Различия между искусственным интеллектом, машинным обучением и глубоким обучением
Искусственный интеллект, машинное обучение и глубокое обучение уже сейчас являются неотъемлемой частью многих предприятий. Часто эти термины используются как синонимы.Искусственный интеллект движется огромными шагами — от достижений в области беспилотных транспортных средств и способности обыгрывать человека в такие игры, как покер и Го, к автоматизированному обслуживанию клиентов. Искусственный интеллект — это передовая технология, которая готова произвести революцию в бизнесе.
Часто термины искусственный интеллект, машинное обучение и глубокое обучение используются бессистемно как взаимозаменяемые, но, на самом деле, между ними есть различия. Чем именно различаются эти термины будет рассказано далее.
Искусственный интеллект (ИИ)
Искусственный интеллект — широкое понятие, касающееся передового машинного интеллекта. В 1956 году на конференции по искусственному интеллекту в Дартмуте эта технология была описана следующим образом: «Каждый аспект обучения или любая другая особенность интеллекта могут быть в принципе так точно описаны, что машина сможет сымитировать их.
 »
»Искусственный интеллект может относиться к чему угодно — от компьютерных программ для игры в шахматы до систем распознавания речи, таких, например, как голосовой помощник Amazon Alexa, способный воспринимать речь и отвечать на вопросы. В целом системы искусственного интеллекта можно разделить на три группы: ограниченный искусственный интеллект (Narrow AI), общий искусственный интеллект (AGI) и сверхразумный искусственный интеллект.
Программа Deep Blue компании IBM, которая в 1996 году обыграла в шахматы Гарри Каспарова, или программа AlphaGo компании Google DeepMind, которая в 2016 году обыграла чемпиона мира по Го Ли Седоля, являются примерами ограниченного искусственного интеллекта, способного решать одну конкретную задачу. Это его главное отличие от общего искусственного интеллекта (AGI), который стоит на одном уровне с человеческим интеллектом и может выполнять много разных задач.
Сверхразумный искусственный интеллект стоит на ступень выше человеческого. Ник Бостром описывает его следующим образом: это «интеллект, который намного умнее, чем лучший человеческий мозг, практически во всех областях, в том числе в научном творчестве, общей мудрости и социальных навыках.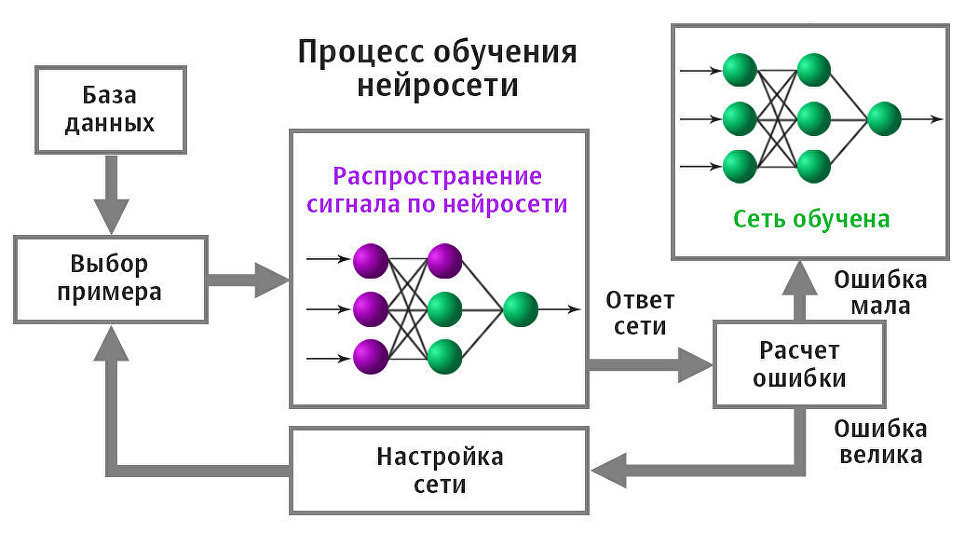
Машинное обучение
Машинное обучение является одним из направлений искусственного интеллекта. Основной принцип заключается в том, что машины получают данные и «обучаются» на них. В настоящее время это наиболее перспективный инструмент для бизнеса, основанный на искусственном интеллекте. Системы машинного обучения позволяют быстро применять знания, полученные при обучении на больших наборах данных, что позволяет им преуспевать в таких задачах, как распознавание лиц, распознавание речи, распознавание объектов, перевод, и многих других. В отличие от программ с закодированными вручную инструкциями для выполнения конкретных задач, машинное обучение позволяет системе научиться самостоятельно распознавать шаблоны и делать прогнозы.
 С другой стороны, DeepMind является примером машинного обучения: программа обыграла чемпиона мира по Го, обучая себя на большом наборе данных ходов, сделанных опытными игроками.
С другой стороны, DeepMind является примером машинного обучения: программа обыграла чемпиона мира по Го, обучая себя на большом наборе данных ходов, сделанных опытными игроками.Заинтересован ли Ваш бизнес в интеграции машинного обучения в свою стратегию? Amazon, Baidu, Google, IBM, Microsoft и другие уже предлагают платформы машинного обучения, которые могут использовать предприятия.
Глубокое обучение
Глубокое обучение является подмножеством машинного обучения. Оно использует некоторые методы машинного обучения для решения реальных задач, используя нейронные сетей, которые могут имитировать человеческое принятие решений. Глубокое обучение может быть дорогостоящим и требует огромных массивов данных для обучения. Это объясняется тем, что существует огромное количество параметров, которые необходимо настроить для алгоритмов обучения, чтобы избежать ложных срабатываний. Например, алгоритму глубокого обучения может быть дано указание «узнать», как выглядит кошка. Чтобы произвести обучение, потребуется огромное количество изображений для того, чтобы научиться различать мельчайшие детали, которые позволяют отличить кошку от, скажем, гепарда или пантеры, или лисицы.

Как уже упоминалось выше, в марте 2016 года искусственным интеллектом была достигнута крупная победа, когда программа AlphaGo DeepMind обыграла чемпиона мира по Го Ли Седоля в 4 из 5 игр с использованием глубокого обучения. Как объясняют в Google, система глубокого обучения работала путем комбинирования «метода Монте-Карло для поиска в дереве с глубокими нейронными сетями, которые прошли обучение с учителем на играх профессионалов и обучения с подкреплением на играх с собой».
Глубокое обучение также имеет бизнес-приложения. Можно взять огромное количество данных — миллионы изображений, и с их помощью выявить определенные характеристики. Текстовый поиск, обнаружение мошенничества, обнаружения спама, распознавание рукописного ввода, поиск изображений, распознавание речи, перевод — все эти задачи могут быть выполнены с помощью глубокого обучения. Например, в Google сети глубокого обучения заменили много «систем, основанных на правилах и требующих ручной работы».
Стоит отметить, что глубокое обучение может быть весьма «предвзятым».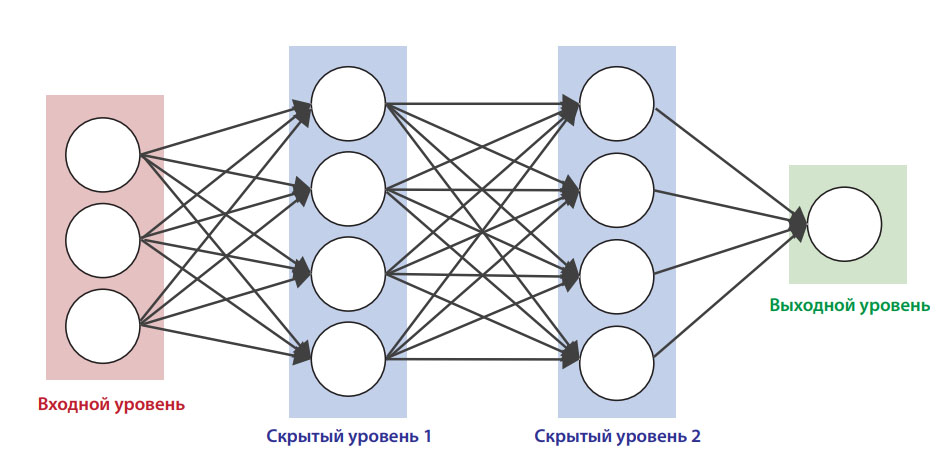
Существует мнение, что тема глубокого обучения сильно раздута. Система Sundown AI, например, предоставляет автоматизированные взаимодействия с клиентами с использованием комбинации машинного обучения и policy graph алгоритмов без использования глубокого обучения.
Оригинал статьи — «Understanding the differences between AI, machine learning, and deep learning».
Искусственный интеллект, нейронные сети и машинное обучение
Искусственный интеллект (ИИ) сейчас на волне хайпа и, в отличие от блокчейна, падения интереса к теме пока не наблюдается. Это значит, что нас продолжат бомбардировать удивительными сообщениями из мира ИИ – то вселять надежду на скорое всеобщее благоденствие, то пугать апокалипсисом восстания машин в духе Терминатора. Чем отличается нейросеть от искусственного интеллекта и как же разобраться: где маркетинговая чепуха, а где настоящие достижения и реальные угрозы?
Это значит, что нас продолжат бомбардировать удивительными сообщениями из мира ИИ – то вселять надежду на скорое всеобщее благоденствие, то пугать апокалипсисом восстания машин в духе Терминатора. Чем отличается нейросеть от искусственного интеллекта и как же разобраться: где маркетинговая чепуха, а где настоящие достижения и реальные угрозы?
Если вы попробуете самостоятельно разобраться и для начала откроете Википедию на статье, например, про перцептрон, то скорее всего вас ждет разочарование – вроде и по-русски написано, но ничего не понятно! Если только вам не повезло изучать математику в университете, но тогда и заметка вам не нужна.
Тем не менее, опираясь на здравый смысл, даже из беглого просмотра статей по ИИ в Википедии один полезный вывод можно сделать сразу. Искусственный интеллект и нейронные сети, однослойные и многослойные, сверточные и рекуррентные, обучение с учителем и без, глубокое и неглубокое – это все чертовски сложно! Значит, должно быть очень мало людей, которые действительно разбираются в предмете, и еще меньше тех, кто может применить математические абстракции на практике.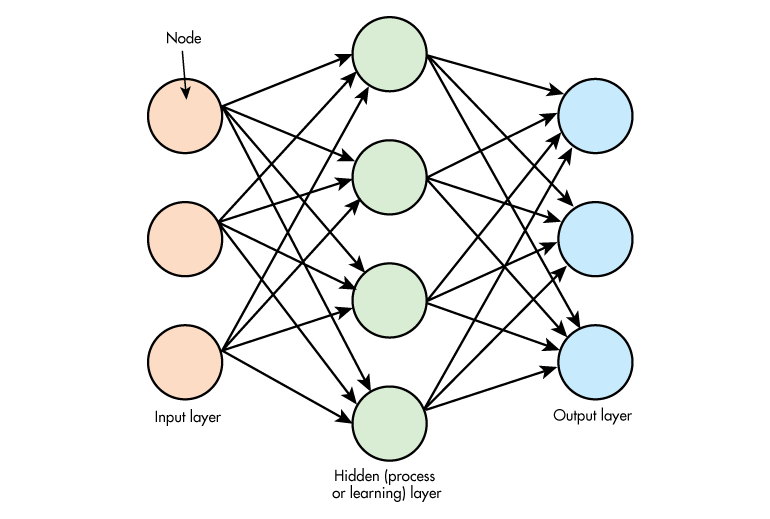
Нейросеть и искусственный интеллект: разница есть, или это одно и то же?
Строго говоря, есть. Существует множество концепций и попыток реализации ИИ. Термин artificial intelligence (AI) был впервые предложен в 1956 году в Стэнфорде и относится к широкой области научных исследований по созданию разумных машин. Первый «подход к снаряду» по созданию искусственного интеллекта на основе нейронных сетей в 70-80-х годах XX века потерпел фиаско, в основном из-за недостаточности вычислительных мощностей. С тех пор попытки не прекращаются, но о полном успехе говорить рано.
Нейросеть – это не искусственный интеллект, но сейчас именно они захватили всеобщее внимание.
Машинное обучение и нейронные сети: разница в контексте маркетинга неочевидна
Когда кто-то загадочным тоном произносит слова «machine learning», то он имеет в виду обучение нейронной сети на основе статистической выборки, то есть, слова «нейросеть» и «машинное обучение» в маркетинговом контексте можно считать синонимами.
Методов обучения и архитектур сетей разработано огромное количество, так что неспециалисту оценить преимущества того или иного подхода нет никакой возможности. Как же быть? Бизнесу следует держать в уме, что не все нейросети одинаково полезны для решения конкретных задач, поэтому к выбору партнера надо подходить очень тщательно – так же, как к выбору стоматолога, а то потом обойдется себе дороже.
А что же тогда deep learning? Глубокое обучение – это разновидность машинного обучения, причем четкой границы между ними не существует.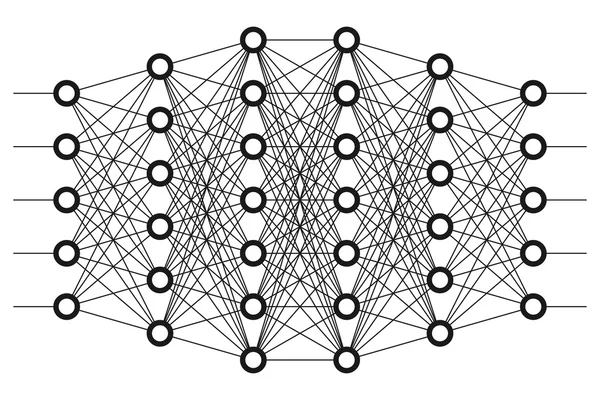 Пишут, что глубокое обучение имитирует абстрактное мышление человека. Чушь, не верьте. Ибо механизм мышления достоверно не изучен. Никакой магии в глубоком обучении нет, работает просто статистика – но действительно, не всегда понятно, как обученная нейросеть приходит к своим выводам. И еще не факт, что все ее решения правильные.
Пишут, что глубокое обучение имитирует абстрактное мышление человека. Чушь, не верьте. Ибо механизм мышления достоверно не изучен. Никакой магии в глубоком обучении нет, работает просто статистика – но действительно, не всегда понятно, как обученная нейросеть приходит к своим выводам. И еще не факт, что все ее решения правильные.
О терминологии: «глубокое» или «глубинное»?
Говорит профессор ВШЭ, Константин Воронцов, один из настоящих экспертов в области ИИ: «Я считаю, что слово “глубинное” имеет в русском языке другой смысл: глубинным бывает залегание нефти, бомбометание, отложение и т. д. “Глубокое” – это более математичный термин, потому что суперпозиция функций может быть глубокой, но не глубинной, а нейронная сеть – это именно суперпозиция функций». Так что не путайте, говорите правильно!
Кстати, по-русски было бы логичнее говорить «обучение машин», что передает суть процесса – обучение нейросети. Но прижилось странное словосочетание «машинное обучение». Чем непонятнее, тем дороже.
Для наглядности вышесказанное можно представить в виде картинки: сначала возникло широкое научное направление «искусственный интеллект», потом внутри него появились искусственные нейронные сети (ИНС), которые ассоциировались с термином «машинное обучение». Как частный случай можно рассматривать нейронные сети глубокого обучения.
Котик или собачка? Применение сверточных нейросетей для компьютерного зрения
Компьютер Deep Blue стоимостью в $10 млн, в котором было 480 специализированных шахматных процессоров и 30 обычных, обыграл чемпиона мира Каспарова еще в 1997 году. Но простая задача, с которой справляется маленький ребенок, – отличить котика от собачки – долго была машинам не под силу. Пока на сцену не вышли сверточные нейронные сети.
Дело, конечно, не в котиках – хотя по количеству публикаций на эту тему может сложиться мнение, что распознавание котиков и есть главная задача современной науки. На самом деле программисты и математики решали проблему компьютерного зрения, чтобы научить машины «видеть» с помощью нейронных сетей.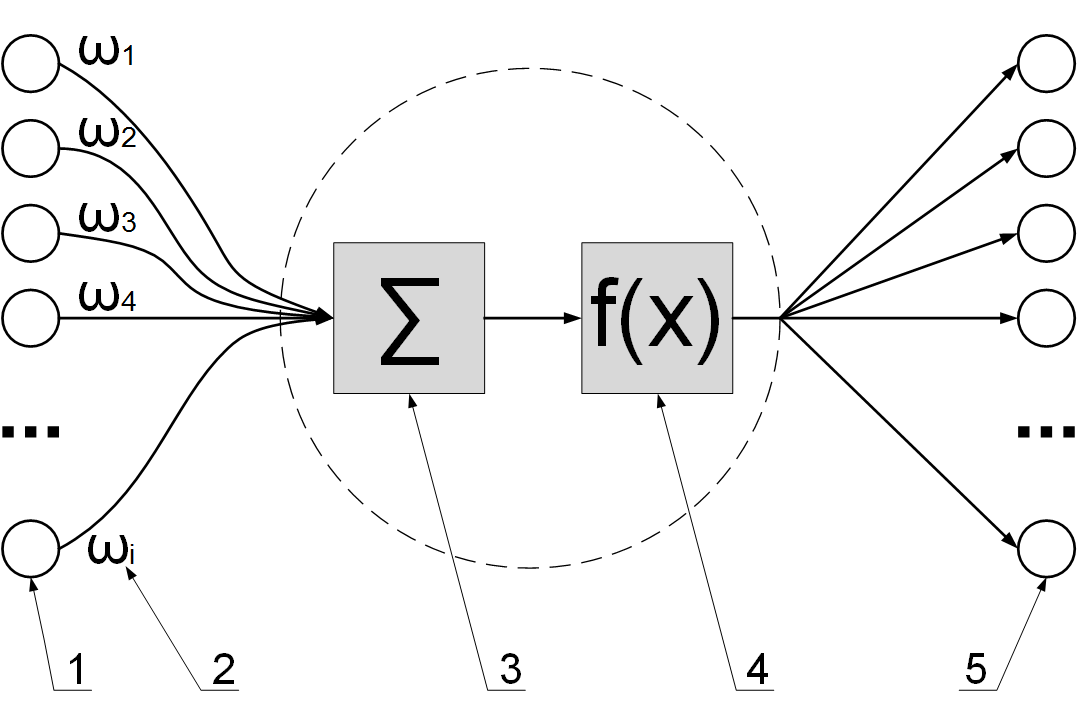 Это нужно в робототехнике, беспилотных автомобилях, медицинской диагностике, системах безопасности и много еще где. А котики – ну просто так повелось, это был один из первых примеров на распознавание образов.
Это нужно в робототехнике, беспилотных автомобилях, медицинской диагностике, системах безопасности и много еще где. А котики – ну просто так повелось, это был один из первых примеров на распознавание образов.
Нейронные сети, или Как обучить искусственный интеллект — Интернет изнутри
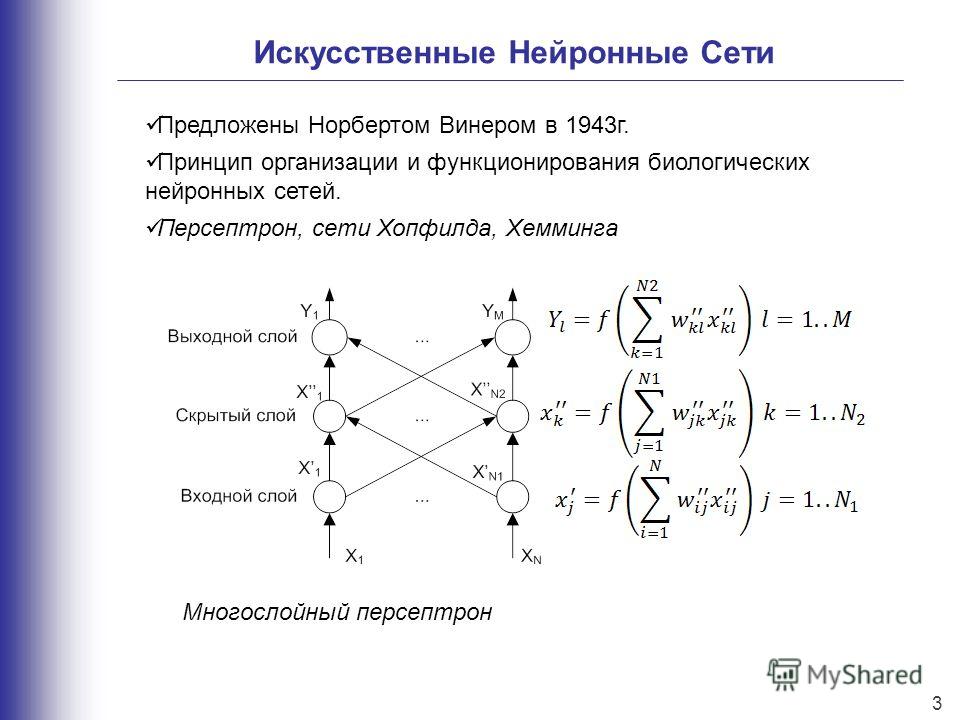
Машинное обучение является не единственным, но одним из фундаментальных разделов искусственного интеллекта, занимающимся вопросами самостоятельного извлечения знаний интеллектуальной системой в процессе ее работы. Основу машинного обучения составляют так называемые искусственные нейронные сети, принцип работы которых напоминает работу биологических нейронов нервной системы животных и человека.
Технологии искусственного интеллекта все активнее используются в самых различных областях – от производственных процессов до финансовой деятельности. Популярные услуги техгигантов, такие как «Яндекс.Алиса», Google Translate, Google Photos и Google Image Search (AlexNet, GoogleNet) основаны на работе нейронных сетей.
Что такое нейронные сети и как они работают – об этом пойдет речь в статье.
Введение
У искусственного интеллекта множество определений. Под этим термином понимается, например, научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования тех видов человеческой деятельности, которые традиционно считаются творческими или интеллектуальными, а также соответствующий раздел информатики, задачей которого является воссоздание с помощью вычислительных систем и иных искусственных устройств разумных рассуждений и действий, равно как и свойство систем выполнять «творческие» функции. Искусственный интеллект уже сегодня прочно вошел в нашу жизнь, он используется так или иначе во многих вещах, которые нас окружают: от смартфонов до холодильников, — и сферах деятельности: компании многих направлений, от IT и банков до тяжелого производства, стремятся использовать последние разработки для
повышения эффективности. Данная тенденция будет лишь усиливаться в будущем.
Машинное обучение является не единственным, но одним из основных разделов, фундаментом искусственного интеллекта, занимающимся вопросами самостоятельного извлечения знаний интеллектуальной системой в процессе ее работы. Зародилось это направление еще в середине XX века, однако резко возросший интерес направление получило с существенным развитием области математики, специализирующейся на нейронных сетях, после недавнего изобретения эффективных алгоритмов обучения таких сетей. Идея создания искусственных нейронных сетей была перенята у природы. В качестве примера и аналога была использована нервная система как животного, так и человека. Принцип работы искусственной нейронной сети соответствует алгоритму работы биологических нейронов.
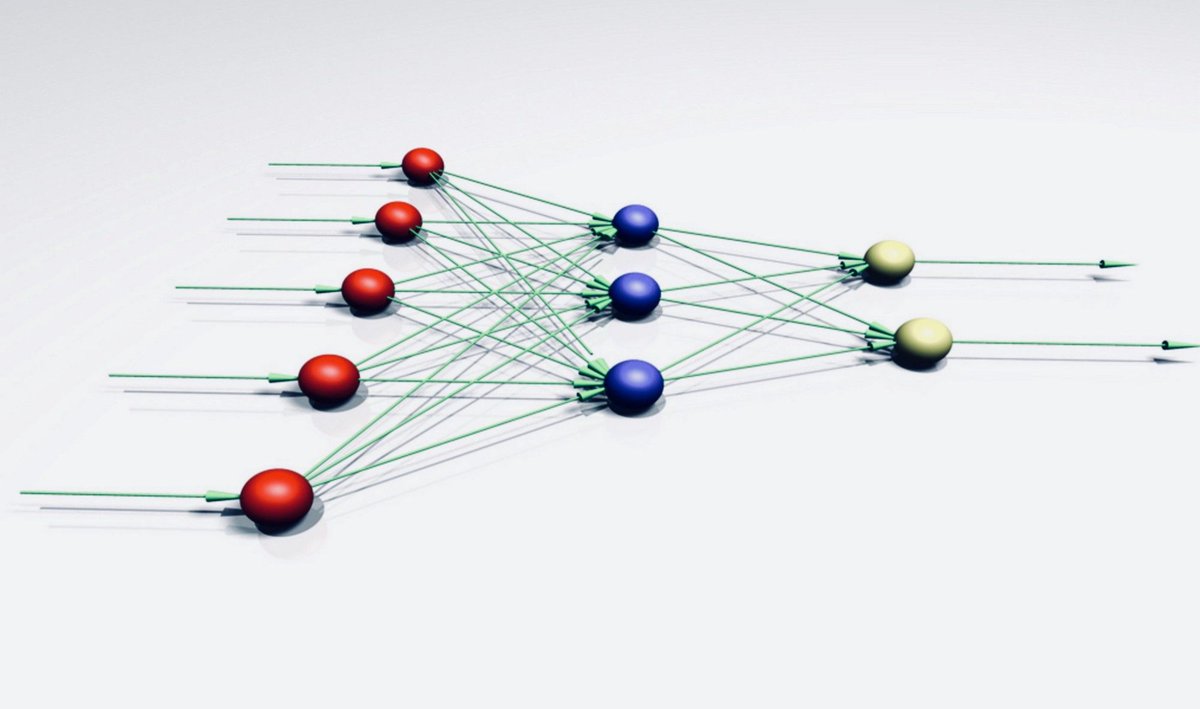
Нейрон – вычислительная единица, получающая информацию и производящая над этой информацией какие-либо вычисления. Нейроны являются простейшей структурной единицей любой нейронной сети, из их множества, упорядоченного некоторым образом в слои, а в конечном счете – во всю сеть, состоят все сети.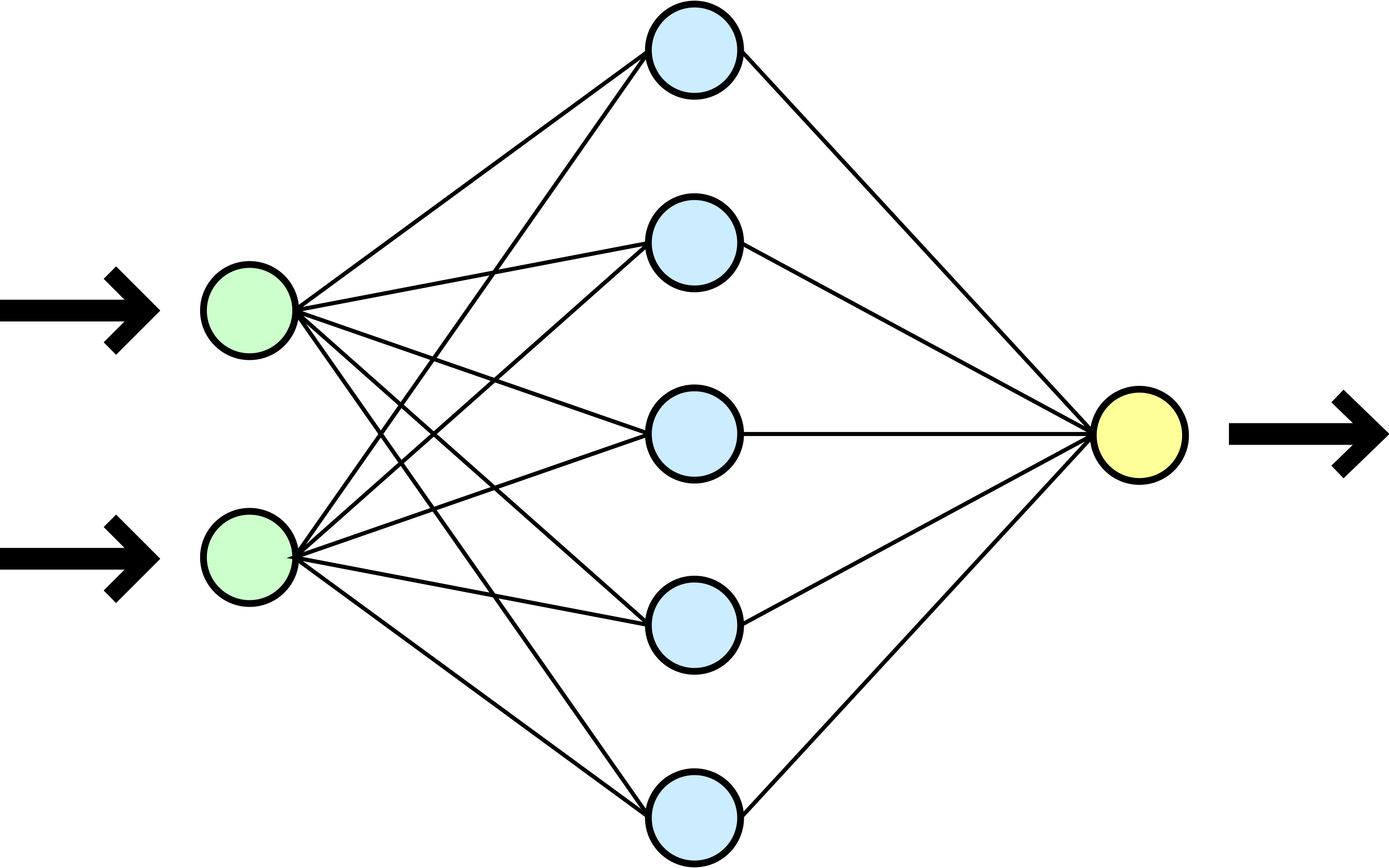 Все нейроны функционируют примерно одинаковым образом, однако бывают некоторые частные случаи нейронов, выполняющих специфические функции. Три основных типа нейронов:
Все нейроны функционируют примерно одинаковым образом, однако бывают некоторые частные случаи нейронов, выполняющих специфические функции. Три основных типа нейронов:
Входной – слой нейронов, получающий информацию (синий цвет на рис. 1).
Скрытый – некоторое количество слоев, обрабатывающих информацию (красный цвет на рис. 1).
Выходной – слой нейронов, представляющий результаты вычислений (зеленый цвет на рис. 1).
Помимо самих нейронов существуют синапсы. Синапс – связь, соединяющая выход одного нейрона со входом другого. Во время прохождения сигнала через синапс сигнал может усиливаться или ослабевать. Параметром синапса является вес (некоторый коэффициент, может быть любым вещественным числом), из-за которого информация, передающаяся от одного нейрона к другому, может изменяться. При помощи весов входная информация проходит обработку — и после мы получаем результат.
Рис. 2. Модель искусственного нейрона.На рис. 2 изображена математическая модель нейрона. На вход подаются числа (сигналы), после они умножаются на веса (каждый сигнал – на свой вес) и суммируются. Функция активации высчитывает выходной сигнал и подает его на выход.
На вход подаются числа (сигналы), после они умножаются на веса (каждый сигнал – на свой вес) и суммируются. Функция активации высчитывает выходной сигнал и подает его на выход.
Сама идея функции активации также взята из биологии. Представьте себе ситуацию: вы подошли и положили палец на конфорку варочной панели. В зависимости от сигнала, который при этом поступит от пальца по нервным окончаниям в мозг, в нейронах вашего мозга будет принято решение: пропускать ли сигнал дальше по нейронным связям, давая посыл мышцам отдернуть палец от горячей конфорки, или не пропускать сигнал, если конфорка холодная и палец можно оставить. Математический аналог функции активации имеет то же назначение. Таким образом, функция активации позволяет проходить или не проходить сигналам от нейрона к нейронам в зависимости от информации, которую они передают. Т.е. если информация является важной, то функция пропускает ее, а если информации мало или она недостоверна, то функция активации не позволяет ей пройти дальше.
В таблице 1 представлены некоторые виды активационных функций нейрона. Простейшей разновидностью функции активации является пороговая. Как следует из названия, ее график представляет из себя ступеньку. Например, если поступивший в нейрон суммарный сигнал от предыдущих нейронов меньше 0, то в результате применения функции активации сигнал полностью «тормозится» и дальше не проходит, т.е. на выход данного нейрона (и, соответственно, входы последующих нейронов) подается 0. Если же сигнал >= 0, то на выход данного нейрона подается 1.
Функция активации должна быть одинаковой для всех нейронов внутри одного слоя, однако для разных слоев могут выбираться разные функции активации. В искусственных нейронных сетях выбор функции обуславливается областью применения и является важной исследовательской задачей для специалиста по машинному обучению.
Нейронные сети набирают все большую популярность и область их использования также расширяется. Список некоторых областей, где применяются искусственные нейронные сети:
Список некоторых областей, где применяются искусственные нейронные сети:
- Ввод и обработка информации. Распознавание текстов на фотографиях и различных документах, распознавание голосовых команд, голосовой ввод текста.
- Безопасность. Распознавание лиц и различных биометрических данных, анализ трафика в сети, обнаружение подделок.
- Интернет. Таргетинговая реклама, капча, составление новостных лент, блокировка спама, ассоциативный поиск информации.
- Связь. Маршрутизация пакетов, сжатие видеоинформации, увеличение скорости кодирования и декодирования информации.
Помимо перечисленных областей, нейронные сети применяются в робототехнике, компьютерных и настольных играх, авионике, медицине, экономике, бизнесе и в различных политических и социальных технологиях, финансово-экономическом анализе.
Архитектуры нейронных сетей
Архитектур нейронных сетей большое количество, и со временем появляются новые. Рассмотрим наиболее часто встречающиеся базовые архитектуры.
Персептрон
Рис. 3. Пример архитектуры персептрона.Персептрон – это простейшая модель нейросети, состоящая из одного нейрона. Нейрон может иметь произвольное количество входов (на рис. 3 изображен пример вида персептрона с четырьмя входами), а один из них обычно тождественно равен 1. Этот единичный вход называют смещением, его использование иногда бывает очень удобным. Каждый вход имеет свой собственный вес. При поступлении сигнала в нейрон, как и было описано выше, вычисляется взвешенная сумма сигналов, затем к сигналу применяется функция активации и сигнал передается на выход. Такая
простая на первый взгляд сеть, всего из одного-единственного нейрона, способна, тем не менее, решать ряд задач: выполнять простейший прогноз, регрессию данных и т.п., а также моделировать поведение несложных функций. Главное для эффективности работы этой сети – линейная разделимость данных.
Для читателей, немного знакомых с таким разделом как логика, будут знакомы логическое И (умножение) и логическое ИЛИ (сложение).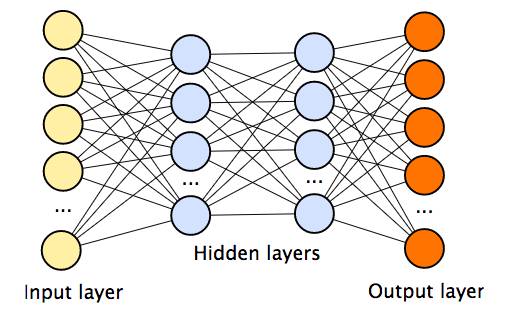 Это булевы функции, принимающие значение, равное 0, всегда, кроме одного случая, для умножения, и, наоборот, значения, равные 1, всегда, кроме одного случая, для сложения. Для таких функций всегда можно провести прямую (или гиперплоскость в многомерном пространстве), отделяющие 0 значения от 1. Это и называют линейной разделимостью объектов. Тогда подобная модель сможет решить поставленную задачу классификации и сформировать базовый логический элемент. Если же объекты линейно неразделимы, то сеть из одного нейрона с ними не справится. Для этого существуют более сложные архитектуры нейронных сетей, в конечном счете, тем не менее, состоящие из множества таких персептронов, объединенных в слои.
Это булевы функции, принимающие значение, равное 0, всегда, кроме одного случая, для умножения, и, наоборот, значения, равные 1, всегда, кроме одного случая, для сложения. Для таких функций всегда можно провести прямую (или гиперплоскость в многомерном пространстве), отделяющие 0 значения от 1. Это и называют линейной разделимостью объектов. Тогда подобная модель сможет решить поставленную задачу классификации и сформировать базовый логический элемент. Если же объекты линейно неразделимы, то сеть из одного нейрона с ними не справится. Для этого существуют более сложные архитектуры нейронных сетей, в конечном счете, тем не менее, состоящие из множества таких персептронов, объединенных в слои.
Многослойный персептрон
Слоем называют объединение нейронов, на схемах, как правило, слои изображаются в виде одного вертикального ряда (в некоторых случаях схему могут поворачивать, и тогда ряд будет горизонтальным). Многослойный персептрон является обобщением однослойного персептрона. Он состоит из некоторого множества входных узлов, нескольких скрытых слоев вычислительных
Он состоит из некоторого множества входных узлов, нескольких скрытых слоев вычислительных
нейронов и выходного слоя (см. рис. 4).
Отличительные признаки многослойного персептрона:
- Все нейроны обладают нелинейной функцией активации, которая является дифференцируемой.
- Сеть достигает высокой степени связности при помощи синаптических соединений.
- Сеть имеет один или несколько скрытых слоев.
Такие многослойные сети еще называют глубокими. Эта сеть нужна для решения задач, с которыми не может справиться персептрон. В частности, линейно неразделимых задач. В действительности, как следствие из теоремы Колмогорова, именно многослойный персептрон является единственной универсальной нейронной сетью, универсальным аппроксиматором, способным решить любую задачу. Возможно, не самым эффективным способом, который могли бы обеспечить более узкопрофильные нейросети, но все же решить.
Именно поэтому, если исследователь не уверен, нейросеть какого вида подходит для решения стоящей перед ним задачи, он выбирает сначала многослойный персептрон.
Сверточная нейронная сеть (convolution neural network)
Сверточная нейронная сеть – сеть, которая обрабатывает передаваемые данные не целиком, а фрагментами. Данные последовательно обрабатываются, а после передаются дальше по слоям. Сверточные нейронные сети состоят из нескольких типов слоев: сверточный слой, субдискретизирующий слой, слой полносвязной сети (когда каждый нейрон одного слоя связан с каждым нейроном следующего – полная связь). Слои свертки и подвыборки (субдискретизации) чередуются и их набор может повторяться несколько раз (см. рис. 5). К конечным слоям часто добавляют персептроны, которые служат для последующей обработки данных.
Рис. 5. Архитектура сверточной нейронной сети.Название архитектура сети получила из-за наличия операции свёртки, суть которой в том, что каждый фрагмент изображения умножается на матрицу (ядро) свёртки поэлементно, а результат суммируется и записывается в аналогичную позицию выходного изображения. Необходимо это для перехода от конкретных особенностей изображения к более абстрактным деталям, и далее – к
ещё более абстрактным, вплоть до выделения понятий высокого уровня (присутствует ли что-либо искомое на изображении).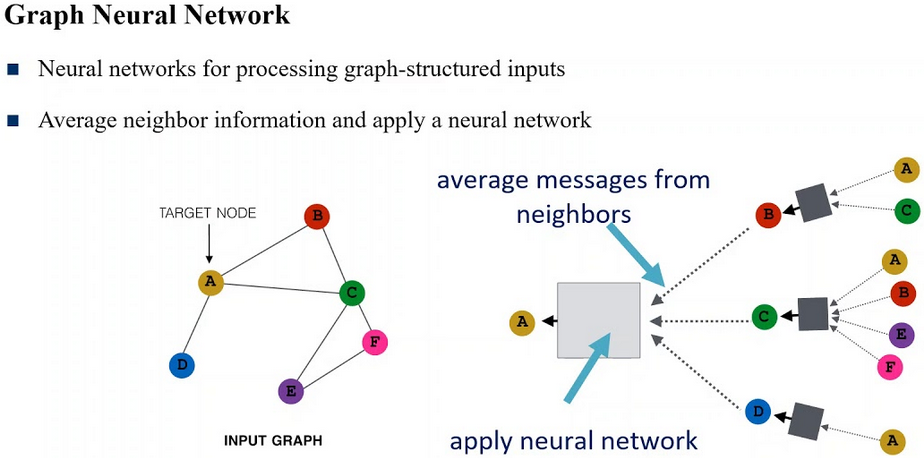
Сверточные нейронные сети решают следующие задачи:
- Классификация. Пример: нейронная сеть определяет, что или кто находится на изображении.
- Детекция. Пример: нейронная сеть определяет, что/кто и где находится на изображении.
- Сегментация. Пример: нейронная сеть может определить каждый пиксель изображения и понять, к чему он относится.
Описанные сети относятся к сетям прямого распространения. Наряду с ними существуют нейронные сети, архитектуры которых имеют в своем составе связи, по которым сигнал распространяется в обратную сторону.
Рекуррентная нейронная сеть
Рекуррентная нейронная сеть – сеть, соединения между нейронами которой образуют ориентированный цикл. Т.е. в сети имеются обратные связи. При этом информация к нейронам может передаваться как с предыдущих слоев, так и от самих себя с предыдущей итерации (задержка). Пример схемы первой рекуррентной нейронной сети (НС Хопфилда) представлен на рис. 6.
Рис. 6. Архитектура рекуррентной нейронной сети.
6. Архитектура рекуррентной нейронной сети.Характеристики сети:
- Каждое соединение имеет свой вес, который также является приоритетом.
- Узлы подразделяются на два типа: вводные (слева) и скрытые (1, 2, … K).
- Информация, находящаяся в нейронной сети, может передаваться как по прямой, слой за слоем, так и между нейронами.
Такие сети еще называют «памятью» (в случае сети Хопфилда – автоассоциативной; бывают также гетероассоциативные (сеть Коско – развитие сети Хопфилда) и другие). Почему? Если подать данной сети на вход некие «образцы» – последовательности кодов (к примеру, 1000001, 0111110 и 0110110) — и обучить ее на запоминание этих образцов, настроив веса синапсов сети определенным образом при помощи правила Хебба3, то затем, в процессе функционирования, сеть сможет «узнавать» запомненные образы и выдавать их на выход, в том числе исправляя искаженные поданные на вход образы. К примеру, если после обучения такой сети я подам на вход 1001001, то сеть узнает и исправит запомненный образец, выдав на выходе 1000001. Правда, эта нейронная сеть не толерантна к поворотам и сдвигам образов, и все же для первой нейронной сети своего класса сеть весьма интересна.
Правда, эта нейронная сеть не толерантна к поворотам и сдвигам образов, и все же для первой нейронной сети своего класса сеть весьма интересна.
Таким образом, особенность рекуррентной нейронной сети состоит в том, что она имеет «области внимания». Данная область позволяет задавать фрагменты передаваемых данных, которым требуется усиленная обработка.
Информация в рекуррентных сетях со временем теряется со скоростью, зависящей от активационных функций. Данные сети на сегодняшний день нашли свое применение в распознавании и обработке текстовых данных. Об этом речь пойдет далее.
Самоорганизующаяся нейронная сеть
Пример самоорганизующейся нейронной сети – сеть Кохонена. В процессе обучения осуществляется адаптация сети к поставленной задаче. В представленной сети (см. рис. 7) сигнал идет от входа к выходу в прямом направлении. Структура сети имеет один слой нейронов, которые не имеют коэффициентов смещения (тождественно единичных входов). Процесс обучения сети происходит при помощи метода последовательных приближений.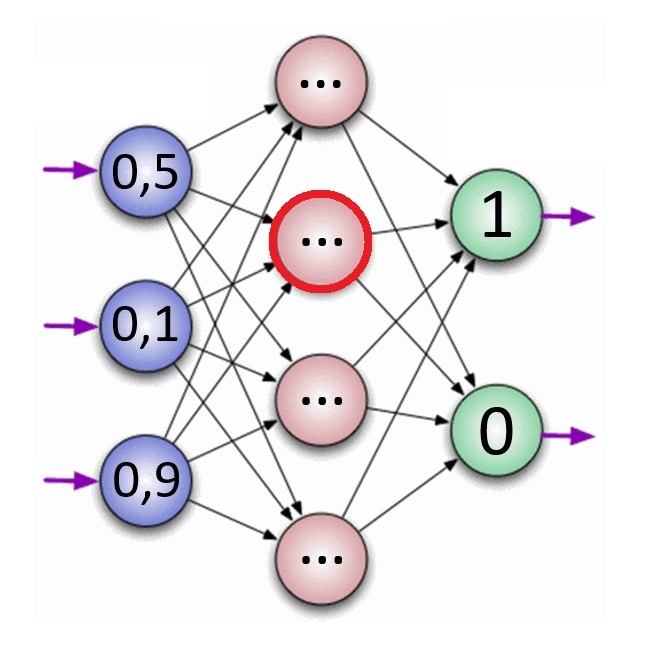 Нейронная сеть подстраивается под закономерности входных данных, а не под лучшее значение на выходе. В результате обучения сеть находит окрестность, в которой находится лучший нейрон. Сеть функционирует по принципу «победитель получает все»: этот самый лучший нейрон в итоге на выходе будет иметь 1, а остальные нейроны, сигнал на которых получился меньше, 0. Визуализировать это можно так: представьте, что правый ряд нейронов, выходной, на
Нейронная сеть подстраивается под закономерности входных данных, а не под лучшее значение на выходе. В результате обучения сеть находит окрестность, в которой находится лучший нейрон. Сеть функционирует по принципу «победитель получает все»: этот самый лучший нейрон в итоге на выходе будет иметь 1, а остальные нейроны, сигнал на которых получился меньше, 0. Визуализировать это можно так: представьте, что правый ряд нейронов, выходной, на
рис. 7 – это лампочки. Тогда после подачи на вход сети данных после их обработки на выходе «зажжется» только одна лампочка, указывающая, куда относится поданный объект. Именно поэтому такие сети часто используются в задачах кластеризации и классификации.
Алгоритмы обучения нейронных сетей
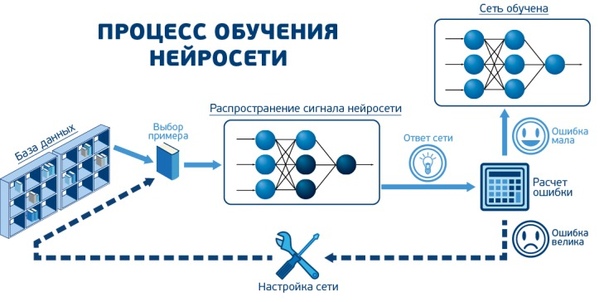
Чтобы получить решение поставленной задачи с использованием нейронной сети, вначале требуется сеть обучить (рис. 8). Процесс обучения сети заключается в настройке весовых коэффициентов связей между нейронами.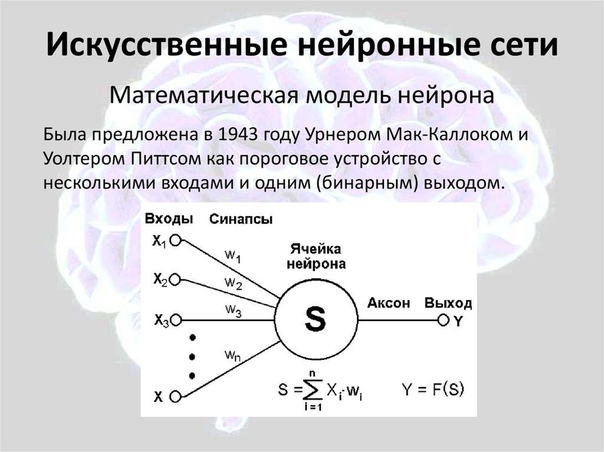
Алгоритмы обучения для нейронной сети бывают с
учителем и без.
- С учителем: предоставление нейронной сети некоторой выборки обучающих примеров. Образец подается на вход, после происходит обработка внутри нейронной сети и рассчитывается выходной сигнал, сравнивающийся с соответствующим значением целевого вектора (известным нам «правильным ответом» для каждого из обучающих примеров). Если ответ сети не совпадает с требуемым, производится коррекция весов сети, напрямую зависящая от того, насколько отличается ответ сети от правильного (ошибка). Правило этой коррекции называется правилом Видроу-Хоффа и является прямой пропорциональностью коррекции каждого веса и размера ошибки, производной функции активации и входного сигнала нейрона. Именно после изобретения и доработок алгоритма распространения этой ошибки на все нейроны скрытых слоев глубоких нейронных сетей эта область искусственного интеллекта вернула к себе интерес.
- Без учителя: алгоритм подготавливает веса сети таким образом, чтобы можно было получить согласованные выходные векторы, т.е. предоставление достаточно близких векторов будет давать похожие выходы. Одним из таких алгоритмов обучения является правило Хебба, по которому настраивается перед работой матрица весов, например, рекуррентной сети Хопфилда.
Рассмотрим теперь, какие архитектуры сетей являются наиболее востребованными сейчас, каковы особенности использования нейросетей на примерах известных крупных проектов.
Рекуррентные сети на примерах Google и «Яндекса»
Уже упоминавшаяся выше рекуррентная нейронная сеть (RNN) – сеть, которая обладает кратковременной «памятью», из-за чего может быстро производить анализ последовательностей различной длины. RNN разбивает потоки данных на части и производит оценку связей между ними.
Сеть долговременной краткосрочной памяти (Long shortterm memory – LSTM) – сеть, которая появилась в результате развития RNN-сетей. Это интересная модификация RNN-сетей, позволяющая сети не просто «держать контекст», но и умеющая «видеть» долговременные зависимости. Поэтому LSTM подходит для прогнозирования различных изменений при помощи экстраполяции (выявление тенденции на основе данных), а также в любых задачах, где важно умение «держать контекст», особенно хорошо подвластное для данной нейросети.
Это интересная модификация RNN-сетей, позволяющая сети не просто «держать контекст», но и умеющая «видеть» долговременные зависимости. Поэтому LSTM подходит для прогнозирования различных изменений при помощи экстраполяции (выявление тенденции на основе данных), а также в любых задачах, где важно умение «держать контекст», особенно хорошо подвластное для данной нейросети.
Форма рекуррентных нейронных сетей представляет собой несколько повторяющихся модулей. В стандартном виде эти модули имеют простую структуру. На рисунке 9 изображена сеть, которая имеет в одном из слоев гиперболический тангенс в качестве функции активации.
Рис. 10. Модуль LSTM-сети.
LSTM также имеет цепочечную структуру. Отличие состоит в том, что сеть имеет четыре слоя, а не один (рис. 10). Главным отличием LSTM-сети является ее клеточное состояние (или состояние ячейки), которое обозначается горизонтальной линией в верхней части диаграммы и по которой проходит информация (рис.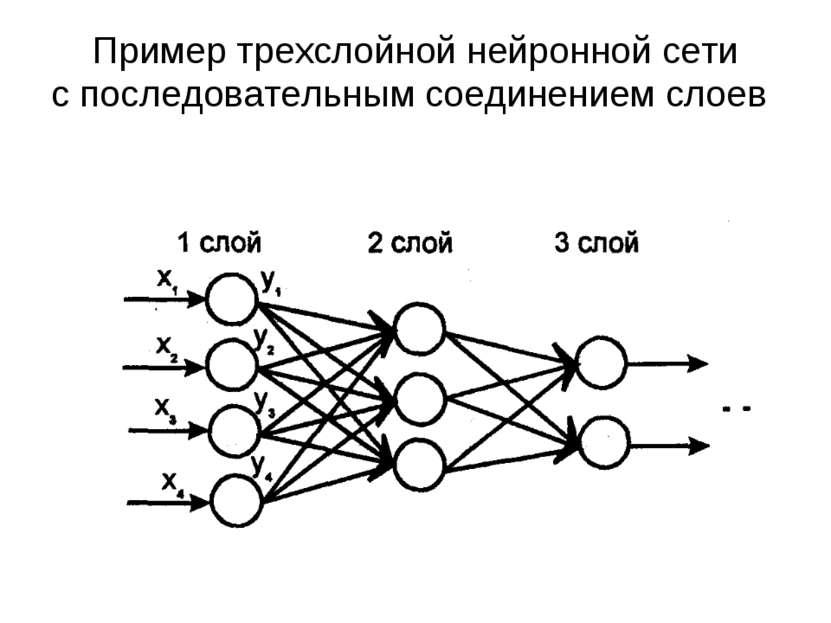 11). Это самое состояние ячейки напоминает ленту конвейера: она проходит напрямую через всю цепочку, участвуя в некоторых преобразованиях. Информация может как «течь» по ней, не подвергаясь изменениям, так и быть подвергнута преобразованиям со стороны нейросети7. (Представьте себе линию контроля на конвейере: изделия продвигаются на ленте перед сотрудником контроля, который лишь наблюдает за ними, но если ему что-то покажется важным или подозрительным, он может вмешаться).
11). Это самое состояние ячейки напоминает ленту конвейера: она проходит напрямую через всю цепочку, участвуя в некоторых преобразованиях. Информация может как «течь» по ней, не подвергаясь изменениям, так и быть подвергнута преобразованиям со стороны нейросети7. (Представьте себе линию контроля на конвейере: изделия продвигаются на ленте перед сотрудником контроля, который лишь наблюдает за ними, но если ему что-то покажется важным или подозрительным, он может вмешаться).
LSTM имеет способность удалять или добавлять информацию к клеточному состоянию. Данная способность осуществляется при помощи вентилей, которые регулируют процессы взаимодействия с информацией. Вентиль – возможность выборочно пропускать информацию. Он состоит из сигмоидного слоя нейронной сети и операции поточечного умножения (рис. 12).
Рис. 12. Вентиль.Сигмоидный слой (нейроны с сигмоидальной функцией активации) подает на выход числа между нулем и единицей, описывая таким образом, насколько каждый компонент должен быть пропущен сквозь вентиль. Ноль – «не пропускать вовсе», один – «пропустить все». Таких «фильтров» в LSTM-сети несколько. Для чего сети нужна эта способность: решать, что важно, а что нет? Представьте себе следующее: сеть переводит предложение и в какой-то момент ей предстоит перевести с английского языка на русский, скажем, местоимение, прилагательное или причастие. Для этого сети необходимо, как минимум, помнить род и/или число предыдущего существительного, к которому переводимое слово относится. Однако как только мы встретим новое существительное, род предыдущего можно забыть. Конечно, это очень упрощенный пример, тем не
Ноль – «не пропускать вовсе», один – «пропустить все». Таких «фильтров» в LSTM-сети несколько. Для чего сети нужна эта способность: решать, что важно, а что нет? Представьте себе следующее: сеть переводит предложение и в какой-то момент ей предстоит перевести с английского языка на русский, скажем, местоимение, прилагательное или причастие. Для этого сети необходимо, как минимум, помнить род и/или число предыдущего существительного, к которому переводимое слово относится. Однако как только мы встретим новое существительное, род предыдущего можно забыть. Конечно, это очень упрощенный пример, тем не
менее, он позволяет понять трудность принятия решения: какая информация еще важна, а какую уже можно забыть. Иначе говоря, сети нужно решить, какая информация будет храниться в состоянии ячейки, а затем – что на выходе из нее будет выводить.
Примеры использования нейронных сетей
Мы рассмотрели основные типы нейронных систем и познакомились с принципами их работы. Остановимся теперь на их практическом применении в системах Google Translate, «Яндекс. Алиса», Google Photos и Google Image Search (AlexNet, GoogleNet).
Алиса», Google Photos и Google Image Search (AlexNet, GoogleNet).
LSTM в Google Translate
Google-переводчик в настоящее время основан на методах машинного обучения и использует принцип работы LSTM-сетей. Система производит вычисления, чтобы понять значение слова или фразы, основываясь на предыдущих значениях в последовательности (контексте). Такой алгоритм помогает системе понимать контекст предложения и верно подбирать перевод среди различных вариантов. Еще несколько лет назад Google Translate работал на основе статистического машинного перевода – это разновидность перевода, где перевод генерируется на основе статистических моделей (бывают: по словам, по фразам, по синтаксису и т.д.), а параметры этих моделей являются результатами анализа корпусов текстов двух выбранных для перевода языков. Эти статистические модели обладали большим быстродействием, однако их эффективность ниже. Общий прирост качества перевода после внедрения системы на основе нейросетей в Google-переводчик составил, казалось бы, не очень много – порядка 10%, однако для отдельных языковых пар эффективность перевода достигла 80-90%,
вплотную приблизившись к оценкам качества человеческого перевода. «Платой» за такое качество перевода является сложность построения, обучения и перенастройки системы на основе нейросети: она занимает недели. Вообще для современных глубоких нейронных сетей, использующихся в таких крупных проектах, в порядке вещей обучение, занимающее дни и недели.
«Платой» за такое качество перевода является сложность построения, обучения и перенастройки системы на основе нейросети: она занимает недели. Вообще для современных глубоких нейронных сетей, использующихся в таких крупных проектах, в порядке вещей обучение, занимающее дни и недели.
Рассмотрим LSTM-сеть переводчика (GNMT) подробнее. Нейронная сеть переводчика имеет разделение на два потока (см. рис. 13). Первый поток нейронной сети (слева) является анализирующим и состоит из восьми слоев. Данный поток помогает разбивать фразы или предложения на несколько смысловых частей, а после производит их анализ. Сеть позволяет читать предложения в двух направлениях, что помогает лучше понимать контекст. Также она занимается формированием модулей внимания, которые позволяют второму потоку определять ценности отдельно взятых смысловых фрагментов.
Второй поток нейронной сети (справа) является синтезирующим. Он позволяет вычислять самый подходящий вариант для перевода, основываясь на контексте и модулях внимания (показаны голубым цветом).
В системе нейронной сети самым маленьким элементом является фрагмент слова. Это позволяет сфокусировать вычислительную мощность на контексте предложения, что обеспечивает высокую скорость и точность переводчика. Также анализ фрагментов слова сокращает риски неточного перевода слов, которые имеют суффиксы, префиксы и окончания.
LSTM в «Яндекс.Алисе»
Компания «Яндекс» также использует нейросеть типа LSTM в продукте «Яндекс.Алиса». На рисунке 14 изображено взаимодействие пользователя с системой. После вопроса пользователя информация передается на сервер распознавания, где она преобразуется в текст. Затем текст поступает в классификатор интентов (интент (от англ. intent) – намерение, цель пользователя, которое он вкладывает в запрос), где при помощи машинного обучения анализируется. После анализа интентов они поступают на семантический теггер (tagger) – модель, которая позволяет выделить полезную и требующуюся информацию из предложения. Затем полученные результаты структурируются и передаются в модуль dialog manager, где обрабатывается полученная информация и генерируется ответ.
LSTM-сети применяются в семантическом теггере. В этом модуле используются двунаправленные LSTM с attention. На этом этапе генерируется не только самая вероятная гипотеза, потому что в зависимости от диалога могут потребоваться и другие. От состояния диалога в dialog manager происходит повторное взвешивание гипотез. Сети с долговременной памятью помогают лучше вести диалог с пользователем, потому что могут помнить предыдущие сообщения и более точно генерировать ответы, а также они помогают разрешать много проблемных ситуаций. В ходе диалога нейронная сеть может убирать слова, которые не несут никакой важной информации, а остальные анализировать и предоставлять ответ9. Для примера на рис. 14 результат работы системы будет следующим. Сначала речь пользователя в звуковом формате будет передана на сервер распознавания, который выполнит лексический анализ (т.е. переведет сказанное в текст и разобьет его на слова – лексемы), затем классификатор интентов выполнит уже роль семантического анализа (понимание смысла того, что было сказано; в данном случае – пользователя интересует погода), а семантический теггер выделит полезные элементы информации: теггер выдал бы, что завтра – это дата, на которую нужен прогноз погоды. В итоге данного анализа запроса пользователя будет составлено внутреннее представление запроса – фрейм, в котором будет указано, что интент – погода, что погода нужна на +1 день от текущего дня, а где – неизвестно. Этот фрейм попадет в диалоговый менеджер, который хранит тот самый контекст беседы и будет принимать на основе хранящегося контекста решение, что делать с этим запросом. Например, если до этого беседа не происходила, а для станции с «Яндекс.Алисой» указана геолокация г. Москва, то менеджер получит через специальный интерфейс (API) погоду на завтра в Москве, отправит команду на генерацию текста с этим прогнозом, после чего тот будет передан в синтезатор речи помощника. Если же Алиса до этого вела беседу с пользователем о достопримечательностях Парижа, то наиболее вероятно, что менеджер учтет это и либо уточнит у пользователя информацию о месте, либо сразу сообщит о погоде в Париже. Сам диалоговый менеджер работает на основе скриптов (сценариев обработки запросов) и правил, именуемых form-filling.
В итоге данного анализа запроса пользователя будет составлено внутреннее представление запроса – фрейм, в котором будет указано, что интент – погода, что погода нужна на +1 день от текущего дня, а где – неизвестно. Этот фрейм попадет в диалоговый менеджер, который хранит тот самый контекст беседы и будет принимать на основе хранящегося контекста решение, что делать с этим запросом. Например, если до этого беседа не происходила, а для станции с «Яндекс.Алисой» указана геолокация г. Москва, то менеджер получит через специальный интерфейс (API) погоду на завтра в Москве, отправит команду на генерацию текста с этим прогнозом, после чего тот будет передан в синтезатор речи помощника. Если же Алиса до этого вела беседу с пользователем о достопримечательностях Парижа, то наиболее вероятно, что менеджер учтет это и либо уточнит у пользователя информацию о месте, либо сразу сообщит о погоде в Париже. Сам диалоговый менеджер работает на основе скриптов (сценариев обработки запросов) и правил, именуемых form-filling. Вот такой непростой набор технических решений, методов, алгоритмов и систем кроется за фасадом, позволяющим пользователю спросить и узнать ответ на простой бытовой вопрос или команду.
Вот такой непростой набор технических решений, методов, алгоритмов и систем кроется за фасадом, позволяющим пользователю спросить и узнать ответ на простой бытовой вопрос или команду.
Свёрточные нейронные сети, используемые для классификации изображений, на примере Google Photos и Google Image Search
Задача классификации изображений – это получение на вход начального изображения и вывод его класса (стол, шкаф, кошка, собака и т.д.) или группы вероятных классов, которая лучше всего характеризует изображение. Для людей это совершенно естественно и просто: это один из первых навыков, который мы осваиваем с рождения. Компьютер лишь «видит» перед собой пиксели изображения, имеющие различный цвет и интенсивность. На сегодня задача классификации объектов, расположенных на изображении, является основной для области компьютерного зрения. Данная область начала активно развиваться с 1970-х, когда компьютеры стали достаточно мощными, чтобы оперировать большими объёмами данных. До развития нейронных сетей задачу классификации изображений решали с помощью специализированных алгоритмов. Например, выделение границ изображения с помощью фильтра Собеля и фильтра Шарра или использование гистограмм градиентов10. С появлением более мощных GPU, позволяющих значительно эффективнее обучать нейросеть, применение нейросетей в сфере компьютерного зрения значительно возросло.
До развития нейронных сетей задачу классификации изображений решали с помощью специализированных алгоритмов. Например, выделение границ изображения с помощью фильтра Собеля и фильтра Шарра или использование гистограмм градиентов10. С появлением более мощных GPU, позволяющих значительно эффективнее обучать нейросеть, применение нейросетей в сфере компьютерного зрения значительно возросло.
В 1988 году Ян Лекун предложил свёрточную архитектуру нейросети, нацеленную на классификацию изображений. А в 2012 году сеть AlexNet, построенная по данной архитектуре, заняла первое место в конкурсе по распознаванию изображений ImageNet, имея ошибку распознавания равную 15,3%12. Свёрточная архитектура нейросети использует некоторые особенности биологического распознавания образов, происходящих в мозгу человека. Например, в мозгу есть некоторые группы клеток, которые активируются, если в определённое поле зрения попадает горизонтальная или вертикальная граница объекта. Данное явление обнаружили Хьюбель и Визель в 1962 году.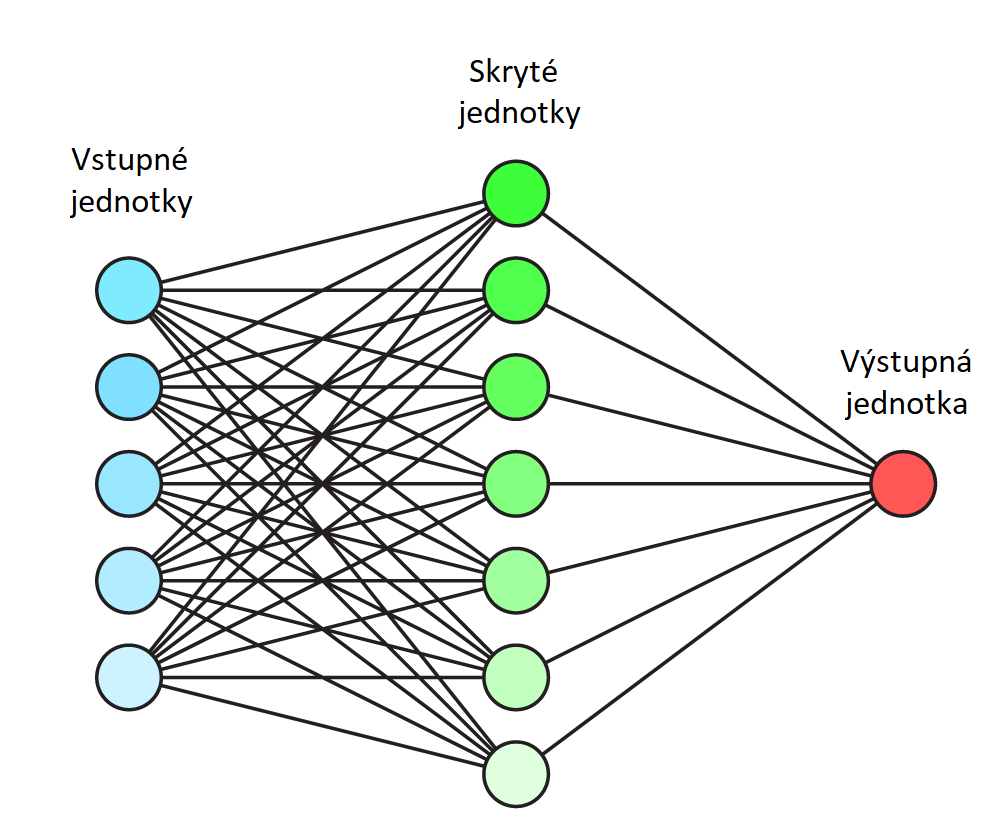 Поэтому, когда мы смотрим на изображение, скажем, собаки, мы можем отнести его к конкретному классу, если у изображения есть характерные особенности, которые можно идентифицировать, такие как лапы или четыре ноги. Аналогичным образом компьютер может выполнять классификацию изображений через поиск характеристик базового уровня, например, границ и искривлений, а затем — с помощью построения более абстрактных концепций через группы сверточных слоев.
Поэтому, когда мы смотрим на изображение, скажем, собаки, мы можем отнести его к конкретному классу, если у изображения есть характерные особенности, которые можно идентифицировать, такие как лапы или четыре ноги. Аналогичным образом компьютер может выполнять классификацию изображений через поиск характеристик базового уровня, например, границ и искривлений, а затем — с помощью построения более абстрактных концепций через группы сверточных слоев.
Рассмотрим подробнее архитектуру и работу свёрточной нейросети (convolution neural network) на примере нейросети AlexNet (см. рис. 15). На вход подаётся изображение 227х227 пикселей (на рисунке изображено желтым), которое необходимо классифицировать (всего 1000 возможных классов). Изображение цветное, поэтому оно разбито по трём RGB-каналам. Наиболее важная операция – операция свёртки.
Операция свёртки (convolution) производится над двумя матрицами A и B размера [axb] и [cxd], результатом которой является матрица С размера
, где s – шаг, на который сдвигают матрицу B. Вычисляется результирующая матрица следующим образом:
Вычисляется результирующая матрица следующим образом:
Рисунок 16. Операция свёртки15: Исходная матрица A обозначена голубым цветом (имеет большую размерность), ядро свертки – матрица B — обозначена темно-синим цветом и перемещается по матрице A; результирующая матрица изображена зеленым, при этом соответствующая каждому шагу свертки результирующая ячейка отмечена темно-зеленым.
Рис. 16. Операция свёртки.Чем больше результирующий элемент ci,j,, тем более похожа область матрицы A на матрицу B. A называют изображением, а B – ядром или фильтром. Обычно шаг смещения B равен s = 1. Если увеличить шаг смещения, можно добиться уменьшения влияния соседних пикселей друг на друга в сумме (уменьшить рецептивное поле восприятия нейросети), в подавляющем большинстве случаев шаг оставляют равным 1. На рецептивное поле также влияет и размер ядра свёртки. Как видно из рис. 16, при свёртке результат теряет в размерности по сравнению с матрицей A. Поэтому, чтобы избежать данного явления, матрицу A дополняют ячейками (padding). Если этого не сделать, данные при переходе на следующие слои будут теряться слишком быстро, а информация о границах слоя будет неточной.
16, при свёртке результат теряет в размерности по сравнению с матрицей A. Поэтому, чтобы избежать данного явления, матрицу A дополняют ячейками (padding). Если этого не сделать, данные при переходе на следующие слои будут теряться слишком быстро, а информация о границах слоя будет неточной.
Таким образом, свёртка позволяет одному нейрону отвечать за определённый набор пикселей в изображении. Весовыми коэффициентами являются коэффициенты фильтра, а входными переменными – интенсивность свечения пикселя плюс параметр смещения.
Данный пример свёртки (см. рис. 16) был одномерным и подходит, например, для черно-белого изображения. В случае цветного изображения операция свёртки происходит следующим образом: в один фильтр включены три ядра, для каждого канала RGB соответственно, над каждым каналом операция свёртки происходит идентично примеру выше, затем три результирующие матрицы поэлементно складываются — и получается результат работы одного
фильтра – карта признаков.
Эта на первый взгляд непростая с математической точки зрения процедура нужна для выделения тех самых границ и искривлений – контуров изображения, при помощи которых, по аналогии с мозгом человека, сеть должна понять, что же изображено на картинке. Т.е. на карте признаков будут содержаться выделенные характеристические очертания детектированных объектов. Эта карта признаков будет являться результатом работы чередующихся слоев свертки и пулинга (от англ. pooling, или иначе – subsampling layers). Помните, в разделе описания концепции архитектуры сверточных сетей мы говорили, что эти слои чередуются и их наборы могут повторяться несколько раз (см. рис. 5)? Для чего это нужно? После свертки, как мы знаем, выделяются и «заостряются» некие характеристические черты анализируемого изображения (матрицы пикселей) путем увеличения значений соответствующих ядру ячеек матрицы и «занулению» значений других. При операции субдискретизации, или пулинга, происходит уменьшение размерности сформированных отдельных карт признаков.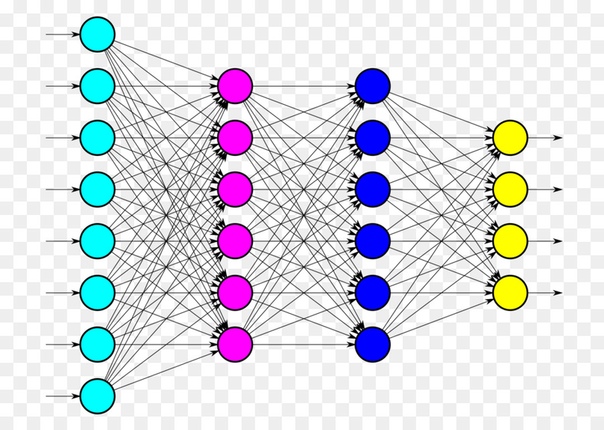 Поскольку для сверточных нейросетей считается, что информация о факте наличия искомого признака важнее точного знания его координат на изображении, то из нескольких соседних нейронов карты признаков выбирается максимальный и принимается за один нейрон уплотнённой карты признаков меньшей размерности. За счёт данной операции, помимо ускорения дальнейших вычислений, сеть становится также более инвариантной к масштабу входного изображения, сдвигам и поворотам изображений. Данное чередование слоев мы видим и для данной сети AlexNet (см. рис. 15), где слои свертки (обозначены CONV) чередуются с пулингом (обозначены эти слои как POOL), при этом следует учитывать, что операции свертки тем ресурсозатратнее, чем больше размер ядра свертки (матрицы B на рис. 16), поэтому иногда, когда требуется свертка с ядром достаточно большой размерности, ее заменяют на две и более последовательных свертки с ядром меньших
Поскольку для сверточных нейросетей считается, что информация о факте наличия искомого признака важнее точного знания его координат на изображении, то из нескольких соседних нейронов карты признаков выбирается максимальный и принимается за один нейрон уплотнённой карты признаков меньшей размерности. За счёт данной операции, помимо ускорения дальнейших вычислений, сеть становится также более инвариантной к масштабу входного изображения, сдвигам и поворотам изображений. Данное чередование слоев мы видим и для данной сети AlexNet (см. рис. 15), где слои свертки (обозначены CONV) чередуются с пулингом (обозначены эти слои как POOL), при этом следует учитывать, что операции свертки тем ресурсозатратнее, чем больше размер ядра свертки (матрицы B на рис. 16), поэтому иногда, когда требуется свертка с ядром достаточно большой размерности, ее заменяют на две и более последовательных свертки с ядром меньших
размерностей. (Об этом мы поговорим далее.) Поэтому на рис. 15 мы можем увидеть участок архитектуры AlexNet, на котором три слоя CONV идут друг за другом.
Самая интересная часть в сети – полносвязный слой в конце. В этом слое по вводным данным (которые пришли с предыдущих слоев) строится и выводится вектор длины N, где N – число классов, по которым мы бы хотели классифицировать изображение, из них программа выбирает нужный. Например, если мы хотим построить сеть по распознаванию цифр, у N будет значение 10, потому что цифр всего 10. Каждое число в этом векторе представляет собой вероятность конкретного класса. Например, если результирующий вектор для распознавания цифр это [0 0.2 0 0.75 0 0 0 0 0.05], значит существует 20% вероятность, что на изображении «1», 75% вероятность – что «3», и 5% вероятность – что «9». Если мы хотим сеть по распознаванию букв латинского алфавита, то N должно быть равным 26 (без учета регистра), а если и буквы, и цифры вместе, то уже 36. И т.д. Конечно, это очень упрощенные примеры. В сети AlexNet конечная размерность выхода (изображена на рис. 15 зеленым) — 1000, а перед этим идут еще несколько полносвязных слоев с размерностями входа 9216 и выхода 4096 и обоими параметрами 4096 (изображены оранжевым и отмечены FC – full connected — на рисунке).
Способ, с помощью которого работает полносвязный слой, – это обращение к выходу предыдущего слоя (который, как мы помним, должен выводить высокоуровневые карты свойств) и определение свойств, которые больше связаны с определенным классом. Поэтому в результате работы окончания сверточной сети по поданному на вход изображению с лужайкой, на которой, скажем, собака гоняется за птичкой, упрощенно можно сказать, что результатом может являться следующий вывод:
[dog (0.6), bird (0.35), cloud (0.05)].
Свёрточная нейронная сеть GoogleNet
В 2014 году на том же соревновании ImageNet, где была представлена AlexNet, компания Google показала свою свёрточную нейросеть под названием GoogleNet. Отличительная особенность этой сети была в том, что она использовала в 12 раз меньше параметров (почувствуйте масштабы: 5 000 000 против 60 000 000) и её архитектура структурно была не похожа на архитектуру AlexNet, в которой было восемь слоёв, причём данная сеть давала более точный результат – 6,67% ошибки против 16,4%16.
Разработчики GoogleNet пытались избежать простого увеличения слоёв нейронной сети, потому что данный шаг привёл бы к значительному увеличению использования памяти и сеть была бы больше склонна к перенасыщению при обучении на небольшом и ограниченном наборе примеров.
Проанализируем приём, на который пошли разработчики компании Google для оптимизации скорости и использования памяти. В нейросети GoogleNet свёртка с размером фильтра 7×7 используется один раз в начале обработки изображения, далее максимальный размер – 5×5. Так как количество параметров при свёртке растёт квадратично с увеличением размерности ядра, нужно стараться заменять одну свёртку на несколько свёрток с меньшим размером фильтра, вместе с этим пропустить промежуточные результаты через ReLU (функция активации, возвращающая 0, если сигнал отрицателен, и само значение сигнала, если нет), чтобы внести дополнительную нелинейность. Например, свёртку с размером фильтра 5×5 можно заменить двумя последовательными операциями с размером ядра 3×3. Такая оптимизация позволяет строить более гибкие и глубокие сети. На хранение промежуточных свёрток тратится память, и использовать их более разумно в слоях, где размер карты признаков небольшой. Поэтому в начале сети GoogleNet вместо трёх свёрток 3×3 используется одна 7×7, чтобы избежать избыточного использования памяти.
Такая оптимизация позволяет строить более гибкие и глубокие сети. На хранение промежуточных свёрток тратится память, и использовать их более разумно в слоях, где размер карты признаков небольшой. Поэтому в начале сети GoogleNet вместо трёх свёрток 3×3 используется одна 7×7, чтобы избежать избыточного использования памяти.
Схему архитектуры сети целиком мы приводить здесь не будем, она слишком громоздка и на ней трудно что-либо разглядеть, кому это будет интересно, могут ознакомиться с ней на официальном ресурсе16. Отличительной особенностью нейросети от компании Google является использование специального модуля – Inception (см. рис. 17). Данный модуль, по своей сути, является небольшой локальной сетью. Идея данного блока состоит в том, что на одну карту признаков накладывается сразу несколько свёрток разного размера, вычисляющихся параллельно. В конце все свёртки объединяются в единый блок. Таким образом, можно из исходной карты признаков извлечь признаки разного размера, увеличив эффективность сети и точность обработки признаков. Однако при использовании данной реализации (см. рис. 17) нужно выполнить колоссальный объём вычислений, между тем, при включении данных модулей друг за другом размерность блока будет только расти. Поэтому разработчики во второй версии добавили свёртки, уменьшающие размерность (см. рис. 18).
Однако при использовании данной реализации (см. рис. 17) нужно выполнить колоссальный объём вычислений, между тем, при включении данных модулей друг за другом размерность блока будет только расти. Поэтому разработчики во второй версии добавили свёртки, уменьшающие размерность (см. рис. 18).
Жёлтые свёртки размера 1×1 введены для уменьшения глубины блоков, и благодаря им, значительно снижается нагрузка на память. GoogleNet содержит девять таких Inception-модулей и состоит из 22 слоёв.
Из-за большой глубины сети разработчики также столкнулись с проблемой затухания градиента при обучении (см. описание процедуры обучения нейросети: коррекция весов осуществляется в соответствии со значением ошибки, производной функции активации – градиента – и т.д.) и ввели два вспомогательных модуля классификатора (см. рис. 19). Данные модули представляют собой выходную часть малой свёрточной сети и уже частично классифицируют объект по внутренним характеристикам самой сети. При обучении нейронной сети данные модули не дают ошибке, распространяющиейся с конца, сильно уменьшиться, так как вводят в середину сети дополнительную ошибку.
При обучении нейронной сети данные модули не дают ошибке, распространяющиейся с конца, сильно уменьшиться, так как вводят в середину сети дополнительную ошибку.
Ещё один полезный аспект в архитектуре GoogleNet, по мнению разработчиков, состоит в том, что сеть интуитивно правильно обрабатывает изображение: сначала картинка обрабатывается в разных масштабах, а затем результаты агрегируются. Такой подход больше соответствует тому, как подсознательно выполняет анализ окружения человек.
В 2015 году разработчики из Google представили модифицированный модуль Inception v2, в котором свёртка 5×5 была заменена на две свёртки 3×3, по причинам, приведённым выше, вдобавок потери информации в картах признаков при таком действии происходят незначительные, так как соседние ячейки имеют между собой сильную корреляционную связь. Также, если заменить свёртку 3×3 на две последовательные свёртки 3×1 и 1×3, то это будет на 33% эффективнее, чем стандартная свёртка, а две свёртки 2×2 дадут выигрыш лишь в 11%17. Данная архитектура нейросети давала ошибку 5,6%, а потребляла ресурсов в 2,5 раза меньше.
Данная архитектура нейросети давала ошибку 5,6%, а потребляла ресурсов в 2,5 раза меньше.
Стоит отметить, что точного алгоритма построения архитектуры нейросети не существует. Разработчики составляют свёрточные нейросети, основываясь на результатах экспериментов и собственном опыте.
Нейронную сеть можно использовать для точной классификации изображений, загруженных в глобальную сеть, либо использовать для сортировки фотографий по определённому признаку в галерее смартфона.
Свёрточная нейронная сеть имеет следующие преимущества: благодаря своей структуре, она позволяет значительно снизить количество весов в сравнении с полносвязанной нейронной сетью, её операции легко поддаются распараллеливанию, что положительно сказывается на скорости обучения и на скорости работы, данная архитектура лидирует в области классификации изображений, занимая первые места на соревновании ImageNet. Из-за того, что для сети более важно наличие признака, а не его место на изображении, она инвариантна к различным сдвигам и поворотам сканируемого изображения.
К недостаткам данной архитектуры можно отнести следующие: состав сети (количество её слоёв, функция активации, размерность свёрток, размерность pooling-слоёв, очередность слоёв и т.п.) необходимо подбирать эмпирически к определённому размеру и виду
изображения; сложность обучения: нейросети с хорошим показателем ошибки должны тренироваться на мощных GPU долгое время; и, наверное, главный недостаток – атаки на данные нейросети. Инженеры Google в 2015 году показали, что к картинке можно подмешать невидимый для человеческого зрения градиент, который приведёт к неправильной классификации.
В чем разница между глубоким обучением и машинным обучением?
{«id»:156528,»url»:»https:\/\/vc.ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem»,»title»:»\u0412 \u0447\u0435\u043c \u0440\u0430\u0437\u043d\u0438\u0446\u0430 \u043c\u0435\u0436\u0434\u0443 \u0433\u043b\u0443\u0431\u043e\u043a\u0438\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c \u0438 \u043c\u0430\u0448\u0438\u043d\u043d\u044b\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c?»,»services»:{«facebook»:{«url»:»https:\/\/www. facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem&title=\u0412 \u0447\u0435\u043c \u0440\u0430\u0437\u043d\u0438\u0446\u0430 \u043c\u0435\u0436\u0434\u0443 \u0433\u043b\u0443\u0431\u043e\u043a\u0438\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c \u0438 \u043c\u0430\u0448\u0438\u043d\u043d\u044b\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c?»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem&text=\u0412 \u0447\u0435\u043c \u0440\u0430\u0437\u043d\u0438\u0446\u0430 \u043c\u0435\u0436\u0434\u0443 \u0433\u043b\u0443\u0431\u043e\u043a\u0438\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c \u0438 \u043c\u0430\u0448\u0438\u043d\u043d\u044b\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c?»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.
facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem&title=\u0412 \u0447\u0435\u043c \u0440\u0430\u0437\u043d\u0438\u0446\u0430 \u043c\u0435\u0436\u0434\u0443 \u0433\u043b\u0443\u0431\u043e\u043a\u0438\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c \u0438 \u043c\u0430\u0448\u0438\u043d\u043d\u044b\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c?»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem&text=\u0412 \u0447\u0435\u043c \u0440\u0430\u0437\u043d\u0438\u0446\u0430 \u043c\u0435\u0436\u0434\u0443 \u0433\u043b\u0443\u0431\u043e\u043a\u0438\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c \u0438 \u043c\u0430\u0448\u0438\u043d\u043d\u044b\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c?»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc. ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem&text=\u0412 \u0447\u0435\u043c \u0440\u0430\u0437\u043d\u0438\u0446\u0430 \u043c\u0435\u0436\u0434\u0443 \u0433\u043b\u0443\u0431\u043e\u043a\u0438\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c \u0438 \u043c\u0430\u0448\u0438\u043d\u043d\u044b\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c?»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u0412 \u0447\u0435\u043c \u0440\u0430\u0437\u043d\u0438\u0446\u0430 \u043c\u0435\u0436\u0434\u0443 \u0433\u043b\u0443\u0431\u043e\u043a\u0438\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c \u0438 \u043c\u0430\u0448\u0438\u043d\u043d\u044b\u043c \u043e\u0431\u0443\u0447\u0435\u043d\u0438\u0435\u043c?&body=https:\/\/vc.
 ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
ru\/ml\/156528-v-chem-raznica-mezhdu-glubokim-obucheniem-i-mashinnym-obucheniem»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
Мир, в котором мы живем, легко увлекается модными словечками. Компании быстро цепляются за новые возможности, которые предлагают технологические инновации — от ИИ до блокчейна.
Среди трендов можно назвать машинное обучение, а в последнее время – еще и глубокое обучение. Но что такое машинное обучение и чем от оно отличается от глубокого обучения?
Чтобы лучше понять терминологию, я бы предложил рассматривать машинное обучение как разновидность искусственного интеллекта — еще одно модное слово, которое уже довольно давно используется и завоевывает отрасли. Концепция машинного обучения уходит от жестких алгоритмов к большей гибкости и, в некотором смысле, к имитации человеческого мозга в том, как он «думает». По сути, машинное обучение — это метод передачи данных машине, которые она анализирует и изучает, выявляет закономерности и прогнозирует результаты на основе первичных данных.
Концепция машинного обучения уходит от жестких алгоритмов к большей гибкости и, в некотором смысле, к имитации человеческого мозга в том, как он «думает». По сути, машинное обучение — это метод передачи данных машине, которые она анализирует и изучает, выявляет закономерности и прогнозирует результаты на основе первичных данных.
Таким образом, машинное обучение — это уникальный тип искусственного интеллекта, который позволяет компьютерам обучаться без необходимости их дополнительного программирования, прежде всего потому, что алгоритмы обучаются и развиваются независимо от получения новых данных.
В свою очередь, глубокое обучение — это разновидность машинного обучения, но более сложная по принципу работы. Когда мы говорим о глубоком обучении, мы на самом деле подразумеваем набор нейронных сетей, которые проходят процесс самообучения на основе данных, которые загружает машина. Нейроны, составляющие сеть, учатся решать, какие функции лучше всего подходят для выполнения задач или классификации данных. Со временем, после многих итераций процесса обучения, глубокое обучение повышает вероятность точной классификации или предсказаний. Как и человеческий мозг, нейронные сети могут учиться на собственных ошибках. При глубоком обучении нейронная сеть состоит из нескольких слоев. На самом деле глубокое обучение — это более сложная и функциональная разновидность машинного обучения.
Когда мы говорим о глубоком обучении, мы на самом деле подразумеваем набор нейронных сетей, которые проходят процесс самообучения на основе данных, которые загружает машина. Нейроны, составляющие сеть, учатся решать, какие функции лучше всего подходят для выполнения задач или классификации данных. Со временем, после многих итераций процесса обучения, глубокое обучение повышает вероятность точной классификации или предсказаний. Как и человеческий мозг, нейронные сети могут учиться на собственных ошибках. При глубоком обучении нейронная сеть состоит из нескольких слоев. На самом деле глубокое обучение — это более сложная и функциональная разновидность машинного обучения.
Ваш бизнес может применять глубокое обучение к любому типу данных — от аудио, видео и распознавания речи до изображений и текста, чтобы предсказывать результаты и делать выводы, как это делает человеческий мозг, но в разы быстрее.
Каждый день мы слышим о новых технологических гигантах, интегрирующих машинное обучение, и о ведущих исследовательских лабораториях, разрабатывающих алгоритмы на основе глубокого машинного обучения, чтобы раздвинуть границы технологических экспериментов. Google уже начал внедрять алгоритмы машинного обучения в сервисы Gmail, Google Search и Google Maps. Папка «Приоритетные» теперь может автоматически определять важные сообщения и группировать их отдельно от папки «Входящие», сортируя их по степени важности. Smart Reply предлагает шаблоны ответов на электронные письма.
Та же самая логика лежит в основе программ Google Search и Google Maps, которые многие из нас используют ежедневно. Может быть, они кажутся интуитивно понятными и легкими, но машинное обучение уже давно является неотъемлемой частью поисковых механизмов, к которым мы все так привыкли: система волшебным образом «угадывает», что мы собираемся искать, но на самом деле это не совсем «волшебство». Это работа умной система, которая изучает поисковые запросы и предугадывает, что мы можем искать в будущем.
Это работа умной система, которая изучает поисковые запросы и предугадывает, что мы можем искать в будущем.
Машинное обучение также находится за фасадом пользовательского интерфейса, который Netflix предлагает своим участникам. Недавно компания обнародовала данные об инвестировании значительных средств в машинное обучение для постоянного улучшения своей системы рекомендаций, которая изучает и учитывает вкусы и предпочтения пользователей в отношении потокового контента и предлагает соответствующие рекомендации того, что смотреть дальше. Netflix также использует результаты прототипирования и A / B тестирования, чтобы обогатить свою библиотеку контента патентованных фильмов и инвестировать в производство контента, который понравится его аудитории.
Помимо развлечений и персонализации, глубокое обучение также является неотъемлемой частью транспортных средств с независимыми навигационными системами, например, Drive. ai. Благодаря способности глубокого обучения изучать и классифицировать данные, автомобили могут использовать датчики для распознавания различных препятствий, пешеходов, перекрытых дорог, дорожных конструкций и многого другого, и гарантировать, что автомобиль соответствующим образом отреагирует на препятствие. Речь идет не только об оптимизации самых безопасных и эффективных маршрутов. Беспилотные автомобили улучшают свою способность управлять транспортным средством в ситуациях, в которых даже водители-люди могут оказаться в затруднительном положении. Беспилотные автомобили становятся все лучше и лучше, стремясь к совершенству, поскольку данные, на которых они обучаются, постоянно увеличиваются.
ai. Благодаря способности глубокого обучения изучать и классифицировать данные, автомобили могут использовать датчики для распознавания различных препятствий, пешеходов, перекрытых дорог, дорожных конструкций и многого другого, и гарантировать, что автомобиль соответствующим образом отреагирует на препятствие. Речь идет не только об оптимизации самых безопасных и эффективных маршрутов. Беспилотные автомобили улучшают свою способность управлять транспортным средством в ситуациях, в которых даже водители-люди могут оказаться в затруднительном положении. Беспилотные автомобили становятся все лучше и лучше, стремясь к совершенству, поскольку данные, на которых они обучаются, постоянно увеличиваются.
Конечно, при сегодняшней культуре, в которой предприятия влюбляются в каждую создаваемую новую технологию, легко стать жертвой привлекательности передовых технологий, которыми индустрия бредит в данный момент.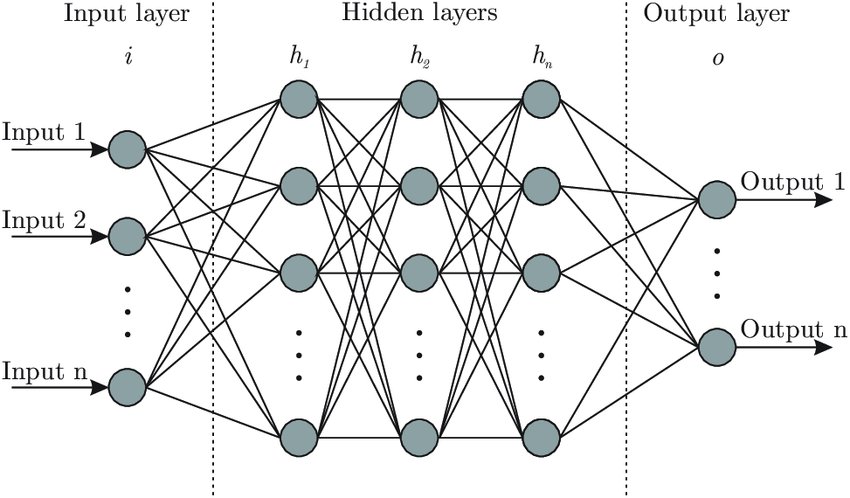 Но в случае машинного обучения и, в частности, глубокого обучения, я считаю, что шумиха вполне заслужена и действительно предоставляет безграничные перспективы для компаний.
Но в случае машинного обучения и, в частности, глубокого обучения, я считаю, что шумиха вполне заслужена и действительно предоставляет безграничные перспективы для компаний.
И с каждым днем мы приближаемся к тому, чтобы повторить гибкий и подвижный образ мышления человеческого мозга, только с большей скоростью.
Сравнение глубокого обучения и машинного обучения — Azure Machine Learning
- Чтение занимает 7 мин
В этой статье
В этой статье объясняется глубокое изучение и машинное обучение, а также их соответствие в более широкой категории искусственного интеллекта. This article explains deep learning vs. machine learning and how they fit into the broader category of artificial intelligence. Узнайте о решениях для глубокого обучения, которые можно создавать на Машинное обучение Azure, таких как обнаружение мошенничества, распознавание речи и лиц, анализ тональностиности и прогнозирование временных рядов.Learn about deep learning solutions you can build on Azure Machine Learning, such as fraud detection, voice and facial recognition, sentiment analysis, and time series forecasting.
This article explains deep learning vs. machine learning and how they fit into the broader category of artificial intelligence. Узнайте о решениях для глубокого обучения, которые можно создавать на Машинное обучение Azure, таких как обнаружение мошенничества, распознавание речи и лиц, анализ тональностиности и прогнозирование временных рядов.Learn about deep learning solutions you can build on Azure Machine Learning, such as fraud detection, voice and facial recognition, sentiment analysis, and time series forecasting.
Рекомендации по выбору алгоритмов для решений см. на странице машинное обучение Algorithm Памятка по.For guidance on choosing algorithms for your solutions, see the Machine Learning Algorithm Cheat Sheet.
Глубокое обучение, машинное обучение и AIDeep learning, machine learning, and AI
Рассмотрим следующие определения для понимания глубокого обучения и машинного обучения и искусственного интеллекта.Consider the following definitions to understand deep learning vs. machine learning vs. AI:
machine learning vs. AI:
Глубокое обучение — это подмножество машинного обучения, основанное на искусственных нейронных сетях.Deep learning is a subset of machine learning that’s based on artificial neural networks. Процесс обучения является глубоким , поскольку структура искусственных нейронных сетей состоит из нескольких входных, выходных и скрытых слоев.The learning process is deep because the structure of artificial neural networks consists of multiple input, output, and hidden layers. Каждый слой содержит единицы, преобразующие входные данные в сведения, которые следующий слой может использовать для определенной задачи прогнозирования.Each layer contains units that transform the input data into information that the next layer can use for a certain predictive task. Благодаря этой структуре компьютер может изучать собственную обработку данных.Thanks to this structure, a machine can learn through its own data processing.
Машинное обучение — это подмножество искусственного интеллекта, которое использует методы (например, глубокое обучение), которые позволяют компьютерам использовать возможности для улучшения задач.Machine learning is a subset of artificial intelligence that uses techniques (such as deep learning) that enable machines to use experience to improve at tasks. Процесс обучения основан на следующих шагах:The learning process is based on the following steps:
- Передавать данные в алгоритм.Feed data into an algorithm. (На этом шаге можно предоставить модели дополнительные сведения, например, выполнив извлечение компонентов.)(In this step you can provide additional information to the model, for example, by performing feature extraction.)
- Используйте эти данные для обучения модели.Use this data to train a model.
- Тестирование и развертывание модели.Test and deploy the model.
- Использование развернутой модели для автоматизированной прогнозной задачи.
 Consume the deployed model to do an automated predictive task. (Иными словами, вызовите и используйте развернутую модель для получения прогнозов, возвращаемых моделью.)(In other words, call and use the deployed model to receive the predictions returned by the model.)
Consume the deployed model to do an automated predictive task. (Иными словами, вызовите и используйте развернутую модель для получения прогнозов, возвращаемых моделью.)(In other words, call and use the deployed model to receive the predictions returned by the model.)
Искусственный интеллект (ии) — это методика, которая позволяет компьютерам имитировать человеческий интеллект.Artificial intelligence (AI) is a technique that enables computers to mimic human intelligence. Он включает в себя машинное обучение.It includes machine learning.
С помощью приемов машинного обучения и глубокого обучения можно создавать компьютерные системы и приложения, которые выполняют задачи, которые обычно связаны с человеческим интеллектом.By using machine learning and deep learning techniques, you can build computer systems and applications that do tasks that are commonly associated with human intelligence. К этим задачам относятся распознавание изображений, распознавание речи и языковой перевод. These tasks include image recognition, speech recognition, and language translation.
These tasks include image recognition, speech recognition, and language translation.
Методы глубокого обучения и машинного обученияTechniques of deep learning vs. machine learning
Теперь, когда у вас есть общие сведения о машинном обучении и глубоком обучении, давайте сравним эти два метода.Now that you have the overview of machine learning vs. deep learning, let’s compare the two techniques. В машинном обучении алгоритму необходимо сообщить, как выполнить точный прогноз, используя дополнительные сведения (например, выполнив извлечение компонентов).In machine learning, the algorithm needs to be told how to make an accurate prediction by consuming more information (for example, by performing feature extraction). В глубоком обучении алгоритм может узнать, как создать точный прогноз с помощью собственной обработки данных благодаря искусственной структуре нейронных сетей.In deep learning, the algorithm can learn how to make an accurate prediction through its own data processing, thanks to the artificial neural network structure.
В следующей таблице приведено более подробное сравнение этих двух приемов:The following table compares the two techniques in more detail:
| Все машинное обучениеAll machine learning | Только глубокое обучениеOnly deep learning | |
|---|---|---|
| Количество точек данныхNumber of data points | Для создания прогнозов можно использовать небольшие объемы данных.Can use small amounts of data to make predictions. | Для создания прогнозов необходимо использовать большие объемы обучающих данных.Needs to use large amounts of training data to make predictions. |
| Зависимости оборудованияHardware dependencies | Может работать на низкоуровневых компьютерах.Can work on low-end machines. Для этого не требуется большой объем вычислительной мощности.It doesn’t need a large amount of computational power. | Зависит от высокопроизводительных компьютеров. Depends on high-end machines. Он по сути выполняет большое количество операций умножения матриц.It inherently does a large number of matrix multiplication operations. GPU может эффективно оптимизировать эти операции.A GPU can efficiently optimize these operations. Depends on high-end machines. Он по сути выполняет большое количество операций умножения матриц.It inherently does a large number of matrix multiplication operations. GPU может эффективно оптимизировать эти операции.A GPU can efficiently optimize these operations. |
| Процесс Добавление признаковFeaturization process | Требует точного определения и создания компонентов пользователями.Requires features to be accurately identified and created by users. | Сведения о функциях высокого уровня данных и о создании новых функций.Learns high-level features from data and creates new features by itself. |
| Подход к обучениюLearning approach | Делит процесс обучения на более мелкие шаги.Divides the learning process into smaller steps. Затем результаты из каждого шага объединяются в один выход.It then combines the results from each step into one output. | Просматривает процесс обучения, устраняя проблему на сквозной основе. Moves through the learning process by resolving the problem on an end-to-end basis. Moves through the learning process by resolving the problem on an end-to-end basis. |
| Время выполненияExecution time | Занимает сравнительно мало времени на обучение, от нескольких секунд до нескольких часов.Takes comparatively little time to train, ranging from a few seconds to a few hours. | Обычно процесс обучения занимает много времени, поскольку алгоритм глубокого обучения включает много уровней.Usually takes a long time to train because a deep learning algorithm involves many layers. |
| Выходные данныеOutput | Выходным значением обычно является числовое значение, например оценка или классификация.The output is usually a numerical value, like a score or a classification. | Выходные данные могут иметь несколько форматов, например текст, оценку или звук.The output can have multiple formats, like a text, a score or a sound. |
Что такое перенос обученияWhat is transfer learning
Обучение модели глубокого обучения часто требует большого количества обучающих данных, высокопроизводительных вычислений (GPU, ТПУ) и более длительного обучения. Training deep learning models often requires large amounts of training data, high-end compute resources (GPU, TPU), and a longer training time. В сценариях, когда вы не имеете доступа к этим средствам, вы можете попытаться упростить процесс обучения с помощью методики, известной как Перенос обучения.In scenarios when you don’t have any of these available to you, you can shortcut the training process using a technique known as transfer learning.
Training deep learning models often requires large amounts of training data, high-end compute resources (GPU, TPU), and a longer training time. В сценариях, когда вы не имеете доступа к этим средствам, вы можете попытаться упростить процесс обучения с помощью методики, известной как Перенос обучения.In scenarios when you don’t have any of these available to you, you can shortcut the training process using a technique known as transfer learning.
Перемещение обучения — это метод, который применяет знания, полученные от решения одной проблемы, к другой, но связанной с ней.Transfer learning is a technique that applies knowledge gained from solving one problem to a different but related problem.
Из-за структуры нейронных сетей первый набор слоев обычно содержит функции более низкого уровня, в то время как окончательный набор слоев содержит функцию более высокого уровня, более близкую к рассматриваемому домену.Due to the structure of neural networks, the first set of layers usually contain lower-level features, whereas the final set of layers contains higher-level feature that are closer to the domain in question. Переориентация окончательные слои для использования в новом домене или проблеме, можно значительно сократить количество времени, данных и ресурсов вычислений, необходимых для обучения новой модели.By repurposing the final layers for use in a new domain or problem, you can significantly reduce the amount of time, data, and compute resources needed to train the new model. Например, если у вас уже есть модель, которая распознает автомобили, вы можете повторно присвоить эту модель с помощью функции перевода, чтобы также распознавать грузовики, мотоциклах и другие виды транспортных средств.For example, if you already have a model that recognizes cars, you can repurpose that model using transfer learning to also recognize trucks, motorcycles, and other kinds of vehicles.
Переориентация окончательные слои для использования в новом домене или проблеме, можно значительно сократить количество времени, данных и ресурсов вычислений, необходимых для обучения новой модели.By repurposing the final layers for use in a new domain or problem, you can significantly reduce the amount of time, data, and compute resources needed to train the new model. Например, если у вас уже есть модель, которая распознает автомобили, вы можете повторно присвоить эту модель с помощью функции перевода, чтобы также распознавать грузовики, мотоциклах и другие виды транспортных средств.For example, if you already have a model that recognizes cars, you can repurpose that model using transfer learning to also recognize trucks, motorcycles, and other kinds of vehicles.
Узнайте, как применить обучение для классификации изображений с помощью платформы с открытым кодом в Машинное обучение Azure: обучение модели PyTorch для глубокого обучения с помощью функции перемещения обучения.Learn how to apply transfer learning for image classification using an open-source framework in Azure Machine Learning : Train a deep learning PyTorch model using transfer learning.
Примеры использования для глубокого обученияDeep learning use cases
Из-за структуры искусственной нейронной сети глубокое обучение предназначен в определении закономерностей в неструктурированных данных, таких как изображения, звук, видео и текст.Because of the artificial neural network structure, deep learning excels at identifying patterns in unstructured data such as images, sound, video, and text. По этой причине глубокое обучение быстро преобразует множество отраслей, включая здравоохранение, энергию, Финансы и транспорт.For this reason, deep learning is rapidly transforming many industries, including healthcare, energy, finance, and transportation. Эти отрасли теперь пересматривают традиционные бизнес-процессы.These industries are now rethinking traditional business processes.
Некоторые из наиболее распространенных приложений для глубокого обучения описаны в следующих абзацах.Some of the most common applications for deep learning are described in the following paragraphs. В Машинное обучение Azure можно использовать модель из среды с открытым исходным кодом или построить модель с помощью предоставленных средств.In Azure Machine Learning, you can use a model from you build from an open-source framework or build the model using the tools provided.
В Машинное обучение Azure можно использовать модель из среды с открытым исходным кодом или построить модель с помощью предоставленных средств.In Azure Machine Learning, you can use a model from you build from an open-source framework or build the model using the tools provided.
Распознавание именованных сущностейNamed-entity recognition
Распознавание именованных сущностей — это метод глубокого обучения, который принимает фрагмент текста в качестве входных данных и преобразует его в предварительно определенный класс.Named-entity recognition is a deep learning method that takes a piece of text as input and transforms it into a pre-specified class. Эта новая информация может быть почтовым индексом, датой и ИДЕНТИФИКАТОРом продукта.This new information could be a postal code, a date, a product ID. Затем эти сведения могут храниться в структурированной схеме для создания списка адресов или служить тестом производительности для обработчика проверки личности.The information can then be stored in a structured schema to build a list of addresses or serve as a benchmark for an identity validation engine.
Обнаружение объектовObject detection
Глубокое обучение было применено во многих вариантах использования для обнаружения объектов.Deep learning has been applied in many object detection use cases. Обнаружение объектов состоит из двух частей: классификация изображений и локализация изображений.Object detection comprises two parts: image classification and then image localization. Классификация изображений определяет объекты изображения, такие как автомобили или люди.Image classification identifies the image’s objects, such as cars or people. Локализация образа предоставляет определенное расположение этих объектов.Image localization provides the specific location of these objects.
Обнаружение объектов уже используется в таких отраслях, как игровые, розничные, туристическая и самостоятельные автомобили.Object detection is already used in industries such as gaming, retail, tourism, and self-driving cars.
Создание заголовка изображенияImage caption generation
Как и при распознавании изображений, в создании субтитров изображений для данного изображения система должна создать заголовок, описывающий содержимое изображения. Like image recognition, in image captioning, for a given image, the system must generate a caption that describes the contents of the image. При обнаружении и отметке объектов в фотографиях следующим шагом является преобразование этих меток в описательные предложения.When you can detect and label objects in photographs, the next step is to turn those labels into descriptive sentences.
Like image recognition, in image captioning, for a given image, the system must generate a caption that describes the contents of the image. При обнаружении и отметке объектов в фотографиях следующим шагом является преобразование этих меток в описательные предложения.When you can detect and label objects in photographs, the next step is to turn those labels into descriptive sentences.
Как правило, для обозначения объектов в образе приложения с заголовком изображений используют свертки нейронных сетей, а затем используются обновленные нейронные сети для преобразования меток в одинаковые предложения.Usually, image captioning applications use convolutional neural networks to identify objects in an image and then use a recurrent neural network to turn the labels into consistent sentences.
Машинный переводMachine translation
Машинный перевод принимает слова или предложения на одном языке и автоматически преобразует их в другой язык.Machine translation takes words or sentences from one language and automatically translates them into another language.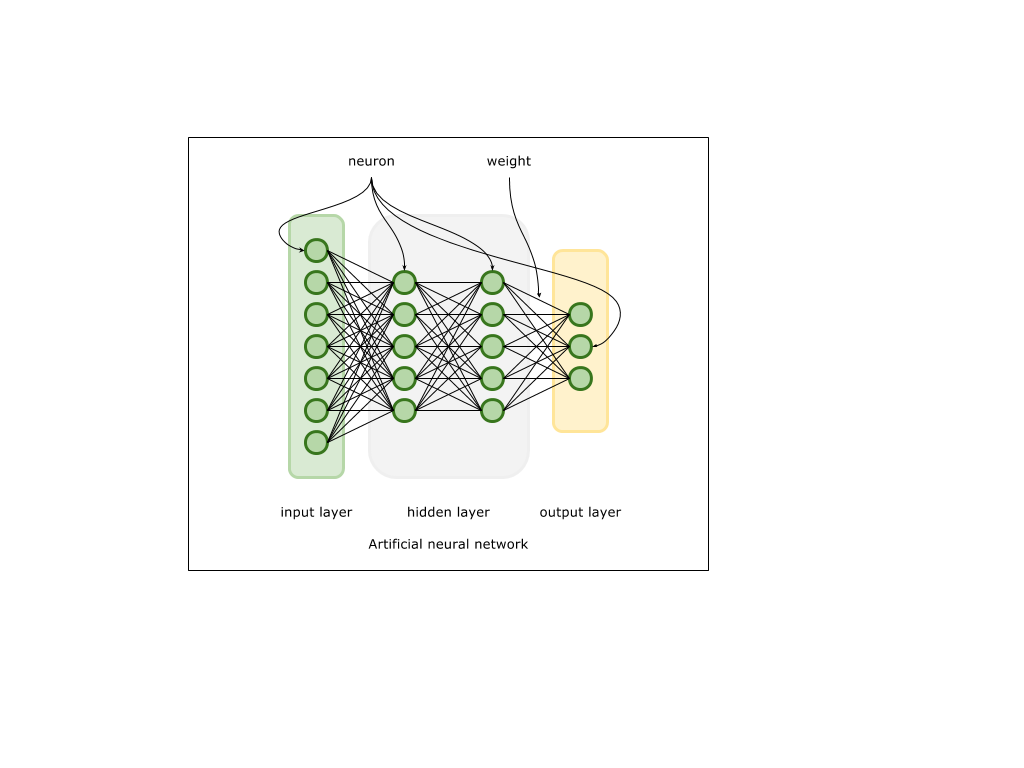 Машинный перевод занимает много времени, но глубокое обучение позволяет получить впечатляющие результаты в двух конкретных областях: Автоматический перевод текста (и перевод речи в текст) и автоматический перевод изображений.Machine translation has been around for a long time, but deep learning achieves impressive results in two specific areas: automatic translation of text (and translation of speech to text) and automatic translation of images.
Машинный перевод занимает много времени, но глубокое обучение позволяет получить впечатляющие результаты в двух конкретных областях: Автоматический перевод текста (и перевод речи в текст) и автоматический перевод изображений.Machine translation has been around for a long time, but deep learning achieves impressive results in two specific areas: automatic translation of text (and translation of speech to text) and automatic translation of images.
С помощью соответствующего преобразования данных нейронная сеть может понимать текст, звук и визуальные сигналы.With the appropriate data transformation, a neural network can understand text, audio, and visual signals. Машинный перевод можно использовать для распознавания фрагментов звука в больших звуковых файлах и транскрипция слово или изображение в виде текста.Machine translation can be used to identify snippets of sound in larger audio files and transcribe the spoken word or image as text.
Текстовая аналитикаText analytics
Текстовая аналитика, основанная на методах глубокого обучения, включает анализ больших объемов текстовых данных (например, медицинских документов или расходов на расходы), распознавание закономерностей и создание упорядоченной и краткой информации. Text analytics based on deep learning methods involves analyzing large quantities of text data (for example, medical documents or expenses receipts), recognizing patterns, and creating organized and concise information out of it.
Text analytics based on deep learning methods involves analyzing large quantities of text data (for example, medical documents or expenses receipts), recognizing patterns, and creating organized and concise information out of it.
Компании используют глубокое обучение для анализа текста, чтобы определить торговую торговлю и соответствие нормативным требованиям.Companies use deep learning to perform text analysis to detect insider trading and compliance with government regulations. Еще один распространенный пример — мошенник: текстовая аналитика часто используется для анализа больших объемов документов, чтобы распознавать шансы на мошенничество.Another common example is insurance fraud: text analytics has often been used to analyze large amounts of documents to recognize the chances of an insurance claim being fraud.
Искусственные нейронные сетиArtificial neural networks
Искусственные нейронные сети формируются с помощью слоев подключенных узлов.Artificial neural networks are formed by layers of connected nodes. Модели глубокого обучения используют нейронные сети с большим количеством уровней.Deep learning models use neural networks that have a large number of layers.
В следующих разделах рассматриваются наиболее популярные типологиес искусственной нейронной сети.The following sections explore most popular artificial neural network typologies.
Нейронная сеть фидфорвардFeedforward neural network
Нейронная сеть фидфорвард — это наиболее простой тип искусственной нейронной сети.The feedforward neural network is the most simple type of artificial neural network. В фидфорвард сети информация перемещается только в одном направлении от уровня ввода к выходному слою.In a feedforward network, information moves in only one direction from input layer to output layer. Нейронные сети фидфорвард преобразуют входные данные, поместив их через ряд скрытых слоев.Feedforward neural networks transform an input by putting it through a series of hidden layers. Каждый слой состоит из набора нейронов, и каждый уровень полностью подключается ко всем нейронам в слое.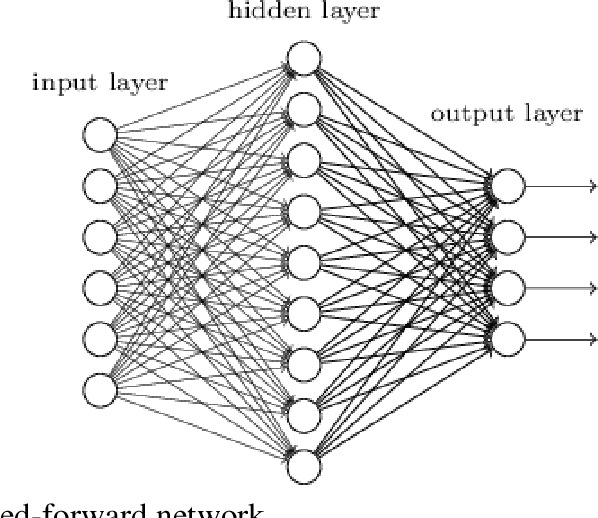 Every layer is made up of a set of neurons, and each layer is fully connected to all neurons in the layer before. Последний полностью подключенный слой (выходной слой) представляет созданные прогнозы.The last fully connected layer (the output layer) represents the generated predictions.
Every layer is made up of a set of neurons, and each layer is fully connected to all neurons in the layer before. Последний полностью подключенный слой (выходной слой) представляет созданные прогнозы.The last fully connected layer (the output layer) represents the generated predictions.
Перетекущая нейронная сетьRecurrent neural network
Перетекущие нейронные сети — широко используемые искусственные нейронные сети.Recurrent neural networks are a widely used artificial neural network. Эти сети сохраняют выходные данные слоя и передают его обратно на входной слой, чтобы помочь предсказать результат слоя.These networks save the output of a layer and feed it back to the input layer to help predict the layer’s outcome. В перетекущих нейронных сетях есть отличные возможности обучения.Recurrent neural networks have great learning abilities. Они широко используются для выполнения сложных задач, таких как прогнозирование временных рядов, изучение рукописного ввода и распознавание языка. They’re widely used for complex tasks such as time series forecasting, learning handwriting, and recognizing language.
They’re widely used for complex tasks such as time series forecasting, learning handwriting, and recognizing language.
Свертка нейронной сетиConvolutional neural network
Воспроизводящая нейронная сеть — это особо эффективная искусственная нейронная сеть, которая представляет собой уникальную архитектуру.A convolutional neural network is a particularly effective artificial neural network, and it presents a unique architecture. Слои организованы в три измерения: ширина, высота и глубина.Layers are organized in three dimensions: width, height, and depth. Нейроны на одном уровне соединяются не со всеми нейронами на следующем уровне, но только в небольшой области нейронов слоя.The neurons in one layer connect not to all the neurons in the next layer, but only to a small region of the layer’s neurons. Окончательный результат сокращается до одного вектора показателей вероятности, упорядоченных по измерению глубины.The final output is reduced to a single vector of probability scores, organized along the depth dimension.
Свертки нейронных сетей использовались в таких областях, как распознавание видео, распознавание изображений и системы рекомендаций.Convolutional neural networks have been used in areas such as video recognition, image recognition, and recommender systems.
Дальнейшие действияNext steps
В следующих статьях приведены дополнительные параметры для использования моделей глубокого обучения с открытым кодом в машинное обучение Azure.The following articles show you more options for using open-source deep learning models in Azure Machine Learning:
Машинное обучение и искусственный интеллект
Что такое машинное обучение
Машинное обучение (Machine learning, ML) – свод методов в области искусственного интеллекта, набор алгоритмов, которые применяют, чтобы создать машину, которая учится на собственном опыте. В качестве обучения машина обрабатывает огромные массивы входных данных и находит в них закономерности.
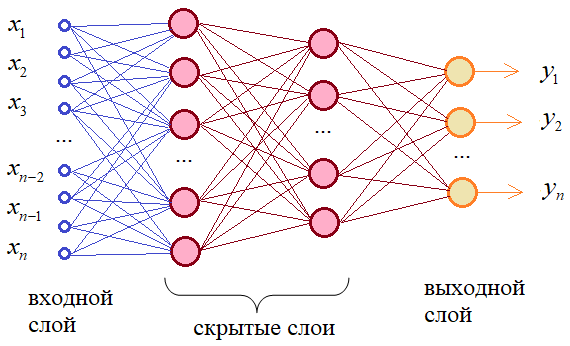
Не стоит путать понятия Data science и Machine learning. Эти инструменты во многом пересекаются, но всё же они разные и каждый со своими задачами. Также в этой статье мы раз и навсегда разберемся, как не смешивать в одну кучу машинное обучение, искусственный интеллект и нейросети.
Искусственный интеллект (Artificial intelligence, AI) – различные технологические и научные решения и методы, которые помогают сделать программы по подобию интеллекта человека. Artificial intelligence включает в себя множество инструментов, алгоритмов и систем, среди которых также все составляющие Data science и Machine learning.
Data science — наука о методах анализа данных и извлечения из них ценной информации, знаний. Она пересекается с такими областями как машинное обучение и наука о мышлении (Cognitive Science), а также с технологиями для работы с большими данными (Big Data).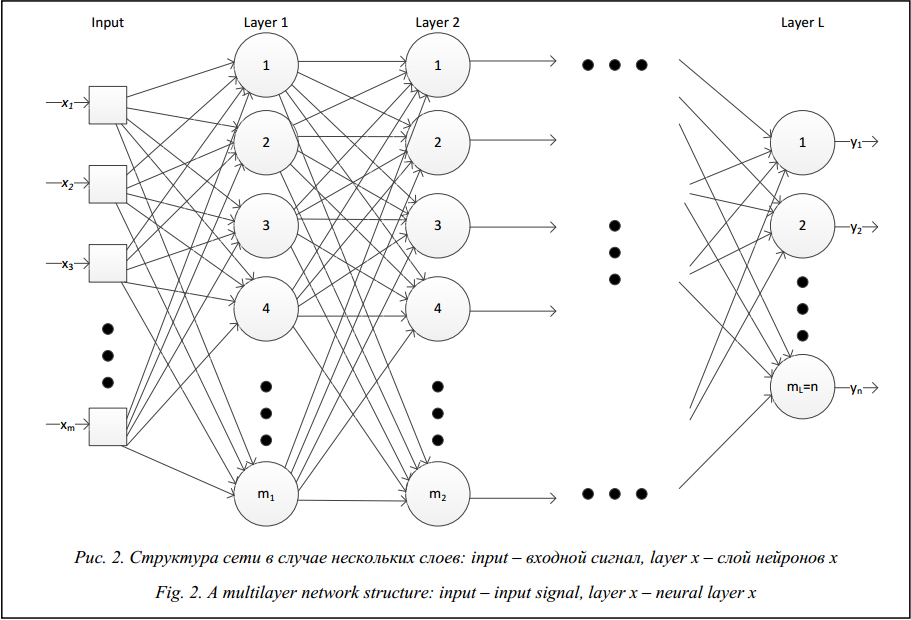 Результатом работы Data science являются проанализированные данные и нахождение правильного подхода для дальнейшей обработки, сортировки, выборки, поиска данных.
Результатом работы Data science являются проанализированные данные и нахождение правильного подхода для дальнейшей обработки, сортировки, выборки, поиска данных.
Например, есть несвязные данные о финансовых операциях затрат предприятия и данные контрагентов. Между собой эти данные связаны исключительно через промежуточные банковские данные или даты и время операций. В результате глубокого машинного анализа можно через промежуточные данные выяснить, какой контрагент является самым затратным.
Машинное обучение или Machine learning – один из разделов AI, алгоритмы, позволяющие компьютеру делать выводы на основании данных, не следуя жестко заданным правилам. То есть, машина может найти закономерность в сложных и многопараметрических задачах (которые мозг человека не может решить), таким образом находя более точные ответы. Как результат – верное прогнозирование.
Нейронная сеть при помощи искусственных нейронов моделирует работу человеческого мозга (нейронов), решающего определенную задачу, самообучается с учетом предыдущего опыта. И с каждым разом совершает все меньше ошибок. Нейросети являются одним из видов машинного обучения, а не отдельным инструментом.
И с каждым разом совершает все меньше ошибок. Нейросети являются одним из видов машинного обучения, а не отдельным инструментом.
Цель машинного обучения и сферы его применения
Цель машинного обучения – частично или даже полностью автоматизировать решение различных сложных аналитических задач.
Поэтому в первую очередь машинное обучение призвано давать максимально точные прогнозы на основании вводных данных, чтобы владельцы бизнесов, маркетологи и сотрудники могли принимать верные решения в своей работе. В результате обучения машина может предсказывать результат, запоминать его, при необходимости воспроизводить, выбирать лучший из нескольких вариантов.
На данный момент машинное обучение охватывает широкий спектр приложений от банков, ресторанов, заправок до роботов на производстве. Новые задачи, возникающие практически ежедневно, приводят к появлению новых направлений машинного обучения.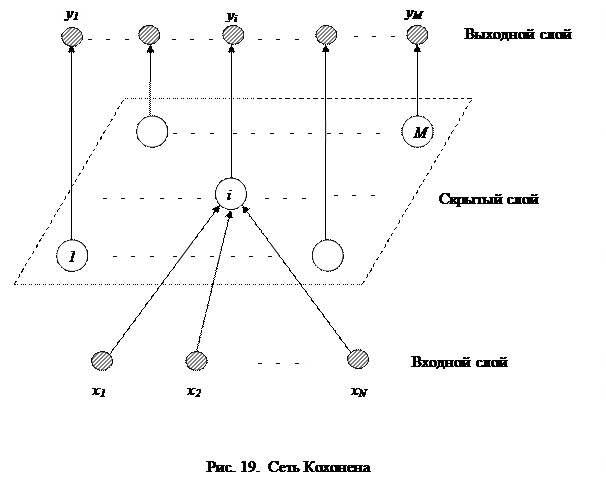
Что нужно для качественного машинного обучения
Машинное обучение строится на трех китах:
А) данные – базовая информация, предоставить которую мы обычно просим клиента. Сюда входят любые выборки данных, работе с которыми нужно обучить систему;
Б) признаки – эта часть работы проводится в тесном сотрудничестве с клиентом. Мы определяем ключевые бизнес-потребности и совместно решаем какие именно характеристики и свойства должна отслеживать система в результате обучения;
В) алгоритм – выбор метода для решения поставленной бизнес-задачи. Эту задачу мы решаем без участия клиента, силами наших сотрудников.
Данные (Data)
Чем больше данных мы загрузим в систему, тем лучше и точнее она будет работать. Сами данные напрямую зависят от задачи, которая стоит перед машиной.
Например, чтобы научить почту отфильтровывать спам от важных писем, необходимы примеры. И чем больше их выборка, тем лучше. Таким образом система учится воспринимать конкретные слова – «Купить», «Дополнительный доход», «Зарабатывай дома», «Деньги», «Кредит», «Увеличение потенции» – как признаки спама и отправлять такие письма в отдельную папку.
И чем больше их выборка, тем лучше. Таким образом система учится воспринимать конкретные слова – «Купить», «Дополнительный доход», «Зарабатывай дома», «Деньги», «Кредит», «Увеличение потенции» – как признаки спама и отправлять такие письма в отдельную папку.
Исходные данные для других задач будут иными. Чтобы советовать покупателю товары, которые могут его заинтересовать, нужна история совершенных им покупок. Чтобы предсказать изменение цен на рынке, нужна история цен.
Самая сложная и одновременно объемная часть работы – сбор этих самых данных. Существует два метода сбора данных: вручную и автоматически. Ручной метод гораздо более медленный, но при этом точный. Автоматический же гораздо более быстрый, но при этом допускает большее количество ошибок.
Хорошая выборка данных дорогого стоит, ведь именно она отвечает за точность прогнозирования, которую вы получите в итоге. Очень важно не ограничивать сбор данных человеческим мышлением, а предоставлять максимум разрозненной информации, поскольку машина может увидеть пользу и взаимосвязи там, где человек их не заметит.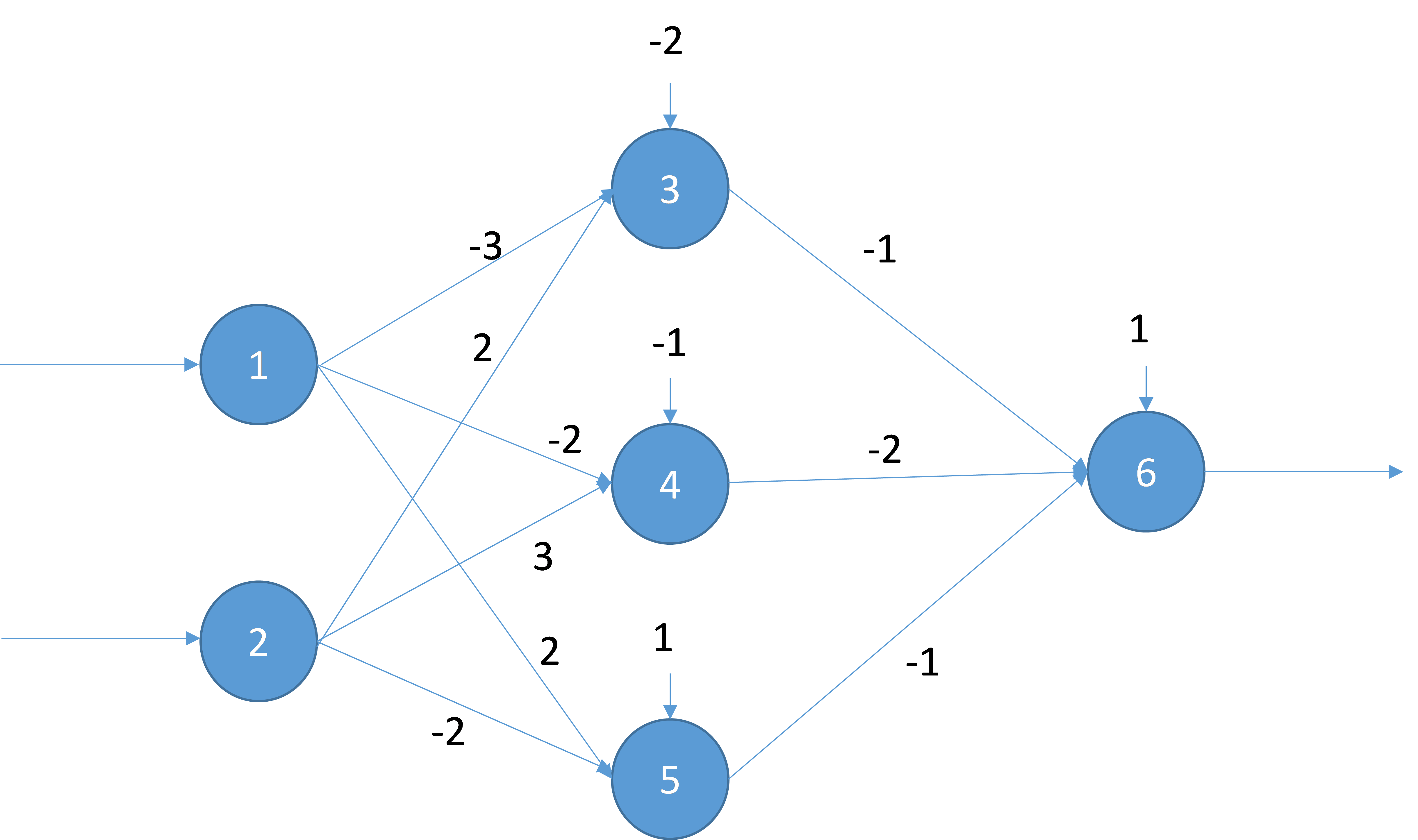
Признаки (свойства, метрики, фичи, характеристики, features).
Например, в случае с автомобилем признаками будут пробег, количество цилиндров, максимально возможная скорость. В случае с покупателем: возраст, пол, образование, уровень дохода и т.д. В случае с животными: порода, рост, длина от кончика хвоста до носа, окрас.
Поскольку правильность свойств напрямую влияет на результат, который вы получите, их отбор занимает зачастую больше времени, чем сам процесс машинного обучения. Здесь главное – не ограничивать набор характеристик, исходя из личного мнения, чтобы не исказить машинное восприятие. А вместе с ним и конечный результат.
Пример датасета, составленного по признакам: https://github.com/php-ai/php-ml/blob/master/data/wine.csv
Эти данные являются результатами химического анализа вин, выращенных в одном регионе в Италии, но полученных из трех разных сортов. Анализ определил 13 компонентов, найденных в каждом из трех типов вин.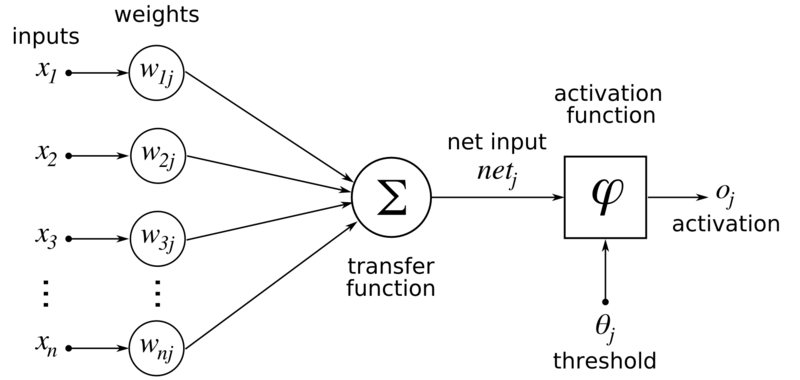 Именно исходя из компонентов вина можно определить его класс.
Именно исходя из компонентов вина можно определить его класс.
Алгоритм (Algorithm)
Система последовательных операций для решения определенной задачи. Иными словами – метод решения. Под каждую конкретную задачу можно подобрать отдельный изящный алгоритм. Именно от выбранного метода напрямую зависит скорость и точность результата обработки исходных данных.
Бывают случаи, когда даже идеально написанные алгоритмы не помогают решать поставленные бизнес-задачи. Например, если вы хотите увеличить количество кросс-продаж на сайте и уверены, что для этого нужно просто улучшить алгоритм рекомендации товаров. Но при этом не знаете, что ваши клиенты приходят по прямым ссылкам из поиска и игнорируют советы по покупке других товаров, показанные на сайте. Поэтому, прежде чем начинать работу, мы определяем реальную причину проблемы клиента. И если она техническая, с удовольствием помогает решить её.
Основные виды машинного обучения
В данной статье мы кратко рассмотрим основные виды машинного обучения, в дальнейшем посвятив каждому из них отдельный развернутый материал.
По признаку наличия учителя, обучение делится на обучение с учителем (Supervised Learning), без учителя (Unsupervised Learning) и с подкреплением (Reinforcement Learning).
— Обучение с учителем применяют когда нужно научить машину распознавать объекты или сигналы. Общий принцип обучения с учителем это “смотри, вот это дверь и это тоже дверь, и вот это тоже дверь”.
— Обучение без учителя использует принцип “эта вещь такая же, как другие”. Алгоритмы изучают сходства и могут обнаружить различие и выполнить обнаружение аномалий, распознавая, что является необычным или несхожим.
— Обучение с подкреплением используют там, где перед машиной стоит задача – правильно выполнить поставленные задачи во внешней среде имея множество возможных вариантов действия. Например, в компьютерных играх, трейдинговых операциях, для беспилотной техники.
По типу применяемых алгоритмов можно выделить два вида:
А) классическое обучение – известные и хорошо изученные алгоритмы обучения, разработанные в основном более 50-ти лет назад для статистических бюро.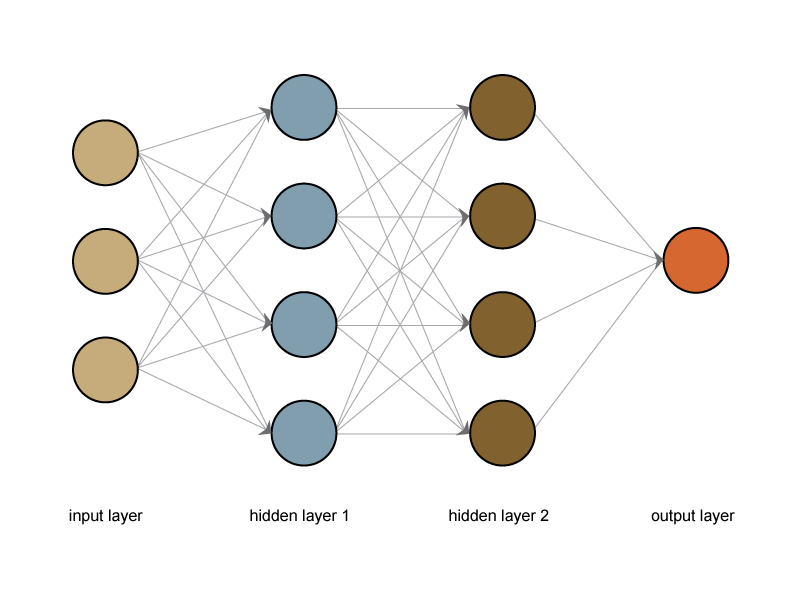 Подходит в первую очередь под задачи работы с данными: классификация, кластеризация, регрессия и т.п. Применяют для прогнозирования, сегментации клиентов и так далее.
Подходит в первую очередь под задачи работы с данными: классификация, кластеризация, регрессия и т.п. Применяют для прогнозирования, сегментации клиентов и так далее.
Б) нейронные сети и глубокое обучение – наиболее современный подход к машинному обучению. Нейронные сети применяются там, где нужны распознавание или генерация изображений и видео, сложные алгоритмы управления или принятия решений, машинный перевод и подобные сложные задачи.
Несколько подходов можно объединить и тогда получатся ансамбли моделей.
Главная польза от машинного обучения
При умелом подходе, комбинируя различные виды машинного обучения, можно добиться автоматизации большинства рутинных бизнес-процессов. Иными словами, алгоритмы и роботы, подготовленные при помощи машинного обучения, могут выполнять всю рутинную работу. Людям же остается вся творческая часть: составление стратегий, ведение переговоров, заключение договоров и прочее. Это важный фактор, поскольку машина не может выйти за заданные ей рамки, а человеческий мозг способен мыслить нешаблонно.
Это важный фактор, поскольку машина не может выйти за заданные ей рамки, а человеческий мозг способен мыслить нешаблонно.
Качественный анализ характеристик машинами подскажет, куда стоит направить больше усилий для привлечения клиентов, а задача людей – продумать стратегию для этих усилий. Хотите узнать, как лучше использовать машинное обучение и искусственный интеллект в целом для решения ваших бизнес-задач? Свяжитесь с нами, подскажем вариант, наиболее подходящий вашему бизнесу.
11.01.2019
Используемые в статье картинки взяты из открытых источников и используются как иллюстрации.Машинное обучение и искусственный интеллект в дивном новом мире
Вопреки антиутопическим результатам, которые некоторые могут себе представить, люди остаются в центре внимания. Настройка и поддержание полезного машинного обучения требует взаимодействия и инсайтов со стороны человека, равно как и валидация выводов ИИ путем проверки их на соответствие новым данным — важный компонент любого развертывания ИИ.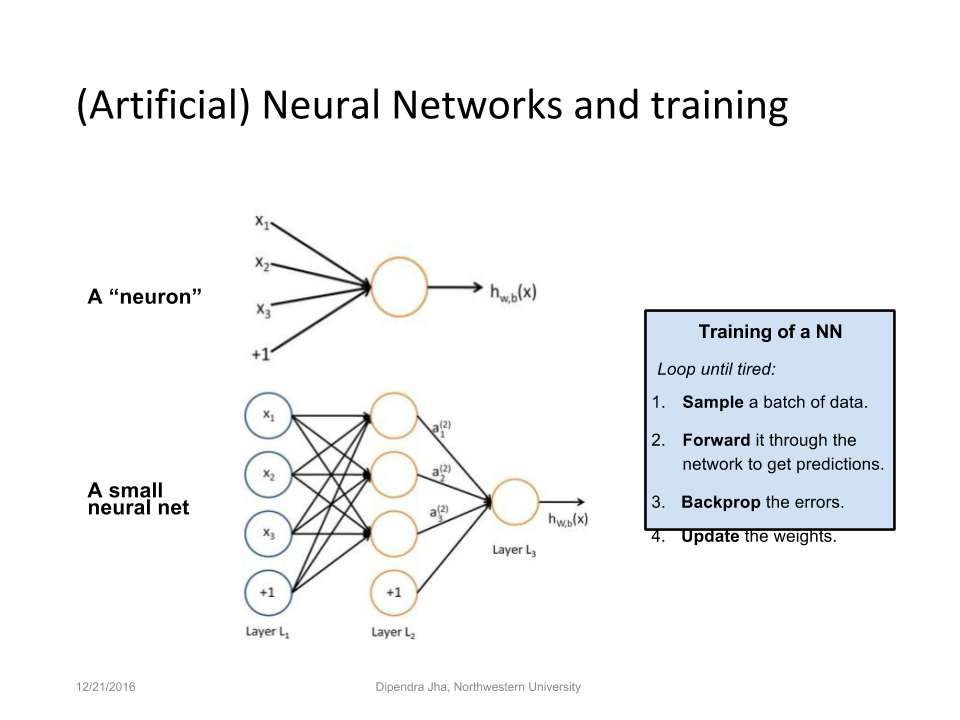 Более того, выбор правильного алгоритма для работы, настройка его для лучшей производительности, уточнение данных, на которых он будет работать, достижение идеального баланса между техническим совершенством машины и ее способностью потреблять данные и интерпретация результатов с пониманием того, что прогнозирование это не то же самое, что причинно-следственная связь — это отчасти наука, отчасти искусство и сила всех людей.
Более того, выбор правильного алгоритма для работы, настройка его для лучшей производительности, уточнение данных, на которых он будет работать, достижение идеального баланса между техническим совершенством машины и ее способностью потреблять данные и интерпретация результатов с пониманием того, что прогнозирование это не то же самое, что причинно-следственная связь — это отчасти наука, отчасти искусство и сила всех людей.
Неудивительно, что, как показали недавние межнациональные опросы клиентов SAS, одна из самых больших проблем, с которой сталкиваются компании в отношении внедрения искусственного интеллекта, заключается в управлении ИИ с помощью человеческого опыта.
«Кто-то захочет присоединиться к модному движению ИИ, потому что это горячая тема, но компании должны определиться, что они хотят с ним делать», — советует Эйнсворт. «К тому же, другие люди все еще негативно воспринимают ИИ из-за того, как его часто изображают так, что это может показаться ошеломляющим. Но во многих случаях эти люди уже используют формы машинного обучения каждый день, когда что-то ищут в интернете, загружают фотографии в социальные сети или совершают покупки в интернете у крупных розничных продавцов. В конечном счете, речь идет об использовании правильного инструмента для правильной работы. ИИ требует стратегии с четко прописанными тактическими шагами для успешного осуществления более крупного плана. ИИ может дать ценные инсайты, но деятельность, связанная с этой информацией, все еще требует человеческого управления».
Но во многих случаях эти люди уже используют формы машинного обучения каждый день, когда что-то ищут в интернете, загружают фотографии в социальные сети или совершают покупки в интернете у крупных розничных продавцов. В конечном счете, речь идет об использовании правильного инструмента для правильной работы. ИИ требует стратегии с четко прописанными тактическими шагами для успешного осуществления более крупного плана. ИИ может дать ценные инсайты, но деятельность, связанная с этой информацией, все еще требует человеческого управления».
Уже ясно, что ИИ настроен на революцию, особенно вероятен переход к автоматизации повторяющихся ручных задач с помощью роботизированного оборудования. ИИ вызовет драматические изменения в культуре. Но это не только повысит производительность — например, выявит проблемы с обслуживанием до того, как они возникнут, либо позволит определить цены в режиме реального времени — но и сэкономит время. ИИ будет работать в фоновом режиме, пока мы будем открыты для инноваций или для решения других задач, требующих человеческого внимания.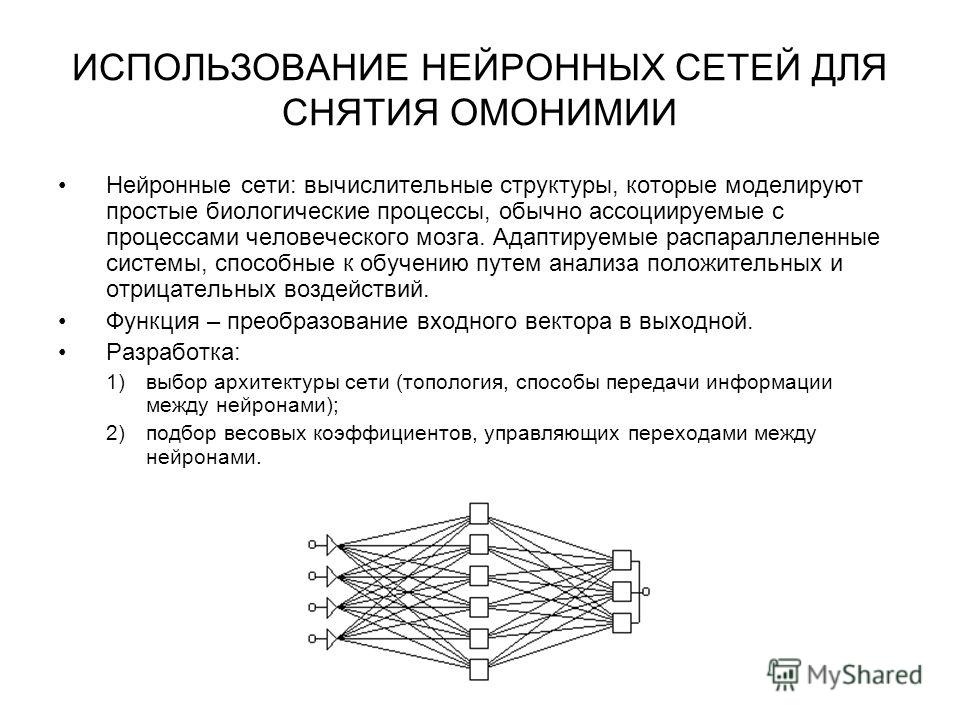 Как распределительные центры Amazon используют робототехнику для отбора товаров, так и люди, которые их упаковывают, коммерция и многие другие сферы жизни станут вопросом командной работы. Человек и машина будут работать вместе.
Как распределительные центры Amazon используют робототехнику для отбора товаров, так и люди, которые их упаковывают, коммерция и многие другие сферы жизни станут вопросом командной работы. Человек и машина будут работать вместе.
AI против машинного обучения против глубокого обучения против нейронных сетей: в чем разница?
Эти термины часто используются как синонимы, но в чем различия, которые делают каждый из них уникальной технологией?
Технологии с каждой минутой все больше внедряются в нашу повседневную жизнь, и, чтобы идти в ногу с ожиданиями потребителей, компании все больше полагаются на алгоритмы обучения, чтобы упростить жизнь.Вы можете увидеть его применение в социальных сетях (через распознавание объектов на фотографиях) или в разговоре напрямую с устройствами (такими как Alexa или Siri).
Эти технологии обычно ассоциируются с искусственным интеллектом, машинным обучением, глубоким обучением и нейронными сетями, и хотя все они играют определенную роль, эти термины, как правило, используются взаимозаменяемо в разговоре, что приводит к некоторой путанице в отношении нюансов между ними. Надеюсь, мы сможем использовать этот пост в блоге, чтобы прояснить здесь некоторую двусмысленность.
Надеюсь, мы сможем использовать этот пост в блоге, чтобы прояснить здесь некоторую двусмысленность.
Как связаны искусственный интеллект, машинное обучение, нейронные сети и глубокое обучение?
Возможно, самый простой способ думать об искусственном интеллекте, машинном обучении, нейронных сетях и глубоком обучении — это думать о них как о русских матрешках. Каждый по сути является составной частью предыдущего термина.
То есть машинное обучение — это подраздел искусственного интеллекта. Глубокое обучение — это подраздел машинного обучения, а нейронные сети составляют основу алгоритмов глубокого обучения.Фактически, именно количество узловых слоев или глубина нейронных сетей отличает одну нейронную сеть от алгоритма глубокого обучения, которого должно быть больше трех.
Что такое нейронная сеть?
Нейронные сети, а точнее искусственные нейронные сети (ИНС), имитируют человеческий мозг с помощью набора алгоритмов. На базовом уровне нейронная сеть состоит из четырех основных компонентов: входов, весов, смещения или порога и выхода. Подобно линейной регрессии, алгебраическая формула будет выглядеть примерно так:
Подобно линейной регрессии, алгебраическая формула будет выглядеть примерно так:
Теперь применим это к более осязаемому примеру, например, следует ли вам заказывать пиццу на ужин.Это будет наш прогнозируемый результат, или y-hat. Предположим, что есть три основных фактора, которые повлияют на ваше решение:
- Если сэкономите время, заказав (Да: 1; Нет: 0)
- Если вы похудеете, заказав пиццу (Да: 1; Нет: 0)
- Если сэкономите (Да: 1; Нет: 0)
Тогда предположим следующее, дав нам следующие входные данные:
- X 1 = 1, так как вы не готовите ужин
- X2 = 0, так как мы получаем ВСЕ начинки
- X 3 = 1, так как мы получаем только 2 фрагмента
Для простоты наши входные данные будут иметь двоичное значение 0 или 1.Технически это определяет его как перцептрон, поскольку нейронные сети в первую очередь используют сигмовидные нейроны, которые представляют значения от отрицательной бесконечности до положительной бесконечности. Это различие важно, поскольку большинство реальных проблем нелинейны, поэтому нам нужны значения, которые уменьшают влияние любого отдельного ввода на результат. Однако такое обобщение поможет вам понять лежащую здесь математику.
Это различие важно, поскольку большинство реальных проблем нелинейны, поэтому нам нужны значения, которые уменьшают влияние любого отдельного ввода на результат. Однако такое обобщение поможет вам понять лежащую здесь математику.
Теперь нам нужно присвоить веса, чтобы определить важность.Большие веса делают вклад одного входа в результат более значительным по сравнению с другими входами.
- W 1 = 5, так как вы цените время
- Вт 2 = 3, так как вы цените форму
- W 3 = 2, так как у вас деньги в банке
Наконец, мы также предположим, что пороговое значение равно 5, что соответствует значению смещения –5.
Поскольку мы установили все соответствующие значения для нашего суммирования, теперь мы можем подставить их в эту формулу.
Теперь, используя следующую функцию активации, мы можем рассчитать выход (т.е. наше решение заказать пиццу):
Итого:
Y-шляпа (наш прогноз) = Решить, заказывать пиццу или нет
Y-шляпа = (1 * 5) + (0 * 3) + (1 * 2) — 5
Y-шляпа = 5 + 0 + 2 — 5
Y-шляпа = 2, что больше нуля.
Поскольку Y-hat равно 2, выход из функции активации будет 1, означает, что мы закажем пиццу (я имею в виду, кто не любит пиццу).
Если выход любого отдельного узла выше указанного порогового значения, этот узел активируется, отправляя данные на следующий уровень сети. В противном случае на следующий уровень сети никакие данные не передаются. Теперь представьте, что описанный выше процесс повторяется несколько раз для одного решения, поскольку нейронные сети, как правило, имеют несколько «скрытых» слоев как часть алгоритмов глубокого обучения. Каждый скрытый слой имеет свою собственную функцию активации, потенциально передавая информацию из предыдущего слоя в следующий.После того, как все выходные данные из скрытых слоев сгенерированы, они используются в качестве входных данных для расчета окончательного выхода нейронной сети.
Основное различие между регрессией и нейронной сетью — это влияние изменения на один вес. В регрессии вы можете изменить вес, не влияя на другие входные данные функции. Однако это не относится к нейронным сетям. Поскольку выходные данные одного уровня передаются на следующий уровень сети, одно изменение может иметь каскадный эффект на другие нейроны в сети.
В регрессии вы можете изменить вес, не влияя на другие входные данные функции. Однако это не относится к нейронным сетям. Поскольку выходные данные одного уровня передаются на следующий уровень сети, одно изменение может иметь каскадный эффект на другие нейроны в сети.
См. Эту статью IBM Developer для более глубокого объяснения количественных концепций, используемых в нейронных сетях.
Чем глубокое обучение отличается от нейронных сетей?
Хотя это подразумевалось в объяснении нейронных сетей, стоит отметить более подробно. «Глубина» в глубоком обучении относится к глубине слоев в нейронной сети. Нейронная сеть, состоящая из более чем трех слоев, включая входные и выходные данные, может считаться алгоритмом глубокого обучения.Обычно это представлено с помощью следующей диаграммы:
Большинство глубоких нейронных сетей имеют прямую связь, то есть они движутся в одном направлении от входа к выходу. Однако вы также можете обучить свою модель с помощью обратного распространения ошибки; то есть двигаться в противоположном направлении от вывода к вводу. Обратное распространение позволяет нам вычислить и приписать ошибку, связанную с каждым нейроном, что позволяет нам соответствующим образом настроить и подогнать алгоритм.
Чем глубокое обучение отличается от машинного обучения?
Как мы объясняем в нашей статье Learn Hub о глубоком обучении, глубокое обучение — это просто подмножество машинного обучения.Они отличаются тем, как обучается каждый алгоритм.
Классическое, или «неглубокое», машинное обучение зависит от вмешательства человека для обучения, поэтому для понимания различий между входными данными требуются помеченные наборы данных. Например, если бы я показал вам серию изображений различных типов фаст-фуда, я бы пометил каждое изображение типом фаст-фуда, таким как «пицца», «бургер» или «тако». Модель машинного обучения будет обучаться и учиться на основе введенных в нее помеченных данных, что также известно как контролируемое обучение.
«Глубокое» машинное обучение может использовать помеченные наборы данных для информирования своего алгоритма, но для этого необязательно наличие помеченного набора данных; вместо этого он также может использовать обучение без учителя для самообучения. В то время как контролируемое обучение использует помеченные данные, в неконтролируемом обучении используются неструктурированные или немаркированные данные.
В то время как контролируемое обучение использует помеченные данные, в неконтролируемом обучении используются неструктурированные или немаркированные данные.
Наблюдая закономерности в данных, модель машинного обучения может кластеризовать и классифицировать входные данные. Взяв тот же пример из предыдущего, мы могли сгруппировать изображения пиццы, гамбургеров и тако по соответствующим категориям на основе сходства, выявленного на изображениях.С учетом сказанного, модели глубокого обучения потребуется больше точек данных для повышения ее точности, тогда как модель машинного обучения опирается на меньшее количество данных с учетом базовой структуры данных. Глубокое обучение в первую очередь используется для более сложных случаев использования, таких как виртуальные помощники или обнаружение мошенничества.
Чем машинное обучение отличается от искусственного интеллекта (ИИ)?
Наконец, искусственный интеллект (ИИ) — это самый широкий термин, используемый для классификации машин, имитирующих человеческий интеллект.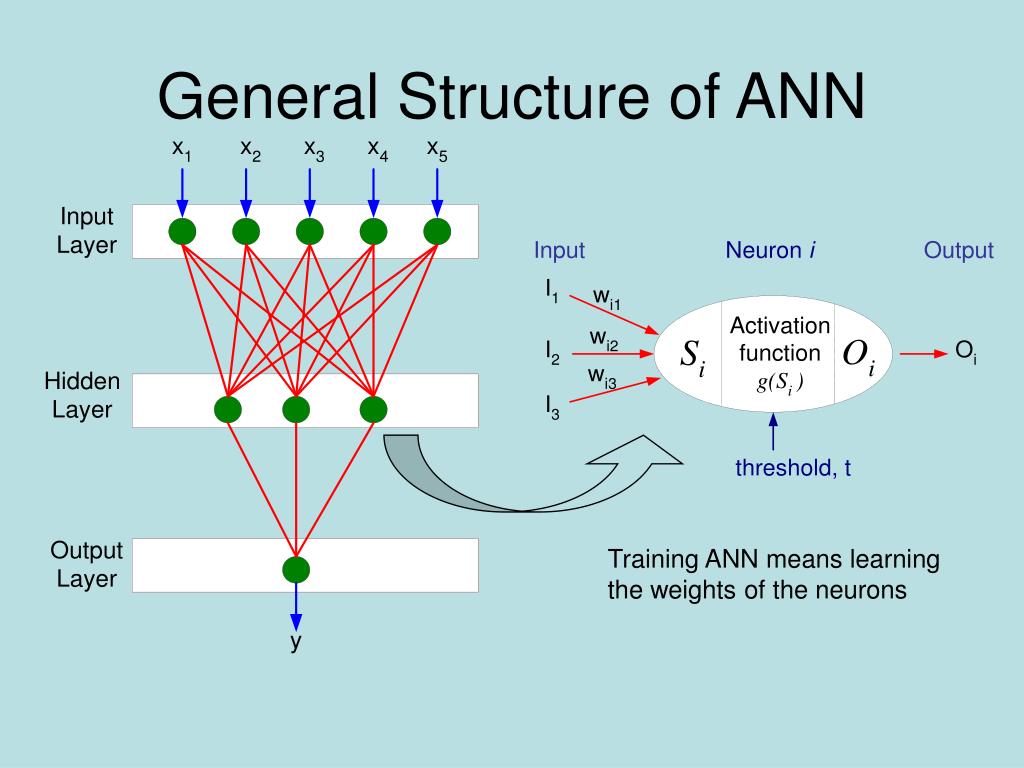 Он используется для прогнозирования, автоматизации и оптимизации задач, которые люди исторически выполняли, таких как распознавание речи и лиц, принятие решений и перевод.
Он используется для прогнозирования, автоматизации и оптимизации задач, которые люди исторически выполняли, таких как распознавание речи и лиц, принятие решений и перевод.
Существует три основных категории AI:
- Искусственный узкий интеллект (ANI)
- Общий искусственный интеллект (AGI)
- Искусственный супер интеллект (ASI)
ANI считается «слабым» AI, тогда как два других типа классифицируются как «сильные» AI.Слабый ИИ определяется его способностью выполнять очень конкретную задачу, например, выиграть в шахматы или идентифицировать конкретного человека на серии фотографий. По мере того, как мы переходим к более сильным формам ИИ, таким как AGI и ASI, становится более заметным включение большего количества человеческих форм поведения, таких как способность интерпретировать тон и эмоции. Чат-боты и виртуальные помощники, такие как Siri, лишь поверхностно относятся к этому, но они по-прежнему являются примерами ANI.
Сильный ИИ определяется его способностями по сравнению с людьми.Общий искусственный интеллект (AGI) будет работать наравне с другим человеком, в то время как искусственный суперинтеллект (ASI), также известный как суперинтеллект, превзойдет человеческий интеллект и способности. Поскольку эта область ИИ все еще быстро развивается, лучший пример того, как это могло бы выглядеть, — это Долорес из сериала HBO Westworld .
Управляйте своими данными для AI
Хотя все эти области ИИ могут помочь оптимизировать области вашего бизнеса и улучшить качество обслуживания клиентов, достижение целей ИИ может быть сложной задачей, потому что вам сначала нужно убедиться, что у вас есть правильные системы для управления данными для построения алгоритмы обучения.Управление данными, пожалуй, сложнее, чем создание реальных моделей, которые вы будете использовать для своего бизнеса. Вам понадобится место для хранения ваших данных и механизмы их очистки и контроля предвзятости, прежде чем вы сможете начать что-либо создавать. Ознакомьтесь с некоторыми предложениями продуктов IBM, которые помогут вам и вашему бизнесу встать на правильный путь для подготовки и масштабного управления данными.
Ознакомьтесь с некоторыми предложениями продуктов IBM, которые помогут вам и вашему бизнесу встать на правильный путь для подготовки и масштабного управления данными.
Что такое нейронная сеть?
Сверточные нейронные сетиСверточные нейронные сети (CNN) часто используются для задач распознавания и классификации изображений.
Например, предположим, что у вас есть набор фотографий, и вы хотите определить, присутствует ли кошка на каждом изображении. CNN обрабатывают изображения с нуля. Нейроны, расположенные ранее в сети, отвечают за изучение небольших окон пикселей и обнаружение простых мелких деталей, таких как края и углы. Эти выходные данные затем передаются в нейроны в промежуточных слоях, которые ищут более крупные особенности, такие как усы, носы и уши. Этот второй набор выходных данных используется для окончательного решения о том, есть ли на изображении кошка.
Сети CNN настолько революционны, потому что снимают задачу локализованного извлечения функций из рук людей. Перед использованием CNN исследователям часто приходилось вручную решать, какие характеристики изображения были наиболее важными для обнаружения кошки. Однако нейронные сети могут создавать эти представления функций автоматически, определяя для себя, какие части изображения являются наиболее значимыми.
Перед использованием CNN исследователям часто приходилось вручную решать, какие характеристики изображения были наиболее важными для обнаружения кошки. Однако нейронные сети могут создавать эти представления функций автоматически, определяя для себя, какие части изображения являются наиболее значимыми.
В то время как CNN хорошо подходят для работы с данными изображений, рекуррентные нейронные сети (RNN) являются сильным выбором для построения последовательных представлений данных с течением времени: таких задач, как распознавание рукописного ввода и распознавание голоса.
Так же, как вы не можете обнаружить кошку, глядя на один пиксель, вы не можете распознать текст или речь, глядя на одну букву или слог. Чтобы понимать естественный язык, вам необходимо понимать не только текущую букву или слог, но и их контекст.
RNN способны «запоминать» прошлые выходные данные сети и использовать эти результаты в качестве входных данных для последующих вычислений.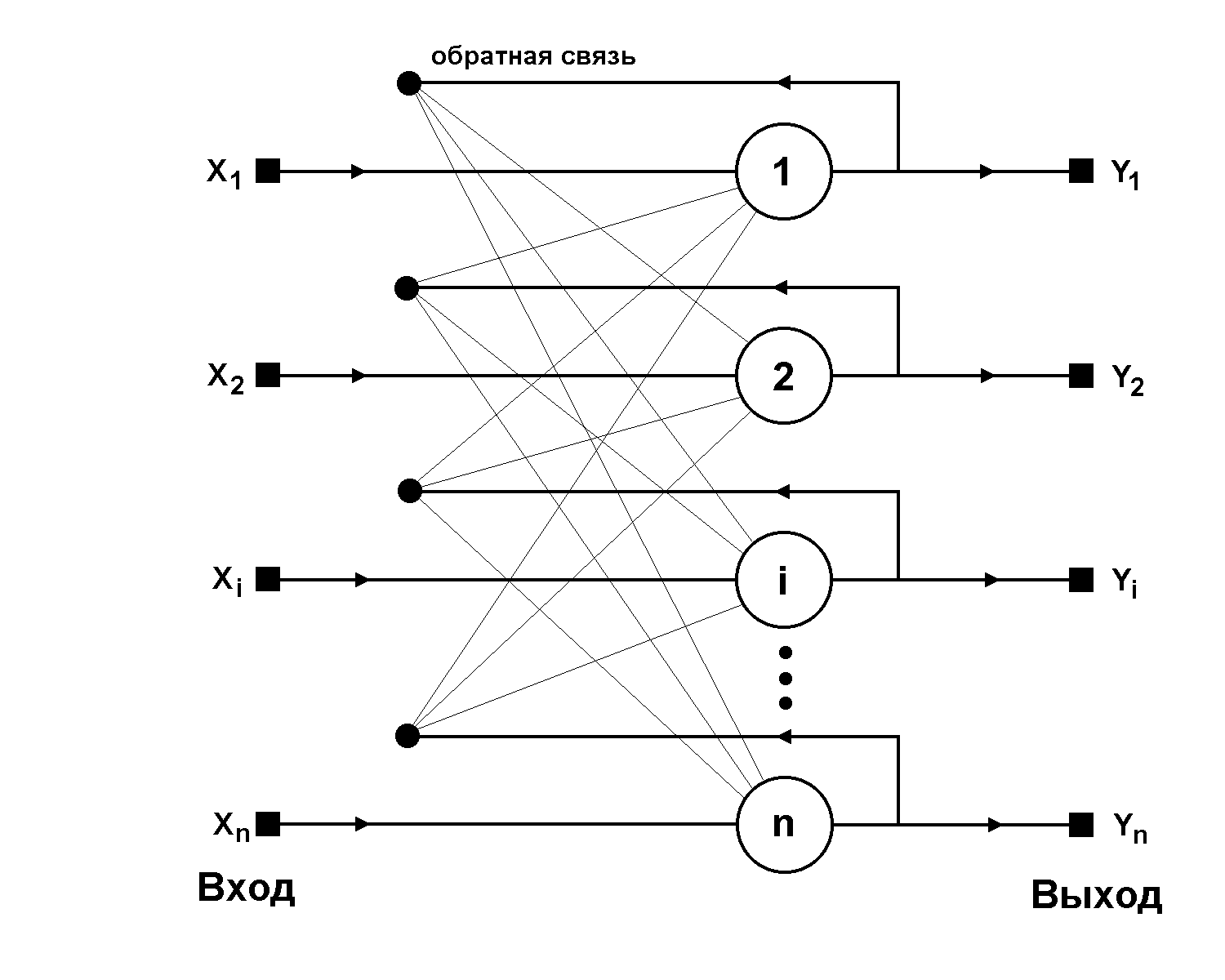 Включая петли как часть сетевой модели, информация из предыдущих шагов может сохраняться с течением времени, помогая сети принимать более разумные решения.Единицы долговременной памяти (LSTM) или стробированные повторяющиеся единицы (GRU) могут быть добавлены к RNN, чтобы позволить ей запоминать важные детали и забывать несущественные.
Включая петли как часть сетевой модели, информация из предыдущих шагов может сохраняться с течением времени, помогая сети принимать более разумные решения.Единицы долговременной памяти (LSTM) или стробированные повторяющиеся единицы (GRU) могут быть добавлены к RNN, чтобы позволить ей запоминать важные детали и забывать несущественные.
Исторический контекст
Все это может показаться современным, но оно уходит в прошлое. Консультанты по большим данным Бернард Марр и Import.io, среди многих других, собрали историю нейронных сетей и глубокого обучения. Вот краткий обзор:
- В 1943 году логик Уолтер Питтс и нейробиолог Уоррен Маккалок создали модель нейронной сети.Они предложили комбинацию математики и алгоритмов, которая была направлена на отражение человеческих мыслительных процессов. Модель, получившая название нейронов Мак-Каллоха-Питтса, конечно, эволюционировала, но остается стандартной.
- В 1980 году Кунихико Фукусима предложил Neoconitron, иерархическую, многоуровневую, искусственную нейронную сеть, используемую для распознавания почерка и других задач распознавания образов.

- В середине 2000-х термин «глубокое обучение» получил распространение после того, как статьи Джеффри Хинтона, Руслана Салахутдинова и других показали, как нейронные сети могут быть предварительно обучены слоем за раз.
- В 2015 году Facebook внедрил DeepFace для автоматической пометки и идентификации пользователей на фотографиях.
- В 2016 году программа AlphaGo от Google обошла одного из лучших игроков в го со всего мира.
Игры, особенно стратегии, были отличным способом протестировать и / или продемонстрировать возможности нейронных сетей. Но есть множество более практичных приложений.
Реальные приложения «Для компаний, стремящихся спрогнозировать модели пользователей или рост инвестиций, возможность мобилизации искусственного интеллекта может сэкономить рабочую силу и защитить инвестиции.Для потребителей, пытающихся понять окружающий мир, ИИ может выявить модели человеческого поведения и помочь изменить наш выбор », — пишет Теренс Миллс, генеральный директор AI.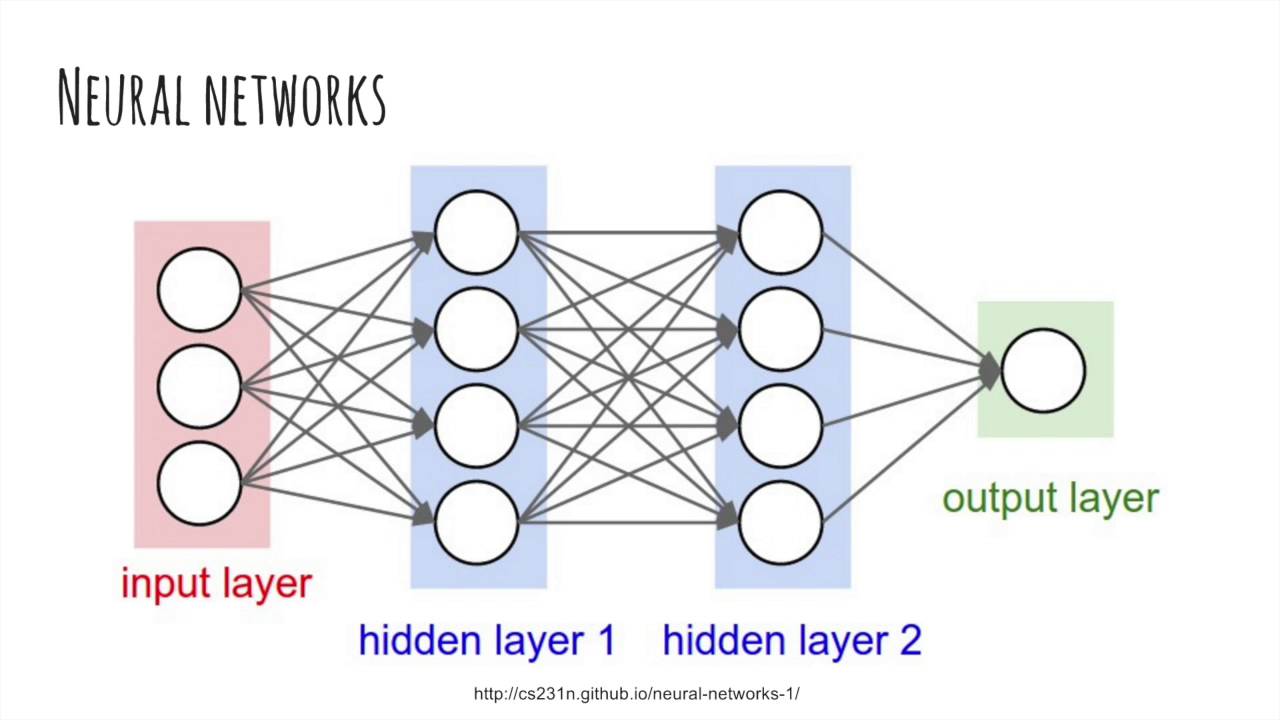 io и Moonshot в статье для Forbes .
io и Moonshot в статье для Forbes .
Применения искусственного интеллекта очень разнообразны. Некоторые из самых интересных — в сфере здравоохранения:
- Исследования 2016 года показывают, что системы с машинным обучением нейронных сетей могут помочь в принятии решений при планировании ортодонтического лечения.
- В исследовательской статье, опубликованной в 2012 году, обсуждаются системы диагностики опухолей головного мозга на основе нейронных сетей.
- PAPNET, разработанный в 1990-х годах, до сих пор используется для выявления рака шейки матки. Из исследовательской работы 1994 года: «Система цитологического скрининга PAPNET использует нейронные сети для автоматического анализа обычных мазков путем обнаружения и распознавания потенциально аномальных клеток».
Многие интересные бизнес-приложения используют глубокие нейронные сети для классификации изображений: нейронная сеть может идентифицировать и различать отношения между изображениями, помещая каждое в соответствующую категорию.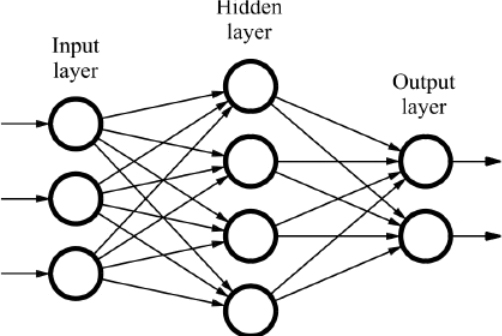 По словам Миллса в своей колонке Forbes, последствия для бизнеса огромны. «Программное обеспечение может сканировать данную сеть в поисках экземпляров ваших продуктов. Вы можете выяснить, носила ли знаменитость созданное вами украшение. Вы даже можете увидеть, фигурировало ли ваше кафе в каких-либо кадрах шоу, сделанных в вашем районе ».
По словам Миллса в своей колонке Forbes, последствия для бизнеса огромны. «Программное обеспечение может сканировать данную сеть в поисках экземпляров ваших продуктов. Вы можете выяснить, носила ли знаменитость созданное вами украшение. Вы даже можете увидеть, фигурировало ли ваше кафе в каких-либо кадрах шоу, сделанных в вашем районе ».
Если вы посмотрели слишком много фильмов-антиутопий, возможно, вы начали беспокоиться. Вам, вероятно, и не нужно. Как объясняет Марр,
«Глубокое обучение обещает не то, что компьютеры начнут думать как люди.Это все равно что просить яблоко стать апельсином. Скорее, он демонстрирует, что при наличии достаточно большого набора данных, достаточно быстрых процессоров и достаточно сложного алгоритма компьютеры могут начать выполнять задачи, которые раньше полностью оставались в сфере человеческого восприятия — например, распознавание видео с кошками в сети (и другие, возможно, более полезные цели) ».
Если вы хотите узнать больше о теории, лежащей в основе нейронных сетей, эта серия видеороликов представляет собой фантастический обзор. Coursera также предлагает серию лекций через YouTube, а простой поиск в Google даст десятки других видео и курсов.
Coursera также предлагает серию лекций через YouTube, а простой поиск в Google даст десятки других видео и курсов.
А нас? Мы взволнованы возможностями — и рады, что HAL не входит в их число. А если вы хотите узнать больше о том, кто «мы», просто напишите нам!
Машинное обучение для начинающих: введение в нейронные сети | Виктор Чжоу
Простое объяснение того, как они работают и как реализовать их с нуля на Python.
Вот кое-что, что может вас удивить: нейронные сети не такие уж сложные! Термин «нейронная сеть» часто используется как модное слово, но на самом деле они часто намного проще, чем люди думают.
Этот пост предназначен для начинающих и предполагает НУЛЕВОЕ предварительное знание машинного обучения . Мы поймем, как работают нейронные сети, реализуя одну с нуля на Python.
Приступим!
Примечание: рекомендую прочитать этот пост о Викторчжоу.
com — большая часть форматирования в этом посте выглядит там лучше.
Во-первых, мы должны поговорить о нейронах, основной единице нейронной сети. Нейрон принимает входные данные, выполняет с ними некоторые вычисления и выдает один выход . Вот как выглядит нейрон с двумя входами:
Здесь происходит 3 вещи. Сначала каждый вход умножается на вес:
Затем все взвешенные входы складываются вместе со смещением b:
Наконец, сумма проходит через функцию активации:
Функция активации используется для включения неограниченного ввод в вывод, который имеет приятную предсказуемую форму.Часто используемой функцией активации является сигмоидальная функция:
Сигмоидальная функция выводит только числа в диапазоне (0,1). Вы можете думать об этом как о сжатии (−∞, + ∞) до (0,1) — большие отрицательные числа становятся ~ 0, а большие положительные числа становятся ~ 1.
Напоминание: большая часть форматирования в этой статье выглядит лучше в исходной публикации на victorzhou.
com.
Предположим, у нас есть нейрон с двумя входами, который использует сигмовидную функцию активации и имеет следующие параметры:
w = [0, 1] — это просто способ записи w 1 = 0, w 2 = 1 в векторной форме.Теперь давайте введем нейрону x = [2, 3]. Мы воспользуемся скалярным произведением, чтобы писать более кратко:
Нейрон выдает 0,999 при входных данных x = [2,3]. Вот и все! Этот процесс передачи входных данных вперед для получения выходных данных известен как с прямой связью .
Пора реализовать нейрон! Мы воспользуемся NumPy, популярной и мощной вычислительной библиотекой для Python, чтобы помочь нам в вычислениях:
Распознать эти числа? Это тот пример, который мы только что сделали! Получаем тот же ответ 0.999.
Нейронная сеть — это не что иное, как связка нейронов, соединенных вместе. Вот как может выглядеть простая нейронная сеть:
Эта сеть имеет 2 входа, скрытый слой с 2 нейронами ( h 1 и h 2) и выходной слой с 1 нейроном ( o 1 ). Обратите внимание, что входы для o 1 — это выходы из h 1 и h 2 — вот что делает эту сеть.
Обратите внимание, что входы для o 1 — это выходы из h 1 и h 2 — вот что делает эту сеть.
Скрытый слой — это любой слой между входным (первым) и выходным (последним) слоями.Может быть несколько скрытых слоев!
Давайте воспользуемся схемой, изображенной выше, и предположим, что все нейроны имеют одинаковые веса w = [0,1], одинаковое смещение b = 0 и одинаковую сигмовидную функцию активации. Пусть h 1, h 2, o 1 обозначают выходов нейронов, которые они представляют.
Что произойдет, если мы передадим на вход x = [2, 3]?
Выход нейронной сети для входа x = [2,3] равен 0.7216. Довольно просто, правда?
Нейронная сеть может иметь любое количество слоев с любым количеством нейронов в этих слоях. Основная идея остается прежней: направить вход (ы) вперед через нейроны в сети, чтобы получить выход (ы) в конце.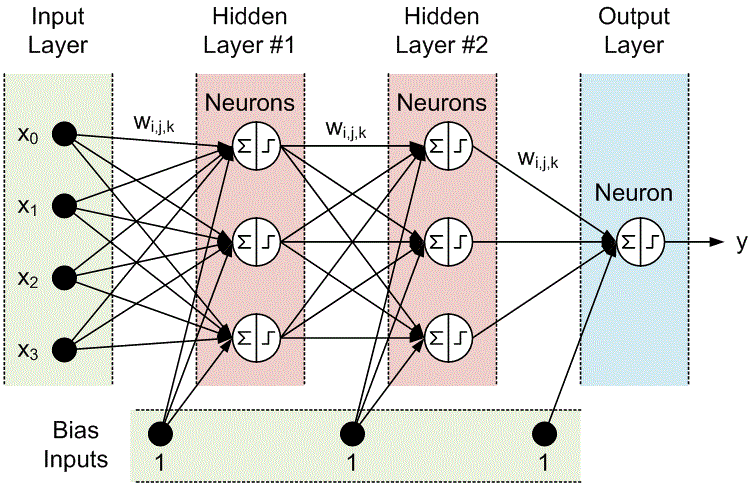 Для простоты мы продолжим использовать сеть, изображенную выше, до конца этой публикации.
Для простоты мы продолжим использовать сеть, изображенную выше, до конца этой публикации.
Давайте реализуем прямую связь для нашей нейронной сети. Вот снова изображение сети для справки:
Мы получили 0.7216 снова! Похоже, это работает.
Предположим, у нас есть следующие измерения:
Давайте обучим нашу сеть предсказанию чьего-либо пола с учетом его веса и роста:
Мы представим мужчину с помощью 0 и женщину с 1, а также перенесем данные в упростить использование:
Перед тем, как обучать нашу сеть, нам сначала нужен способ количественно оценить, насколько она «хороша», чтобы она могла попытаться сделать «лучше». Вот что такое потеря .
Мы будем использовать среднеквадратичную ошибку (MSE) потеря:
Давайте разберем это:
- n — это количество выборок, равное 4 (Алиса, Боб, Чарли, Диана).
- y представляет прогнозируемую переменную, т. Е. Пол.
- y_true — это истинное значение переменной («правильный ответ»).
 Например, y_true для Алисы будет 1 (женщина).
Например, y_true для Алисы будет 1 (женщина). - y_pred — это предсказанное значение переменной. Это то, что выводит наша сеть.
( y_true — y_pred ) ² известна как ошибка квадрата . Наша функция потерь просто берет среднее значение по всем квадратам ошибок (отсюда и название означает ошибку в квадрате ).Чем лучше наши прогнозы, тем меньше будут наши потери!
Лучшие прогнозы = меньшие убытки.
Обучение сети = попытка минимизировать ее потери.
Допустим, наша сеть всегда выводит 00 — другими словами, она уверена, что все люди — мужчины 🤔. Какой была бы наша потеря?
Код: MSE Loss
Вот код для расчета потерь для нас:
Если вы не понимаете, почему этот код работает, прочтите краткое руководство NumPy по операциям с массивами.Ницца.Вперед!
Нравится этот пост? Я пишу много статей по ML для начинающих.
Подпишитесь на мою рассылку, чтобы получать их в свой почтовый ящик!
Теперь у нас есть четкая цель: минимизировать потери нейронной сети. Мы знаем, что можем изменить веса и смещения сети, чтобы повлиять на ее прогнозы, но как это сделать, чтобы уменьшить потери?
В этом разделе используется немного многомерного исчисления. Если вас не устраивает математический анализ, не стесняйтесь пропускать математические части.
Для простоты представим, что в нашем наборе данных есть только Алиса:
Тогда среднеквадратичная потеря ошибки — это просто квадрат ошибки Алисы:
Еще один способ думать о потерях — это как функция весов и смещений. Обозначим каждый вес и смещение в нашей сети:
Затем мы можем записать потери как многопараметрическую функцию:
Представьте, что мы хотели настроить на 1. Как изменились бы потери L , если бы мы изменили на 1? На этот вопрос может ответить частная производная. Как рассчитать?
Как рассчитать?
Вот где математика начинает усложняться. Не расстраивайтесь! Я рекомендую взять ручку и бумагу, чтобы следить по тексту — это поможет вам понять.
Если у вас возникли проблемы с чтением этого: форматирование для приведенной ниже математики выглядит лучше в исходном сообщении на victorzhou.com.
Для начала давайте перепишем частную производную в терминах ∂ y_pred / ∂ w 1 вместо:
Это работает из-за правила цепочки.Мы можем вычислить ∂ L / ∂ y_pred , потому что мы вычислили L = (1− y_pred ) ² выше:
Теперь давайте разберемся, что делать с ∂ y_pred / ∂ w 1. Как и раньше, пусть h 1, h 2, o 1 будут выходами нейронов, которые они представляют. Тогда
f — это функция активации сигмовидной кишки, помните?Поскольку w 1 влияет только на h 1 (не h 2), мы можем написать
More Chain Rule.
Мы делаем то же самое для ∂ h 1 / ∂ w 1:
Как вы уже догадались, правило цепочки.x 1 здесь вес, а x 2 высота. Это уже второй раз, когда мы видим f ′ ( x ) (производное сигмовидной функции)! Получим это:
Мы будем использовать эту красивую форму для f ′ ( x ) позже.
Готово! Нам удалось разбить ∂ L / ∂ w 1 на несколько частей, которые мы можем вычислить:
Эта система вычисления частных производных путем работы в обратном направлении известна как обратное распространение , или «обратное распространение».
Уф. Это было много символов — ничего страшного, если вы еще немного запутались. Давайте рассмотрим пример, чтобы увидеть это в действии!
Мы продолжим делать вид, будто в нашем наборе данных присутствует только Алиса:
Давайте инициализируем все веса до 1 и все смещения до 0. Если мы сделаем прямой проход через сеть, мы получим:
Сетевые выходы y_pred = 0,524, что не сильно способствует мужскому (0) или женскому (1). Рассчитаем ∂ L / ∂ w 1:
Рассчитаем ∂ L / ∂ w 1:
Напоминание: мы вывели f ′ ( x ) = f ( x ) ∗ (1− f ( x ) )) для нашей сигмовидной функции активации ранее.
Мы сделали это! Это говорит нам, что если бы мы увеличили w 1, L в результате увеличили бы tiiiny bit.
Теперь у нас есть все необходимые инструменты для обучения нейронной сети! Мы будем использовать алгоритм оптимизации, называемый стохастическим градиентным спуском (SGD), который сообщает нам, как изменить наши веса и смещения, чтобы минимизировать потери. По сути, это просто уравнение обновления:
η — это константа, называемая скоростью обучения , которая определяет, насколько быстро мы тренируемся.Все, что мы делаем, это вычитаем η ∂ w 1 / ∂ L из w 1:
- Если ∂ L / ∂ w 1 положительно, w 1 уменьшится, что составит уменьшение L .
- Если ∂ L / ∂ w 1 отрицательно, w 1 увеличится, что приведет к уменьшению L .
Если мы сделаем это для каждого веса и смещения в сети, потери будут медленно уменьшаться, а наша сеть улучшится.
Наш процесс обучения будет выглядеть так:
- Выберите один образец из нашего набора данных. Это то, что делает его стохастическим градиентным спуском — мы работаем только с одним образцом за раз.
- Рассчитайте все частные производные потерь по весам или смещениям (например, ∂ L / ∂ w 1, ∂ L / ∂ w 2 и т. Д.).
- Используйте уравнение обновления для обновления каждого веса и смещения.
- Вернитесь к шагу 1.
Давайте посмотрим на это в действии!
Пришло время , наконец, , пора реализовать полную нейронную сеть:
Вы можете запускать / играть с этим кодом самостоятельно.
Он также доступен на Github.
Наши потери неуклонно сокращаются по мере того, как сеть учится:
Теперь мы можем использовать сеть для прогнозирования пола:
Вы сделали это! Краткий обзор того, что мы сделали:
- Представлено нейронов , строительных блоков нейронных сетей.
- Используется сигмовидная активационная функция в наших нейронах.
- Видел, что нейронные сети — это просто нейроны, соединенные вместе.
- Создан набор данных с весом и ростом в качестве входных данных (или с характеристиками ) и полом в качестве выходных данных (или метка ).
- Узнал о функциях потерь и среднеквадратичной ошибке (MSE) потерь.
- Понятно, что обучение сети сводит к минимуму ее потери.
- Используется обратного распространения ошибки для вычисления частных производных.
- Использовал стохастический градиентный спуск (SGD) для обучения нашей сети.
Еще многое предстоит сделать:
Я могу писать на эти или похожие темы в будущем, поэтому подпишитесь, если вы хотите получать уведомления о новых сообщениях.
Спасибо за чтение!
Нежное введение в нейронные сети для машинного обучения
Зачем нам машинное обучение?Нам нужно машинное обучение для задач, которые слишком сложны для непосредственного кодирования людьми, т.е.е. задачи, которые настолько сложны, что для нас непрактично, если не невозможно, проработать все нюансы и явно написать для них код. Поэтому вместо этого мы предоставляем алгоритм машинного обучения с большим объемом данных и позволяем ему исследовать и искать модель, которая будет определять то, что программисты намеревались достичь.
Давайте посмотрим на эти два примера:
- Очень сложно писать программы, которые решают такие проблемы, как распознавание 3D-объекта с новой точки зрения, в новых условиях освещения, в загроможденной сцене.
 Мы не знаем, какую программу написать, потому что не знаем, как это делается в нашем мозгу. Даже если бы у нас была хорошая идея, как это сделать, программа могла бы быть ужасно сложной.
Мы не знаем, какую программу написать, потому что не знаем, как это делается в нашем мозгу. Даже если бы у нас была хорошая идея, как это сделать, программа могла бы быть ужасно сложной. - Трудно написать программу для вычисления вероятности мошенничества при транзакции по кредитной карте. Не может быть правил, которые были бы одновременно простыми и надежными. Нам нужно объединить очень большое количество слабых правил. Мошенничество — подвижная цель, но программа должна постоянно меняться.
Затем идет Подход к машинному обучению : вместо того, чтобы писать программу вручную для каждой конкретной задачи, мы собираем множество примеров, которые указывают правильный вывод для данного ввода.Затем алгоритм машинного обучения берет эти примеры и создает программу, которая выполняет эту работу. Программа, созданная с помощью алгоритма обучения, может сильно отличаться от типичной рукописной программы — она может содержать миллионы чисел. Если мы все сделаем правильно, программа работает как для новых случаев, так и для тех, на которых мы ее обучали.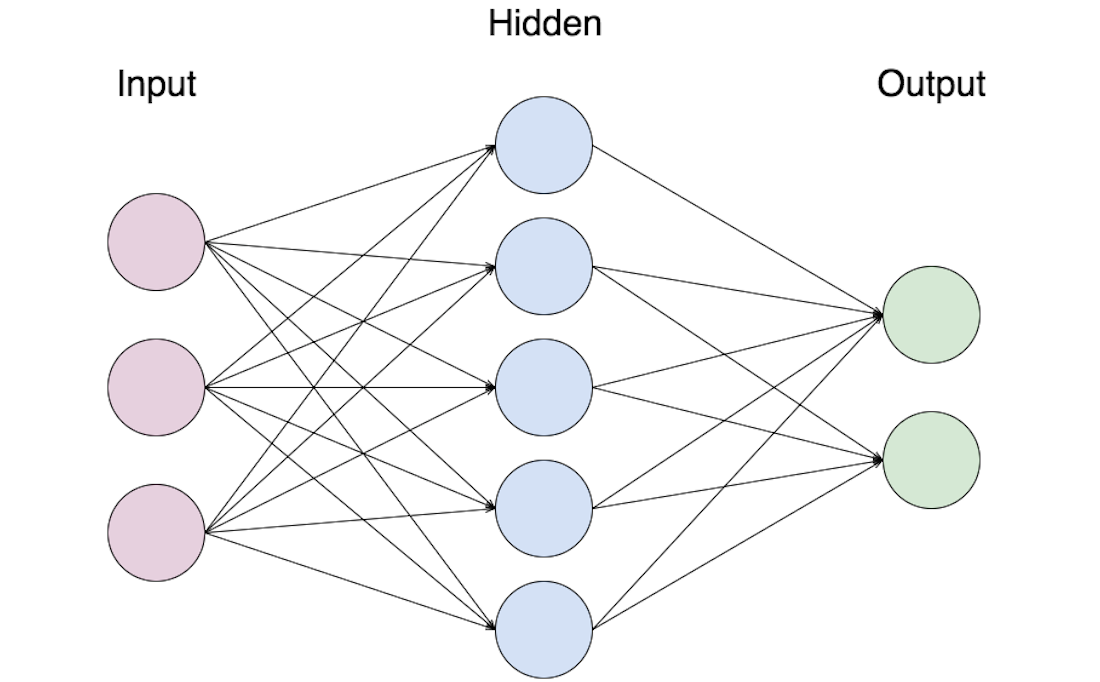 Если данные изменяются, программа также может измениться, обучаясь на новых данных. Вы должны отметить, что выполнение огромных объемов вычислений теперь дешевле, чем платить кому-то за написание программы для конкретной задачи.
Если данные изменяются, программа также может измениться, обучаясь на новых данных. Вы должны отметить, что выполнение огромных объемов вычислений теперь дешевле, чем платить кому-то за написание программы для конкретной задачи.
Вот несколько примеров задач, которые лучше всего решает машинное обучение:
- Распознавание образов: объекты в реальных сценах, лица или выражения лица и / или произнесенные слова
- Распознавание аномалий: необычная последовательность операций с кредитными картами, необычные схемы показаний датчиков на атомной электростанции
- Прогноз: будущие цены на акции или курсы валют, какие фильмы понравятся человеку
Что такое нейронные сети?
Нейронные сети — это класс моделей в общей литературе по машинному обучению.Нейронные сети — это особый набор алгоритмов, которые произвели революцию в машинном обучении. Они вдохновлены биологическими нейронными сетями, и нынешние так называемые глубокие нейронные сети доказали свою эффективность. Нейронные сети сами по себе являются приближениями общих функций, поэтому их можно применять практически к любой задаче машинного обучения, касающейся изучения сложного сопоставления входного и выходного пространства.
Нейронные сети сами по себе являются приближениями общих функций, поэтому их можно применять практически к любой задаче машинного обучения, касающейся изучения сложного сопоставления входного и выходного пространства.
Вот три причины, по которым вы должны изучать нейронные вычисления:
- Чтобы понять, как на самом деле работает мозг: он очень большой и очень сложный и сделан из материала, который умирает, когда вы его ткните, поэтому нам нужно использовать компьютерное моделирование.
- Чтобы понять стиль параллельных вычислений, вдохновленный нейронами и их адаптивными связями: это совсем другой стиль, чем последовательные вычисления.
- Для решения практических задач с помощью новых алгоритмов обучения, вдохновленных мозгом: алгоритмы обучения могут быть очень полезными, даже если они не соответствуют тому, как на самом деле работает мозг.
1 — Персептроны
Считающиеся первым поколением нейронных сетей, персептроны представляют собой просто вычислительные модели отдельного нейрона.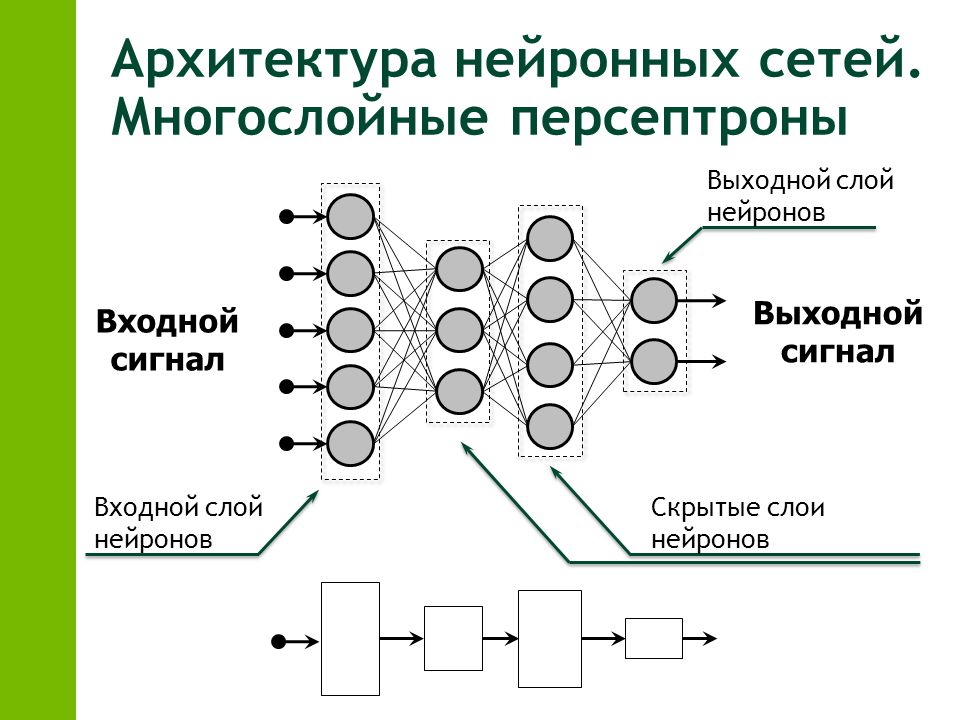 Первоначально персептрон был придуман Фрэнком Розенблаттом («Персептрон: вероятностная модель хранения и организации информации в мозге»). Также называемая нейронной сетью с прямой связью , перцептрон передает информацию спереди назад. Обучающие перцептроны обычно требуют обратного распространения , давая сети парные наборы данных входов и выходов. Входные данные отправляются в нейрон, обрабатываются и приводят к выходным данным. Ошибка, которая распространяется обратно, обычно является разницей между входными и выходными данными.Если в сети достаточно скрытых нейронов, она всегда может моделировать отношения между входом и выходом. На практике их использование намного более ограничено, но они обычно комбинируются с другими сетями для формирования новых сетей.
Первоначально персептрон был придуман Фрэнком Розенблаттом («Персептрон: вероятностная модель хранения и организации информации в мозге»). Также называемая нейронной сетью с прямой связью , перцептрон передает информацию спереди назад. Обучающие перцептроны обычно требуют обратного распространения , давая сети парные наборы данных входов и выходов. Входные данные отправляются в нейрон, обрабатываются и приводят к выходным данным. Ошибка, которая распространяется обратно, обычно является разницей между входными и выходными данными.Если в сети достаточно скрытых нейронов, она всегда может моделировать отношения между входом и выходом. На практике их использование намного более ограничено, но они обычно комбинируются с другими сетями для формирования новых сетей.
Если вы выбираете функции вручную и их достаточно, вы можете делать почти все. Для двоичных входных векторов у нас может быть отдельный блок признаков для каждого из экспоненциально многих двоичных векторов, и мы можем сделать любую возможную дискриминацию для двоичных входных векторов. Однако у перцептронов действительно есть ограничения: после определения закодированных вручную функций существуют очень строгие ограничения на то, что перцептрон может изучить.
Однако у перцептронов действительно есть ограничения: после определения закодированных вручную функций существуют очень строгие ограничения на то, что перцептрон может изучить.
2 — Сверточные нейронные сети
В 1998 году Ян Лекун и его сотрудники разработали действительно хороший распознаватель рукописных цифр под названием LeNet. Он использовал обратное распространение в сети с прямой связью со многими скрытыми слоями, множеством карт реплицированных единиц в каждом слое, объединением выходных данных соседних реплицированных единиц, широкой сетью, которая может работать с несколькими символами одновременно, даже если они перекрываются, и умным способ обучения всей системы, а не только распознавателя.Позже он был формализован под названием *** сверточные нейронные сети (CNN) ***.
Сверточные нейронные сети сильно отличаются от большинства других сетей. Они в основном используются для обработки изображений, но также могут использоваться для других типов ввода, например, аудио. Типичный вариант использования CNN — это когда вы загружаете сетевые образы и классифицируете данные. CNN обычно начинаются со входного «сканера», который не предназначен для одновременного анализа всех обучающих данных.Например, чтобы ввести изображение размером 100 x 100 пикселей, вам не нужен слой с 10 000 узлов. Скорее, вы создаете сканирующий входной слой, скажем, 10 x 10, и вы загружаете первые 10 x 10 пикселей изображения. После того, как вы передали этот ввод, вы подаете ему следующие 10 x 10 пикселей, перемещая сканер на один пиксель вправо.
Типичный вариант использования CNN — это когда вы загружаете сетевые образы и классифицируете данные. CNN обычно начинаются со входного «сканера», который не предназначен для одновременного анализа всех обучающих данных.Например, чтобы ввести изображение размером 100 x 100 пикселей, вам не нужен слой с 10 000 узлов. Скорее, вы создаете сканирующий входной слой, скажем, 10 x 10, и вы загружаете первые 10 x 10 пикселей изображения. После того, как вы передали этот ввод, вы подаете ему следующие 10 x 10 пикселей, перемещая сканер на один пиксель вправо.
Эти входные данные затем проходят через сверточные слои вместо обычных слоев, где не все узлы подключены. Каждый узел касается только близких соседних ячеек.Эти сверточные слои также имеют тенденцию сжиматься по мере того, как они становятся глубже, в основном из-за легко делимых факторов входных данных. Помимо этих сверточных слоев, они также часто содержат объединяющих слоев . Пул — это способ отфильтровать детали: обычно используется метод объединения , максимальное объединение , где мы берем, скажем, 2 x 2 пикселя и передаем пиксель с наибольшим количеством красного.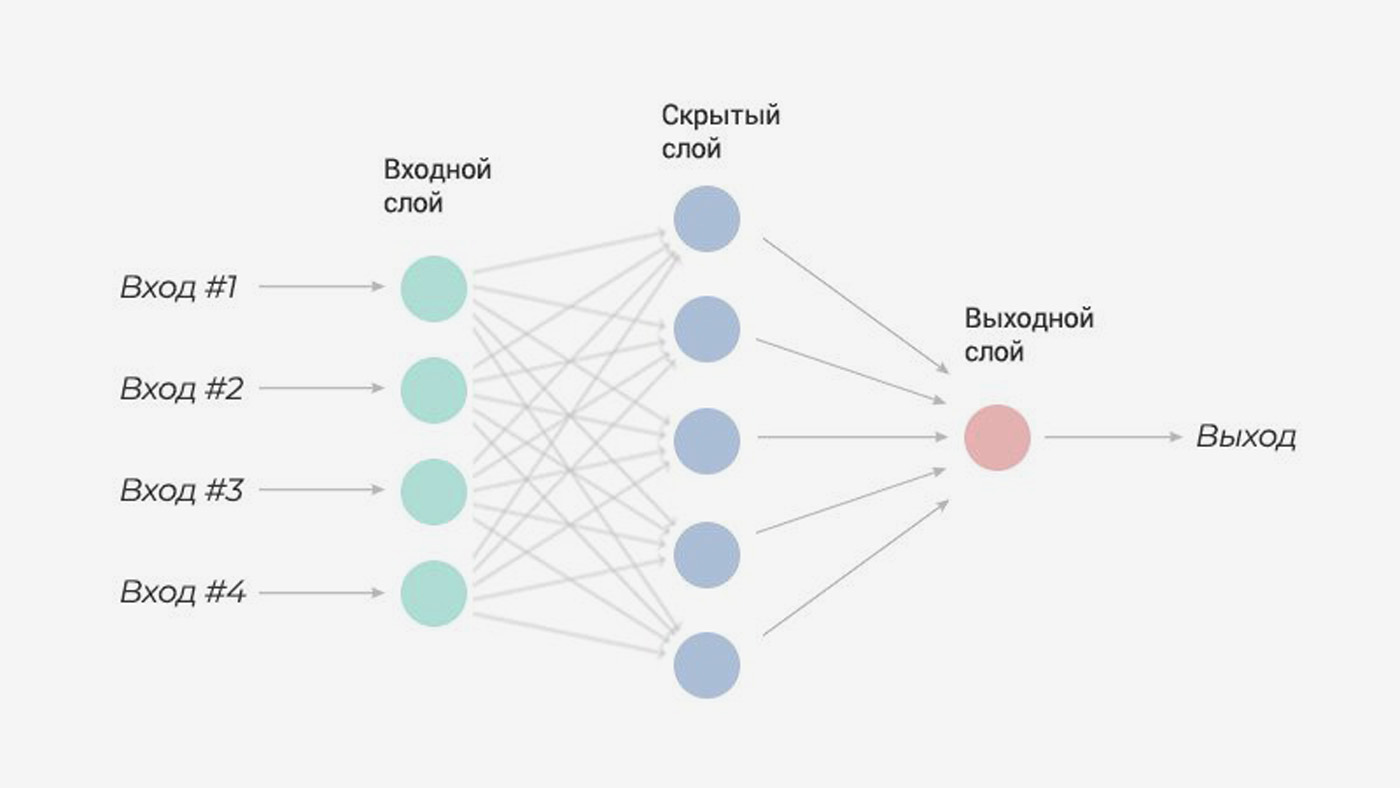 Если вы хотите глубже изучить CNN, прочтите оригинальную статью Яна Лекуна «Градиентное обучение применительно к распознаванию документов» (1998).
Если вы хотите глубже изучить CNN, прочтите оригинальную статью Яна Лекуна «Градиентное обучение применительно к распознаванию документов» (1998).
3 — Рекуррентные нейронные сети
Чтобы понять RNN, нам нужен краткий обзор моделирования последовательности . Применяя машинное обучение к последовательностям, мы часто хотим превратить входную последовательность в выходную последовательность, которая находится в другом домене. Например, превратите последовательность звукового давления в последовательность словосочетаний. Когда нет отдельной целевой последовательности, мы можем получить обучающий сигнал, пытаясь предсказать следующий член во входной последовательности.Целевая выходная последовательность — это входная последовательность с шагом вперед. Это кажется гораздо более естественным, чем попытка предсказать один пиксель изображения на основе других пикселей или один фрагмент изображения на основе остальной части изображения. Прогнозирование следующего термина в последовательности стирает различие между обучением с учителем и обучением без учителя. Он использует методы, разработанные для обучения с учителем, но не требует отдельного обучающего сигнала.
Он использует методы, разработанные для обучения с учителем, но не требует отдельного обучающего сигнала.
Модели без памяти — стандартный подход к этой задаче.В частности, модели авторегрессии могут предсказывать следующий член в последовательности из фиксированного числа предыдущих членов с помощью «отводов задержки». Нейронные сети с прямой связью — это обобщенные авторегрессионные модели, в которых используется один или несколько слоев нелинейных скрытых единиц. Однако, если мы дадим нашей генеративной модели какое-то скрытое состояние и если мы дадим этому скрытому состоянию его собственную внутреннюю динамику, мы получим гораздо более интересный вид модели, которая может хранить информацию в своем скрытом состоянии в течение длительного времени. Если динамика и то, как он генерирует выходные данные из своего скрытого состояния, зашумлены, мы никогда не узнаем его точное скрытое состояние.Лучшее, что мы можем сделать, — это вывести распределение вероятностей по пространству векторов скрытого состояния. Этот вывод возможен только для двух типов моделей скрытого состояния.
Первоначально представленный в книге Джеффри Элмана «Поиск структуры во времени» (1990), рекуррентные нейронные сети (RNN) в основном являются перцептронами. Однако, в отличие от перцептронов, которые не имеют состояния, у них есть связи между проходами, связи во времени. RNN очень мощные, потому что они сочетают в себе два свойства: 1) распределенное скрытое состояние, которое позволяет им эффективно хранить большой объем информации о прошлом, и 2) нелинейная динамика, которая позволяет им обновлять свое скрытое состояние сложными способами.Имея достаточное количество нейронов и времени, RNN могут вычислить все, что может вычислить ваш компьютер. Итак, какое поведение могут проявлять RNN? Они могут колебаться, оседать на точечных аттракторах и вести себя хаотично. Они потенциально могут научиться реализовывать множество небольших программ, каждая из которых захватывает крупицу знаний и запускается параллельно, взаимодействуя друг с другом для создания очень сложных эффектов.
Одна большая проблема с RNN — проблема исчезающего (или взрывающегося) градиента, когда, в зависимости от используемых функций активации, информация быстро теряется со временем.Интуитивно это не составит особой проблемы, потому что это просто веса, а не состояния нейронов, но веса во времени на самом деле являются тем местом, где хранится информация из прошлого. Если вес достигает значения 0 или 1 000 000, предыдущее состояние не будет очень информативным. В принципе, RNN могут использоваться во многих областях, поскольку большинство форм данных, которые фактически не имеют временной шкалы (не аудио или видео), могут быть представлены в виде последовательности. Изображение или текстовую строку можно загружать по одному пикселю или символу за раз, поэтому веса, зависящие от времени, используются для того, что было раньше в последовательности, а не для того, что произошло на x секунд раньше.В общем, повторяющиеся сети — хороший выбор для продвижения или дополнения информации, например автозаполнения.
4 — Долговременная / кратковременная память
Hochreiter & Schmidhuber (1997) решили проблему, заставив RNN запоминать вещи на долгое время, построив так называемые *** сети долговременной памяти (LSTM) * **. LSTM пытаются бороться с проблемой исчезающего / взрывающегося градиента, вводя вентили и явно заданную ячейку памяти. Ячейка памяти хранит предыдущие значения и удерживает их, если только «ворота забывания» не говорят ячейке забыть эти значения.LSTM также имеют «входной вентиль», который добавляет новый материал в ячейку, и «выходной вентиль», который решает, когда переходить по векторам из ячейки в следующее скрытое состояние.
Напомним, что для всех RNN значения, поступающие из X_train и H_previous, используются для определения того, что происходит в текущем скрытом состоянии. Результаты текущего скрытого состояния (H_current) используются для определения того, что происходит в следующем скрытом состоянии. LSTM просто добавляют слой ячеек, чтобы гарантировать, что передача информации о скрытом состоянии от одной итерации к следующей достаточно высока.Другими словами, мы хотим запоминать материал из предыдущих итераций столько, сколько необходимо, и ячейки в LSTM позволяют этому происходить. LSTM способны изучать сложные последовательности, такие как сочинение Хемингуэя или музыка Моцарта.
5 — Блокируемый рекуррентный блок
Блокированный повторяющийся блок (ГРУ) — это небольшая вариация LSTM. Они принимают X_train и H_previous в качестве входных данных. Они выполняют некоторые вычисления, а затем передают H_current. В следующей итерации X_train.next и H_current используются для дополнительных вычислений и так далее. Что отличает их от LSTM, так это то, что GRU не нуждается в уровне ячеек для передачи значений. Вычисления в рамках каждой итерации гарантируют, что передаваемые значения H_current либо сохраняют большой объем старой информации, либо запускаются с большим объемом новой информации.
В большинстве случаев ГРУ работают так же, как LSTM, с самой большой разницей в том, что ГРУ немного быстрее и проще в использовании (но также немного менее выразительно).На практике они, как правило, нейтрализуют друг друга, так как вам нужна более крупная сеть, чтобы восстановить некоторую выразительность, что, в свою очередь, сводит на нет преимущества в производительности. В некоторых случаях, когда дополнительная выразительность не требуется, ГРУ могут превзойти LSTM. Вы можете прочитать больше о ГРУ в книге Джунён Чанг 2014 «Эмпирическая оценка стробированных рекуррентных нейронных сетей при моделировании последовательностей».
6 — Сеть Хопфилда
Повторяющиеся сети нелинейных единиц обычно очень трудно анализировать.Они могут вести себя по-разному: переходить в стабильное состояние, колебаться или следовать хаотическим траекториям, которые невозможно предсказать в далеком будущем. Чтобы решить эту проблему, Джон Хопфилд представил сеть Хопфилда в своей работе 1982 года «Нейронные сети и физические системы с возникающими коллективными вычислительными возможностями». Сеть Хопфилда (HN) — это сеть, в которой каждый нейрон соединен с каждым другим нейроном. Это полностью запутанная тарелка спагетти, поскольку даже все узлы функционируют как все.Каждый узел вводится перед обучением, затем скрывается во время обучения и выводится после. Сети обучаются путем установки значения нейронов на желаемый шаблон, после чего можно вычислить веса. После этого веса не меняются. После обучения одному или нескольким шаблонам сеть всегда будет сходиться к одному из изученных шаблонов, потому что сеть стабильна только в этих состояниях.
Существует еще одна вычислительная роль сетей Хопфилда. Вместо того, чтобы использовать сеть для хранения воспоминаний, мы используем ее для построения интерпретаций сенсорного ввода.Входные данные представлены видимыми единицами, состояния скрытых единиц, а плохая интерпретация представлена энергией.
К сожалению, люди показали, что сеть Хопфилда очень ограничена в своих возможностях. Сеть Хопфилда из N единиц может запоминать только 0,15N паттернов из-за так называемого ложного минимума в своей энергетической функции. Идея состоит в том, что, поскольку функция энергии непрерывна в пространстве своих весов, если два локальных минимума находятся слишком близко друг к другу, они могут «упасть» друг в друга, создав один локальный минимум, который не соответствует ни одной обучающей выборке, в то время как забывая о двух образцах, которые предполагается запомнить.Это явление значительно ограничивает количество выборок, которые может изучить сеть Хопфилда.
7 — Машина Больцмана
Машина Больцмана — это тип стохастической рекуррентной нейронной сети. Его можно рассматривать как стохастический генеративный аналог сетей Хопфилда. Это была одна из первых нейронных сетей, способных изучать внутренние представления, а также представлять и решать сложные комбинаторные задачи. Впервые представленные Джеффри Хинтоном и Терренсом Сейновски в статье «Обучение и повторное обучение на машинах Больцмана» (1986), машины Больцмана во многом похожи на сети Хопфилда, но некоторые нейроны помечены как входные нейроны, а другие остаются «скрытыми».”Входные нейроны становятся выходными нейронами в конце полного обновления сети. Он начинается со случайных весов и учится через обратное распространение. По сравнению с сетью Хопфилда, нейроны в основном имеют бинарные паттерны активации.
Цель обучения алгоритму машинного обучения Больцмана — максимизировать произведение вероятностей, которые машина Больцмана присваивает двоичным векторам в обучающей выборке. Это эквивалентно максимизации суммы логарифмических вероятностей, которые машина Больцмана назначает обучающим векторам.Это также эквивалентно максимизации вероятности того, что мы получим ровно N обучающих примеров, если мы сделаем следующее: 1) пусть сеть установится на свое стационарное распределение N разное время без внешнего входа и 2) каждый раз выбирает видимый вектор. .
Эффективная процедура мини-пакетного обучения была предложена для машин Больцмана Салахутдиновым и Хинтоном в 2012 году.
- Для положительной фазы сначала инициализируйте скрытые вероятности на 0.5, зафиксируйте вектор данных на видимых единицах, затем обновите все скрытые единицы параллельно до сходимости, используя обновления среднего поля. После схождения сети запишите PiPj для каждой подключенной пары устройств и усредните это значение по всем данным в мини-пакете.
- Для отрицательной фазы: сначала сохраните набор «фантастических частиц». Каждая частица имеет значение, которое является глобальной конфигурацией. Последовательно обновите все юниты в каждой частице фэнтези несколько раз. Для каждой связанной пары единиц среднее значение SiSj по всем фантастическим частицам.
В общей машине Больцмана стохастические обновления единиц должны быть последовательными. Существует особая архитектура, которая позволяет чередовать параллельные обновления, которые намного более эффективны (без соединений внутри уровня, без соединений с пропуском уровня). Эта процедура мини-партии делает обновления машины Больцмана более параллельными. Это называется глубокой машиной Больцмана (DBM), общей машиной Больцмана с множеством недостающих соединений.
8 — Deep Belief Networks
Обратное распространение считается стандартным методом в искусственных нейронных сетях для вычисления вклада ошибок каждого нейрона после обработки пакета данных.Однако при использовании обратного распространения возникают некоторые серьезные проблемы. Во-первых, требуются помеченные данные для обучения, в то время как почти все данные не помечены. Во-вторых, время обучения плохо масштабируется, что означает, что оно очень медленное в сетях с несколькими скрытыми слоями. В-третьих, он может застрять в плохих локальных оптимумах, поэтому для глубоких сетей они далеки от оптимальных.
Чтобы преодолеть ограничения обратного распространения, исследователи рассмотрели возможность использования методов обучения без учителя. Это помогает сохранить эффективность и простоту использования градиентного метода для настройки весов, а также для моделирования структуры сенсорного ввода.В частности, они корректируют веса, чтобы максимизировать вероятность того, что генеративная модель сгенерирует сенсорный ввод. Вопрос в том, какую генеративную модель нам следует изучить? Может ли это быть энергетическая модель, подобная машине Больцмана? Или причинная модель из идеализированных нейронов? Или гибрид двух?
Йошуа Бенджио разработал Deep Belief Networks («Жадное послойное обучение глубоких сетей»), которые, как было показано, эффективно обучаются стек за стеком.Этот метод также известен как жадное обучение, где жадность означает принятие локально оптимальных решений для получения достойного, но, возможно, не оптимального ответа. Сеть убеждений — это ориентированный ациклический граф, составленный из стохастических переменных. Используя сеть убеждений, мы можем наблюдать некоторые из переменных, и мы хотели бы решить две проблемы: 1) проблему вывода: вывести состояния ненаблюдаемых переменных и 2) проблема обучения: настроить взаимодействия между переменными, чтобы сделать сеть с большей вероятностью сгенерирует обучающие данные.
Deep Belief Networks можно обучить через контрастное расхождение или обратное распространение и научиться представлять данные в виде вероятностной модели. После обучения или перехода к стабильному состоянию посредством обучения без учителя модель можно использовать для генерации новых данных. При обучении с контрастной дивергенцией он может даже классифицировать существующие данные, потому что нейроны были обучены искать различные особенности.
9 — Автоэнкодеры
Автоэнкодеры — это нейронные сети, разработанные для обучения без учителя, т.е.е. когда данные без метки. В качестве моделей сжатия данных они могут использоваться для кодирования заданного ввода в представление меньшего размера. Затем можно использовать декодер для восстановления ввода из закодированной версии.
Работа, которую они выполняют, очень похожа на анализ основных компонентов , который обычно используется для представления заданных входных данных с использованием меньшего количества измерений, чем изначально. Так, например, в НЛП, если вы представляете слово как вектор из 100 чисел, вы можете использовать PCA для представления его в 10 числах.Конечно, это может привести к потере некоторой информации, но это хороший способ представить свой ввод, если вы можете работать только с ограниченным числом измерений. Кроме того, это хороший способ визуализировать данные, поскольку вы можете легко нанести уменьшенные размеры на двухмерный график, а не на 100-мерный вектор. Автоэнкодеры выполняют аналогичную работу — разница в том, что они могут использовать нелинейные преобразования для кодирования заданного вектора в меньшие размеры (по сравнению с PCA, который является линейным преобразованием), поэтому он может генерировать более сложные кодировки.
Их можно использовать для уменьшения размерности, предварительного обучения других нейронных сетей, генерации данных и т. Д. Есть несколько причин: (1) они обеспечивают гибкие сопоставления в обоих направлениях, (2) время обучения линейно (или лучше ) в количестве обучающих примеров, и (3) окончательная модель кодирования довольно компактна и быстра. Однако оказывается, что очень сложно оптимизировать глубинные автокодеры с использованием обратного распространения. При малых начальных весах обратный градиент умирает.В настоящее время они редко используются в практических приложениях, главным образом потому, что в ключевых областях, где они когда-то считались прорывом (например, послойное предварительное обучение), ванильное обучение с учителем работает лучше. Ознакомьтесь с оригинальной статьей Бурларда и Кампа, датированной 1988 годом.
10 — Генеративная состязательная сеть
В статье «Генеративные состязательные сети» (2014) Ян Гудфеллоу представил новое поколение нейронных сетей, в которых две сети работают вместе. Генеративные состязательные сети (GAN) состоят из любых двух сетей (хотя часто это комбинация прямой прямой связи и сверточных нейронных сетей), одна из которых предназначена для генерации контента (генеративная), а другая — для оценки контента (дискриминационная).Задача дискриминантной модели — определить, выглядит ли данное изображение естественным (изображение из набора данных) или искусственно созданным. Задача генератора — создавать естественно выглядящие изображения, похожие на исходное распределение данных. Это можно рассматривать как игру с нулевой суммой или минимаксную игру для двух игроков. В статье используется аналогия: генеративная модель похожа на «команду фальшивомонетчиков, пытающихся произвести и использовать фальшивую валюту», в то время как дискриминационная модель похожа на «полицию, пытающуюся обнаружить фальшивую валюту».«Генератор пытается обмануть дискриминатор, в то время как дискриминатор пытается не обмануть генератор. По мере обучения моделей путем попеременной оптимизации оба метода улучшаются до точки, когда «подделки неотличимы от подлинных изделий».
По словам Яна ЛеКуна, эти сети могут стать следующим крупным развитием. Это один из немногих успешных методов машинного обучения без учителя, который быстро меняет нашу способность выполнять генеративные задачи.За последние несколько лет мы добились очень впечатляющих результатов. В этой области ведется много активных исследований с целью применения GAN для языковых задач, повышения их стабильности и простоты обучения и т. Д. Они уже применяются в промышленности для различных приложений, начиная от интерактивного редактирования изображений, оценки трехмерной формы, открытия лекарств и полу-контролируемого обучения до робототехники.
Заключение
Нейронные сети — одна из самых красивых парадигм программирования, когда-либо изобретенных.При традиционном подходе к программированию мы говорим компьютеру, что делать, и разбиваем большие проблемы на множество мелких, точно определенных задач, которые компьютер может легко выполнить. Напротив, мы не говорим компьютеру, как решить наши проблемы для нейронной сети. Вместо этого он учится на данных наблюдений и находит собственное решение проблемы.
Сегодня глубокие нейронные сети и глубокое обучение достигают выдающейся производительности при решении многих важных задач в области компьютерного зрения, распознавания речи и обработки естественного языка.Они широко используются такими компаниями, как Google, Microsoft и Facebook. Я надеюсь, что этот пост поможет вам изучить основные концепции нейронных сетей, включая современные методы глубокого обучения.
Дополнительная информация
Ссылки на статьи
Объяснение искусственного интеллекта, глубокого обучения и нейронных сетей
Таким образом, архитектура модели и ее настройка являются основными компонентами методов ИНС, помимо самих алгоритмов обучения.Все эти характеристики ИНС могут существенно повлиять на производительность модели.
Кроме того, модели характеризуются и настраиваются функцией активации, используемой для преобразования взвешенного входа нейрона в активацию его выхода. Существует множество различных типов преобразований, которые можно использовать в качестве функции активации, и их обсуждение выходит за рамки данной статьи.
Абстракция вывода в результате преобразований входных данных через нейроны и слои является формой распределенного представления в отличие от локального представления.Например, значение, представленное одним искусственным нейроном, является формой локального представления. Однако смысл всей сети — это форма распределенного представления из-за множества преобразований между нейронами и слоями.
Следует отметить одну вещь: хотя ИНС чрезвычайно мощны, они также могут быть очень сложными и считаются алгоритмами черного ящика, а это означает, что их внутреннюю работу очень трудно понять и объяснить. Поэтому при выборе использования ИНС для решения проблем следует помнить об этом.
Введение в глубокое обучение
Глубокое обучение, хотя и звучит ярко, на самом деле это всего лишь термин для описания определенных типов нейронных сетей и связанных с ними алгоритмов, которые часто используют очень необработанные входные данные. Они обрабатывают эти данные с помощью множества уровней нелинейных преобразований входных данных для вычисления целевого выхода.
Неконтролируемое извлечение функций также является областью, в которой глубокое обучение выделяется. Извлечение признаков — это когда алгоритм может автоматически выводить или конструировать значимые особенности данных, которые будут использоваться для дальнейшего обучения, обобщения и понимания.Бремя выполнения процесса извлечения признаков в большинстве других подходов к машинному обучению, наряду с выбором функций и проектированием, традиционно лежит на специалистах по обработке данных или программистах.
Извлечение признаков обычно также включает некоторое уменьшение размерности, что уменьшает количество входных объектов и данных, необходимых для получения значимых результатов. Это дает много преимуществ, в том числе упрощение, снижение вычислительной мощности и мощности памяти и так далее.
В более общем смысле, глубокое обучение подпадает под группу методов, известных как изучение функций или обучение представлению.Как уже говорилось, извлечение функций используется, чтобы «узнать», на каких функциях следует сосредоточиться и использовать их в решениях для машинного обучения. Сами алгоритмы машинного обучения «изучают» оптимальные параметры для создания наиболее эффективной модели.
Перефразируя Википедию, алгоритмы изучения функций позволяют машине как обучаться для конкретной задачи, используя хорошо подобранный набор функций, так и изучать сами функции. Другими словами, эти алгоритмы учатся учиться!
Глубокое обучение успешно использовалось во многих приложениях и на момент написания этой статьи считалось одним из самых передовых методов машинного обучения и искусственного интеллекта.Связанные алгоритмы часто используются для задач обучения с учителем, без учителя и с учителем.
Для моделей глубокого обучения на основе нейронных сетей количество слоев больше, чем в так называемых алгоритмах поверхностного обучения. Мелкие алгоритмы, как правило, менее сложны и требуют более глубоких знаний об оптимальных функциях для использования, что обычно включает выбор функций и разработку.
Напротив, алгоритмы глубокого обучения больше полагаются на оптимальный выбор модели и оптимизацию посредством настройки модели.Они больше подходят для решения проблем, где предварительное знание функций менее желательно или необходимо, и где маркированные данные недоступны или не требуются для основного варианта использования.
Помимо статистических методов, нейронные сети и глубокое обучение также используют концепции и методы обработки сигналов, включая нелинейную обработку и / или преобразования.
Вы можете вспомнить, что нелинейная функция — это функция, которая не характеризуется просто прямой линией.Следовательно, для моделирования взаимосвязи между входом или независимой переменной и выходом или зависимой переменной требуется нечто большее, чем просто наклон. Нелинейные функции могут включать полиномиальные, логарифмические и экспоненциальные члены, а также любое другое преобразование, которое не является линейным.
Многие явления, наблюдаемые в физической вселенной, на самом деле лучше всего моделируются с помощью нелинейных преобразований. Это верно также для преобразований между входными данными и целевым выходом в решениях машинного обучения и ИИ.
Более глубокое погружение в глубокое обучение — без каламбура
Как уже упоминалось, входные данные преобразуются на всех уровнях нейронной сети глубокого обучения искусственными нейронами или процессорами. Цепочка преобразований, которые происходят от ввода к выводу, известна как путь присвоения кредита или CAP.
Значение CAP — это прокси для измерения или концепции «глубины» в архитектуре модели глубокого обучения. Согласно Википедии, большинство исследователей в этой области согласны с тем, что глубокое обучение имеет несколько нелинейных уровней с CAP больше двух, а некоторые считают CAP больше десяти очень глубоким обучением.
Хотя подробное обсуждение множества различных архитектур моделей глубокого обучения и алгоритмов обучения выходит за рамки данной статьи, некоторые из наиболее примечательных включают:
Нейронные сети с прямой связью
Рекуррентные нейронные сети
Многослойные персептроны (MLP)
Сверточные нейронные сети
Рекурсивные нейронные сети
Сети глубоких убеждений
Сверточные сети глубоких убеждений
Самоорганизующиеся карты 22
Машины глубокого Больцмана
Составные автокодировщики с шумоподавлением
Стоит отметить, что из-за относительного увеличения сложности алгоритмы глубокого обучения и нейронных сетей могут быть подвержены переобучению.Кроме того, увеличенная модель и алгоритмическая сложность могут привести к очень значительным требованиям к вычислительным ресурсам и времени.
Также важно учитывать, что решения могут представлять локальные минимумы в отличие от глобального оптимального решения. Это связано со сложной природой этих моделей в сочетании с методами оптимизации, такими как градиентный спуск.
Учитывая все это, необходимо проявлять должную осторожность при использовании алгоритмов искусственного интеллекта для решения проблем, включая выбор, реализацию и оценку производительности самих алгоритмов.Хотя это выходит за рамки данной статьи, машинное обучение включает в себя множество методов, которые могут помочь в этих областях.
Резюме
Искусственный интеллект — чрезвычайно мощная и захватывающая область. По мере продвижения вперед он станет только более важным и повсеместным, и, безусловно, будет продолжать оказывать очень значительное влияние на современное общество.
Искусственные нейронные сети (ИНС) и более сложные методы глубокого обучения являются одними из наиболее эффективных инструментов искусственного интеллекта для решения очень сложных проблем, и они будут продолжать развиваться и использоваться в будущем.
Хотя сценарий, похожий на терминатора, маловероятен в ближайшее время, за развитием методов и приложений искусственного интеллекта, безусловно, будет очень интересно наблюдать!
Чтобы узнать больше, ознакомьтесь с моей книгой AI для людей и бизнеса: основа для улучшения человеческого опыта и успеха в бизнесе .
Об авторе
Алекс — основатель InnoArchiTech и InnoArchiTech Institute, а также автор книги AI для людей и бизнеса , опубликованной O’Reilly Media.
Машинное обучение и нейронные сети: в чем разница?
Искусственный интеллект (AI), машинное обучение (ML) и глубокое обучение (DL) настолько глубоко и быстро стали неотъемлемой частью нашей повседневной жизни, что мы привыкли к ним, даже не осознавая их смысла. Для большинства людей AI, ML и DL одинаковы. Однако, хотя эти технологии взаимосвязаны, у них есть врожденные различия.
Сегодня мы рассмотрим один из таких источников массового заблуждения — машинное обучение против нейронной сети.
Что такое машинное обучение?Машинное обучение относится к более широкому кругу вопросов искусственного интеллекта. Машинное обучение направлено на создание интеллектуальных систем или машин, которые могут автоматически обучаться и обучаться на основе опыта, не будучи явно запрограммированными или требуя какого-либо вмешательства человека.
В этом смысле машинное обучение — это постоянно развивающаяся деятельность. Машинное обучение направлено на понимание структуры данных имеющегося набора данных и на включение данных в модели машинного обучения, которые могут использоваться компаниями и организациями.
Два основных метода машинного обучения — это обучение с учителем и обучение без учителя. Узнайте больше о типах машинного обучения.
Что такое нейронная сеть?Структура человеческого мозга вдохновила на создание нейронной сети. По сути, это модель машинного обучения (точнее, глубокого обучения), которая используется в обучении без учителя. Нейронная сеть — это сеть взаимосвязанных объектов, известных как узлы, в которой каждый узел отвечает за простые вычисления.Таким образом, нейронная сеть функционирует аналогично нейронам человеческого мозга.
Читать: Глубокое обучение против нейронной сети
Машинное обучение и нейронная сеть: ключевые различияДавайте посмотрим на основные различия между машинным обучением и нейронными сетями.
1. Машинное обучение использует продвинутые алгоритмы, которые анализируют данные, учатся на них и используют эти знания для обнаружения значимых закономерностей, представляющих интерес. В то время как нейронная сеть состоит из набора алгоритмов, используемых в машинном обучении для моделирования данных с использованием графов нейронов.
2. В то время как модель машинного обучения принимает решения в соответствии с тем, что она извлекла из данных, нейронная сеть упорядочивает алгоритмы таким образом, чтобы сама принимать точные решения. Таким образом, хотя модели машинного обучения могут учиться на данных, на начальных этапах они могут потребовать некоторого вмешательства человека.
Нейронные сети не требуют вмешательства человека, поскольку вложенные слои внутри передают данные через иерархии различных концепций, что в конечном итоге делает их способными учиться через собственные ошибки.
3. Как мы упоминали ранее, модели машинного обучения можно разделить на два типа — модели обучения с учителем и модели обучения без учителя. Однако нейронные сети можно разделить на нейронные сети с прямой связью, рекуррентные, сверточные и модульные.
4. Модель машинного обучения работает просто — она получает данные и учится на них. Со временем модель машинного обучения становится более зрелой и обучаемой, поскольку она постоянно учится на данных. Напротив, структура нейронной сети довольно сложна.В нем данные проходят через несколько уровней взаимосвязанных узлов, при этом каждый узел классифицирует характеристики и информацию предыдущего уровня перед передачей результатов другим узлам на последующих уровнях.
5. Поскольку модели машинного обучения адаптивны, они постоянно развиваются, обучаясь с использованием новых образцов данных и опыта. Таким образом, модели могут идентифицировать закономерности в данных. Здесь данные — единственный входной слой. Однако даже в простой модели нейронной сети есть несколько уровней.
Первый слой — это входной слой, за ним следует скрытый слой и, наконец, выходной слой. Каждый слой содержит один или несколько нейронов. Увеличивая количество скрытых слоев в модели нейронной сети, вы можете увеличить ее вычислительные возможности и возможности решения проблем.
6. Навыки, необходимые для машинного обучения, включают программирование, вероятность и статистику, большие данные и Hadoop, знание структур машинного обучения, структур данных и алгоритмов. Нейронные сети требуют таких навыков, как моделирование данных, математика, линейная алгебра и теория графов, программирование, вероятность и статистика.
7. Машинное обучение применяется в таких областях, как здравоохранение, розничная торговля, электронная коммерция (механизмы рекомендаций), BFSI, беспилотные автомобили, потоковое видео в Интернете, Интернет вещей, транспорт и логистика, и многие другие. Нейронные сети, с другой стороны, используются для решения множества бизнес-задач, включая, среди прочего, прогнозирование продаж, проверку данных, исследование клиентов, управление рисками, распознавание речи и распознавание символов.
ЗаключениеЭто некоторые из основных различий между машинным обучением и нейронными сетями.Нейронные сети по сути являются частью глубокого обучения, которое, в свою очередь, является подмножеством машинного обучения. Итак, нейронные сети — это не что иное, как высокоразвитое приложение машинного обучения, которое сейчас находит применение во многих областях, представляющих интерес.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG Diploma в области машинного обучения и искусственного интеллекта IIIT-B и выше, который разработан для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT -B Статус выпускника, 5+ практических проектов и помощь в трудоустройстве в ведущих фирмах.
Подготовьтесь к карьере будущего
ДИПЛОМ PG ПО МАШИННОМУ ОБУЧЕНИЮ И ИСКУССТВЕННОМУ ИНТЕЛЛЕКТУ
Объяснение: Нейронные сети | MIT News
За последние 10 лет самые эффективные системы искусственного интеллекта, такие как распознаватели речи на смартфонах или новейший автоматический переводчик Google, были созданы с помощью техники, называемой «глубокое обучение».
Глубокое обучение — это фактически новое название подхода к искусственному интеллекту, называемого нейронными сетями, который входил и выходил из моды более 70 лет. Нейронные сети были впервые предложены в 1944 году Уорреном Маккалоу и Уолтером Питтсом, двумя исследователями из Чикагского университета, которые переехали в Массачусетский технологический институт в 1952 году как члены-основатели того, что иногда называют первым отделом когнитивной науки.
Нейронные сети были основной областью исследований как в нейробиологии, так и в информатике до 1969 года, когда, согласно знаниям информатики, они были уничтожены математиками Массачусетского технологического института Марвином Мински и Сеймуром Папертом, которые через год стали содиректорами. новой лаборатории искусственного интеллекта Массачусетского технологического института.
Затем эта техника возродилась в 1980-х, снова ушла в тень в первом десятилетии нового столетия и вернулась, как гангстеры во втором, во многом благодаря возросшей вычислительной мощности графических чипов.
«Есть мнение, что идеи в науке чем-то похожи на эпидемии вирусов», — говорит Томазо Поджио, профессор мозга и когнитивных наук Юджина Макдермотта в Массачусетском технологическом институте, исследователь из Института исследований мозга Макговерна при Массачусетском технологическом институте и директор центра Массачусетского технологического института. для мозга, разума и машин.«По всей видимости, существует пять или шесть основных штаммов вирусов гриппа, и каждый из них возвращается примерно через 25 лет. Люди заражаются, у них развивается иммунный ответ, поэтому они не заражаются в течение следующих 25 лет. А еще есть новое поколение, которое готово заразиться тем же штаммом вируса. В науке люди влюбляются в идею, воодушевляются ею, забивают ее до смерти, а затем получают иммунизацию — они устают от нее. Значит, у идей должна быть такая же периодичность! »
Важные вопросы
Нейронные сети — это средство машинного обучения, при котором компьютер учится выполнять некоторые задачи, анализируя обучающие примеры.Обычно образцы маркируются заранее вручную. Система распознавания объектов, например, могла бы получать тысячи изображений автомобилей, домов, кофейных чашек и т. Д. С этикетками и находить на изображениях визуальные паттерны, которые последовательно соотносятся с определенными этикетками.
Нейронная сеть, смоделированная по образцу человеческого мозга, состоит из тысяч или даже миллионов простых узлов обработки, которые плотно взаимосвязаны. Большинство современных нейронных сетей организованы в слои узлов, и они имеют «прямую связь», что означает, что данные проходят через них только в одном направлении.Отдельный узел может быть подключен к нескольким узлам на нижнем уровне, от которого он получает данные, и к нескольким узлам на верхнем уровне, на которые он отправляет данные.
Каждому из своих входящих соединений узел присваивает номер, известный как «вес». Когда сеть активна, узел получает другой элемент данных — другое число — по каждому из своих соединений и умножает его на соответствующий вес. Затем он складывает полученные продукты вместе, получая одно число.Если это число ниже порогового значения, узел не передает данные на следующий уровень. Если число превышает пороговое значение, узел «срабатывает», что в современных нейронных сетях обычно означает отправку числа — суммы взвешенных входных данных — по всем его исходящим соединениям.
Когда нейронная сеть обучается, все ее веса и пороги изначально устанавливаются на случайные значения. Обучающие данные поступают на нижний уровень — входной уровень — и проходят через последующие уровни, умножаются и складываются сложным образом, пока, наконец, не попадают, радикально преобразованные, на выходной уровень.Во время обучения веса и пороги постоянно корректируются до тех пор, пока данные обучения с одинаковыми метками не будут давать одинаковые результаты.
Умы и машины
Нейронные сети, описанные Маккаллоу и Питтсом в 1944 году, имели пороговые значения и веса, но они не были расположены по слоям, и исследователи не указали какой-либо механизм обучения. Маккалоу и Питтс показали, что нейронная сеть, в принципе, может вычислить любую функцию, которую может выполнить цифровой компьютер.Результатом стало больше нейробиологии, чем информатики: суть заключалась в том, чтобы предположить, что человеческий мозг можно рассматривать как вычислительное устройство.
Нейронные сети продолжают оставаться ценным инструментом нейробиологических исследований. Например, определенные схемы сети или правила настройки весов и пороговых значений воспроизводят наблюдаемые особенности нейроанатомии и познания человека, что свидетельствует о том, что они фиксируют что-то о том, как мозг обрабатывает информацию.
Первая обучаемая нейронная сеть, Персептрон, была продемонстрирована психологом Корнельского университета Фрэнком Розенблаттом в 1957 году.Дизайн персептрона был очень похож на дизайн современной нейронной сети, за исключением того, что он имел только один слой с регулируемыми весами и порогами, зажатый между входным и выходным слоями.
Персептроны были активной областью исследований как в психологии, так и в молодой дисциплине информатики до 1959 года, когда Мински и Паперт опубликовали книгу под названием «Персептроны», которая продемонстрировала, что выполнение некоторых довольно распространенных вычислений на персептронах будет непрактично трудоемким.
«Конечно, все эти ограничения как бы исчезают, если вы возьмете более сложное оборудование, например, двухуровневое», — говорит Поджио. Но в то время книга оказала сдерживающее воздействие на исследования нейронных сетей.
«Вы должны поместить эти вещи в исторический контекст», — говорит Поджио. «Они выступали за программирование — для таких языков, как Lisp. Не так давно люди все еще использовали аналоговые компьютеры. В то время было не совсем ясно, что программирование — это правильный путь.Думаю, они немного переборщили, но, как обычно, это не черно-белое. Если вы думаете об этом как о соревновании между аналоговыми вычислениями и цифровыми вычислениями, они боролись за то, что в то время было правильным ».
Периодичность
Однако к 1980-м годам исследователи разработали алгоритмы для изменения весов и пороговых значений нейронных сетей, которые были достаточно эффективными для сетей с более чем одним слоем, устранив многие ограничения, указанные Мински и Папертом.Поле пережило ренессанс.
Но интеллектуально в нейронных сетях есть что-то неудовлетворительное. Достаточное обучение может изменить настройки сети до такой степени, что она сможет с пользой классифицировать данные, но что означают эти настройки? На какие особенности изображения смотрит распознаватель объектов и как он объединяет их в отличительные визуальные подписи автомобилей, домов и кофейных чашек? На этот вопрос нельзя ответить, глядя на веса отдельных связей.
В последние годы компьютерные ученые начали придумывать оригинальные методы для вывода аналитических стратегий, используемых нейронными сетями.Но в 80-е годы стратегии сетей было невозможно расшифровать. Поэтому на рубеже веков нейронные сети были вытеснены машинами опорных векторов — альтернативным подходом к машинному обучению, основанным на очень чистой и элегантной математике.
Недавнее возрождение нейронных сетей — революция глубокого обучения — произошло благодаря индустрии компьютерных игр. Сложные изображения и быстрые темпы современных видеоигр требуют оборудования, способного не отставать, и результатом стал графический процессор (GPU), который объединяет тысячи относительно простых процессорных ядер на одном чипе.Исследователям не потребовалось много времени, чтобы понять, что архитектура графического процессора в высшей степени похожа на архитектуру нейронной сети.
Современные графические процессоры позволили однослойным сетям 1960-х годов и двух- или трехуровневым сетям 1980-х годов превратиться в современные 10-, 15- и даже 50-уровневые сети. Это то, что означает «глубокое обучение» в «глубоком обучении» — глубина слоев сети. И в настоящее время глубокое обучение отвечает за самые эффективные системы почти во всех областях исследований искусственного интеллекта.
Под капотом
Непрозрачность сетей по-прежнему тревожит теоретиков, но и в этом направлении есть успехи. Помимо руководства Центром мозга, разума и машин (CBMM), Поджио возглавляет исследовательскую программу центра в области теоретических основ разведки. Недавно Поджио и его коллеги из CBMM опубликовали теоретическое исследование нейронных сетей, состоящее из трех частей.
В первой части, опубликованной в прошлом месяце в International Journal of Automation and Computing , рассматривается диапазон вычислений, которые могут выполнять сети с глубоким обучением, и когда глубокие сети предлагают преимущества перед более мелкими.Вторая и третья части, выпущенные в виде технических отчетов CBMM, посвящены проблемам глобальной оптимизации или гарантии того, что сеть нашла настройки, которые наилучшим образом соответствуют ее обучающим данным, и переобучению, или случаях, когда сеть становится настроенной таким образом.