Python уроки для начинающих — курсы с нуля
Уроки программирования Python для начинающих. Обучение с нуля для чайников. Большой видео курс по изучению языка Питон.
Информация про Python
Питон входит в топ популярнейших языков программирования по нынешним оценкам рейтинга TIOBE. Именно с него многие программисты начинают карьеру в своих домах или университетах. Вам не составит особого труда самостоятельно разобраться в языке.
Программирование на нём приносит эстетическое удовольствие и неплохой доход. Даже у неопытного программиста здесь получается лаконичный и легко читаемый код. Питон – это красивый и очень мощный язык.

Из-за распространения языка, вокруг него ходит много легенд, мифов и тайн. Многие начинающие программисты просто не понимают, почему Python невероятно полезен в современном мире. По этой причине мы решили составить небольшой обзорный материал.
Где применяется Python?
Несколько основных функциональных достоинств Python:
- Умеет работать с расширениями
xml/html; - Поддерживает управление http-запросами;
- Обладает графическим интерфейсом;
- Помогает создавать веб-скрипты;
- Может работать с FTP;
- Способен оперировать картинками, видео и звуковыми файлами;
- Используется в разработке робототехники;
- Отвечает за создание научных, вычислительных площадок и ещё много всего другого.
Можно сказать, что Python отлично подходит для выполнения большей части ежедневных задач программистов. Участвует как в создании обычных бекапов или чтении писем с почты, так и в разработке крупных игр. Питон практически не имеет ограничений по сферам использования, что позволяет использовать его в проектах колоссальных масштабов.
Python часто применяется китами мира IT – Google и Яндекс. Если добавить к этому простоту создания программ, несложно понять, почему Питон заслуживает место в списке лучших языков.
Чтобы начать работать на Python, прежде стоит пройти на официальный веб-ресурс для скачивания дистрибутива языка. На сайте есть масса полезной информации в отношении правил написания кода и расширяемости языка.
Сфера применения языка выходит далеко за пределы разработки обычных приложений. Он используется в разработке игр, веб-программировании и многом другом. Для работы в подобных направлениях нужно только подобрать, скачать и установить соответствующий фреймворк. Библиотеки помогут расширить функции языка в конкретном направлении. С библиотеками проще создавать проекты, так как не требуется создавать «велосипед».
Создание сайтов на Python
На сегодня популярнейшей библиотекой является Django — это фреймворк для веб-разработки сайтов, в котором есть функции для быстрого добавления действий на веб-ресурс. Google активно применяет язык в ряде собственных проектов, а всё по причине удобной работы и широкого функционала, применимого в любых направлениях программирования. Если метите на место в Гугл, изучение Python – неплохой шанс начать работать в компании.

План курса
В ходе курса вы изучите основы языка Python и научитесь писать консольные программы на нём. Далее вам потребуется изучить дополнительные библиотеки, которые будут расширять и дополнять язык. На нашем сайте вы можете изучить не только Python, но и дополнительные библиотеки. Множество курсов по языку Python представлен по этой ссылке.
Большой курс
Хотите изучить больше информации и далее устроиться на фриланс или разрабатывать проекты для себя? Проходите нашу онлайн программу «Профессия Python разработчик».
Сферы применения языка python
Python – это не просто язык программирования. Это целый мир со своими возможностями, трудными задачами и способами их решений. Новичку, который только начал знакомство с языком, довольно трудно осознать, в каких областях могут пригодиться его знания.
На самом деле, выбор довольно огромный. Python с каждым днем всё активнее завоевывает рынок, и на сегодняшний день он занимает одну из лидирующих позиций среди все остальных языков, соревнуясь за первенство с «монолитами» индустрии.
Конечно, Питон никогда не сможет заменить низкоуровневые C и C++, ведь именно они способны практически полностью контролировать процессор, не займет место Java, предназначенный для разработки сложнейших приложений. Также, Python нельзя назвать аналогом JavaScript, который поддерживается огромной долей сайтов.
На самом деле, с Питоном всё максимально прозрачно – он простой и универсальный, поэтому может применяться для работы по многим направлениям.
Web-разработка

На Питоне можно делать весь backend интернет-ресурса, который будет выполняться на сервере. Делается это при помощи специальных фреймворков (Django и Flask), написанных на этом языке. С их помощью упрощается процесс обработки адресов, обращение к базам данный и создание HTML, отображающихся на пользовательских страницах.
На сегодняшний день сторонними разработчиками написано большое количество дополнительного инструментария, направленно на реализацию сетевых приложений. К примеру, инструмент HTMLGen позволяет создавать готовые классы под страницу на HTML, используя для этого язык Питон. А пакет mod_python облегчает запуск сценариев Apache, обеспечивая при этом стабильную работу шаблонов Python Server Pages.
Графический интерфейс

Если говорить о визуальной составляющей в сфере IT, то и здесь Python может показать себя как вполне эффективный инструмент, решающий массу задач. Создавая современные графические интерфейсы на Питоне, можно легко подстроиться под стилистику ОС, в чьей среде создается приложение. Специально для этих целей были созданы дополнительные библиотеки для построения интерфейса – PythonCard и Dabo, облегчающие процесс работы.
Базы данных

Разработчики современной версии Питона создали максимально простой и понятный доступ практически к любым базам данных. Так, на сегодняшний день, в рабочей среде языка находится программный интерфейс, который позволяет пользоваться базами прямиком из сценария с помощью запросов SQL. Также, код, написанный на Python, может с минимальными доработками использоваться для баз данных MySQL и Oracle.
Системное программирование

Ещё одна монетка в копилку возможностей Python – это интерфейсы языка, которые позволяют управлять службами операционных систем Windows, Linux и др. Благодаря этому, Питон открывает массу возможностей для создания портативных программ. Не секрет, что этот язык применяется для написания приложений, используемых системными администраторами. Таким образом, Python ускоряет поиск и открытие файлов, запуск приложений, облегчает вычисления и многое другое.
Сложные вычислительные процессы

Это та самая сфера, где Питон может потягаться в своих возможностях с FORTRAN или C++. Специальное расширение NumPy, написанное для математических расчётов, прекрасно функционирует с массивами, интерфейсами уравнений и другими данными. Как только расширение устанавливается на компьютер, Python без проблем проходит интеграцию с библиотеками формул.
Но NumPy предназначен не только для вычислений. Помимо своей основной задачи, с его помощью можно создавать анимированные элементы и прорисовывать объекты в среде 3D, производя при этом параллельные вычисления. Например, популярное дополнение ScientificPython может похвастаться собственными библиотеками, которые созданы для вычислительных процессов в сфере науки.
Помимо расчётов, Python позволяет визуализировать полученные данные, что довольно удобно.
Машинное обучение

Помимо основного инструментария, у Python есть дополнительные библиотеки и фреймворки, позволяющие работать в области машинного обучения. Особой популярностью пользуются scikit-learn и TensorFlow. Scikit-learn отличается тем, что в него уже встроены самые распространенные алгоритмы обучения. TensorFlow, в свою очередь – это низкоуровневая библиотека, которая открывает возможности для создания алгоритмов пользователя.
Процессы машинного обучения, основанные на языке программирования Python, помогают реализовывать системы распознавания лиц и голоса, создавать нейронные сети, глубокое обучение и многое другое.
Автоматизация процессов

Сегодня одним из самых востребованных способов использования языка Питон является создание мелких скриптов, автоматизирующих некоторые рабочие процессы. Например, можно написать вполне простой код, который будет «самостоятельно» работать с письмами на электронной почте. Если человеку необходимо отсортировывать письма с определенными ключевыми словами или фразами, то вручную это сделать довольно проблематично, а вот скрипт справится с этой задачей без проблем.
Почему для этого лучше всего использовать именно Python? Во-первых, он отличается вполне простым синтаксисом, который позволяет с легкостью разрабатывать сценарии. А во-вторых, сам код не проходит компиляцию перед запуском, что заметно облегчает процесс отладки.
Игровая индустрия

Зря многие люди недооценивают геймдейв, ведь именно благодаря нему появилось так много гаджетов, разработок и значительно улучшилась графика. Конечно, для крупных проектов Python вряд ли подойдет, его инструментарий в данной области несколько ограничен, но для фанатов этого языка собрать небольшие приложения и инди-игрушки — не такая уж и сложная задача. Для мультиплатформенных игр лучше всего подойдет движок Unity, управляемый с помощью языка C#. Этот инструмент как раз и создан для таких целей.
Изучая Python, не стоит бояться пробовать свои силы, выполняя простые задачи, создавая элементарные скрипты, даже если они кажутся вам слишком шаблонными. Ведь только таким образом вы сможете подобрать для себя подходящее направление, в котором захотите развиваться и строить карьеру.
У нас вы можете пройти курсы по изучению программирования на Python.
Как создать собственную нейронную сеть с нуля на языке Python
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, TensorFlow. Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры нейронной сети.
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Что такое нейронная сеть?
Большинство статей по нейронным сетям при их описании проводят параллели с мозгом. Мне проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат, не вникая в подробности.
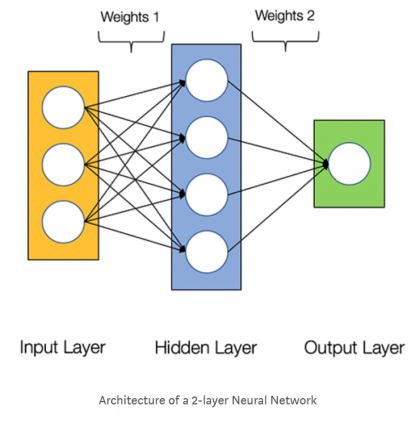
Нейронные сети состоят из следующих компонентов:
- входной слой, x
- произвольное количество скрытых слоев
- выходной слой, ŷ
- набор весов и смещений между каждым слоем W и b
- выбор функции активации для каждого скрытого слоя σ; в этой работе мы будем использовать функцию активации Sigmoid
На приведенной ниже диаграмме показана архитектура двухслойной нейронной сети (обратите внимание, что входной уровень обычно исключается при подсчете количества слоев в нейронной сети).
Создание класса Neural Network на Python выглядит просто:
Обучение нейронной сети
Выход ŷ простой двухслойной нейронной сети:
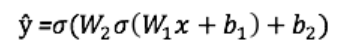
В приведенном выше уравнении, веса W и смещения b являются единственными переменными, которые влияют на выход ŷ.
Естественно, правильные значения для весов и смещений определяют точность предсказаний. Процесс тонкой настройки весов и смещений из входных данных известен как обучение нейронной сети.
Каждая итерация обучающего процесса состоит из следующих шагов
- вычисление прогнозируемого выхода ŷ, называемого прямым распространением
- обновление весов и смещений, называемых обратным распространением
Последовательный график ниже иллюстрирует процесс:
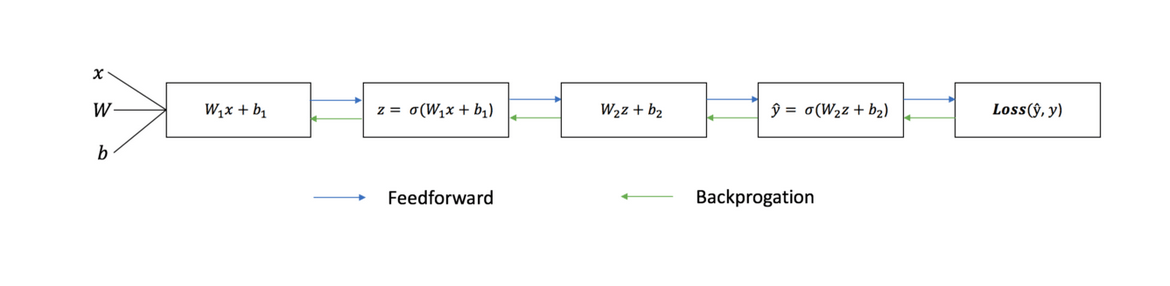
Прямое распространение
Как мы видели на графике выше, прямое распространение — это просто несложное вычисление, а для базовой 2-слойной нейронной сети вывод нейронной сети дается формулой:
Давайте добавим функцию прямого распространения в наш код на Python-е, чтобы сделать это. Заметим, что для простоты, мы предположили, что смещения равны 0.
Однако нужен способ оценить «добротность» наших прогнозов, то есть насколько далеки наши прогнозы). Функция потери как раз позволяет нам сделать это.
Функция потери
Есть много доступных функций потерь, и характер нашей проблемы должен диктовать нам выбор функции потери. В этой работе мы будем использовать сумму квадратов ошибок в качестве функции потери.

Сумма квадратов ошибок — это среднее значение разницы между каждым прогнозируемым и фактическим значением.
Цель обучения — найти набор весов и смещений, который минимизирует функцию потери.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения.
Чтобы узнать подходящую сумму для корректировки весов и смещений, нам нужно знать производную функции потери по отношению к весам и смещениям.
Напомним из анализа, что производная функции — это тангенс угла наклона функции.
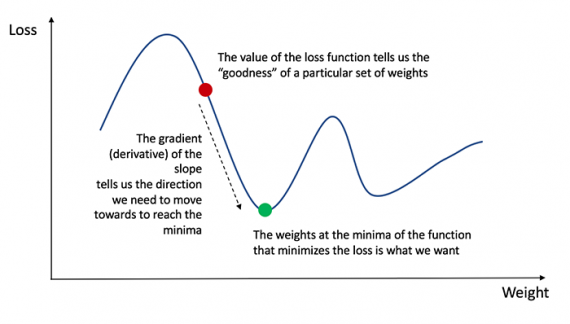
Если у нас есть производная, то мы можем просто обновить веса и смещения, увеличив/уменьшив их (см. диаграмму выше). Это называется градиентным спуском.
Однако мы не можем непосредственно вычислить производную функции потерь по отношению к весам и смещениям, так как уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно правило цепи для помощи в вычислении.

Фух! Это было громоздко, но позволило получить то, что нам нужно — производную (наклон) функции потерь по отношению к весам. Теперь мы можем соответствующим образом регулировать веса.
Добавим функцию backpropagation (обратного распространения) в наш код на Python-е:
Проверка работы нейросети
Теперь, когда у нас есть наш полный код на Python-е для выполнения прямого и обратного распространения, давайте рассмотрим нашу нейронную сеть на примере и посмотрим, как это работает.
 Идеальный набор весов
Идеальный набор весовНаша нейронная сеть должна изучить идеальный набор весов для представления этой функции.
Давайте тренируем нейронную сеть на 1500 итераций и посмотрим, что произойдет. Рассматривая график потерь на итерации ниже, мы можем ясно видеть, что потеря монотонно уменьшается до минимума. Это согласуется с алгоритмом спуска градиента, о котором мы говорили ранее.

Посмотрим на окончательное предсказание (вывод) из нейронной сети после 1500 итераций.
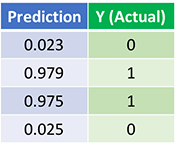
Мы сделали это! Наш алгоритм прямого и обратного распространения показал успешную работу нейронной сети, а предсказания сходятся на истинных значениях.
Заметим, что есть небольшая разница между предсказаниями и фактическими значениями. Это желательно, поскольку предотвращает переобучение и позволяет нейронной сети лучше обобщать невидимые данные.
Финальные размышления
Я многому научился в процессе написания с нуля своей собственной нейронной сети. Хотя библиотеки глубинного обучения, такие как TensorFlow и Keras, допускают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я нахожу, что начинающим Data Scientist-ам полезно получить более глубокое их понимание.
Я инвестировал много своего личного времени в данную работу, и я надеюсь, что она будет полезной для вас!
Руководств по программированию на Python
K-средние с нуля в Python
Добро пожаловать в 37-ю часть нашей серии руководств по машинному обучению и еще одно руководство по теме «Кластеризация ». .
В этом уроке мы собираемся построить наш собственный алгоритм K-средних с нуля. Напомним методологию алгоритма K Means:
- Выберите значение для K
- Произвольно выберите K наборов функций для запуска в качестве центроидов
- Расчет расстояния до центроидов всех остальных наборов функций
- Классифицировать другие наборы функций как те же, что и ближайший центроид
- Возьмите среднее значение каждого класса (среднее значение всех наборов функций по классам), что означает новый центроид
- Повторяйте шаги 3-5 до оптимизации (центроиды больше не перемещаются)
Для начала начнем с:
импорт matplotlib.pyplot как plt
из стиля импорта matplotlib
style.use ('ggplot')
импортировать numpy как np
X = np.array ([[1, 2],
[1.5, 1.8],
[5, 8],
[8, 8],
[1, 0,6],
[9,11]])
plt.scatter (X [:, 0], X [:, 1], s = 150)
plt.show () Должно быть очевидно, где находятся наши кластеры. Мы собираемся выбрать K = 2 . Мы начнем строить наш класс K-средних:
класс К_Средство:
def __init __ (self, k = 2, tol = 0.001, max_iter = 300):
я.к = к
self.tol = tol
self.max_iter = max_iter Мы только что установили здесь некоторые начальные значения, k равно … ну … k. Значение tol — это наш допуск, который позволит нам сказать, что мы оптимизированы, если центроид перемещается не больше, чем значение допуска. Значение max_iter ограничивает количество циклов, которые мы хотим запустить.
Теперь начнем работать над методом подгонки:
def fit (self, data):
self.centroids = {}
для i в диапазоне (self.л):
self.centroids [i] = data [i] Для начала мы знаем, что нам просто нужно передать те данные, которым мы подходим. Затем мы начинаем пустой словарь, который скоро будет содержать наши центроиды. Затем мы начинаем цикл for, который просто назначает наши начальные центроиды в качестве первых двух выборок данных в наших данных. Если вы хотите действительно случайным образом выбрать начальные центроиды, вы можете сначала перетасовать данные, но это должно быть нормально.
Продолжаем строить класс:
класс К_Средство:
def __init __ (self, k = 2, tol = 0.001, max_iter = 300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit (self, data):
self.centroids = {}
для i в диапазоне (self.k):
self.centroids [i] = data [i]
для i в диапазоне (self.max_iter):
self.classifications = {}
для i в диапазоне (self.k):
self.classification [i] = [] Теперь мы начинаем перебирать значение max_iter . Здесь мы начинаем с пустых классификаций, а затем создаем два ключа dict (путем итерации по диапазону self.к ).
Затем нам нужно перебрать наши объекты, вычислить расстояния от них до текущих центроидов и классифицировать их как таковые:
класс К_Средство:
def __init __ (self, k = 2, tol = 0.001, max_iter = 300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit (self, data):
self.centroids = {}
для i в диапазоне (self.k):
self.centroids [i] = data [i]
для i в диапазоне (self.max_iter):
я.классификации = {}
для i в диапазоне (self.k):
self.classification [i] = []
для набора функций в данных:
Distance = [np.linalg.norm (featureset-self.centroids [centroid]) для центроида в self.centroids]
классификация = distance.index (min (расстояния))
self.classifications [классификация] .append (набор функций) Далее нам нужно будет создать новые центроиды, а также измерить движение центроидов.Если это движение меньше нашего допуска ( self.tol ), то все готово. Включая это дополнение, полный код до этого момента:
импортировать matplotlib.pyplot как plt
из стиля импорта matplotlib
style.use ('ggplot')
импортировать numpy как np
X = np.array ([[1, 2],
[1.5, 1.8],
[5, 8],
[8, 8],
[1, 0,6],
[9,11]])
plt.scatter (X [:, 0], X [:, 1], s = 150)
plt.show ()
colors = 10 * ["g", "r", "c", "b", "k"]
класс K_Means:
def __init __ (self, k = 2, tol = 0.001, max_iter = 300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit (self, data):
self.centroids = {}
для i в диапазоне (self.k):
self.centroids [i] = data [i]
для i в диапазоне (self.max_iter):
self.classifications = {}
для i в диапазоне (self.k):
self.classification [i] = []
для набора функций в данных:
Distance = [np.linalg.norm (featureset-self.centroids [centroid]) для центроида в self.центроиды]
классификация = distance.index (min (расстояния))
self.classifications [классификация] .append (набор функций)
prev_centroids = dict (self.centroids)
для отнесения к самоклассификации:
self.centroids [классификация] = np.average (self.classifications [классификация], ось = 0)
В следующем уроке мы закончим наш класс и посмотрим, как он работает!
Следующий учебник: Завершение K-средних с нуля в Python
Python — Scratch Wiki
| В этой статье есть ссылки на веб-сайты или программы, которым Scratch не доверяет и которые размещены в Википедии.Не забывайте оставаться в безопасности при использовании Интернета, поскольку мы не можем гарантировать безопасность других веб-сайтов. |
Python — это язык программирования, который обычно считается очень удобочитаемым и обычно изучается после освоения Scratch [ необходима цитата ] . Впервые он был выпущен в 1991 году Гвидо ван Россумом. [1]
На этой странице описывается использование Python с Scratch и различных программ Python, связанных с Scratch.
Расширения
Существуют библиотеки, упрощающие написание кода Python, взаимодействующего с Scratch.
Обратите внимание, что механизмы расширения для Scratch 1.4 и Scratch 2.0 совершенно разные и несовместимы.
Скретч 2,0
- blockext — для написания расширений, совместимых с Scratch 2.0 и Snap !. Автоматически генерирует файлы расширения. Чистый интерфейс программирования. Требуется документация.
- pyscratch3 — позволяет получить Scratch API из проекта в коде Python. (не работает на компьютерах Mac)
- ScratchAPI — библиотека Python с открытым исходным кодом, предоставляющая интерфейс для Scratch API.
Царапина 1,4
См. Руководство по настройке подключений удаленного датчика в Scratch 1.4.
- Scratra — Обеспечивает чистый интерфейс для ответа на широковещательные сообщения и обновления датчиков с использованием декораторов. (на основе scratch.py)
- scratch.py (страница форума) от pquiza — предоставляет код для связи с Scratch
- Scratch Space от Magnie — сервер Mesh
Проекты, которые взаимодействуют со Scratch с помощью Python и подключений удаленных датчиков:
- scratch3web.py by TheSuccessor — позволяет использовать Scratch в качестве веб-сервера
Программное обеспечение
Программное обеспечениеScratch, написанное на Python:
- M30W, ранее Emerald — текстовая версия Scratch
Scratch-связанных библиотек, которые можно использовать в коде Python:
Общая информация
| Тема этой статьи или раздела сильно изменилась и требует обновления. Помните, что некоторая информация или изображения могут быть неточными или иметь отношение к текущей версии Scratch, веб-сайту Scratch или теме статьи. (апрель 2019) |
- См. Также: Scratch 2.0
Scratch 2.0 использовал Python в качестве внутреннего или серверного кода. Это означает, что страницы на сайте (например, студия или страница профиля) создаются кодом Python. Между Python и интерфейсом находится Django, библиотека Python для создания больших веб-сайтов на базе баз данных.
Список литературы
Внешние ссылки
Лучшая цена на скретч-питон — отличные предложения на скретч-питоне от мировых продавцов скретч-питона
Отличные новости !!! Вы попали в нужное место для скретч-питона.К настоящему времени вы уже знаете, что что бы вы ни искали, вы обязательно найдете это на AliExpress. У нас буквально тысячи отличных продуктов во всех товарных категориях. Ищете ли вы товары высокого класса или дешевые и недорогие оптовые закупки, мы гарантируем, что он есть на AliExpress.
Вы найдете официальные магазины торговых марок наряду с небольшими независимыми продавцами со скидками, каждый из которых предлагает быструю доставку и надежные, а также удобные и безопасные способы оплаты, независимо от того, сколько вы решите потратить.
AliExpress никогда не уступит по выбору, качеству и цене. Каждый день вы будете находить новые онлайн-предложения, скидки в магазинах и возможность сэкономить еще больше, собирая купоны. Но вам, возможно, придется действовать быстро, поскольку этот первоклассный питон быстро станет одним из самых востребованных бестселлеров. Подумайте, как вам будут завидовать друзья, когда вы скажете им, что приобрели своего скретч-питона на AliExpress.Благодаря самым низким ценам в Интернете, дешевым тарифам на доставку и возможности получения на месте вы можете еще больше сэкономить.
Если вы все еще не знаете, что такое царапающий питон и думаете о выборе аналогичного товара, AliExpress — отличное место для сравнения цен и продавцов. Мы поможем вам решить, стоит ли доплачивать за высококлассную версию или вы получаете столь же выгодную сделку, приобретая более дешевую вещь.А если вы просто хотите побаловать себя и потратиться на самую дорогую версию, AliExpress всегда позаботится о том, чтобы вы могли получить лучшую цену за свои деньги, даже сообщая вам, когда вам будет лучше дождаться начала рекламной акции. и ожидаемая экономия.AliExpress гордится тем, что у вас всегда есть осознанный выбор при покупке в одном из сотен магазинов и продавцов на нашей платформе. Реальные покупатели оценивают качество обслуживания, цену и качество каждого магазина и продавца.Кроме того, вы можете узнать рейтинги магазина или отдельных продавцов, а также сравнить цены, доставку и скидки на один и тот же продукт, прочитав комментарии и отзывы, оставленные пользователями. Каждая покупка имеет звездный рейтинг и часто имеет комментарии, оставленные предыдущими клиентами, описывающими их опыт транзакций, поэтому вы можете покупать с уверенностью каждый раз. Короче говоря, вам не нужно верить нам на слово — просто слушайте миллионы наших довольных клиентов.
А если вы новичок на AliExpress, мы откроем вам секрет.Непосредственно перед тем, как вы нажмете «купить сейчас» в процессе транзакции, найдите время, чтобы проверить купоны — и вы сэкономите еще больше. Вы можете найти купоны магазина, купоны AliExpress или собирать купоны каждый день, играя в игры в приложении AliExpress. Вместе с бесплатной доставкой, которую предлагают большинство продавцов на нашем сайте, вы сможете приобрести Scratch python по самой выгодной цене.
У нас всегда есть новейшие технологии, новейшие тенденции и самые обсуждаемые лейблы.На AliExpress отличное качество, цена и сервис всегда в стандартной комплектации. Начните лучший опыт покупок прямо здесь.
Python с нуля LiveLessons [Видео]
5 часов видеоинструкцийОписание
Python from Scratch LiveLessons — более нежный, интересный и многогранный практическая отправная точка для изучения языка программирования Python.В отличие от типичный подход к обучению языку программирования, охватывающий каждый раздел за разделом, этот курс больше похож на кулинарный класс. Вы можете следить и выполнять весь код, демонстрируемый в интерактивный блокнот, пока вы смотрите видео, почти так же, как вы бы смотрели видео о приготовлении пищи на вашей кухне.
Загрузите ресурсы, необходимые для использования этого LiveLesson:
Уровень навыка- Начинающий уровень для всех, кто плохо знаком с Python и объектно-ориентированным программированием.Строится из перейти от новичка к более продвинутым темам с помощью последующих подход.
Чему вы научитесь
- Как пользоваться интерактивная платформа ноутбука Jupyter для выполнения простых команд
- Как используйте оператор импорта для использования внешнего кода и чтения ввода из внешнего исходный код
- Как работать со строками и как использовать операторы индексации
- Как писать программные элементы управления
- Как использовать встроенные типы и запись / использование пользовательских типов
- Как получить доступ к элементам в словарях
- Как использовать управляющие структуры if и elif
- Как воспользоваться преимуществами словарей и кортежей
- Как писать сложные функции
- Как использовать аргументы ключевого слова в функциях
- Как писать классы и использовать наследование
- Как считывать данные и передавать данные другим программам
- Как создавать обратные вызовы и имитировать классы
- Как использовать сторонние библиотеки
- Как документировать код Python
Кому следует брать Этот курс
- Всем, кто заинтересован в изучении основ программирование с использованием Python, который предпочитает более практический, прагматичный подход к обучение
Требования к курсу
- Предполагает базовый уровень знакомство с концепциями программирования, но без предыдущего опыта программирования в Python требуется
- Python 3 с Jupyter (http: // bit.ly / PyScratchInstall) установлен на вашем компьютере, вместе с исходными файлами, найденными на http://bit.ly/PyScratch. Загрузки Anaconda доступны для Apple OS X, Microsoft Windows и большинства Дистрибутивы Linux.
- Современный веб-браузер, например Google Chrome (https://www.google.com/chrome)
Описание уроков
Урок 1:
Настройка
В этом уроке показано, как настроить платформу, используемую повсюду.
курс. Он также демонстрирует конечный продукт — фабрику пирогов, которую вы
взаимодействовать с через веб-браузер.Бэкэнд демонстрирует, как удерживать
логика и данные, которые питают фабрику.
Урок 2:
Рецепт — Работа с текстом в Python
Этот урок посвящен тому, как читать
вход от внешнего источника. В данном случае это копия моего
Рецепт бабушкиного яблочного пирога сохранен на диск. Мы разбиваем текст на
части. Введем понятие функций. Наконец, мы реорганизуем все
разбиение кода рецепта на функции для введения
возможность повторного использования.
Урок 3: Ингредиенты — базовые типы Python (строка,
int, decimal, tuple, lists)
Этот урок посвящен преобразованию текста
в рецепте в некоторые репрезентативные типы данных, чтобы мы могли с ними работать.За
Например, нашей программе необходимо знать, что на самом деле означает строка «1/2 стакана муки»
означает.
Урок 4: Смешивание ингредиентов – словари Python
В Уроке 2 мы читаем ингредиенты / шаги. В Уроке 3 мы проанализировали эти
ингредиенты, чтобы понять, что они делают. Теперь мы делаем шаги
и смешайте ингредиенты, чтобы глубже понять
структуры данных, например словари.
Урок 5 Bake It – Python:
Функции
В этом уроке более подробно рассматриваются функции в Python.Ты учишь
о синтаксисе, как писать, как выполнять и как документировать. Ты учишь
немного о том, как запускать несколько функций одновременно. Наконец, ты
узнать о параметрах и аргументах и о том, как их можно настроить, чтобы
сформировать больше функциональности для выполнения реальных задач при повторном использовании
код.
Урок 6: Многие типы классов Pie – Python
В этом
урок, мы приступаем к созданию нашего собственного Pie Class. Метафора бега прекрасно сочетается
с идеей повторяемости без отказа от гибкости.Мы переживаем
красота Python, поскольку мы начинаем глубже погружаться в концепции объектного
ориентированное программирование.
Урок 7: Фабрика пирогов — объектно-ориентированный
Python
В этом уроке вы узнаете, как Python работает как связующий язык.
Вы узнаете об интерфейсах прикладных программ (API) и о том, как и зачем использовать
их. Как и в уроке 2, когда мы считываем данные в нашу программу, вы теперь узнаете
как мы одновременно считываем данные и отправляем данные другим программам. Это позволяет нашим
программа для разговора с другой программой.Прежде чем мы это сделаем, мы устанавливаем моделирование, чтобы
можно функционально изолировать, прежде чем мы подключим все это в Уроке 8.
Урок
8. Pie Store – Visuals UX / UI Design
На этом последнем уроке мы создадим
нашу полную программу и поговорим о стеке технологий. Создаем простой
Пользовательский интерфейс для браузера, и мы подключаем его к нашему коду. Мы узнаем о
пара библиотек с открытым исходным кодом, которые предоставляют некоторые базовые функции для
поддержите нас в этой задаче.
О видео-тренингах LiveLessons
В серии видео-тренингов LiveLessons публикуются сотни практических, видеоуроки под руководством экспертов, охватывающие широкий выбор тем, связанных с технологиями разработан, чтобы научить вас навыкам, необходимым для достижения успеха.Этот профессионал и серия видео о персональных технологиях с участием ведущих мировых преподавателей-авторов опубликовано вашими надежными технологическими брендами: Addison-Wesley, Cisco Press, IBM Press, Pearson IT Certification, Prentice Hall, Sams и Que. Темы включают: ИТ-сертификация, программирование, веб-разработка, мобильная разработка, дом и Офисные технологии, бизнес и менеджмент и многое другое. Просмотреть все живые уроки на InformIT по адресу: http://www.informit.com/livelessons
Реализация нейронной сети с нуля на Python — Введение — WildML
Получите код: весь код также доступен в виде записной книжки iPython на Github.
В этом посте мы реализуем простую трехслойную нейронную сеть с нуля. Мы не получим всю необходимую математику, но я попытаюсь дать интуитивное объяснение того, что мы делаем. Я также укажу на ресурсы, чтобы вы могли прочитать подробности.
Здесь я предполагаю, что вы знакомы с основными концепциями исчисления и машинного обучения, например вы знаете, что такое классификация и регуляризация. В идеале вы также должны немного знать о том, как работают методы оптимизации, такие как градиентный спуск.Но даже если вы не знакомы ни с одним из вышеперечисленных, этот пост все равно может оказаться интересным;)
Но зачем вообще создавать нейронную сеть с нуля? Даже если вы планируете использовать библиотеки нейронной сети, такие как PyBrain, в будущем, реализация сети с нуля хотя бы один раз является чрезвычайно ценным упражнением. Это поможет вам понять, как работают нейронные сети, и это важно для разработки эффективных моделей.
Следует отметить, что приведенные здесь примеры кода не очень эффективны.Они предназначены для того, чтобы их было легко понять. В следующем посте я расскажу, как написать эффективную реализацию нейронной сети с помощью Theano. (Обновление: уже доступно)
Создание набора данных
Давайте начнем с создания набора данных, с которым мы можем поиграть. К счастью, в scikit-learn есть несколько полезных генераторов наборов данных, поэтому нам не нужно писать код самостоятельно. Мы воспользуемся функцией make_moons.
# Создать набор данных и построить его нп. случайный.семя (0) X, y = sklearn.datasets.make_moons (200, шум = 0.20) plt.scatter (X [:, 0], X [:, 1], s = 40, c = y, cmap = plt.cm.Spectral)
# Создать набор данных и построить его np.random.seed (0) X, y = sklearn.datasets.make_moons (200, noise = 0.20) plt.scatter (X [:, 0], X [:, 1], s = 40, c = y, cmap = plt.cm.Spectral) |
Созданный нами набор данных состоит из двух классов, обозначенных красными и синими точками.Вы можете думать о синих точках как о пациентах-мужчинах, а о красных точках как о пациентах-женщинах, а оси x и y — это медицинские измерения.
Наша цель — обучить классификатор машинного обучения, который предсказывает правильный класс (мужчина или женщина) с учетом координат x и y. Обратите внимание, что данные нельзя разделить линейно, мы не можем провести прямую линию, разделяющую два класса. Это означает, что линейные классификаторы, такие как логистическая регрессия, не смогут соответствовать данным, если вы вручную не создадите нелинейные функции (например, полиномы), которые хорошо работают для данного набора данных.
Фактически, это одно из главных преимуществ нейронных сетей. Вам не нужно беспокоиться о проектировании функций. Скрытый слой нейронной сети научит вас особенностям.
Логистическая регрессия
Чтобы продемонстрировать это, давайте обучим классификатор логистической регрессии. На входе будут значения x и y, а на выходе — предсказанный класс (0 или 1). Чтобы упростить нашу жизнь, мы используем класс логистической регрессии из scikit-learn .
# Обучить классификатор логистической регрессии clf = sklearn.linear_model.LogisticRegressionCV () clf.fit (X, y) # Постройте границу решения plot_decision_boundary (лямбда x: clf.predict (x)) plt.title («Логистическая регрессия»)
# Обучите классификатор логистической регрессии clf = sklearn.linear_model.LogisticRegressionCV () clf.fit (X, y) # Постройте границу решения plot_decision_boundary (lambda.прогноз (x)) plt.title («Логистическая регрессия») |
График показывает границу решения, полученную нашим классификатором логистической регрессии. Он разделяет данные настолько хорошо, насколько может, используя прямую линию, но не может уловить «форму луны» наших данных.
Обучение нейронной сети
Давайте теперь построим трехслойную нейронную сеть с одним входным слоем, одним скрытым слоем и одним выходным слоем.Количество узлов на входном слое определяется размерностью наших данных, 2. Точно так же количество узлов в выходном слое определяется количеством классов, которые у нас есть, также 2. (Поскольку у нас есть только 2 класса, мы на самом деле может уйти только один выходной узел, предсказывающий 0 или 1, но наличие 2 упрощает расширение сети на большее количество классов в дальнейшем). Входными данными в сеть будут координаты x и y, а на выходе — две вероятности: одна для класса 0 («женский») и одна для класса 1 («мужской»).Выглядит это примерно так:
Мы можем выбрать размерность (количество узлов) скрытого слоя. Чем больше узлов мы поместим в скрытый слой, тем более сложные функции мы сможем уместить. Но более высокая размерность имеет свою цену. Во-первых, требуется больше вычислений, чтобы делать прогнозы и изучать параметры сети. Большее количество параметров также означает, что мы становимся более склонными к переоснащению наших данных.
Как выбрать размер скрытого слоя? Хотя есть некоторые общие правила и рекомендации, это всегда зависит от вашей конкретной проблемы и является скорее искусством, чем наукой.Позже мы поиграем с количеством скрытых узлов и посмотрим, как это повлияет на наш вывод.
Нам также нужно выбрать функцию активации для нашего скрытого слоя. Функция активации преобразует входы слоя в его выходы. Нелинейная функция активации — это то, что позволяет нам соответствовать нелинейным гипотезам. Обычно для функций активации выбирают tanh, сигмовидную функцию или ReLU. Мы будем использовать tanh , который достаточно хорошо работает во многих сценариях.Приятным свойством этих функций является то, что их производная может быть вычислена с использованием исходного значения функции. Например, производная от. Это полезно, потому что позволяет нам вычислить один раз и повторно использовать его значение позже, чтобы получить производную.
Поскольку мы хотим, чтобы наша сеть выводила вероятности, функцией активации для выходного уровня будет softmax, который представляет собой просто способ конвертировать необработанные оценки в вероятности. Если вы знакомы с логистической функцией, вы можете думать о softmax как о ее обобщении на несколько классов.
Как наша сеть делает прогнозы
Наша сеть делает прогнозы, используя прямое распространение, которое представляет собой всего лишь набор умножений матриц и применение функций активации, которые мы определили выше. Если x — двумерный вход для нашей сети, то мы вычисляем наш прогноз (также двумерный) следующим образом:
— это вход слоя и выход слоя после применения функции активации. — это параметры нашей сети, которые нам нужно узнать из наших обучающих данных.Вы можете думать о них как о матрицах, преобразующих данные между уровнями сети. Глядя на матричные умножения выше, мы можем выяснить размерность этих матриц. Если мы используем 500 узлов для нашего скрытого слоя, то,,,. Теперь вы понимаете, почему у нас больше параметров, если мы увеличиваем размер скрытого слоя.
Изучение параметров
Изучение параметров нашей сети означает нахождение параметров (), которые минимизируют ошибку в наших обучающих данных. Но как определить ошибку? Мы называем функцию, которая измеряет нашу ошибку, функцией потерь .Обычным выбором для вывода softmax является категориальная кросс-энтропийная потеря (также известная как отрицательное логарифмическое правдоподобие). Если у нас есть обучающие примеры и классы, то потеря нашего прогноза относительно истинных меток будет равна:
Формула выглядит сложной, но на самом деле она суммирует наши обучающие примеры и добавляет к потерям, если мы предсказали неправильный класс. Чем дальше расположены два распределения вероятностей (правильные метки) и (наши прогнозы), тем больше будут наши потери.Находя параметры, которые минимизируют потери, мы максимизируем вероятность наших обучающих данных.
Мы можем использовать градиентный спуск, чтобы найти минимум, и я буду реализовывать самую ванильную версию градиентного спуска, также называемую пакетным градиентным спуском с фиксированной скоростью обучения. Такие варианты, как SGD (стохастический градиентный спуск) или градиентный спуск минипакет, обычно лучше работают на практике. Так что, если вы настроены серьезно, вы захотите использовать один из них, и в идеале вы также со временем снизите скорость обучения.
В качестве входных данных для градиентного спуска необходимы градиенты (вектор производных) функции потерь по нашим параметрам:,,,. Для вычисления этих градиентов мы используем знаменитый алгоритм обратного распространения , который является способом эффективного вычисления градиентов, начиная с вывода. Я не буду вдаваться в подробности того, как работает обратное распространение ошибки, но в сети есть много отличных объяснений (здесь или здесь).
Применяя формулу обратного распространения ошибки, мы находим следующее (поверьте мне):
Реализация
Теперь мы готовы к реализации.Начнем с определения некоторых полезных переменных и параметров для градиентного спуска:
num_examples = len (X) # размер обучающего набора nn_input_dim = 2 # размерность входного слоя nn_output_dim = 2 # размерность выходного слоя # Параметры градиентного спуска (подбирал вручную) epsilon = 0,01 # скорость обучения для градиентного спуска reg_lambda = 0.01 # сила регуляризации
num_examples = len (X) # размер обучающего набора nn_input_dim = 2 # размерность входного слоя nn_output_dim = 2 # размерность выходного слоя # Параметры градиентного спуска (я выбрал их вручную) epsilon .01 # скорость обучения для градиентного спуска reg_lambda = 0,01 # сила регуляризации |
Сначала давайте реализуем функцию потерь, которую мы определили выше. Мы используем это, чтобы оценить, насколько хорошо работает наша модель:
# Вспомогательная функция для оценки общих потерь в наборе данных def calculate_loss (модель): W1, b1, W2, b2 = модель [‘W1’], модель [‘b1’], модель [‘W2’], модель [‘b2’] # Прямое распространение для расчета наших прогнозов z1 = X.точка (W1) + b1 a1 = np.tanh (z1) z2 = a1.dot (W2) + b2 exp_scores = np.exp (z2) probs = exp_scores / np.sum (exp_scores, axis = 1, keepdims = True) # Расчет убытка corect_logprobs = -np.log (probs [диапазон (num_examples), y]) data_loss = np.sum (corect_logprobs) # Добавить срок регулирования к убытку (необязательно) data_loss + = reg_lambda / 2 * (np.sum (np.square (W1)) + np.sum (np.square (W2))) вернуть 1./num_examples * data_loss
# Вспомогательная функция для оценки общих потерь в наборе данных def calculate_loss (model): W1, b1, W2, b2 = model [‘W1’], model [‘b1’], model [‘W2’ ], модель [‘b2’] # Распространение в прямом направлении для расчета наших прогнозов z1 = X.точка (W1) + b1 a1 = np.tanh (z1) z2 = a1.dot (W2) + b2 exp_scores = np.exp (z2) probs = exp_scores / np.sum (exp_scores, axis = 1, keepdims = True) # Расчет потерь corect_logprobs = -np.log (probs [range (num_examples), y]) data_loss = np.sum (corect_logprobs) # Добавить срок регулирования в потеря (необязательно) data_loss + = reg_lambda / 2 * (np.sum (np.square (W1)) + np.sum (np.square (W2))) return 1./num_examples * data_loss |
Мы также реализуем вспомогательную функцию для вычисления выхода сети. Он выполняет прямое распространение, как определено выше, и возвращает класс с наибольшей вероятностью.
# Вспомогательная функция для прогнозирования вывода (0 или 1) def прогнозировать (модель, x): W1, b1, W2, b2 = модель [‘W1’], модель [‘b1’], модель [‘W2’], модель [‘b2’] # Прямое распространение z1 = х.точка (W1) + b1 a1 = np.tanh (z1) z2 = a1.dot (W2) + b2 exp_scores = np.exp (z2) probs = exp_scores / np.sum (exp_scores, axis = 1, keepdims = True) return np.argmax (probs, axis = 1)
# Вспомогательная функция для прогнозирования результата (0 или 1) def прогноз (модель, x): W1, b1, W2, b2 = модель [‘W1’], модель [‘b1’], модель [ ‘W2’], модель [‘b2’] # Прямое распространение z1 = x.точка (W1) + b1 a1 = np.tanh (z1) z2 = a1.dot (W2) + b2 exp_scores = np.exp (z2) probs = exp_scores / np.sum (exp_scores, axis = 1, keepdims = True) return np.argmax (probs, axis = 1) |
И, наконец, появилась функция для обучения нашей нейронной сети. Он реализует пакетный градиентный спуск с использованием производных обратного распространения, которые мы нашли выше.
# Эта функция изучает параметры нейронной сети и возвращает модель.# — nn_hdim: количество узлов в скрытом слое # — num_passes: количество проходов через обучающие данные для градиентного спуска # — print_loss: Если True, выводить убыток каждые 1000 итераций def build_model (nn_hdim, num_passes = 20000, print_loss = False): # Инициализировать параметры случайными значениями. Нам нужно этому научиться. np.random.seed (0) W1 = np.random.randn (nn_input_dim, nn_hdim) / np.sqrt (nn_input_dim) b1 = np.zeros ((1, nn_hdim)) W2 = np.random.randn (nn_hdim, nn_output_dim) / np.sqrt (nn_hdim) b2 = np.zeros ((1, nn_output_dim)) # Это то, что мы возвращаем в конце модель = {} # Градиентный спуск. Для каждой партии … для i в xrange (0, num_passes): # Прямое распространение z1 = X.dot (W1) + b1 a1 = np.tanh (z1) z2 = a1.dot (W2) + b2 exp_scores = np.exp (z2) probs = exp_scores / np.sum (exp_scores, axis = 1, keepdims = True) # Обратное распространение delta3 = вероятность delta3 [диапазон (num_examples), y] — = 1 dW2 = (a1.Т). Точка (дельта3) db2 = np.sum (delta3, axis = 0, keepdims = True) delta2 = delta3.dot (W2.T) * (1 — np.power (a1, 2)) dW1 = np.dot (X.T, дельта2) db1 = np.sum (delta2, ось = 0) # Добавить условия регуляризации (b1 и b2 не имеют условий регуляризации) dW2 + = reg_lambda * W2 dW1 + = reg_lambda * W1 # Обновление параметра градиентного спуска W1 + = -псилон * dW1 b1 + = -псилон * db1 W2 + = -псилон * dW2 b2 + = -псилон * db2 # Назначить модели новые параметры model = {‘W1’: W1, ‘b1’: b1, ‘W2’: W2, ‘b2’: b2} # При желании распечатать убыток.# Это дорого, потому что используется весь набор данных, поэтому мы не хотим делать это слишком часто. если print_loss и я% 1000 == 0: напечатайте & quot; Потери после итерации% i:% f & quot; % (i, calculate_loss (модель)) вернуть модель
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 13 14 18 19 20 21 22 23 24 25 26 27 28 29 30 3435 36 37 38 39 40 41 42 43 44 45 46 47 51 52 53 54 |