«Нет единственно возможного пути». Как начать изучение AI и machine learning с нуля (+список курсов)
Это ещё один пример успешного человека, который сам с нуля прошёл путь до инженера машинного обучения. Разработчик Дэниэл Бурк поделился своей историей на Hacker Noon.
Я работал в магазине Apple, но хотел изменить свою жизнь и создавать технологии, которые обслуживал. Я начал интересоваться машинным обучением (МО) и искусственным интеллектом (ИИ). Это очень насыщенная и динамичная сфера: кажется, каждый день Google и Facebook выпускают новые ИИ-продукты, которые делают жизнь человека проще и удобнее. Не говоря уже о количестве компаний, разрабатывающих беспилотные авто.
Но вместе с тем общепринятого определения «искусственного интеллекта» ещё нет. Одни считают, что к ИИ можно отнести глубокое обучение, другие — что только те системы, которые прошли тест Тьюринга. Отсутствие чёткого понятия поначалу сбивало с толку: было трудно изучать что-то, под чем понимают много разных вещей.
Но нужно было с чего-то начать.
У меня был неудавшийся веб-стартап, но я всё больше слышал о МО и ИИ. Я не верил, что машина может обучаться чему-то, как человек.
Мне попался курс по глубокому обучению на Udacity. В одном из промо-роликов был харизматичный разработчик Сираж Равал. Его энергетика была так заразительна, что я решил записаться на курс, хотя не проходил по базовым требованиям (к тому моменту я не написал ни строчки на Python). За три недели до старта я спросил в поддержке Udacity о компенсации: боялся, что не потяну программу.
Компенсация не понадобилась, потому что я закончил курс в срок. Было непросто, а иногда — даже очень сложно. Два первых проекта я сдал на четыре дня позже дедлайна, но восторг от того, что я прикоснулся к одной из самых важных технологий в мире, подталкивал меня вперёд.
После окончания курса по глубокому обучению я точно проходил на курсы по ИИ, беспилотным автомобилям или робототехнике. Все варианты отличные, но я не знал, какой лучше выбрать. Мне был нужен план. Первый курс помог заложить фундамент, и теперь нужно было решить, куда развиваться дальше.
Мне был нужен план. Первый курс помог заложить фундамент, и теперь нужно было решить, куда развиваться дальше.
Я создал свою программу изучения ИИ.
Я не собирался возвращаться в университет, тем более у меня не было лишних $100 тысяч на магистратуру. Поэтому я сделал то, что и вначале: обратился к своему ментору — гуглу, посмотрел несколько курсов и составил список самых интересных в Trello.
У онлайн-курсов высокий процент отсева слушателей. Но у меня была цель, и я решил идти до конца. А чтобы не отступать, начал делиться своими успехами в сети. Так я тренировался объяснять то, чему научился, и смог найти единомышленников. Я открыл доступ к доске в Trello и написал пост о своих начинаниях.
Со временем программа немного изменилась, но она по-прежнему актуальна. Я заглядываю на доску несколько раз в неделю, чтобы отслеживать прогресс в делах.
Потом я получил работу.
Я купил билет на самолёт до США в один конец. Я учился уже год: пришло время найти работу и применить эти навыки на практике.
Однажды мне написали из компании Max Kelsen на LinkedIn и предложили встретиться. Я рассказал о том, как проходил онлайн-курсы, как решил перебраться в США и что увлекаюсь медицинскими технологиями. Мне устроили встречу с командой, которая занималась этими технологиями, а потом с генеральным директором и главным инженером МО компании. В итоге они предложили мне остаться на год.
Рассказывайте о своих проектах.
Онлайн-курсы — нетрадиционный метод обучения. Все вакансии, на которые я пробовался, требовали диплом магистра или хотя бы диплом по какой-то технической специальности. У меня не было ни того, ни другого. Но у меня были навыки, которые я приобрёл, пока проходил различные курсы в сети.
Попутно я публиковал то, что делаю. Все мои проекты были на GitHub, о них я писал в профиле на LinkedIn, а также делился тем, чему научился, в видео на YouTube и статьях на Medium.
Я не посылал резюме в Max Kelsen. Они сами нашли меня через LinkedIn. Багаж проектов, которые я сделал, говорил обо мне лучше резюме.
Независимо от того, учитесь вы онлайн или в вузе, портфолио — отличный способ привлечь к себе внимание. Навыки МО и ИИ востребованы, но это не значит, что их не нужно демонстрировать. Чтобы продать товар, нужно выложить его на витрину.
Будь то GitHub, Kaggle, LinkedIn или личный блог, у вас должен быть свой уголок в сети, чтобы люди могли узнать о вас.
С чего начать?
Многие спрашивают, с чего начать обучение и какие курсы — лучше. Но на него нет единственно верного ответа. Каждый человек выбирает то, что ближе ему: кому-то больше нравится читать книги, а кому-то удобнее смотреть видео. Гораздо важнее не как вы начинаете, а для чего.
Поэтому начните с ответа на вопрос, «зачем» вы хотите приобрести эти навыки:
- чтобы заработать много денег;
- чтобы строить что-то;
- чтобы сделать что-то значимое.
Здесь тоже нет «правильного» ответа: каждая из этих причин имеет смысл. Но когда вам будет трудно (а вам обязательно будет трудно), эта причина напомнит, зачем вы начали учиться.
Теперь нужно получить сами навыки. Я могу посоветовать только то, что пробовал сам. Я закончил следующие курсы (по порядку):
- Treehouse — введение в Python
- Udacity — курсы по глубокому обучению и искусственному интеллекту
- Coursera — курс по глубокому обучению от Эндрю Ына
- fast.ai — Часть 1 (вышла Часть 2)
Все эти курсы — просто высочайшего уровня. Я визуал и лучше воспринимаю информацию, когда мне наглядно объясняют, как что-то нужно делать, поэтому подбирал именно такие варианты. Если вы начинаете совсем с нуля, в первую очередь пройдите вводные курсы по Python, а когда почувствуете себя увереннее, переходите к обработке данных, машинному обучению и искусственному интеллекту.
Сколько будет математики?
Я учил математику только в школе, а всё остальное по мере необходимости — на Khan Academy.
Есть много разных точек зрения на то, сколько математики нужно в МО и ИИ. По моему мнению, если вы собираетесь применять эти технологии для решения конкретной задачи, то хорошие результаты получите и без глубоких познаний в математике.
Если вы хотите глубоко погрузиться в исследования МО и ИИ, например, чтобы написать докторскую диссертацию, без досконального знания математики вам не обойтись.
Лично я просто люблю использовать доступные мне библиотеки и по-всякому применять их для решения разных задач.
Чем занимается инженер машинного обучения?
Может оказаться, что совсем не тем, чем вы думаете. Несмотря на картинки к статьям в интернете, их деятельность связана не только с роботами с красными зрачками.
Вот несколько вопросов, над которыми ежедневно работает инженер МО.
- Контекст. Как можно применить МО, чтобы больше узнать о задаче?
- Данные. Нужно ли больше данных? В какой форме они должны быть представлены? Что делать, если данных недостаточно?
- Модели.
Какую использовать модель? Не произойдёт ли переобучение или недообучение?
- Продакшн. Как развёртывать модель в продакшн? Она должна быть доступна онлайн, или обновлять её периодически?
- Поддержка. Что делать, если модель сломается? Как улучшить её, добавив больше данных? Можно ли усовершенствовать её?
Подробно об этом можно прочитать в замечательной статье соосновательницы fast.ai Рейчел Томас. Также у меня есть видео о том, чем мы занимаемся в Max Kelsen.
Нет единственно возможного пути
Нет правильных и неправильных способов войти в МО или ИИ. В этой сфере прекрасно то, что передовые технологии мира доступны всем. Нужно только научиться использовать их.
Можете начинать с изучения Python, или матанализа, или статистики, или философии принятия решений. Меня всегда восхищало то, как в искусственном интеллекте и машинном обучении переплетаются все эти области.
Иногда мне не даются какие-то понятия или мой код не работает. Я расстраиваюсь и на время всё бросаю: ложусь спать или отправляюсь на прогулку, чтобы отвлечься от проблемы. Это позволяет посмотреть на неё свежим взглядом, и я продолжаю учиться с новыми силами.
Эта сфера бурно развивается, и кажется, что начинать очень страшно. Не пытайтесь взяться за всё сразу. Выберите то, что для вас наиболее интересно, и не распыляйтесь. Если это ни к чему не приведёт, здесь тоже есть и свои плюсы: вы поняли, чем заниматься не стоит. Вернитесь в начало и выберите что-то другое.
Microsoft выпустила бесплатный инструмент для обучения ИИ для тех, кто не умеет программировать. Видео
, Текст: Эльяс Касми
Microsoft открыла всему миру доступ к программе Lobe, позволяющей за несколько минут создавать готовые модели машинного обучения для дальнейшего их использования в сторонних ПО и устройствах. Программа полностью бесплатна и исключает написание программного кода в процессе тренировки моделей – от пользователей нужно лишь загрузить в нее данные, а всю работу она выполнит сама.
Программа полностью бесплатна и исключает написание программного кода в процессе тренировки моделей – от пользователей нужно лишь загрузить в нее данные, а всю работу она выполнит сама.
Машинное обучение для «чайников»
Компания Microsoft выпустила решение Lobe для тренировки моделей машинного обучения. Оно нацелено на самую широкую массу пользователей, так как совершенно не требует знаний и навыков в программировании. То есть тренировать с ее помощью искусственный интеллект сможет каждый человек, даже никак не связанный с ИТ-отраслью. По заявлению разработчиков, Lobe позволяет создать модель машинного обучения с нуля всего за 10 минут.
Lobe – это автономная программа, устанавливаемая на компьютер или ноутбук и не требующая дополнительного подключения к облачным сервисам. По заявлению Microsoft, Lobe проводит все расчеты непосредственно на устройстве пользователя.
На момент публикации материала Lobe была доступна только в бета-версии и только под Windows и macOS.
Интерфейс Lobe тоже максимально упрощен
Сроки выпуска финальной версии сервиса и его появления на других платформах, например, под Android и iOS, разработчики не сообщают.
Как работает Lobe
Бета-версия Lobe имеет ограниченные возможности, по сути, демонстрирующие потенциал программы. На момент выхода беты она умела лишь автоматически классифицировать изображения. Пользователю требуется загрузить в программу заранее подготовленные файлы, после чего промаркировать их, и на выходе программа выдаст готовую модель. В Microsoft отметили, что точность распознавания изображений окажется недостаточно высокой, пользователь сможет самостоятельно повысить ее, дообучив программу.
Демонстрация возможностей нового детища Microsoft
Весь интерфейс Lobe построен по принципу по принципу drag’n’drop. После того, как пользователь перенесет в программу данные, программа обработает их, и итоговую модель затем можно будет выгрузить, например, в требуемое приложение под iOS и Android с помощью фреймфорков CoreML и TensorFlow. Также возможен экспорт прямо в облако – поддерживаются сервисы Microsoft Azure, Google Cloud и Amazon Web Services.
Разработчики привели несколько примеров использования Lobe. При помощи этого сервиса можно тренировать модели машинного обучения, которые затем будут использоваться для анализа аэороснимков и фотографий животных и растений, распознавания масок на лицах людей, определения жестов и эмоций и даже видов спортивных упражнений.
Примеры использования Lobe
С помощью Lope можно создавать модели для определения дыма и огня, что может пригодиться, например, для выявления лесных пожаров на ранней стадии. Еще один пример использования – создание модели машинного обучения для умных радионянь. Они смогут определить, спит ребенок или уже проснулся, и уведомить родителей о его пробуждении до того, как он начнет плакать.
С чего все начиналось
Microsoft не разрабатывала Lobe с нуля. Изначально это была отдельная одноименная компания-стартап, основанная, по данным ресурса CrunchBase, в 2016 г. в Сан-Франциско, США. У ее истоков стоят Адам Менгес (Adam Menges), Маркус Бейссингер (Markus Beissinger) и Майк Матас (Mike Matas).
Сервис Lobe был единственным проектом над которым работала команда стартапа. Они ставили перед собой цель сделать программу для тренировки моделей машинного обучения, доступной всем пользователям.
Microsoft заинтересовалась Lobe в 2018 г. Стартап стал ее собственностью в сентябре 2018 г., однако стороны так и не раскрыли финансовые и другие условия сделки. В своем сообщении основатели Lobe заявили лишь, что после перехода в собственность Microsoft сервис Lobe останется самостоятельным продуктом.
Программирование в прошлом
Выпустив Lobe в свободный доступ и позволив простым пользователям делать то, на что раньше были способны лишь специалисты в сфере машинного обучения, Microsoft пошла по стопам Amazon. Как сообщал CNews, в июне 2020 г. она запустила сервис Honeycode для создания полноценных приложений, притом, как и в случае с Lobe, без необходимости написания программного кода.
Honeycode можно пользоваться совершенно бесплатно, и доступ к нему открыт как обычным потребителям, так и крупным разработчикам. В частности, возможности этого сервиса будут применяться при разработке новых версий корпоративного мессенджера Slack.
В Honeycode реализован специальный графический интерфейс с набором специальных шаблонов для создания программ различного рода. Это, к примеру, менеджер мероприятий (Event Management), контроль бюджета (Budget Approval), менеджер оборудования (Inventory Manager), инструмент управления контентом (CMS, Content Tracker), и др. Сама Amazon в качестве примера приложений, разработанных при помощи Honeycode, привела планировщик задач (Simple To-do) и инструмент анализа работы сотрудников компании с клиентами (CRM, Customer Tracker).
Большой гид по Data Science для начинающих: термины, применение, образование и вход в профессию
Профессию Data Scientist сегодня часто называют одной из самых перспективных и модных. Онлайн-курсы и университеты предлагают все больше программ обучения этой специальности, и новичкам не всегда понятно, с чего начать и как выбрать самый эффективный путь. Руководитель факультета Data Science онлайн-университета «Нетология» Елена Герасимова специально для «Цеха» составила подробный путеводитель по миру науки о данных. В материале вы найдете объяснения главных терминов, пошаговую инструкцию для тех, кто только входит в профессию, а также список полезной литературы по каждой теме.
Онлайн-курсы и университеты предлагают все больше программ обучения этой специальности, и новичкам не всегда понятно, с чего начать и как выбрать самый эффективный путь. Руководитель факультета Data Science онлайн-университета «Нетология» Елена Герасимова специально для «Цеха» составила подробный путеводитель по миру науки о данных. В материале вы найдете объяснения главных терминов, пошаговую инструкцию для тех, кто только входит в профессию, а также список полезной литературы по каждой теме.
О чем речь
Data Science — деятельность, связанная с анализом данных и поиском лучших решений на их основе. Раньше подобными задачами занимались специалисты по математике и статистике. Затем на помощь пришел искусственный интеллект, что позволило включить в методы анализа оптимизацию и информатику. Этот новый подход оказался намного эффективней.
Как строится процесс? Все начинается со сбора больших массивов структурированных и неструктурированных данных и их преобразования в удобный для восприятия формат. Дальше используется визуализация, работа со статистикой и аналитические методы — машинного и глубокого обучения, вероятностный анализ и прогнозные модели, нейронные сети и их применение для решения актуальных задач.
Пять главных терминов, которые нужно запомнить
Искусственный интеллект, машинное обучение, глубокое обучение и наука о данных — основные и самые популярные термины. Они близки, но не эквивалентны друг другу. На старте важно разобраться, чем они отличаются.
Искусственный интеллект (Artificial Intelligence) — область, посвященная созданию интеллектуальных систем, работающих и действующих как люди. Ее возникновение связано с появлением машин Алана Тьюринга в 1936 году.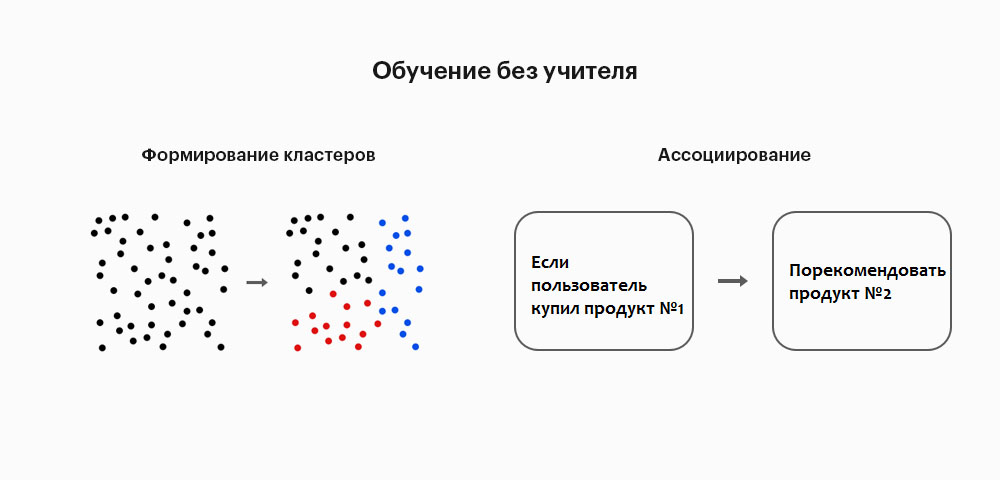 Несмотря на долгую историю развития, искусственный интеллект пока не способен полностью заменить человека в большинстве областей. А конкуренция ИИ с людьми в шахматах и шифрование данных — две стороны одной медали.
Несмотря на долгую историю развития, искусственный интеллект пока не способен полностью заменить человека в большинстве областей. А конкуренция ИИ с людьми в шахматах и шифрование данных — две стороны одной медали.
Машинное обучение (Machine learning) — создание инструмента для извлечения знаний из данных. Модели ML обучаются на данных самостоятельно или поэтапно: обучение с учителем на подготовленных человеком данных и без учителя — работа со стихийными, зашумленными данными.
Глубокое обучение (Deep learning) — создание многослойных нейронных сетей в областях, где требуется более продвинутый или быстрый анализ, и традиционное машинное обучение не справляется. «Глубина» обеспечивается некоторым количеством скрытых слоев нейронов в сети, которые проводят математические вычисления.
Большие данные (Big Data) — работа с большим объемом часто неструктурированных данных.
Наука об анализе данных (Data Science) — в основе области лежит наделение смыслом массивов данных, визуализация, сбор идей и принятие решений на основе этих данных. Специалисты по анализу данных используют некоторые методы машинного обучения и Big Data: облачные вычисления, инструменты для создания виртуальной среды разработки и многое другое.
Где применяется Data Science
• обнаружение аномалий, например, ненормальное поведение клиента, мошенничества;
• персонализированный маркетинг — электронные рассылки, ретаргетинг, системы рекомендаций;
• количественные прогнозы — показатели эффективности, качество рекламных кампаний и других мероприятий;
• скоринговые системы — обработка больших объемов данных, помощь в принятии решений, например, о предоставлении кредита;
• базовое взаимодействие с клиентом — стандартные ответы в чатах, голосовые помощники, сортировка писем по папкам.
Пять основных этапов в работе с данными
• Сбор. Поиск каналов, где можно собирать данные, и выбор методов их получения.
• Проверка. Валидация, нивелирование аномалий, которые не влияют на результат и мешают дальнейшему анализу.
• Анализ. Изучение данных, подтверждение предположений.
• Визуализация. Представление информации в понятном для восприятия виде: графики, диаграммы.
• Реакция. Принятие решений на основе данных. Например, изменение маркетинговой стратегии, увеличение бюджета компании.
Образование. Шесть шагов на пути к Data Scientist
Путь к этой профессии труден: невозможно овладеть всеми инструментами за месяц или даже год. Придется постоянно учиться, делать маленькие шаги каждый день, ошибаться и пытаться вновь.
Шаг 1. Статистика, математика, линейная алгебра
Для серьезного понимания Data Science понадобится фундаментальный курс по теории вероятностей (математический анализ как необходимый инструмент в теории вероятностей), линейной алгебре и математической статистике.
Фундаментальные математические знания важны, чтобы анализировать результаты применения алгоритмов обработки данных. Сильные инженеры в машинном обучении без такого образования есть, но это скорее исключение.
Что почитать:
«Элементы статистического обучения», Тревор Хасти, Роберт Тибширани и Джером Фридман — если после учебы в университете осталось много пробелов. Классические разделы машинного обучения представлены в терминах математической статистики со строгими математическими вычислениями.
«Глубокое обучение», Ян Гудфеллоу. Лучшая книга о математических принципах, лежащих в основе нейронных сетей.
«Нейронные сети и глубокое обучение», Майкл Нильсен. Для знакомства с основными принципами.
Полное руководство по математике и статистике для Data Science. Крутое и нескучное пошаговое руководство, которое поможет сориентироваться в математике и статистике.
Крутое и нескучное пошаговое руководство, которое поможет сориентироваться в математике и статистике.
Введение в статистику для Data Science поможет понять центральную предельную теорему. Оно охватывает генеральные совокупности, выборки и их распределение, содержит полезные видеоматериалы.
Полное руководство для начинающих по линейной алгебре для специалистов по анализу данных. Всё, что необходимо знать о линейной алгебре.
Линейная алгебра для Data Scientists. Интересная статья, знакомящая с основами линейной алгебры.
Шаг 2. Программирование
Большим преимуществом будет знакомство с основами программирования. Вы можете немного упростить себе задачу: начните изучать один язык и сосредоточьтесь на всех нюансах его синтаксиса.
При выборе языка обратите внимание на Python. Во-первых, он идеален для новичков, его синтаксис относительно прост. Во-вторых, Python многофункционален и востребован на рынке труда.
Во-вторых, Python многофункционален и востребован на рынке труда.
Что почитать:
«Автоматизация рутинных задач с помощью Python: практическое руководство для начинающих». Практическое руководство для тех, кто учится с нуля. Достаточно прочесть главу «Манипулирование строками» и выполнить практические задания из нее.
Codecademy — здесь вы научитесь хорошему общему синтаксису.
Легкий способ выучить Python 3 — блестящий мануал, в котором объясняются основы.
Dataquest поможет освоить синтаксис.
The Python Tutorial — официальная документация.
После того, как изучите основы Python, познакомьтесь с основными библиотеками:
Визуализация:
Машинное обучение и глубокое обучение:
Обработка естественного языка:
Web scraping (Работа с web):
Шаг 3. Машинное обучение
Компьютеры обучаются действовать самостоятельно, нам больше не нужно писать подробные инструкции для выполнения определенных задач. Поэтому машинное обучение имеет большое значение для практически любой области, но прежде всего будет хорошо работать там, где есть Data Science.
Первый шаг в изучении машинного обучения — знакомство с тремя его основными формами.
1) Обучение с учителем — наиболее развитая форма машинного обучения. Идея в том, чтобы на основе исторических данных, для которых нам известны «правильные» значения (целевые метки), построить функцию, предсказывающую целевые метки для новых данных. Исторические данные промаркированы. Маркировка (отнесение к какому-либо классу) означает, что у вас есть особое выходное значение для каждой строки данных. В этом и заключается суть алгоритма.
2) Обучение без учителя. У нас нет промаркированных переменных, а есть много необработанных данных. Это позволяет идентифицировать то, что называется закономерностями в исторических входных данных, а также сделать интересные выводы из общей перспективы. Итак, выходные данные здесь отсутствуют, есть только шаблон, видимый в неконтролируемом наборе входных данных. Прелесть обучения без учителя в том, что оно поддается многочисленным комбинациям шаблонов, поэтому такие алгоритмы сложнее.
3) Обучение с подкреплением применяется, когда у вас есть алгоритм с примерами, в которых отсутствует маркировка, как при неконтролируемом обучении. Однако вы можете дополнить пример положительными или отрицательными откликами в соответствии с решениями, предлагаемыми алгоритмом. Обучение с подкреплением связано с приложениями, для которых алгоритм должен принимать решения, имеющие последствия. Это похоже на обучение методом проб и ошибок. Интересный пример обучения с подкреплением — когда компьютеры учатся самостоятельно играть в видеоигры.
Что почитать:
Контролируемые и неконтролируемые алгоритмы в машинном обучении. Доходчивые и лаконичные объяснения типов алгоритмов машинного обучения.
Визуализация в машинном обучении. Отличная визуализация, которая поможет понять, как используется машинное обучение.
Шаг 4. Data Mining (Анализ данных) и визуализация данных
Data Mining — важный исследовательский процесс. Он включает анализ скрытых моделей данных в соответствии с различными вариантами перевода в полезную информацию, которая собирается и формируется в хранилищах данных для облегчения принятия деловых решений, призванных сократить расходы и увеличить доход.
Что почитать и посмотреть:
Как работает анализ данных. Отличное видео с доходчивым объяснением анализа данных.
«Работа уборщика данных» — главное препятствие для анализа» — интересная статья, в которой подробно рассматривается важность анализа данных в области Data Science.
Шаг 5. Практический опыт
Заниматься исключительно теорией не очень интересно, важно попробовать свои силы на практике. Вот несколько хороших вариантов для этого.
Используйте Kaggle. Здесь проходят соревнования по анализу данных. Существует большое количество открытых массивов данных, которые можно анализировать и публиковать свои результаты. Кроме того, вы можете смотреть скрипты, опубликованные другими участниками и учиться на успешном опыте.
Шаг 6. Подтверждение квалификации
После того, как вы изучите все, что необходимо для анализа данных, и попробуете свои силы в открытых соревнованиях, начинайте искать работу. Преимуществом станет независимое подтверждение вашей квалификации.
Например:
- расширенный профиль на Kaggle, где есть система рангов. Вы можете пройти путь от новичка до гроссмейстера. За успешное участие в конкурсах, публикацию скриптов и обсуждения вы получаете баллы, которые увеличивают ваш рейтинг. Кроме того, на сайте отмечено, в каких соревнованиях вы участвовали и каковы ваши результаты.
- программы анализа данных можно публиковать на GitHub или других открытых репозиториях, тогда все желающие могут ознакомиться с ними. В том числе и работодатель, который проводит с вами собеседование.
Последний совет: не будьте копией копий, найдите свой путь. Любой может стать Data Scientist. В том числе самостоятельно. В свободном доступе есть все необходимое: онлайн-курсы, книги, соревнования для практики. Но не стоит приходить в сферу только из-за моды. Что мы слышим о Data Science: это круто, это самая привлекательная работа XXI века. Если это основной стимул для вас, его вряд ли хватит надолго. Чтобы добиться успеха, важно получать удовольствие от процесса.
Машинное обучение — Краткое руководство
Сегодняшний искусственный интеллект (ИИ) намного превзошел шумиху в блокчейне и квантовых вычислениях. Это связано с тем, что огромные вычислительные ресурсы легко доступны обычному человеку. Разработчики теперь используют это при создании новых моделей машинного обучения и переподготовке существующих моделей для повышения производительности и результатов. Легкая доступность высокопроизводительных вычислений (HPC) привела к внезапному увеличению спроса на ИТ-специалистов, обладающих навыками машинного обучения.
В этом уроке вы подробно узнаете о —
В чем суть машинного обучения?
Какие существуют виды машинного обучения?
Какие существуют алгоритмы для разработки моделей машинного обучения?
Какие инструменты доступны для разработки этих моделей?
Каковы варианты выбора языка программирования?
Какие платформы поддерживают разработку и развертывание приложений машинного обучения?
Какие интегрированные среды разработки (интегрированная среда разработки) доступны?
Как быстро улучшить свои навыки в этой важной области?
Какие существуют виды машинного обучения?
Какие существуют алгоритмы для разработки моделей машинного обучения?
Какие инструменты доступны для разработки этих моделей?
Каковы варианты выбора языка программирования?
Какие платформы поддерживают разработку и развертывание приложений машинного обучения?
Какие интегрированные среды разработки (интегрированная среда разработки) доступны?
Как быстро улучшить свои навыки в этой важной области?
Когда вы отмечаете лицо на фотографии в Facebook, это искусственный интеллект, который работает за кулисами и идентифицирует лица на фотографии. В некоторых приложениях тегирование лиц теперь вездесуще, и в нем отображаются изображения с человеческими лицами. Почему только человеческие лица? Существует несколько приложений, которые обнаруживают такие объекты, как кошки, собаки, бутылки, автомобили и т. Д. На наших дорогах работают автономные автомобили, которые в режиме реального времени обнаруживают объекты для управления автомобилем. Когда вы путешествуете, вы используете Google Directions, чтобы изучать ситуации с трафиком в режиме реального времени и следовать лучшему пути, предложенному Google на тот момент. Это еще одна реализация метода обнаружения объектов в реальном времени.
Давайте рассмотрим пример приложения Google Translate, которое мы обычно используем при посещении зарубежных стран. Приложение Google для онлайн-перевода на вашем мобильном телефоне поможет вам общаться с местными людьми, которые говорят на иностранном для вас языке.
Есть несколько приложений ИИ, которые мы используем практически сегодня. Фактически, каждый из нас использует ИИ во многих частях нашей жизни, даже без нашего ведома. Сегодняшний ИИ может выполнять чрезвычайно сложные задания с большой точностью и скоростью. Давайте обсудим пример сложной задачи, чтобы понять, какие возможности ожидаются в приложении для искусственного интеллекта, которое вы разрабатываете сегодня для своих клиентов.
пример
Мы все используем Google Directions во время нашей поездки в любую точку города для ежедневных поездок на работу или даже для поездок по городу. Приложение Google Directions предлагает самый быстрый путь к месту назначения в данный момент. Следуя этому пути, мы заметили, что Google почти на 100% прав в своих предложениях, и мы экономим наше драгоценное время в поездке.
Вы можете вообразить сложность, связанную с разработкой такого рода приложений, учитывая, что существует множество путей к пункту назначения, и приложение должно оценивать ситуацию с дорожным движением на каждом возможном пути, чтобы дать вам оценку времени в пути для каждого такого пути. Кроме того, учтите тот факт, что Google Directions охватывает весь земной шар. Несомненно, под капотами таких приложений используется множество методов искусственного интеллекта и машинного обучения.
Учитывая постоянную потребность в разработке таких приложений, вы теперь поймете, почему внезапно возникает потребность в ИТ-специалистах с навыками искусственного интеллекта.
В нашей следующей главе мы узнаем, что нужно для разработки программ ИИ.
Путешествие ИИ началось в 1950-х годах, когда вычислительная мощность была незначительной по сравнению с сегодняшней. ИИ начал с прогнозов, сделанных машиной так, как статистик делает прогнозы, используя свой калькулятор. Таким образом, начальная разработка ИИ была основана главным образом на статистических методах.
В этой главе давайте обсудим подробно, что это за статистические методы.
Статистические методы
Разработка современных приложений ИИ началась с использования вековых традиционных статистических методов. Вы, должно быть, использовали прямую интерполяцию в школах, чтобы предсказать будущее значение. Существует несколько других подобных статистических методов, которые успешно применяются при разработке так называемых программ ИИ. Мы говорим «так называемые», потому что программы ИИ, которые мы имеем сегодня, намного более сложны и используют методы, намного превосходящие статистические методы, используемые в ранних программах ИИ.
Некоторые из примеров статистических методов, которые использовались для разработки приложений ИИ в те дни и все еще применяются на практике, перечислены здесь —
- регрессия
- классификация
- Кластеризация
- Теории вероятностей
- Деревья решений
Здесь мы перечислили только некоторые основные методы, которых достаточно, чтобы вы начали изучать ИИ, не пугая вас обширностью, которую требует ИИ. Если вы разрабатываете приложения ИИ на основе ограниченных данных, вы будете использовать эти статистические методы.
Однако сегодня данных в изобилии. Анализ огромных данных, которыми мы располагаем, не очень помогает, поскольку у них есть свои собственные ограничения. Поэтому для решения многих сложных проблем разрабатываются более продвинутые методы, такие как глубокое обучение.
Продвигаясь вперед в этом руководстве, мы поймем, что такое машинное обучение и как оно используется для разработки таких сложных приложений ИИ.
Рассмотрим следующий рисунок, который показывает график цен на жилье в зависимости от его размера в кв. Футах.
После построения различных точек данных на графике XY мы рисуем наиболее подходящую линию, чтобы сделать наши прогнозы для любого другого дома с учетом его размера. Вы передадите известные данные на машину и попросите найти линию наилучшего соответствия. Как только машина найдет наилучшую линию подгонки, вы проверите ее пригодность, введя известный размер дома, то есть значение Y на приведенной выше кривой. Теперь машина вернет приблизительное значение Х, то есть ожидаемую цену дома. Диаграмма может быть экстраполирована, чтобы узнать цену дома, который составляет 3000 кв. Футов или даже больше. Это называется регрессией в статистике. В частности, этот вид регрессии называется линейной регрессией, поскольку отношения между точками данных X & Y являются линейными.
Во многих случаях отношения между точками данных X & Y могут не быть прямой линией, и это может быть кривая со сложным уравнением. Ваша задача теперь состоит в том, чтобы найти наиболее подходящую кривую, которая может быть экстраполирована для прогнозирования будущих значений. Один такой сюжет приложения показан на рисунке ниже.
Источник:
https://upload.wikimedia.org/wikipedia/commons/c/c9/
Вы будете использовать методы статистической оптимизации, чтобы найти здесь уравнение для наилучшей кривой соответствия. И это именно то, что такое машинное обучение. Вы используете известные методы оптимизации, чтобы найти лучшее решение вашей проблемы.
Далее давайте рассмотрим различные категории машинного обучения.
Машинное обучение широко классифицируется под следующими заголовками —
Машинное обучение развивалось слева направо, как показано на схеме выше.
Первоначально исследователи начали с контролируемого обучения. Это случай прогноза цен на жилье, который обсуждался ранее.
За этим последовало неконтролируемое обучение, когда машина обучалась самостоятельно без какого-либо надзора.
Ученые также обнаружили, что это может быть хорошей идеей, чтобы вознаградить машину, когда она выполняет работу ожидаемым образом, и наступило обучение по усилению.
Очень скоро данные, доступные в наши дни, стали настолько огромными, что разработанные до сих пор традиционные методы не смогли проанализировать большие данные и дать нам прогнозы.
Таким образом, пришло глубокое понимание, где человеческий мозг моделируется в искусственных нейронных сетях (ANN), созданных в наших двоичных компьютерах.
Теперь машина учится самостоятельно, используя высокую вычислительную мощность и огромные ресурсы памяти, доступные сегодня.
В настоящее время наблюдается, что глубокое обучение решило многие из ранее неразрешимых проблем.
В настоящее время эта техника получила дальнейшее развитие, поощряя сети Deep Learning в качестве наград, и, наконец, приходит Deep Reinforcement Learning.
Первоначально исследователи начали с контролируемого обучения. Это случай прогноза цен на жилье, который обсуждался ранее.
За этим последовало неконтролируемое обучение, когда машина обучалась самостоятельно без какого-либо надзора.
Ученые также обнаружили, что это может быть хорошей идеей, чтобы вознаградить машину, когда она выполняет работу ожидаемым образом, и наступило обучение по усилению.
Очень скоро данные, доступные в наши дни, стали настолько огромными, что разработанные до сих пор традиционные методы не смогли проанализировать большие данные и дать нам прогнозы.
Таким образом, пришло глубокое понимание, где человеческий мозг моделируется в искусственных нейронных сетях (ANN), созданных в наших двоичных компьютерах.
Теперь машина учится самостоятельно, используя высокую вычислительную мощность и огромные ресурсы памяти, доступные сегодня.
В настоящее время наблюдается, что глубокое обучение решило многие из ранее неразрешимых проблем.
В настоящее время эта техника получила дальнейшее развитие, поощряя сети Deep Learning в качестве наград, и, наконец, приходит Deep Reinforcement Learning.
Давайте теперь изучим каждую из этих категорий более подробно.
Контролируемое обучение
Обучение под присмотром аналогично обучению ребенка ходить. Вы будете держать ребенка за руку, показывать ему, как сделать шаг вперед, ходить на демонстрацию и так далее, пока ребенок не научится ходить самостоятельно.
регрессия
Аналогично, в случае контролируемого обучения вы даете конкретные известные примеры компьютеру. Вы говорите, что для данного значения признака x1 выход равен y1, для x2 это y2, для x3 это y3 и так далее. Основываясь на этих данных, вы позволяете компьютеру определить эмпирические отношения между x и y.
После того, как машина обучена таким образом с достаточным количеством точек данных, теперь вы бы попросили машину предсказать Y для данного X. Предполагая, что вы знаете реальное значение Y для данного X, вы сможете вывести правильный ли прогноз машины?
Таким образом, вы будете проверять, узнал ли машина, используя известные тестовые данные. Как только вы убедитесь, что машина может делать прогнозы с желаемым уровнем точности (скажем, от 80 до 90%), вы можете прекратить дальнейшую подготовку машины.
Теперь вы можете безопасно использовать машину для прогнозирования неизвестных точек данных или попросить машину прогнозировать Y для заданного X, для которого вы не знаете действительного значения Y. Это обучение относится к регрессии, о которой мы говорили ранее.
классификация
Вы также можете использовать методы машинного обучения для задач классификации. В задачах классификации вы классифицируете объекты сходной природы в одну группу. Например, в наборе из 100 студентов вы можете сгруппировать их в три группы в зависимости от их роста — короткая, средняя и длинная. Измеряя рост каждого ученика, вы поместите их в соответствующую группу.
Теперь, когда приходит новый студент, вы поместите его в соответствующую группу, измерив его рост. Следуя принципам регрессионного обучения, вы научите машину классифицировать ученика на основе его характеристики — роста. Когда машина узнает, как формируются группы, она сможет правильно классифицировать любого неизвестного нового ученика. Еще раз, вы должны использовать данные испытаний, чтобы убедиться, что машина изучила вашу технику классификации, прежде чем запускать разработанную модель в производство.
Обучение под наблюдением — это место, где ИИ действительно начал свое путешествие. Эта методика была успешно применена в нескольких случаях. Вы использовали эту модель во время распознавания рукописного текста на своем компьютере. Для контролируемого обучения было разработано несколько алгоритмов. Вы узнаете о них в следующих главах.
Обучение без учителя
При неконтролируемом обучении мы не указываем целевую переменную для машины, а спрашиваем машину: «Что вы можете рассказать мне о X?». В частности, мы можем задавать вопросы, такие как огромный набор данных X: «Какие пять лучших групп мы можем сделать из X?» Или «Какие функции чаще всего встречаются вместе в X?». Чтобы получить ответы на такие вопросы, вы можете понять, что число точек данных, которые потребуются машине для определения стратегии, будет очень большим. В случае контролируемого обучения, машина может быть обучена даже с несколькими тысячами точек данных. Однако в случае неконтролируемого обучения количество точек данных, приемлемо приемлемых для обучения, начинается с нескольких миллионов. В наши дни данные, как правило, в изобилии доступны. Данные в идеале требуют кураторства. Тем не менее, объем данных, который непрерывно течет в социальной сети, в большинстве случаев курирование данных является невыполнимой задачей.
На следующем рисунке показана граница между желтыми и красными точками, как это определено автоматическим обучением без присмотра. Вы можете ясно видеть, что машина будет в состоянии определить класс каждой из черных точек с довольно хорошей точностью.
Источник:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
Обучение без присмотра показало большой успех во многих современных приложениях ИИ, таких как обнаружение лиц, обнаружение объектов и так далее.
Усиление обучения
Подумайте над тем, чтобы дрессировать собаку, мы дрессируем ее, чтобы он приносил нам мяч. Мы бросаем мяч на определенное расстояние и просим собаку вернуть его нам. Каждый раз, когда собака делает это правильно, мы награждаем собаку. Медленно, собака узнает, что правильное выполнение работы дает ему вознаграждение, и затем собака начинает выполнять работу правильно каждый раз в будущем. Именно эта концепция применяется в обучении типа «Укрепление». Техника изначально была разработана для машин, чтобы играть в игры. У машины есть алгоритм для анализа всех возможных ходов на каждом этапе игры. Машина может выбрать один из ходов наугад. Если ход правильный, машина вознаграждена, в противном случае она может быть оштрафована. Постепенно машина начнет различать правильные и неправильные ходы и после нескольких итераций научится решать головоломку с большей точностью. Точность выигрыша в игре улучшится, когда машина будет играть все больше и больше игр.
Весь процесс может быть изображен на следующей диаграмме —
Этот метод машинного обучения отличается от контролируемого обучения тем, что вам не нужно снабжать помеченные пары ввода / вывода. Основное внимание уделяется поиску баланса между изучением новых решений и использованием изученных решений.
Глубокое обучение
Глубокое обучение — это модель, основанная на искусственных нейронных сетях (ANN), более конкретно, на сверточных нейронных сетях (CNN). Есть несколько архитектур, используемых в глубоком обучении, таких как глубокие нейронные сети, сети глубокого убеждения, рекуррентные нейронные сети и сверточные нейронные сети.
Эти сети успешно применяются для решения проблем компьютерного зрения, распознавания речи, обработки естественного языка, биоинформатики, разработки лекарств, анализа медицинских изображений и игр. Есть несколько других областей, в которых глубокое обучение активно применяется. Глубокое обучение требует огромной вычислительной мощности и огромных данных, которые обычно легко доступны в наши дни.
Мы поговорим о глубоком изучении более подробно в следующих главах.
Глубокое обучение
Глубокое обучение с подкреплением (DRL) сочетает в себе методы глубокого и подкрепляющего обучения. Алгоритмы обучения с подкреплением, такие как Q-learning, теперь сочетаются с глубоким обучением для создания мощной модели DRL. Техника была с большим успехом в области робототехники, видеоигр, финансов и здравоохранения. Многие ранее неразрешимые проблемы теперь решаются путем создания моделей DRL. В этой области ведется множество исследований, и отрасль очень активно этим занимается.
Пока у вас есть краткое введение в различные модели машинного обучения, а теперь давайте немного углубимся в различные алгоритмы, доступные в этих моделях.
Контролируемое обучение является одной из важных моделей обучения, связанных с обучением машин. В этой главе подробно говорится о том же.
Алгоритмы для контролируемого обучения
Есть несколько алгоритмов, доступных для контролируемого обучения. Некоторые из широко используемых алгоритмов контролируемого обучения, как показано ниже —
- k-Ближайшие соседи
- Деревья решений
- Наивный байесовский
- Логистическая регрессия
- Опорные векторные машины
По мере продвижения в этой главе давайте поговорим подробно о каждом из алгоритмов.
k-Ближайшие соседи
K-Ближайшие соседи, которые просто называются kNN, — это статистический метод, который можно использовать для решения задач классификации и регрессии. Давайте обсудим случай классификации неизвестного объекта с использованием kNN. Рассмотрим распределение объектов, как показано на рисунке ниже —
Источник:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Диаграмма показывает три типа объектов, отмеченных красным, синим и зеленым цветами. Когда вы запустите классификатор kNN в указанном наборе данных, границы для каждого типа объекта будут отмечены, как показано ниже —
Источник:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Теперь рассмотрим новый неизвестный объект, который вы хотите классифицировать как красный, зеленый или синий. Это изображено на рисунке ниже.
Как вы видите, неизвестная точка данных принадлежит классу синих объектов. Математически это можно сделать путем измерения расстояния этой неизвестной точки до каждой другой точки в наборе данных. Когда вы сделаете это, вы узнаете, что большинство его соседей имеют синий цвет. Среднее расстояние до красных и зеленых объектов будет определенно больше, чем среднее расстояние до синих объектов. Таким образом, этот неизвестный объект может быть классифицирован как принадлежащий к синему классу.
Алгоритм kNN также может использоваться для задач регрессии. Алгоритм kNN доступен как готовый к использованию в большинстве библиотек ML.
Деревья решений
Простое дерево решений в формате блок-схемы показано ниже —
Вы бы написали код для классификации ваших входных данных на основе этой блок-схемы. Блок-схема не требует пояснений и тривиальна. В этом сценарии вы пытаетесь классифицировать входящее письмо, чтобы решить, когда его читать.
В действительности деревья решений могут быть большими и сложными. Есть несколько алгоритмов, доступных для создания и обхода этих деревьев. Как энтузиаст машинного обучения, вы должны понять и освоить эти методы создания и обхода деревьев решений.
Наивный байесовский
Наивный Байес используется для создания классификаторов. Предположим, вы хотите отсортировать (классифицировать) фрукты разных видов из корзины с фруктами. Вы можете использовать такие функции, как цвет, размер и форма фрукта. Например, любой фрукт красного цвета, круглой формы и диаметром около 10 см может рассматриваться как яблоко. Таким образом, для обучения модели вы должны использовать эти функции и проверить вероятность того, что данный объект соответствует желаемым ограничениям. Вероятности различных функций затем объединяются, чтобы получить вероятность того, что данный фрукт является яблоком. Наивный байесовский метод обычно требует небольшого количества обучающих данных для классификации.
Логистическая регрессия
Посмотрите на следующую диаграмму. Показывает распределение точек данных в плоскости XY.
Из диаграммы мы можем визуально осмотреть отделение красных точек от зеленых точек. Вы можете нарисовать границу, чтобы отделить эти точки. Теперь, чтобы классифицировать новую точку данных, вам просто нужно определить, на какой стороне линии находится точка.
Опорные векторные машины
Посмотрите на следующее распределение данных. Здесь три класса данных не могут быть линейно разделены. Граничные кривые являются нелинейными. В таком случае поиск уравнения кривой становится сложной задачей.
Источник: http://uc-r.github.io/svm
Машины опорных векторов (SVM) пригодятся для определения границ разделения в таких ситуациях.
К счастью, в большинстве случаев вам не нужно кодировать алгоритмы, упомянутые в предыдущем уроке. Существует много стандартных библиотек, которые обеспечивают готовую реализацию этих алгоритмов. Одним из таких инструментов, который обычно используется, является scikit-learn. На рисунке ниже показаны алгоритмы, доступные для использования в этой библиотеке.
Источник: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
Использование этих алгоритмов тривиально, и, поскольку они хорошо протестированы на практике, вы можете безопасно использовать их в своих приложениях ИИ. Большинство из этих библиотек могут свободно использовать даже в коммерческих целях.
Пока что вы видели, как заставить машину научиться находить решение для нашей цели. В регрессии мы обучаем машину предсказывать будущее значение. При классификации мы обучаем машину классифицировать неизвестный объект в одной из определенных нами категорий. Короче говоря, мы обучали машины так, чтобы они могли прогнозировать Y для наших данных X. Учитывая огромный набор данных и не оценивая категории, нам было бы трудно обучить машину, используя контролируемое обучение. Что если машина может искать и анализировать большие данные, занимающие несколько гигабайт и терабайт, и сообщать нам, что эти данные содержат так много разных категорий?
В качестве примера рассмотрим данные избирателя. Рассматривая некоторые входные данные от каждого избирателя (это называется особенностями в терминологии ИИ), позвольте машине предсказать, что есть так много избирателей, которые проголосовали бы за X политическую партию, и так много проголосовало бы за Y, и так далее. Таким образом, в общем, мы запрашиваем у машины огромный набор точек данных X: «Что вы можете рассказать мне о X?». Или это может быть вопрос типа «Какие пять лучших групп мы можем сделать из X?». Или это может быть даже похоже на «Какие три функции чаще всего встречаются вместе в X?».
Это как раз и есть самообучаемое обучение.
Алгоритмы для обучения без учителя
Давайте теперь обсудим один из широко используемых алгоритмов классификации в неконтролируемом машинном обучении.
К-среднее кластеризация
Президентские выборы 2000 и 2004 годов в Соединенных Штатах были близкими — очень близкими. Самый большой процент голосов избирателей, полученных любым кандидатом, составлял 50,7%, а самый низкий — 47,9%. Если бы процент избирателей перешел на другую сторону, исход выборов был бы другим. Есть небольшие группы избирателей, которые при правильном обращении перейдут на другую сторону. Эти группы могут быть не очень большими, но с такими близкими расами они могут быть достаточно большими, чтобы изменить исход выборов. Как вы находите эти группы людей? Как вы обращаетесь к ним с ограниченным бюджетом? Ответ кластеризация.
Давайте разберемся, как это делается.
Во-первых, вы собираете информацию о людях как с их согласия, так и без него: любую информацию, которая может дать некоторое представление о том, что для них важно и что повлияет на их голосование.
Затем вы помещаете эту информацию в какой-то алгоритм кластеризации.
Далее, для каждого кластера (было бы разумно сначала выбрать самый большой), вы создаете сообщение, которое понравится этим избирателям.
Наконец, вы проводите кампанию и измеряете, работает ли она.
Во-первых, вы собираете информацию о людях как с их согласия, так и без него: любую информацию, которая может дать некоторое представление о том, что для них важно и что повлияет на их голосование.
Затем вы помещаете эту информацию в какой-то алгоритм кластеризации.
Далее, для каждого кластера (было бы разумно сначала выбрать самый большой), вы создаете сообщение, которое понравится этим избирателям.
Наконец, вы проводите кампанию и измеряете, работает ли она.
Кластеризация — это разновидность обучения без присмотра, которое автоматически формирует кластеры похожих вещей. Это как автоматическая классификация. Вы можете кластеризовать практически все, и чем больше элементов в кластере схожи, тем лучше кластеры. В этой главе мы собираемся изучить один тип алгоритма кластеризации, который называется k-means. Он называется k-means, поскольку он находит «k» уникальных кластеров, а центр каждого кластера является средним значением в этом кластере.
Идентификация кластера
Идентификация кластера говорит алгоритму: «Вот некоторые данные. Теперь сгруппируйте похожие вещи и расскажите мне об этих группах ». Ключевое отличие от классификации в том, что в классификации вы знаете, что ищете. Пока дело не в кластеризации.
Кластеризацию иногда называют неконтролируемой классификацией, потому что она дает тот же результат, что и классификация, но без наличия предопределенных классов.
Теперь мы довольны как контролируемым, так и неконтролируемым обучением. Чтобы понять остальные категории машинного обучения, мы должны сначала понять Искусственные нейронные сети (ANN), которые мы изучим в следующей главе.
Идея искусственных нейронных сетей была получена из нейронных сетей в человеческом мозге. Человеческий мозг действительно сложен. Тщательно изучая мозг, ученые и инженеры придумали архитектуру, которая могла бы вписаться в наш цифровой мир бинарных компьютеров. Одна такая типичная архитектура показана на диаграмме ниже —
Существует входной слой, который имеет много датчиков для сбора данных из внешнего мира. Справа у нас есть выходной слой, который дает нам прогнозируемый сетью результат. Между этими двумя скрыты несколько слоев. Каждый дополнительный уровень добавляет дополнительную сложность в обучении сети, но обеспечит лучшие результаты в большинстве ситуаций. Существует несколько типов архитектур, которые мы сейчас обсудим.
АНН Архитектур
Диаграмма ниже показывает несколько архитектур ANN, разработанных за определенный период времени и применяемых сегодня.
Источник:
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
Каждая архитектура разработана для конкретного типа приложения. Таким образом, когда вы используете нейронную сеть для своего приложения машинного обучения, вам придется использовать либо одну из существующих архитектур, либо разрабатывать свою собственную. Тип приложения, с которым вы окончательно определитесь, зависит от потребностей вашего приложения. Не существует единого руководства, которое бы указывало на использование конкретной сетевой архитектуры.
Глубокое обучение использует ANN. Сначала мы рассмотрим несколько приложений глубокого обучения, которые дадут вам представление о его силе.
Приложения
Глубокое обучение показало большой успех в нескольких областях применения машинного обучения.
Автомобили с самостоятельным вождением — в автономных автомобилях с автономным управлением используются методы глубокого обучения Как правило, они адаптируются к постоянно меняющимся дорожным ситуациям и становятся все лучше и лучше за время вождения.
Распознавание речи — еще одно интересное приложение Deep Learning — распознавание речи. Сегодня мы все используем несколько мобильных приложений, способных распознавать нашу речь. Siri от Apple, Alexa от Amazon, Microsoft Cortena и Google Assistant — все они используют методы глубокого обучения.
Мобильные приложения. Мы используем несколько веб-приложений и мобильных приложений для организации наших фотографий. Обнаружение лица, идентификация лица, маркировка лица, идентификация объектов на изображении — все это требует глубокого изучения.
Неиспользованные возможности глубокого обучения
Взглянув на огромный успех, достигнутый приложениями глубокого обучения во многих областях, люди начали изучать другие области, где машинное обучение пока не применялось. Есть несколько областей, в которых методы глубокого обучения успешно применяются, и есть много других областей, которые могут быть использованы. Некоторые из них обсуждаются здесь.
Сельское хозяйство является одной из таких отраслей, где люди могут применять методы глубокого обучения для повышения урожайности.
Потребительское финансирование является еще одной областью, где машинное обучение может в значительной степени помочь в раннем обнаружении мошенничества и анализе платежеспособности клиента.
Методы глубокого обучения также применяются в области медицины для создания новых лекарств и предоставления индивидуального рецепта пациенту.
Сельское хозяйство является одной из таких отраслей, где люди могут применять методы глубокого обучения для повышения урожайности.
Потребительское финансирование является еще одной областью, где машинное обучение может в значительной степени помочь в раннем обнаружении мошенничества и анализе платежеспособности клиента.
Методы глубокого обучения также применяются в области медицины для создания новых лекарств и предоставления индивидуального рецепта пациенту.
Возможности бесконечны, и нужно постоянно наблюдать, как часто появляются новые идеи и разработки.
Что требуется для достижения большего с помощью глубокого обучения
Чтобы использовать глубокое обучение, суперкомпьютерная мощность является обязательным требованием. Вам нужны как память, так и процессор для разработки моделей глубокого обучения. К счастью, сегодня у нас есть легкая доступность высокопроизводительных вычислений. Благодаря этому разработка приложений для глубокого обучения, о которых мы упоминали выше, стала реальностью сегодня, и в будущем мы также сможем увидеть приложения в тех неиспользованных областях, которые мы обсуждали ранее.
Теперь мы рассмотрим некоторые ограничения глубокого обучения, которые мы должны рассмотреть, прежде чем использовать его в нашем приложении для машинного обучения.
Недостатки глубокого обучения
Некоторые из важных моментов, которые вы должны рассмотреть, прежде чем использовать глубокое обучение, перечислены ниже —
- Подход черного ящика
- Продолжительность разработки
- Количество данных
- Вычислительно дорого
Теперь мы подробно изучим каждое из этих ограничений.
Подход черного ящика
ANN похож на черный ящик. Вы даете ему определенный вклад, и он предоставит вам конкретный вывод. На следующей диаграмме показано одно из таких приложений, в котором вы передаете изображение животного в нейронную сеть, и оно говорит о том, что это изображение собаки.
Почему этот подход называется «черным ящиком», вы не знаете, почему сеть дала определенный результат. Вы не знаете, как в сети пришли к выводу, что это собака? Теперь рассмотрим банковское приложение, в котором банк хочет решить вопрос кредитоспособности клиента. Сеть обязательно даст вам ответ на этот вопрос. Однако сможете ли вы оправдать это для клиента? Банки должны объяснить своим клиентам, почему кредит не санкционирован?
Продолжительность разработки
Процесс обучения нейронной сети изображен на диаграмме ниже —
Сначала вы определяете проблему, которую хотите решить, создаете для нее спецификацию, выбираете входные функции, проектируете сеть, разворачиваете ее и тестируете выходные данные. Если результат не соответствует ожиданиям, примите это как обратную связь для реструктуризации сети. Это итеративный процесс, и может потребоваться несколько итераций, пока сеть времени не будет полностью обучена для получения желаемых результатов.
Количество данных
Сети глубокого обучения обычно требуют огромного количества данных для обучения, в то время как традиционные алгоритмы машинного обучения могут быть с большим успехом использованы даже с несколькими тысячами точек данных. К счастью, обилие данных растет на 40% в год, а мощность процессора увеличивается на 20% в год, как показано на диаграмме, приведенной ниже —
Вычислительно дорого
Обучение нейронной сети требует в несколько раз большей вычислительной мощности, чем требуется для запуска традиционных алгоритмов. Для успешного обучения глубоких нейронных сетей может потребоваться несколько недель тренировочного времени.
В отличие от этого, традиционные алгоритмы машинного обучения занимают всего несколько минут / часов. Кроме того, объем вычислительной мощности, необходимой для обучения глубокой нейронной сети, сильно зависит от размера ваших данных, а также от того, насколько глубока и сложна сеть?
После обзора того, что такое машинное обучение, его возможностей, ограничений и приложений, давайте теперь углубимся в изучение «машинного обучения».
Машинное обучение имеет очень большую ширину и требует навыков в нескольких областях. Навыки, которые вам необходимо приобрести, чтобы стать экспертом в области машинного обучения, перечислены ниже —
- Статистика
- Теории вероятностей
- Исчисление
- Методы оптимизации
- Визуализация
Необходимость различных навыков машинного обучения
Чтобы дать вам краткое представление о том, какие навыки вам необходимо приобрести, давайте обсудим несколько примеров:
Математическая запись
Большинство алгоритмов машинного обучения в значительной степени основаны на математике. Уровень математики, который вам нужно знать, вероятно, только начальный уровень. Важно то, что вы должны быть в состоянии прочитать обозначения, которые математики используют в своих уравнениях. Например — если вы можете прочитать нотацию и понять, что это значит, вы готовы к обучению машинному обучению. Если нет, возможно, вам придется освежить свои знания по математике.
f_ {AN} (net- \ theta) = \ begin {case} \ gamma & if \: net- \ theta \ geq \ epsilon \\ net- \ theta & if — \ epsilon <net- \ theta <\ epsilon \\ — \ gamma & if \: net- \ theta \ leq- \ epsilon \ end {case}
displaystyle max limit alpha beginbmatrix displaystyle sum limitmi=1 alpha− frac12 displaystyle sum limitmi,j=1метка left( beginarrayci endarray right) cdotметка left( beginarraycj endarray right) cdotai cdotaj langlex left( beginarrayci endarray справа),x left( beginarraycj endarray right) rangle endbmatrix
fAN(net− тета)= влево( гидроразрывае Lambda(net− тета)−е− Lambda(net− тета)е лямбда(net− тета)+е− Lambda(net− тета) справа)
Теория вероятности
Вот пример, чтобы проверить ваши текущие знания теории вероятностей: Классификация с условными вероятностями.
р(Cя|х,у) = гидроразрывар(х,у|Cг)р(Cя)р(х,у)
С помощью этих определений мы можем определить правило байесовской классификации —
- Если P (c1 | x, y)> P (c2 | x, y), класс c1.
- Если P (c1 | x, y) <P (c2 | x, y), класс c2.
Задача оптимизации
Вот функция оптимизации
displaystyle max limit alpha beginbmatrix displaystyle sum limitmi=1 alpha− frac12 displaystyle sum limitmi,j=1метка left( beginarrayci endarray right) cdotметка left( beginarraycj endarray right) cdotai cdotaj langlex left( beginarrayci endarray справа),x left( beginarraycj endarray right) rangl
Методы Машинного обучения (Data Mining)
Доказав себе однажды, что ни один из индикаторов по отдельности или в совокупности с другими работают неудовлетворительно (по тестам от 3-х лет и более) я пришел к простейшим методам Data Mining, которые показали очень хорошие результаты. Пришла пора капнуть глубже, тут как раз и аккуратненькая подборочка, для поверхностного ознакомления, нашлась.А вы используете в своей торговле подобные штуки?
Метод опорных векторов
Метод опорных векторов был разработан Владимиром Вапником в 1995 году [86] и впервые применен к задаче классификации текстов Йоахимсом (Joachims) в 1998 году в работе. В своем первоначальном виде алгоритм решал задачу различения объектов двух классов. Метод приобрел огромную популярность благодаря своей высокой эффективности. Многие исследователи использовали его в своих работах, посвященных классификации текстов. Подход, предложенный Вапником для определения того, к какому из двух заранее определенных классов должен принадлежать анализируемый образец, основан на принципе структурной минимизации риска. Вероятность ошибки при классификации оценивается, как непрерывная убывающая функция, от расстояния между вектором и разделяющей плоскостью. Она равна 0,5 в нуле и стремится к 0 на бесконечности.
Результаты классификации текстов с помощью метода опорных векторов, являются одними из лучших, по сравнению с остальными методами машинного обучения. Однако, скорость обучения данного алгоритма одна из самых низких. Метод опорных векторов требует большого объема памяти и значительных затрат машинного времени на обучение.
Метод k–ближайших соседей
Метод k-ближайших соседей является одним из самых изученных и высокоэффективных алгоритмов, используемых при создании автоматических классификаторов. Впервые он был предложен еще в 1952 году для решения задач дискриминантного анализа.
В основе метода лежит очень простая идея: находить в отрубрицированной коллекции самые похожие на анализируемый текст документы и на основе знаний об их категориальной принадлежности классифицировать неизвестный документ.
Рассмотрим алгоритм подробнее. При классификации неизвестного документа находится заранее заданное число k текстов из обучающей выборки, которые в пространстве признаков расположены к ближе всего. Иными словами находятся k-ближайших соседей. Принадлежность текстов к распознаваемым классам считается известной. Параметр k обычно выбирают от 1 до 100. Близость классифицируемого документа и документа, принадлежащего категории, определяется как косинус угла между их векторами признаков. Чем значение ближе к 1, тем документы больше друг на друга похожи.
Решение об отнесении документа к тому или иному классу принимается на основе анализа информации о принадлежности k его ближайших соседей. Например, коэффициент соответствия рубрики анализируемому документу, можно выяснить путем сложения для этой рубрики значений.
При монотематической классификации выбирается рубрика с максимальным значении. Если же документ может быть приписан к нескольким рубрикам (случай мультитематической классификации), классы считаются соответствующими, если значение превосходит некоторый, заранее заданный порог.
Главной особенностью, выделяющей метод k-NN среди остальных, является отсутствие у этого алгоритма стадии обучения. Иными словами, принадлежность документа рубрикам определяется без построения классифицирующей функции.
Основным преимуществом такого подхода является возможность обновлять обучающую выборку без переобучения классификатора. Это свойство может быть полезно, например, в случаях, когда обучающая коллекция часто пополняется новыми документами, а переобучение занимает слишком много времени.
Классический алгоритм предлагает сравнивать анализируемый документ со всеми документами из обучающей выборки и поэтому главный недостаток метода k-ближайших соседей заключается в длительности времени работы рубрикатора на этапе классификации.
Деревья решений
В отличии от остальных подходов представленных здесь, подход, получивший название деревья решений относится к символьным (т.е. не числовым) алгоритмам. Преимущество символьных алгоритмов, заключается в относительной простоте интерпретации человеком правил отнесения документов к рубрике. Они хорошо приспособлены для графического отображения, и поэтому сделанные на их основе выводы гораздо легче интерпретировать, чем, если бы они были представлены только в числовой форме.
Цель построения деревьев решений заключается в п
редсказании значений категориальной зависимой переменной, и поэтому используемые методы тесно связаны с более традиционными методами дискриминантного и кластерного анализа, а также нелинейного оценивания и непараметрической статистики. Обширная сфера применения деревьев решений делает их весьма удобным инструментом для анализа данных и позволяет решать как задачи классификации и регрессии, так и задачи описания данных.
Деревья решений — метод, применяемый при многоходовом процессе анализа данных и принятии решений о категориальной принадлежности. Ветви дерева изображают события, которые могут иметь место, а узлы и вершины — момент выбора направления действий. Принятие решений осуществляется на основе логической конструкции «если… то…», путем ответа на вопрос вида «является ли значение переменной меньше значения порога?». При положительном ответе осуществляется переход к правому узлу дерева, при отрицательном к левому узлу. После этого осуществляется принятие решения уже для выбранного узла.
Для более ясного понимания принципов работы деревьев решений представим следующую ситуацию. Перед нами стоит задача сортировки камней на крупные, средние и мелкие. Эти классы камней отличаются линейными размерами, и вследствие этого данный параметр может быть использован для построения иерархического устройства сортировки камней. Предположим, у нас имеется два сита, размер ячеек которых соответствует минимальному размеру крупных камней, и минимальному размеру средних камней, соответственно. Далее все камни высыпаются в первое сито. Те из них, что не прошли просеивание считаются крупными камнями, а те, что прошли – средними и мелкими. Затем камни высыпаются во второе сито. Те камни, что остались во втором сите считаются принадлежащими среднему классу камней, а те, что прошли сквозь него – мелкому.
Рассмотрим применения деревьев решений к автоматической классификации текста. В этом случае внутренние узлы представляют собой термы, ветви, отходящие от них, характеризуют вес терма в анализируемом документе, а листья — категории. Такой классификатор категоризирует испытываемый документ, рекурсивно проверяя веса вектора признаков по отношению к порогам, выставленным для каждого из весов, пока не достигнет листа дерева (категории). К этой категории (листа которой достиг классификатор) и приписывается анализируемый документ.
Метод Байеса
Метод Байеса это простой классификатор, основанный на вероятностной модели, имеющей сильное предположение независимости компонент вектора признаков [95, 96]. Обычно это допущение не соответствует действительности и потому одно из названий метода — Naıve Bayes (Наивный Байес).
Вероятностная модель метода основана на известной формуле Байеса по вычислению апостериорной вероятности гипотез. Применяя эту формулу для задачи классификации текстов, получим вероятность того, что документ принадлежит категории :
Так как знаменатель не зависит от рубрики и является константой, на практики его сокращают. Основываясь на этом, получим формулу для определения принадлежности документа к рубрикам :
Условная вероятность вычисляется как:
Для облегчения задачи вычисления этой вероятности предположим независимость компонент вектора признаков. Тогда:
Как и все вероятностные классификаторы, классификатор, основанный на методе Байеса, правильно классифицирует документы, если соответствующий документу класс более вероятен, чем любой другой. В этом случае формула для определения наиболее вероятной категории примет следующий вид:
Предположим, что классификатор состоит из рубрик и может быть выражена через параметров. Тогда соответствующий алгоритм Байеса для классификации текста будет иметь параметров. Но на практике, чаше всего (случай бинарной классификации) и . Поэтому, число параметров для метода Байеса обычно равно , где — размерность вектора признаков.
Наивный классификатор Байеса имеет несколько свойств, которые делают его чрезвычайно полезным практически, несмотря на то, что сильные предположения независимости часто нарушаются. Этот метод показывает высокую скорость работы и достаточно высокое качество классификации [91, 96]. Его можно рекомендовать для построения классификатора, когда существую жесткие ограничения на время счета и воспользоваться более точными методами, не представляется возможны.
Метод Роше
Одним из наиболее простых классификаторов, основанных на векторной модели, является так называемый классификатор Роше. Основная особенность этого метода заключается в том, что для каждой рубрики вычисляется взвешенный центроид. Он получается вычитанием веса каждого терма векторов признаков не соответствующих рубрике документов, из весов термов векторов признаков соответствующих рубрике документов.
Пусть каждый документ рубрики будет представлен в виде вектора признаков следующим образом. Тогда рубрика будет представлена в виде вектора признаков. Для каждой рубрики вычисляется взвешенный центроид.
Таким образом, получившийся взвешенный центроид представляет рубрику в пространстве признаков. Принадлежность рубрикам неизвестного документа, определяется путем вычисления расстояния между центроидом каждой из рубрик и вектором классифицируемого документа. Если расстояние не превосходит некоторый, заранее заданный порог, документ считается принадлежащим данной рубрике.
Практическое исследования метода Роше показали, что данный метод обладает высокой эффективностью в решении задачи классификации текстов. Одной из главных его особенностей является возможность изменять вектор взвешенного центроида рубрики, без переобучения классификатора. Это свойство может быть полезно, например, в случаях, когда обучающая коллекция часто пополняется новыми документами, а переобучение занимает слишком много времени. Благодаря своей результативности и простоте метод Роше стал одним из самых популярных в рассматриваемой нами области и часто используется как базовый, для сравнения эффективности различных классификаторов.
Метод «случайный лес»
Алгоритм «случайный лес» — техника, с помощью которой можно достичь высокой точности в классификации и регрессии с минимальной настройкой параметров.
В этом методе модель классификатора строится с помощью обучающей выборки, на основе которой строится большое число независимых деревьев решений. Деревья создаются так, чтобы для каждого дерева, вместо того, чтобы рассматривать все возможные узлы, анализ проводился для маленькой группой случайно отобранных узлов. В этом случае для каждого дерева, в целях последующего анализа, выбирается лучший лист. Классификации происходит голосованием либо усреднением результатов для всех деревьев.
Случайность в этом методе присутствует в выборе примеров из обучающей выборки для построения деревьев решений, а также в выборе узлов, для которых будет работать алгоритм каждого конкретного дерева решений.
Точность классификации в методе «случайный лес» зависит от численности построенных деревьев решений, а также от их взаимной корреляции. То есть в идеальном случае для каждой рубрики мы должны построить большое количество независимых деревьев решений. Если эффективность каждого конкретного дерева решений падает или возрастает их зависимость, в этом случае снижается и точность классификации этого метода. В случае алгоритма «случайный лес», независимость деревьев решений достигается через случайность в выборе примеров из обучающей выборки и через случайность в выборе для каждого дерева узлов, по которым проводится анализ.
Метод «случайный лес» обладает множеством положительных особенностей: параллельность работы, высокая точность, быстрая обучаемость, и тенденция к отсутствию переобучаемости.
Также, его положительной особенностью является то, что он показывает высокое качество рубрикации для обучающих выборок, с малым количеством примеров. Это свойство выделяет метод «случайный лес» среди множества других алгоритмов и является чрезвычайно ценным для успешного применения методов машинного обучения.
Эффективное улучшение: помимо «просто решать больше проблем»?
Приведенная ниже идея должна помочь участникам уровня CM или M (возможно, тоже) достичь уровня IM или GM.
На мой взгляд, самый простой способ улучшить — сначала найти темы, в которых вы слабы. Это можно сделать, просмотрев несколько недавних конкурсов, которые вы провели, или выполнив пару венчурных инвестиций. Вы должны быть в состоянии видеть некоторые типы проблем, с которыми вы беспокоитесь.
Что ж, теперь у вас есть тема, в которой вы слабы или не любите (я предполагаю, что это один из тегов CF).Один из способов улучшить это — просто открыть «страницу набора проблем», выбрать тег, отсортировать проблемы по сложности и начать их решать по порядку. Это неплохой процесс, но он требует много времени, а также вы решаете множество проблем, которые могут быть легкими для вас.
Я сделал (и я думаю, что это один из самых быстрых способов улучшить определенную тему) следующее:
Мы снова рассмотрим проблемы, но начнем с тех, которые для нас довольно сложны. Когда я это сделал, трудностей не возникло, но, поскольку они есть сейчас, я думаю, начав с задач со сложностью равной («Ваш рейтинг» + 200), вы решите задачу, которая будет для вас довольно сложной.Пока что процесс такой же, как и у многих советов, которые вы, возможно, читали в других блогах для предложений по обучению. Разница возникает, когда мы смотрим на способ решения проблем.
В большинстве случаев, когда я решаю задачу для тренировки по определенной теме, я трачу не более 10 минут, прежде чем взгляну на решение. Это потому, что если я думал в течение 10 минут подряд, вероятно, есть концепция, которую я не знаю, или есть наблюдение, которое мне не хватает. И по мере тренировки лучше решать больше задач (вы узнаете больше «хитростей» и идей).Так что вы должны посмотреть редакционную статью через 10 минут.
Если в редакционной статье есть концепция, с которой вы не знакомы, изучите ее и найдите одну или две проблемы, связанные с ней (вы можете легко найти их в Google). Если вы знаете все из этой редакционной статьи, вы, вероятно, теперь знаете, какие наблюдения вы упустили. Запомните их, чтобы в следующий раз вы не пропустили их (как правило, в CP я заметил, что есть много проблем, которые представляют собой просто комбинацию таких наблюдений). Ну наконец то можно реализовать задачу.Если это несложно реализовать или вы внедрили такую вещь недавно, вы можете не кодировать ее, потому что, вероятно, это не будет очень полезно для вас.
Весь процесс решения одной проблемы займет 30-40 минут, если вы не смогли решить проблему изначально, или около 20 минут, если вы смогли ее решить. Представьте, что вы тренируетесь 1 час в день. Это означает, что вы сможете решать 2 задачи в день. Я думаю, что для уверенности в теме достаточно решения 10-15 задач, чтобы усвоить самые распространенные идеи и приемы.Значит, на одну бирку хватит недели-двух. Если вы будете проводить больше времени каждый день, это будет еще быстрее.
Очевидно, что вы плохо разбираетесь в ограниченном количестве тем. Так что, если вы настроены серьезно, через два-три месяца вы хорошо справитесь с большинством из них. Теперь, чтобы иметь возможность повышать свой уровень, вы должны тренироваться по одному из следующих способов:
1) Более быстрое наблюдение за проблемами
2) Более быстрое выполнение задач
Я не совсем уверен, как тренироваться по последнему, но я предполагаю, что достаточно будет просто решить больше проблем и реализовать их все.С другой стороны, я знаю, как улучшить первое. Если вы тренируетесь на конструктивных задачах (тег «конструктивные алгоритмы» на CF), вы значительно сократите время, затрачиваемое на поиск наблюдений. Решение некоторых математических задач или чтение сообщений для тега комбинаторики на AoPS также улучшают это. Наконец, решение некоторых проблем из OI также может быть полезным, так как эти проблемы, как правило, содержат много наблюдений, связанных друг с другом, а также из-за подзадач процесс их поиска проще.
Также полезно провести раунды CF (когда вы можете, и CF проведет их в удобное время: ‘)) или провести на них виртуальные соревнования.
Итак, в заключение, вы должны найти темы, в которых вы слабы, а затем улучшить их. После этого. После этого тренируйте навыки наблюдения и поиска и время выполнения. Это общий способ, которым я тренировался последние два года, и он мне помог. Я надеюсь, что некоторые из вас сочтут это полезным.
Решение проблем: систематический подход
Одна из радостей управления проектами — постоянная потребность в решении проблем.
Новизна и неопределенность проектной среды постоянно преподносят сюрпризы. Итак, менеджер проекта должен уметь решать проблемы.
В этой статье мы рассмотрим решение проблем и предложим вам структурированный, систематический подход.
Методики решения проблем
Существует множество устоявшихся подходов к структурированному решению проблем. И есть большая вероятность, что, если вы работаете в большой организации, одна из них находится в общем пользовании.Действительно, некоторые организации предписывают использовать особую методологию решения проблем.
Например, в автомобильной промышленности широко используется методология 8 дисциплин или 8-D. И везде, где «Шесть сигм» является важной частью набора инструментов, вы, вероятно, найдете метод решения проблем DMAIC.
Еще мне нравятся Simplex и TOSIDPAR с броским названием. И есть еще другие, которые, хотя и очень эффективны, также надежно защищены авторским правом, что затрудняет их обсуждение в такой статье.Я думаю о тебе, Синектик.
Сильные и слабые стороны
Все эти методологии предлагают отличные возможности. И что любопытно, хотя каждый из них кажется завершенным, ни один из них не предлагает каждый шаг, который вам может понадобиться. Причина проста. Каждый подход ориентирован на определенную часть процесса решения проблемы. Другие части либо выходят за рамки их компетенции, либо им уделяется меньше внимания.
Сравнение подходов
Следствием этого является то, что любой структурированный подход может упускать шаги, которые важны в некоторых контекстах.Чтобы проиллюстрировать это, давайте сравним четыре упомянутые мною методологии.
Сравнение четырех методик решения проблем
Устранение пробелов
В OnlinePMCourses мы используем 8-этапный подход к решению проблем, который охватывает практически все этапы, предлагаемые этими четырьмя методологиями. Но прежде чем мы обратимся к ним, давайте взглянем на некоторые практические подходы к применению решения проблем.
Практическая реализация
Некоторые из лучших примеров решения проблем в проектах содержатся в двух моих любимых фильмах:
- Аполлон 13
«Давайте поработаем над проблемой»
(Джин Кранц, которого играет Эд Харрис) - Марсианин
«Перед лицом огромных разногласий у меня остается только один вариант: мне придется научиться всему этому дерьмо.
(Марк Уотни в исполнении Мэтта Дэймона)
Вайгая
В A
Мой компьютер работает медленно, что я могу сделать, чтобы это исправить?
Обновлено: 30.06.2020, Computer Hope
Ниже приведены шаги, которые пользователи могут выполнить, чтобы ускорить работу компьютера или определить, почему компьютер работает медленно. Следует отметить, что на этой странице рассматривается только общий медленный компьютер, а не компьютер, который медленно запускается или имеет медленное подключение к Интернету. Чтобы диагностировать эти проблемы, посетите следующие страницы:
Перезагрузка
Если ваш компьютер в последнее время не перезагружался, обязательно перезагрузите его, прежде чем выполнять какие-либо из следующих действий.Перезагрузка компьютера может решить многие проблемы и является простым первым шагом.
Фоновые программы
Одна из наиболее частых причин медленной работы компьютера — это программы, работающие в фоновом режиме. Удалите или отключите все TSR и программы запуска, которые автоматически запускаются при каждой загрузке компьютера.
НаконечникЧтобы узнать, какие программы работают в фоновом режиме и сколько памяти и ЦП они используют, откройте диспетчер задач. Если вы используете Windows 7 или более позднюю версию, запустите Resmon, чтобы лучше понять, как используются ресурсы вашего компьютера.
Если на вашем компьютере есть антивирусный сканер, программа защиты от шпионского ПО или другая утилита безопасности, убедитесь, что она не сканирует ваш компьютер в фоновом режиме. Если сканирование выполняется, это снижает общую производительность вашего компьютера. В этом случае дождитесь завершения сканирования, и производительность компьютера должна повыситься.
Удалить временные файлы
Когда компьютер запускает программы, временные файлы хранятся на жестком диске. Удаление этих временных файлов помогает повысить производительность компьютера.
Компьютеры Windows
Во-первых, мы предлагаем использовать утилиту Windows Disk Cleanup для удаления временных файлов и других файлов, которые больше не нужны на компьютере.
К сожалению, очистка диска не может удалить все файлы во временном каталоге. Поэтому мы также рекомендуем удалять временные файлы вручную.
- Откройте меню «Пуск» или и нажмите клавишу Windows, затем введите % temp% в поле поиска.
В Windows XP и более ранних версиях щелкните опцию Run в меню «Пуск» и введите % temp% в поле Run .
- Нажмите Введите , и откроется папка Temp.
- Вы можете удалить все файлы, найденные в этой папке, и, если какие-либо файлы используются и не могут быть удалены, их можно пропустить.
Свободное место на жестком диске
Убедитесь, что на жестком диске имеется не менее 200-500 МБ свободного места. Это доступное пространство позволяет компьютеру иметь место для файла подкачки, чтобы увеличиться в размере и освободить место для временных файлов.
Плохой, поврежденный или фрагментированный жесткий диск
Проверить жесткий диск на наличие ошибок
На компьютере с Windows запустите ScanDisk, chkdsk или что-то подобное, чтобы убедиться, что с жестким диском компьютера все в порядке.
На компьютере с macOS откройте программу Disk Utility и воспользуйтесь опцией First Aid , чтобы проверить жесткий диск на наличие ошибок. Чтобы открыть Дисковую утилиту:
- Щелкните значок Launchpad на док-станции.
- Откройте папку Other .
- Нажмите Дисковая утилита , чтобы открыть программу.
Убедитесь, что жесткий диск не фрагментирован
Запустите дефрагментацию, чтобы убедиться, что данные расположены в наилучшем порядке.
Тест жесткого диска
Используйте другие программные инструменты, чтобы проверить жесткий диск на наличие ошибок, посмотрев на SMART диска.
Проверка на вирусы
Если ваш компьютер заражен одним или несколькими вирусами, он может работать медленнее. Если на вашем компьютере не установлена антивирусная программа, запустите бесплатную онлайн-утилиту Trend Micro Housecall для сканирования и удаления вирусов с вашего компьютера. Также рекомендуем установить антивирусную программу для активной защиты от вирусов.
Поиск вредоносных программ
Сегодня шпионское ПО и другие вредоносные программы являются основной причиной многих компьютерных проблем, включая снижение производительности. Даже если на компьютере установлен антивирусный сканер, мы также рекомендуем запустить сканирование на наличие вредоносных программ. Используйте бесплатную версию Malwarebytes для сканирования вашего компьютера на наличие вредоносных программ.
Конфликты оборудования
Убедитесь, что диспетчер устройств не имеет конфликтов. Если таковые существуют, устраните эти проблемы, поскольку они могут быть причиной вашей проблемы.
Обновите операционную систему
Чтобы обновить компьютер под управлением Microsoft Windows, запустите Центр обновления Windows.
Чтобы обновить компьютер с macOS, запустите «Обновление программного обеспечения». Чтобы обновить операционную систему, используйте App Store.
Отключить надстройки браузера
Если ваш компьютер работает особенно медленно, когда вы используете веб-браузер, если вы хотите отключить любые плагины и надстройки браузера,
Лучшие вопросы и ответы на собеседование по машинному обучению на 2020 год
С тех пор, как машины начали учиться и рассуждать без участия человека вмешательства, нам удалось достичь бесконечной вершины технической эволюции.Излишне говорить, что мир изменился с тех пор, как были введены искусственный интеллект, машинное обучение и глубокое обучение, и так будет продолжаться до скончания веков. В этом блоге, посвященном вопросам машинного обучения, я собрал наиболее часто задаваемые вопросы интервьюеров. Эти вопросы собираются после консультации со специалистами по обучению сертификации машинного обучения.
Если вы недавно посещали какое-либо собеседование по машинному обучению, вставьте эти вопросы в раздел комментариев, и мы ответим на них в ближайшее время.Вы также можете прокомментировать ниже, если у вас есть какие-либо вопросы, с которыми вы можете столкнуться на собеседовании по машинному обучению.
Вы можете просмотреть эту запись вопросов и ответов на собеседовании по машинному обучению, где наш инструктор подробно объяснил темы с примерами, которые помогут вам лучше понять эту концепцию.
Интервью по машинному обучению Вопросы и ответы | Подготовка к собеседованию по машинному обучению | Edureka
Это видео Edureka о вопросах и ответах на собеседование по машинному обучению поможет вам подготовиться к собеседованиям по Data Science / Machine Learning.
В этом блоге, посвященном вопросам собеседования по машинному обучению, я буду обсуждать самые популярные вопросы, связанные с машинным обучением, которые задаются в ваших интервью. Итак, для вашего лучшего понимания я разделил этот блог на следующие 3 раздела:
- Основные вопросы собеседования по машинному обучению
- Машинное обучение с использованием вопроса на собеседовании Python
- Интервью на основе сценария машинного обучения
Вопрос на собеседовании с ядром машинного обучения
1 кв.Какие существуют типы машинного обучения?
Типы машинного обучения — вопросы собеседования по машинному обучению — Edureka
Есть три способа обучения машин:
- контролируемое обучение
- Неконтролируемое обучение
- обучение с подкреплением
контролируемое обучение
Обучение с учителем — это метод, при котором машина обучается с использованием помеченных данных.
- Это похоже на обучение под руководством учителя
- Набор обучающих данных похож на учителя, которого используют для обучения машины
- Модель обучается на заранее определенном наборе данных, прежде чем она начнет принимать решения при получении новых данных
Неконтролируемое обучение:
Неконтролируемое обучение — это метод, при котором машина обучается на немаркированных данных или без какого-либо руководства
- Это похоже на обучение без учителя.
- Модель учится через наблюдение и находит структуры в данных.
- Модель получает набор данных, и ей остается автоматически находить закономерности и взаимосвязи в этом наборе данных путем создания кластеров.
Обучение с подкреплением:
Обучение с подкреплением включает в себя агента, который взаимодействует со своей средой, производя действия и обнаруживая ошибки или вознаграждения.
- Это похоже на то, что вы застряли на изолированном острове, где вы должны исследовать окружающую среду и научиться жить и адаптироваться к условиям жизни самостоятельно.
- Модель обучается с помощью метода проб и ошибок
- Она обучается на основе вознаграждения или штрафа за каждое выполненное действие
Q2. Как бы вы объяснили машинное обучение школьнику?
- Предположим, ваш друг приглашает вас на вечеринку, где вы встречаетесь с совершенно незнакомыми людьми. Поскольку вы понятия не имеете о них, вы мысленно классифицируете их по полу, возрастной группе, одежде и т. Д.
- В этом сценарии посторонние представляют собой немаркированные данные, а процесс классификации немаркированных точек данных представляет собой не что иное, как обучение без учителя. .
- Поскольку вы не использовали никаких предварительных знаний о людях и не классифицировали их на ходу, это становится проблемой обучения без учителя.
3 квартал. Чем глубокое обучение отличается от машинного обучения?
| Глубокое обучение | Машинное обучение |
| Глубокое обучение — это форма машинного обучения, которая основана на структуре человеческого мозга и особенно эффективна при обнаружении признаков. | Машинное обучение — это все об алгоритмах, которые анализируют данные, учатся на них, а затем применяют полученные знания для принятия обоснованных решений. |
Глубокое обучение и машинное обучение — вопросы собеседования по машинному обучению — Edureka
Q4. Объяснение классификации и регрессии
Классификация и регрессия — вопросы собеседования по машинному обучению — Edureka
Q5.Что вы понимаете под предвзятостью отбора?
- Это статистическая ошибка, которая вызывает систематическую ошибку в части выборки эксперимента.
- Ошибка приводит к тому, что одна группа выборки выбирается чаще, чем другие группы, включенные в эксперимент.
- Ошибка выбора может привести к неточному заключению, если систематическая ошибка выбора не выявлена.
Q6. Что вы понимаете под точностью и отзывчивостью?
Позвольте мне объяснить вам это на примере:
- Представьте, что ваша девушка дарила вам сюрприз на день рождения каждый год в течение последних 10 лет.Однажды ваша девушка спрашивает вас: «Милая, ты помнишь все сюрпризы на день рождения от меня?»
- Чтобы оставаться в хороших отношениях с девушкой, тебе нужно вспомнить все 10 событий из своей памяти. Следовательно, отзыва — это отношение количества событий, которые вы можете правильно вызвать, к общему количеству событий.
- Если вы можете правильно вспомнить все 10 событий, то ваш коэффициент отзыва составляет 1,0 (100%), а если вы можете правильно вспомнить 7 событий, ваш коэффициент отзыва составляет 0,7 (70%)
Однако вы можете ошибаться в некоторые ответы.
- Например, предположим, что вы сделали 15 предположений, из которых 10 были правильными, а 5 — неправильными. Это означает, что вы можете вспомнить все события, но не очень точно.
- Следовательно, точность — это отношение количества событий, которые вы можете правильно вспомнить, к общему количеству событий, которые вы можете вспомнить (сочетание правильных и неправильных отзывов).
- Из приведенного выше примера (10 реальных событий, 15 ответов: 10 правильных, 5 неправильных) вы получаете 100% отзыв, но ваша точность составляет всего 66.67% (10/15)
Q7. На простом примере объясните ложноотрицательный, ложноположительный, истинно отрицательный и истинно положительный.
Рассмотрим сценарий возникновения пожара:
- Истинно положительный: Если срабатывает тревога в случае пожара.
Пожар положительный, и прогноз, сделанный системой, верен. - Ложное срабатывание: Если тревога продолжается, а возгорания нет.
Система спрогнозировала положительный пожар, что является неверным прогнозом, следовательно, прогноз неверен. - Ложно-отрицательный: Если тревога не срабатывает, но возник пожар.
Система спрогнозировала отрицательный результат возгорания, что оказалось ложным, поскольку возник пожар. - Истинно Отрицательно: Если сигнализация не срабатывает и возгорания не было.
Пожар отрицательный, и это предсказание сбылось.
Q8. Что такое матрица неточностей?
Матрица неточностей или матрица ошибок — это таблица, которая используется для суммирования производительности алгоритма классификации.
Матрица путаницы — вопросы собеседования по машинному обучению — Edureka
Рассмотрим приведенную выше таблицу, где:
- TN = истинно отрицательный
- TP = истинно положительный
- FN = ложно отрицательный
- FP = ложноположительный
Q9. В чем разница между индуктивным и дедуктивным обучением?
- Индуктивное обучение — это процесс использования наблюдений для получения выводов
- Дедуктивное обучение — это процесс использования выводов для формирования наблюдений
Индуктивное и дедуктивное обучение — Вопросы на собеседовании по машинному обучению — Edureka
Q10.Чем KNN отличается от кластеризации K-средних?
K-means vs KNN — Вопросы на собеседовании по машинному обучению — Edureka
Q11. Что такое кривая ROC и что она собой представляет?
Кривая рабочих характеристик приемника (или кривая ROC) является основным инструментом для оценки диагностических тестов и представляет собой график зависимости истинно положительной частоты (чувствительности) от ложноположительной частоты (специфичности) для различных возможных точек отсечения диагностический тест.
ROC — Вопросы для собеседования по машинному обучению — Edureka
- Он показывает компромисс между чувствительностью и специфичностью (любое увеличение чувствительности будет сопровождаться уменьшением специфичности).
- Чем ближе кривая следует к левой границе, а затем к верхней границе пространства ROC, тем точнее тест.
- Чем ближе кривая подходит к 45-градусной диагонали пространства ROC, тем менее точен тест.
- Наклон касательной в точке отсечения дает отношение правдоподобия (LR) для этого значения теста.
- Площадь под кривой является мерой точности теста.
Q12. В чем разница между ошибками типа I и типа II?
Ошибка типа 1 и типа 2 — Вопросы собеседования по машинному обучению — Edureka
Q13. Что лучше: слишком много ложных срабатываний или слишком много ложноотрицательных результатов? Объясни.
Ложноотрицательные и ложные срабатывания — Вопросы собеседования по машинному обучению — Edureka
Это зависит от вопроса, а также от домена, для которого мы пытаемся решить проблему. Если вы используете машинное обучение в области медицинского тестирования, ложноотрицательный результат очень опасен, поскольку отчет не покажет никаких проблем со здоровьем, когда человек действительно болен. Точно так же, если машинное обучение используется для обнаружения спама, ложное срабатывание очень рискованно, потому что алгоритм может классифицировать важное электронное письмо как спам.
Q14. Что для вас важнее — точность модели или производительность модели?
Простое решение проблем с помощью машинного обучения: подход
8 мая 2019 г.
Простое решение проблем с помощью машинного обучения: подход
Впервые в машинном обучении?
Если вы совершали покупки в Интернете, значит, сознательно или неосознанно вы внесли свой вклад в машинное обучение.Да, мы говорим о рекомендациях «покупатели, купившие этот товар, тоже купили» на торговых сайтах. И нет, это не произвольно.
Источник: Starecat.com
В самом простом определении машинное обучение означает «область обучения, которая дает компьютерам возможность учиться без явного программирования». Эта черта «способности к обучению» имеет огромное значение, поскольку на протяжении столетий эта единственная черта «способности учиться, сохранять, улучшать и передавать знания» отличала людей от других видов, которые более или менее начинали с той же точки, в основном заново изобретая колесо снова и снова.
Чтобы понять машинное обучение, давайте рассмотрим простой набор задач:
Случай 1: Мы знаем, что это фрукты, и все, что нам нужно сделать, это классифицировать их.
Случай 2: Мы знаем, что это фрукты, но мы хотим знать, насколько они свежие.
Случай 3. Мы не знаем, фрукты это или что-то еще, и хотим, чтобы алгоритм решал это за нас.
Типы машинного обученияСлучай 1. Обучение с учителем — простой сценарий «Обучите меня», в котором ограниченные данные передаются в компьютер для простой классификации «да / нет».
Процесс:
Помеченные данные передаются в компьютер → алгоритм понимает помеченные данные и разделяет их на шаблоны и ассоциации → алгоритм определяет метку для новых данных
Источник: Research Gate
Обучение с учителем решает вышеуказанную проблему в три этапа:
Шаг 1: Подготовьте данные для тренировки с указанием физических характеристик фруктов.
Шаг 2: Введите переменную решения.
Алгоритм определит название фруктов на основе данных обучения.
Шаг 3: Например, если фрукт большой, красный и круглый с углублением наверху, он перейдет в группу яблок.
Общие алгоритмы, используемые для контролируемого обучения: линейная регрессия, логистическая регрессия, вспомогательные векторные машины, деревья решений, наивный байесовский алгоритм, алгоритм k-ближайшего соседа, линейный дискриминантный анализ, нейронные сети (многослойный перцептрон), обучение по подобию
Пример 2: Обучение с подкреплением — сценарий «Я могу учиться самостоятельно», в котором для обучения и непрерывного совершенствования вводятся неограниченные данные.
Процесс:
Шаг 1. Создайте обучающие данные апельсинов (свежие, не свежие, гнилые)
Шаг 2: Введите данные в алгоритм, чтобы определить возраст.
Общие алгоритмы обучения с подкреплением: кластеризация (иерархическая кластеризация, k-средние, смешанные модели), обнаружение аномалий (локальный фактор выброса), нейронные сети (автоэнкодеры, сети глубокого убеждения, обучение Хебба, самоорганизующаяся карта), модели со скрытыми переменными ( Алгоритм ожидания – максимизации (EM), Метод моментов).
Случай 3: Обучение без учителя. Сценарий «Я найду, чему научиться, и выучу это сам», в котором неограниченные данные загружаются в компьютер для осмысления и дальнейшего обучения.
Человеческое общение всегда было сложным синтезом вербальных и невербальных ключей. Помимо других факторов, значение сказанных слов также зависит от опыта слушателя, тона и языка тела говорящего. Но то, что сыграло такую решающую роль в эволюции наиболее развитых видов во времени, должно быть сложным, что также затрудняет его воспроизведение.Короче говоря, ИИ, предназначенный для общения, должен уметь работать на уровне человеческого интеллекта. Ранее считавшееся невозможным, теперь это повышение кажется вполне вероятным с помощью машинного обучения и обработки естественного языка (НЛП).
Обычное явление в онлайн-мире, чат-боты со сценариями для нас не новички. Эти чат-боты, разработанные для определенных целей и аудитории, используют заранее определенные сценарии для выполнения действий и ответов на определенный набор вопросов. Но это были просто продолжение письменных часто задаваемых вопросов.Войдите в интеллектуальные чат-боты, и все изменится — навсегда. Интеллектуальные чат-боты учатся при каждом взаимодействии со своими клиентами или, другими словами, они работают над НЛП.
Процесс:
Начните с классификации фруктов по их физическим характеристикам.
Цвет — желтый
Виноград или папайя.
Форма — круглая или овальная, форма пучка цилиндрическая или овальная
Круглые и гроздевидные: виноград
Овал: виноград и папайя.
Размер — (большой / маленький)
Маленький: Виноград
Большой: Папайя
Источник: Средний
Общие алгоритмы для обучения без учителя: кластеризация, обнаружение аномалий, нейронные сети, алгоритм ожидания-максимизации (EM), метод моментов, слепое разделение сигналов
Rundown:Используется машинное обучение с учителем:
- Когда результаты предсказуемы.
- Где входы и выходы известны и нам нужна простая классификация данных.
Используется машинное обучение с подкреплением:
- Когда результаты известны и требуется постоянное уточнение.
Используется неконтролируемое машинное обучение:
- Когда результаты неизвестны.
Машинное обучение нашло применение во множестве бизнес-целей. Перечислим самые распространенные из них:
Обучение с учителем:
- Кампания Google PayPerClick
- Системы маркировки спама
- Распознавание лиц в Facebook
Источник: Средний
Обучение с подкреплением:
- AlphaGo
- Роботы для управления запасами
- Реклама
- Оптимизация контента
Обучение без учителя:
- Актуальные новости
- Рекомендации фильмов
- Выявление клиентов для программы лояльности
Источник: Средний
Является ли главный алгоритм решением наших проблем машинного обучения? — TechCrunch
Хасан Ахмед Автор
Машинное обучение не новость.Мы наблюдаем это с 1990-х годов, когда Amazon представила новый раздел «Рекомендовано для вас» для своих пользователей, чтобы отображать более персонализированные результаты. Когда мы ищем что-то в Google, за результатами поиска стоит машинное обучение. Рекомендации «друзей», предлагаемые страницы в Facebook или рекомендации по продукту на любом сайте электронной коммерции — все зависит от машинного обучения.
В остальном эти сайты знают о нас много. Каждый клик или поиск, который мы выполняем, записываются и предоставляют дополнительную информацию о нас этим сайтам, но ни один из этих сайтов не знает о нас полностью.Google знает, что мы ищем, Amazon знает, что мы хотим купить, Apple знает о наших музыкальных интересах, а Facebook много знает о нашем социальном поведении. Но ни один из этих сайтов не знает о наших предпочтениях и выборе в течение дня. Они могут предсказать, только глядя на наши предыдущие клики, а не глядя на нас в целом.
Что такое главный алгоритм?
Но предположим, что существует алгоритм, который знает, что мы ищем в Google, что мы покупаем на Amazon и что слушаем в Apple Music или смотрим на Netflix.Он также знает о наших последних статусах и репостах на Facebook.
Теперь этот алгоритм много знает о нас и имеет лучшее и более полное представление о нас.
Этот мощный «главный алгоритм» лежит в основе работы, постулированной Педро Домингосом, автором книги «Главный алгоритм: как поиски совершенной обучающей машины переделают наш мир».
Машинное обучение имеет разные точки зрения, и каждая рассматривает проблему с разных точек зрения. Символисты больше сосредотачиваются на философии, логике и психологии и рассматривают обучение как инверсию дедукции.Коннекционисты сосредоточены на физике и неврологии и верят в обратную инженерию мозга. Эволюционеры , , как следует из названия, делают свои выводы на основе генетики и эволюционной биологии, тогда как байесовцы сосредотачиваются на статистике и вероятностных выводах. Аналоги зависят от экстраполяции суждений о сходстве, уделяя больше внимания психологии и математической оптимизации.
Более глубокий взгляд на различные школы машинного обучения
Коннекционисты
Эта школа мысли верит в получение знаний через связи между нейронами.Коннекционисты сосредоточены на физике и нейробиологии и верят в обратную инженерию мозга. Они верят в алгоритм обратного распространения или «обратного распространения ошибок» для обучения искусственных нейронных сетей для получения результатов.
Джефф Хинтон из Университета Торонто — один из ведущих исследователей в этой области машинного обучения. Хинтон активно работает с Google, а также является автором модели «глубокого обучения», которая произвела революцию в искусственном интеллекте в различных областях, таких как распознавание речи, определение характеристик изображений и создание удобочитаемых предложений.
Искусственный интеллект ставит технологическое развитие на опасный путь?
Все крупные компании, включая Facebook, Microsoft и Google, используют эту модель для улучшения своих систем. Навдип Джайтли, который проводил свои исследования под руководством Хинтона, работает научным сотрудником в команде Google «Brain». Он использовал модель глубокого обучения, чтобы перехитрить уже «отлаженные» алгоритмы распознавания речи в ОС Android.
Янн ЛеКун, директор Facebook AI Research (FAIR), — еще одно известное имя в этой области исследований.Янн также защитил докторскую диссертацию. под руководством Хинтона и посвятил себя области глубокого обучения.
Йошуа Бенжио, глава Монреальского института алгоритмов обучения, — еще одно известное имя, возглавляющее исследования, следуя подходу коннекционистов. Он организовывал различные мероприятия и конференции, связанные с ИИ, в том числе Learning Workshop. Бенхио был соавтором Deep Learning вместе со своим учеником Яном Гудфеллоу, ныне исследователем OpenAI, и Аароном Курвиллем.
Многие исследователи в области машинного обучения, особенно коннекционисты, считают, что модель глубокого обучения является ответом на все проблемы ИИ, и считают ее основным алгоритмом.
Символисты
Подход символистов основан на «высокоуровневой» интерпретации проблем. Символисты больше сосредотачиваются на философии, логике и психологии и рассматривают обучение как инверсию дедукции. Джон Хогеланд назвал это «старомодным добрым искусственным интеллектом» (GOFAI) в своей книге «Искусственный интеллект: сама идея».Подход символистов решает проблему, используя уже существующие знания, чтобы заполнить пробелы. Большинство экспертных систем используют подход символистов для решения проблемы с помощью подхода «если-то».
Том Митчелл из Университета Карнеги-Меллона входит в число ведущих исследователей, ведущих школу мысли символистов. Себастьян Трун, соучредитель Udacity, бывший вице-президент Google и профессор Стэнфордского университета, и Орен Эциони, генеральный директор Института искусственного интеллекта Аллена, также входят в число известных учеников Тома Митчелла.
Стивен Магглетон, автор книги «Индуктивное получение экспертных знаний» из Имперского колледжа Лондона, и Росс Куинлан, основатель RuleRequest, компании, известной различными инструментами интеллектуального анализа данных, — среди других известных исследователей, которые следуют подходу символистов к машинному обучению.
Эволюционеры
Третья школа мысли, эволюционисты, делают свои выводы на основе генетики и эволюционной биологии. Джон Холланд, который умер в 2015 году и ранее преподавал в Мичиганском университете, сыграл очень важную роль в внедрении теории эволюции Дарвина в компьютерные науки.Холланд был пионером генетических алгоритмов, и его «фундаментальная теорема алгоритма генетики» считается основой в этой области.
Станем ли мы рабами машин или ИИ — это ворота к высшему прогрессу человечества?
Большая часть работы в области робототехники, 3D-печати и биоинформатики выполняется эволюционистами, такими как Ход Липсон, директор лаборатории креативной механики Колумбийского университета. Джон Коза, бывший профессор Стэнфордского университета и основатель компании Scientific Games Corporation, — еще один пионер в области генетических алгоритмов.Между тем, Серафим Бацоглу, профессор компьютерных наук в Стэнфорде и основатель Serafim’s Lab, является еще одним заметным исследователем, работающим в области вычислительной геномики.
Байесовская школа мысли
Если вы пользуетесь электронной почтой 10–12 лет, то знаете, как улучшились спам-фильтры. Это все из-за байесовской школы машинного обучения. Байесовцы сосредотачиваются на вероятностном выводе и теореме Байеса для решения проблем.Байесовцы исходят из убеждения, что они называют априор . Затем они получают некоторые данные и обновляют предыдущие на основе этих данных; результат называется задним . Затем апостериор обрабатывается с дополнительными данными и становится априорным, и этот цикл повторяется до тех пор, пока мы не получим окончательный ответ. Большинство спам-фильтров работают по тому же принципу.
Джудея Перл из отдела информатики Калифорнийского университета в Лос-Анджелесе — один из самых выдающихся исследователей, придерживающихся байесовского подхода.Дэвид Хекерман, директор Genomics Group в Microsoft, также является одним из видных ученых, специализирующихся на байесовском подходе. Он помогал Microsoft разрабатывать различные инструменты анализа данных и фильтры нежелательной почты в Outlook и Hotmail.
Майкл Джордан из Калифорнийского университета в Беркли также известен своими работами в той же области.
Аналоги
Пятое поколение машинного обучения, аналогизаторы, зависят от экстраполяции суждений о сходстве, уделяя больше внимания психологии и математической оптимизации.Аналогиизаторы следуют принципу «ближайшего соседа» в своих исследованиях. Рекомендации по продуктам на различных сайтах электронной коммерции, таких как Amazon, или рейтинги фильмов на Netflix — наиболее распространенные примеры подхода аналоговизаторов.
Дуглас Хофштадтер из Университета Индианы — наиболее известное имя в когнитивных науках. Владимир Вапник, соавтор «машины опорных векторов» и главный разработчик теории Вапника-Червоненкиса, — еще один видный ученый, известный своей работой в той же области.Facebook недавно нанял его вместе с другими известными исследователями, чтобы он присоединился к своей лаборатории искусственного интеллекта. Питер Харт, соавтор классификации паттернов и основатель Ricoh Innovations, широко известен, придерживаясь подхода аналогизаторов.
Проблемы и опасности
Все вышеперечисленные школы решают разные проблемы и предлагают разные решения. Настоящая задача состоит в том, чтобы разработать алгоритм, который решит все различные проблемы, которые пытаются решить эти подходы — этот единственный алгоритм будет «главным алгоритмом».”
Мы все еще живем в первые дни машинного обучения и искусственного интеллекта. Еще многое предстоит сделать. Мы не знаем, когда и где возникнет проблема, которая замедлит весь этот процесс и принесет следующую «Зиму искусственного интеллекта», или когда и где новый прорыв полностью изменит нынешний сценарий.
Прогресс в машинном обучении будет больше похож на эволюцию. Подобно тому, как бактерии развиваются быстрее, чем люди, машинное обучение будет развиваться быстрее, но наступит этап, когда эти алгоритмы обучения станут слишком сложными для быстрого развития.
Есть и другие опасности. «Идеальный» мастер-алгоритм знает о нас все. Хотя машинное обучение для начала требует участия человека, в конечном итоге оно достигнет точки, когда перехитрит нас. Что тогда будет? Небольшого расхождения между их целями и нашими целями может быть достаточно, чтобы положить конец человечеству.
Это только один сценарий. Допустим, мы успешно создали механизм для управления этими сверхразумными машинами, что похоже на идею о том, что муравьи создадут механизм для управления нами, людьми.Тем не менее, будут возникать конфликты интересов между нациями, людьми и группами, которые могут инициировать атаку, подобную Скайнету.
Как машинное обучение уже меняет мир
Есть много стартапов, специализирующихся на машинном обучении и его применении для поиска решений различных жизненных проблем; что еще более важно, их поддерживает каждая крупная технологическая компания. DeepMind, купленный Google, ориентирован на здравоохранение и работает над лечением рака с помощью машинного обучения.