам.


 Это может привести к тому, что некоторые организации столкнутся с лавиной информации, которая в случае неправильного управления может создать больше проблем, чем решений.
Это может привести к тому, что некоторые организации столкнутся с лавиной информации, которая в случае неправильного управления может создать больше проблем, чем решений. твердо на краю.
твердо на краю.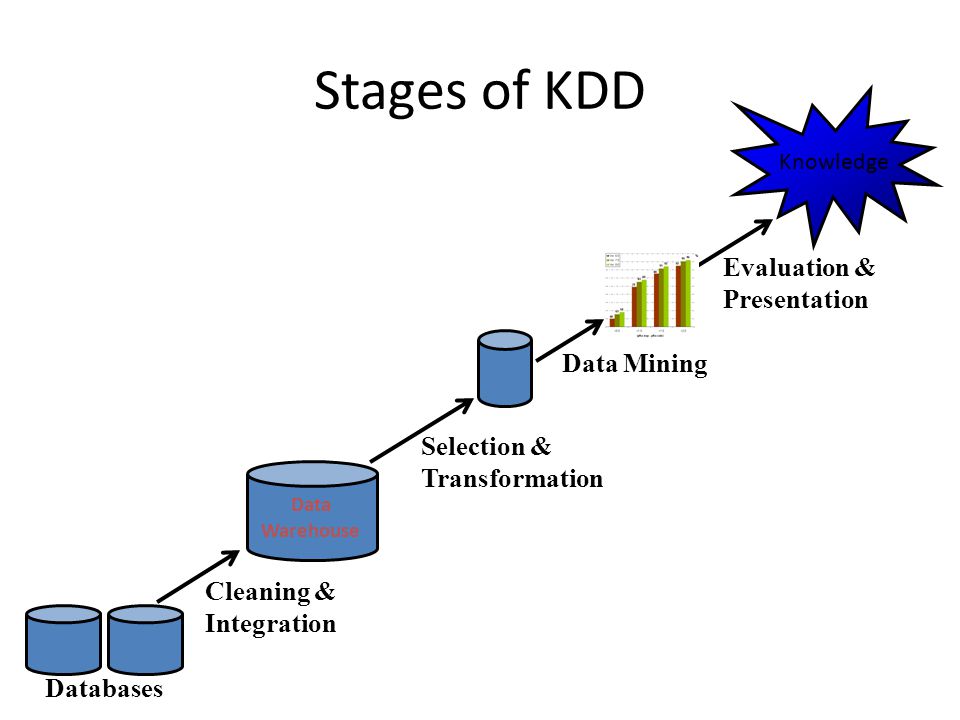
 Достижения в облачных технологиях и мобильных приложениях позволили предприятиям и ИТ-пользователям взаимодействовать совершенно по-новому. Одной из самых быстрорастущих технологий в этой сфере является бизнес-аналитика и связанные с ней концепции, такие как большие данные и интеллектуальный анализ данных.
Достижения в облачных технологиях и мобильных приложениях позволили предприятиям и ИТ-пользователям взаимодействовать совершенно по-новому. Одной из самых быстрорастущих технологий в этой сфере является бизнес-аналитика и связанные с ней концепции, такие как большие данные и интеллектуальный анализ данных. Помимо стандартных показателей, таких как финансовые показатели, углубленная бизнес-аналитика выявляет влияние текущих практик на производительность сотрудников, общую удовлетворенность компании, конверсии, охват СМИ и ряд других факторов.
Помимо стандартных показателей, таких как финансовые показатели, углубленная бизнес-аналитика выявляет влияние текущих практик на производительность сотрудников, общую удовлетворенность компании, конверсии, охват СМИ и ряд других факторов. Например, данные, которые нельзя легко обработать в электронных таблицах Excel, могут называться большими данными.
Например, данные, которые нельзя легко обработать в электронных таблицах Excel, могут называться большими данными.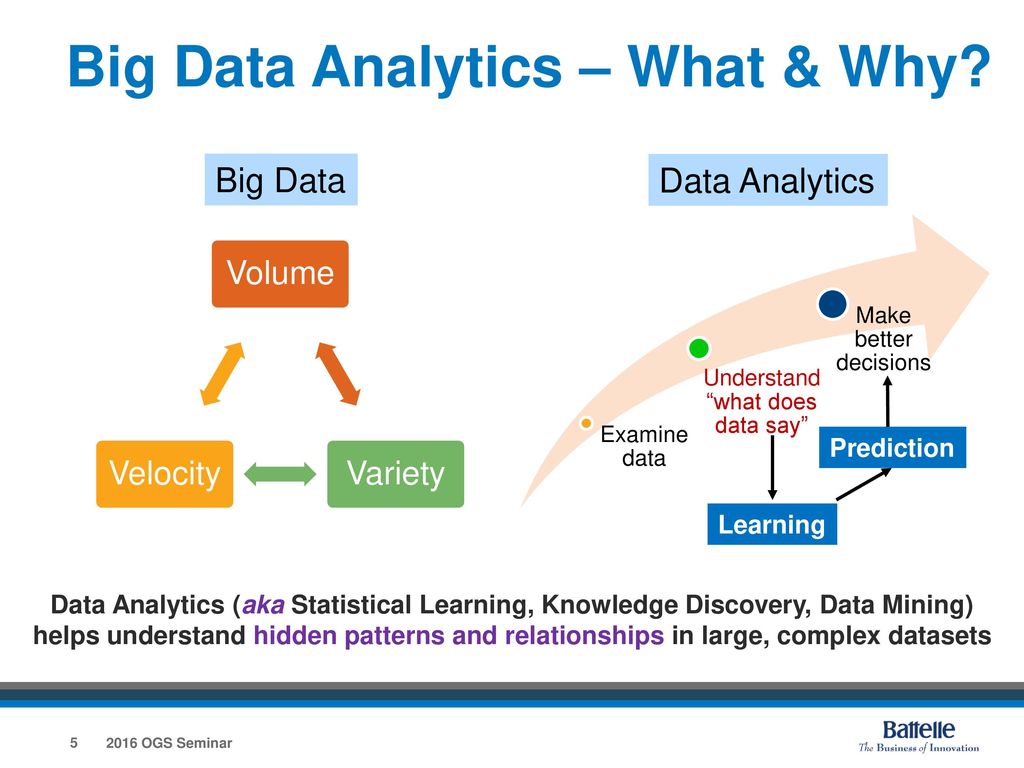

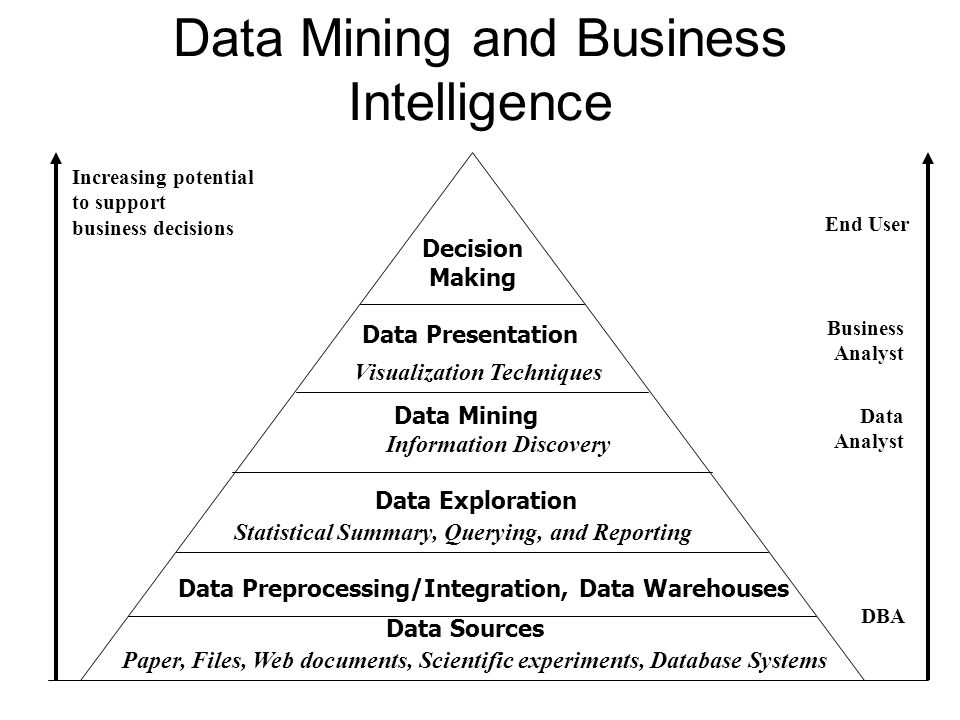 При сравнении больших данных и бизнес-аналитики некоторые люди используют термин большие данные, когда речь идет о размере данных, в то время как другие используют этот термин в отношении конкретных подходов к аналитике.
При сравнении больших данных и бизнес-аналитики некоторые люди используют термин большие данные, когда речь идет о размере данных, в то время как другие используют этот термин в отношении конкретных подходов к аналитике.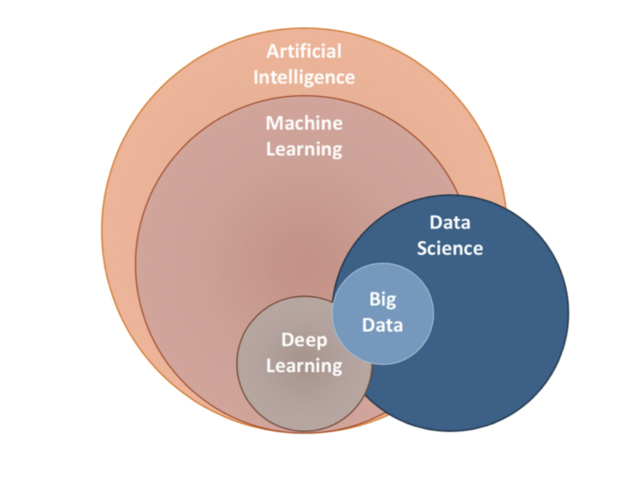 С другой стороны, большие данные состоят только из этих больших наборов данных.
С другой стороны, большие данные состоят только из этих больших наборов данных.