16 бесплатных онлайн-курсов по машинному обучению
Популярная тенденция в сфере онлайн-образования — массовые открытые онлайн-курсы (Massive open online-courses, MOOC). Появились бесплатные курсы по машинному обучению и data science. Они доступны каждому и основаны на образовательных программах от ведущих университетов, например, МФТИ.
Большинство MOOC по машинному обучению доступны на английском языке и представлены на известных платформах онлайн-образования, таких как Coursera, Udacity, World Education University и edX.
Отдельно стоит отметить, что курсы Coursera доступны бесплатно только для прослушивания лекций. Для того, чтобы выполнять задания или получить сертификат по окончании курса, нужно оформить подписку или оплатить курс.
Видео-материалы и лекции курса можно получить бесплатно, для этого на странице курса внизу нужно нажать кнопку «прослушать курс», как показано на картинке:
В этой статье собраны бесплатные курсы по машинному обучению и Data Science на русском языке или с русскими субтитрами.
Курсы по data science
Введение в машинное обучение
Авторы: ВШЭ и Яндекс
Платформа: Coursera
Язык: русский
На курсе Константина Воронцова Введение в машинное обучение рассматриваются популярные задачи, решаемые с помощью машинного обучения — классификация, регрессия, кластеризация. Слушателю нужно знать об основных понятиях математики: функциях, производных, векторах, матрицах, желательно иметь базовые навыки программирования и быть знакомым с python.
Продолжительность: 35 часов
Машинное обучение и анализ данных
Авторы: МФТИ и Яндекс
Платформа: Coursera
Язык: русский
Специализация Машинное обучение и анализ данных включает 6 курсов. Осваиваются основные инструменты, необходимые в работе с большим массивом данных: современные методы классификации и регрессии, поиск структуры в данных, проведение экспериментов, построение выводов, фундаментальная математика, основы программирования на python.
Продолжительность: 8 месяцев (7 часов в неделю)
Python для анализа данных
Авторы: МФТИ, ФРОО, Mail.ru Group
Платформа: Coursera
Курс Python для анализа данных ориентирован на решение практических задач. Студенты будут применять свои навыки программирования для построения предиктивных моделей, визуализации данных и работы с нейросетями.
Продолжительность: 25 часов
Введение в науку о данных
Автор: СПбГУ
Платформа: Coursera
Язык: русский
Курс Введение в науку о данных рассматривает постановку и решение типичных задач, с которыми может столкнуться в своей работе data scientist, подходы к сбору, анализу, обработке и визуализации массивов данных.
Продолжительность: 17 часов
Глубокое обучение в творчестве с TensorFlow
Автор: Google Magenta
Язык: английский, русские субтитры
MOOC Использование глубокого обучения в творчестве с помощью TensorFlow расскажет о том, как строить алгоритмы глубокого обучения на основе сверточных, рекуррентных, генеративных нейросетей и применять их для создания творческих приложений.
Продолжительность: 60 часов
Data Science
Автор: Johns Hopkins University
Платформа: Courserа
Язык: английский, русские субтитры
В специализацию Data Science университета John Hopkins входят 10 курсов, включая сбор и сортировку данных, программирование на языке R, регрессионные модели, разработку продуктов для обработки данных и другие.
Продолжительность: 8 месяцев (5 часов в неделю)
Data science для руководителей
Автор: Johns Hopkins University
Платформа: Courserа
Язык: английский, русские субтитры
Data Science для руководителей — это ускоренная обучающая программа — 5 курсов, которые дают базовое понимание о том, что такое data science и как работать с проектами в этой сфере, собирать и развивать команду и даже лидерские качества.
Продолжительность: 40 часов
Нейронные сети
Автор: Институт биоинформатики
Платформа: Stepic
Язык: русский
Бесплатный курс Нейронные сети дает основы теории нейронных сетей и практики применения. Детальный разбор процесса создания и применения нейронных сетей. Алгоритмы, лежащие в основе нейросетей и множество практических задач.
Продолжительность: 33 часа
Программирование на Python
Автор: Институт биоинформатики
Платформа: Stepic
Язык: русский
На курсе Программирование на Python представлены базовые понятия программирования на python и большое количество практических задач. Решения будут проверяться автоматической системой.
Продолжительность: 22 часа
Алгоритмы: теория и практика. Методы
Автор: Computer Science Center
Платформа: Stepic
Язык: русский
Рассматриваются теоретические основы создания алгоритмов и особенности реализации на языках C++, Java и Python.
Продолжительность: 35 часов
Основы программирования на R
Платформа: Stepic
Язык: русский
На курсе Основы программирования на R изучаются основные типы данных и семантические правила, анализ и обработка данных.
Продолжительность: 19 часов
Анализ данных в R
Автор: Институт биоинформатики
Платформа: Stepic
Язык: русский
На курсе рассматриваются этапы статистического анализа на R — предварительная обработка данных, применение статистических методов анализа и визуализация данных.
Продолжительность: 21 час
Базы данных
Автор: СПбГУ
Платформа: Coursera
Язык: русский
В основе курса Базы данных изучение и применение языка SQL для создания, модификации объектов и управления данными в реляционных базах данных. Рассматриваются сферы применения NoSQL баз данных и современные подходы к обработке big data.
Продолжительность: 20 часов
От Excel до MySQL: способы анализа бизнес-данных
Автор: Duke University
Платформа: Coursera
Язык: английский, русские субтитры
В специализацию входят 5 курсов, которые демонстрируют, как использовать Excel, Tableau и MySQL для анализа данных, прогнозирования, создания моделей и визуализации данных для решения задач и улучшения бизнес-процессов.
Продолжительность: 8 месяцев (5 часов в неделю)
Линейная регрессия
Автор: СПбГУ
Платформа: Coursera
В курсе Линейная регрессия разбираются основные методы описания взаимосвязей между количественными признаками, регрессионный анализ и построение моделей. Специальное место отводится операциям с матрицами. Курс ориентирован на людей, которые уже знакомы с базовыми понятиями анализа данных.
Продолжительность: 22 часа
Анализ данных
Автор: НГУ
Платформа: Coursera
Язык: русский
В специализацию Анализ данных Новосибирского государственного Университета входят 4 курса. Курсы содержат материалы по основам теории вероятностей и математической статистики, исследованию связей между признаками, построению прогнозов на основе регрессионных моделей, кластерному и статистическому анализу. Курсы разработаны совместно с 2GIS.
Продолжительность: 4 месяца (3 часа в неделю)
Машинное обучение — это легко / Хабр
В данной статье речь пойдёт о машинном обучении в целом и взаимодействии с датасетами. Если вы начинающий, не знаете с чего начать изучение и вам интересно узнать, что такое «датасет», а также зачем вообще нужен Machine Learning и почему в последнее время он набирает все большую популярность, прошу под кат. Мы будем использовать Python 3, так это как достаточно простой инструмент для изучения машинного обучения.Для кого эта статья?
Каждый, кому будет интересно затем покопаться в истории за поиском новых фактов, или каждый, кто хотя бы раз задавался вопросом «как же все таки это, машинное обучение, работает», найдёт здесь ответ на интересующий его вопрос. Вероятнее всего, опытный читатель не найдёт здесь для себя ничего интересного, так как программная часть
В цифрах
С каждым годом растёт потребность в изучении больших данных как для компаний, так и для активных энтузиастов. В таких крупных компаниях, как Яндекс или Google, всё чаще используются такие инструменты для изучения данных, как язык программирования R, или библиотеки для Python (в этой статье я привожу примеры, написанные под Python 3). Согласно Закону Мура (а на картинке — и он сам), количество транзисторов на интегральной схеме удваивается каждые 24 месяца. Это значит, что с каждым годом производительность наших компьютеров растёт, а значит и ранее недоступные границы познания снова «смещаются вправо» — открывается простор для изучения больших данных, с чем и связано в первую очередь создание «науки о больших данных», изучение которого в основном стало возможным благодаря применению ранее описанных алгоритмов машинного обучения, проверить которые стало возможным лишь спустя полвека. Кто знает, может быть уже через несколько лет мы сможем в абсолютной точности описывать различные формы движения жидкости, например.
Анализ данных — это просто?
clf = RandomForestClassifier() clf.fit(X, y)
Вот мы и создали простейшую машину, способную предсказывать (или классифицировать) значения аргументов по их признакам.
— Если все так просто, почему до сих пор не каждый предсказывает, например, цены на валюту?
С этими словами можно было бы закончить статью, однако делать я этого, конечно же, не буду (буду конечно, но позже) существуют определенные нюансы выполнения корректности прогнозов для поставленных задач. Далеко не каждая задача решается вот так легко (о чем подробнее можно прочитать здесь)
Ближе к делу
— Получается, зарабатывать на этом деле я не сразу смогу?
Да, до решения задач за призы в $100 000 нам ещё далеко, но ведь все начинали с чего-то простого.
Итак, сегодня нам потребуются:
- Python 3 (с установленной pip3)
- Jupyter
- SKlearn, NumPy и matplotlib
Если чего-то нет: ставим всё за 5 минутДля начала, скачиваем и устанавливаем Python 3 (при установке не забудьте поставить pip и добавить в PATH, если скачали установщик Windows). Затем, для удобства был взят и использован пакет Anaconda, включающий в себя более 150 библиотек для Python (ссылка на скачивание). Он удобен для использования Jupyter, библиотек numpy, scikit-learn, matplotlib, а так же упрощает установку всех. После установки, запускаем Jupyter Notebook через панель управления Anaconda, или через командную строку(терминал): «jupyter notebook».
Дальнейшее использование требует от читателя некоторых знаний о синтаксисе Python и его возможностях (в конце статьи будут представлены ссылки на полезные ресурсы, среди них и «основы Python 3»).
Как обычно, импортируем необходимые для работы библиотеки:
import numpy as np
from pandas import read_csv as read— Ладно, с Numpy всё понятно. Но зачем нам Pandas, да и еще read_csv?
Иногда бывает удобно «визуализировать» имеющиеся данные, тогда с ними становится проще работать. Тем более, большинство датасетов с популярного сервиса Kaggle собрано пользователями в формате CSV.
А вот так выглядит визуализированный pandas’ом датасетЗдесь колонка Activity показывает, идёт реакция или нет (1 при положительном, 0 при отрицательном ответе). А остальные колонки — множества признаков и соответствующие им значения (различные процентные содержания веществ в реакции, их агрегатные состояния и пр.)
— Помнится, ты использовал слово «датасет». Так что же это такое?
Датасет — выборка данных, обычно в формате «множество из множеств признаков» → «некоторые значения» (которыми могут быть, например, цены на жильё, или порядковый номер множества некоторых классов), где X — множество признаков, а y — те самые некоторые значения. Определять, например, правильные индексы для множества классов — задача классификации, а искать целевые значения (такие как цена, или расстояния до объектов) — задача ранжирования. Подробнее о видах машинного обучения можно прочесть в статьях и публикациях, ссылки на которые, как и обещал, будут в конце статьи.
Знакомимся с данными
Предложенный датасет можно скачать здесь. Ссылка на исходные данные и описание признаков будет в конце статьи. По представленным параметрам нам предлагается определять, к какому сорту относится то или иное вино. Теперь мы можем разобраться, что же там происходит:
path = "%путь к файлу%/wine.csv"
data = read(path, delimiter=",")
data.head()Работая в Jupyter notebook, получаем такой ответ:
Это значит, что теперь нам доступны данные для анализа. В первом столбце значения Grade показывают, к какому сорту относится вино, а остальные столбцы — признаки, по которым их можно различать. Попробуйте ввести вместо data.head() просто data — теперь для просмотра вам доступна не только «верхняя часть» датасета.
Простая реализация задачи на классификацию
Переходим к основной части статьи — решаем задачу классификации. Всё по порядку:
- создаём обучающую выборку
- пробуем обучить машину на случайно подобранных параметрах и классах им соответствующих
- подсчитываем качество реализованной машины
Посмотрим на реализацию (каждая выдержка из кода — отдельный Cell в notebook):
X = data.values[::, 1:14]
y = data.values[::, 0:1]
from sklearn.cross_validation import train_test_split as train
X_train, X_test, y_train, y_test = train(X, y, test_size=0.6)
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)Создаем массивы, где X — признаки (с 1 по 13 колонки), y — классы (0ая колонка). Затем, чтобы собрать тестовую и обучающую выборку из исходных данных, воспользуемся удобной функцией кросс-валидации train_test_split, реализованной в scikit-learn. С готовыми выборками работаем дальше — импортируем RandomForestClassifier из ensemble в sklearn. Этот класс содержит в себе все необходимые для обучения и тестирования машины методы и функции. Присваиваем переменной clf (classifier) класс RandomForestClassifier, затем вызовом функции fit() обучаем машину из класса clf, где X_train — признаки категорий y_train. Теперь можно использовать встроенную в класс метрику score, чтобы определить точность предсказанных для X_test категорий по истинным значениям этих категорий y_test. При использовании данной метрики выводится значение точности от 0 до 1, где 1 100% Готово!Про RandomForestClassifier и метод кросс-валидации train_test_split
При инициализации clf для RandomForestClassifier мы выставляли значения n_estimators=100, n_jobs = -1, где первый отвечает за количество деревьев в лесу, а второй — за количество участвующих в работе ядер процессора (при -1 задействованы все ядра, по умолчанию стоит 1). Так как мы работаем с данным датасетом и нам негде взять тестирующую выборку, используем train_test_split для «умного» разбиения данных на обучающую выборку и тестирующую. Подробнее про них можно узнать, выделив интересующий Вас класс или метод и нажав Shift+Tab в среде Jupyter.
— Неплохая точность. Всегда ли так получается?
Для решения задач на классификацию важным фактором является выбор наилучших параметров для обучающей выборки категорий. Чем больше, тем лучше. Но не всегда (об этом также можно прочитать подробнее в интернете, однако, скорее всего, я напишу об этом ещё одну статью, рассчитанную на начинающих).
— Слишком легко. Больше мяса!
Для наглядного просмотра результата обучения на данном датасете можно привести такой пример: оставив только два параметра, чтобы задать их в двумерном пространстве, построим график обученной выборки (получится примерно такой график, он зависит от обучения):
Да, с уменьшением количества признаков, падает и точность распознавания. И график получился не особенно-то красивым, но это и не решающее в простом анализе: вполне наглядно видно, как машина выделила обучающую выборку (точки) и сравнила её с предсказанными (заливка) значениями.Реализация здесь
from sklearn.preprocessing import scale
X_train_draw = scale(X_train[::, 0:2])
X_test_draw = scale(X_test[::, 0:2])
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
clf.fit(X_train_draw, y_train)
x_min, x_max = X_train_draw[:, 0].min() - 1, X_train_draw[:, 0].max() + 1
y_min, y_max = X_train_draw[:, 1].min() - 1, X_train_draw[:, 1].max() + 1
h = 0.02
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
pred = clf.predict(np.c_[xx.ravel(), yy.ravel()])
pred = pred.reshape(xx.shape)
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
plt.figure()
plt.pcolormesh(xx, yy, pred, cmap=cmap_light)
plt.scatter(X_train_draw[:, 0], X_train_draw[:, 1],
c=y_train, cmap=cmap_bold)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Score: %.0f percents" % (clf.score(X_test_draw, y_test) * 100))
plt.show()Предлагаю читателю самостоятельно узнать почему и как он работает.
Последнее слово
Надеюсь, данная статья помогла хоть чуть-чуть освоиться Вам в разработке простого машинного обучения на Python. Этих знаний будет достаточно, чтобы продолжить интенсивный курс по дальнейшему изучению BigData+Machine Learning. Главное, переходить от простого к углубленному постепенно. А вот полезные ресурсы и статьи, как и обещал:
Материалы, вдохновившие автора на создание данной статьи
Исторические очерки:
Подробнее про машинное обучение:
Изучаем python, или до работы с данными:
Однако для наилучшего освоения библиотеки sklearn пригодится знание английского: в этом источнике собраны все необходимые знания (так как это API reference).
Более углубленное изучение использования машинного обучения с Python стало возможным, и более простым благодаря преподавателям с Яндекса — этот курс обладает всеми необходимыми средствами объяснения, как же работает вся система, рассказывается подробнее о видах машинного обучения итд.
Файл сегодняшнего датасета был взят отсюда и несколько модифицирован.
Где брать данные, или «хранилище датасетов» — здесь собрано огромное количество данных от самых разных источников. Очень полезно тренироваться на реальных данных.
Буду признателен за поддержку по улучшению данной статьи, а так же готов к любому виду конструктивной критики.
Профессия Data Scientist: машинное обучение
Валентин
Пановский
Chief Data Scientist в Skillbox. Блоки «Аналитика и машинное обучение. Начальный уровень» Михаил
Овчинников
Главный методист технического направления Skillbox Алла
Тамбовцева
Преподаватель НИУ ВШЭ Александр
Джумурат
Руководитель команды разработки рекомендательной системы в ivi.ru Дмитрий
Коробченко
Deep Learning R&D инженер и менеджер в NVIDIA. Блок «Машинное обучение. Средний уровень» Алексей
Мастов
Deep Learning инженер в NVIDIA. Блок «Машинное обучение. Средний уровень» Лидия
Храмова
Team Lead Data Scientist группы бизнес-моделирования в QIWI. Блок «Статистика и теория вероятностей» Адель
Томилова
Data Scientist в KPMG. Блок «Аналитика. Начальный уровень» Николай
Голов
Chief Data Architect в ManyChat. Блок «Аналитика. Начальный уровень» Артемий
Козырь
Старший аналитик данных Wheely. Блок «Аналитика. Начальный уровень» Андрей
Мещеряков
Data Scientist в EPAM. Блок «Аналитика. Начальный уровень»Машинное обучение для людей :: Разбираемся простыми словами :: Блог Вастрик.ру
💰 Спонсоры статьи: Фонд развития онлайн-образования
Если вы хотите углубиться в машинное обучение и научиться применять его на практикте, то ребята запустили курс «Машинное обучение и анализ данных» с преподавателями из Яндекса.
💰Специализация Data Scientist on SkillFactory
В SkillFactory стартовал набор на новый онлайн-курс, где вы пройдете полный цикл обучения, начиная с изучения Python для анализа данных, классического машинного обучения и заканчивая нейросетями и диплёрнингом. Специальных знаний чтобы начать не потребуется, всему научат на месте.
Снова разберём на Олегах.
Предположим, Олег хочет купить автомобиль и считает сколько денег ему нужно для этого накопить. Он пересмотрел десяток объявлений в интернете и увидел, что новые автомобили стоят около $20 000, годовалые — примерно $19 000, двухлетние — $18 000 и так далее.
В уме Олег-аналитик выводит формулу: адекватная цена автомобиля начинается от $20 000 и падает на $1000 каждый год, пока не упрётся в $10 000.
Олег сделал то, что в машинном обучении называют регрессией — предсказал цену по известным данным. Люди делают это постоянно, когда считают почём продать старый айфон или сколько шашлыка взять на дачу (моя формула — полкило на человека в сутки).
Да, было бы удобно иметь формулу под каждую проблему на свете. Но взять те же цены на автомобили: кроме пробега есть десятки комплектаций, разное техническое состояние, сезонность спроса и еще столько неочевидных факторов, которые Олег, даже при всём желании, не учел бы в голове.
Люди тупы и ленивы — надо заставить вкалывать роботов. Пусть машина посмотрит на наши данные, найдёт в них закономерности и научится предсказывать для нас ответ. Самое интересное, что в итоге она стала находить даже такие закономерности, о которых люди не догадывались.
Так родилось машинное обучение.
17 примеров применения машинного обучения в 5 отраслях бизнеса
Машинное обучение (machine learning) лежит в основе многих инновационных технологий искусственного интеллекта. Программы, разработанные с помощью ML, умеют предсказывать поломки оборудования, предугадывать поведение клиентов и принимать логические и аналитические решения почти как люди.
Расскажем, как компании используют machine learning и покажем примеры применения машинного обучения на реальных кейсах.
Машинное обучение в промышленности: управление производством, минимизация простоев и аварий
Минимизация простоев на производстве. Простои из-за поломок, сбоев или нехватки сырья могут стоить заводу миллионы долларов. Машинное обучение помогает их предотвратить. Для этого с датчиков на оборудовании собирают данные, а потом смотрят, при каких показателях возникают сбои. В будущем с помощью этой информации можно предсказать, когда и почему случится простой, как его избежать.
К примеру, может оказаться, что перед поломкой оборудования в цехе всегда поднимается температура. Тогда при повышении температуры система оповестит инженеров, а они вовремя предотвратят проблему.
Чтобы избежать простоев при добыче полезных ископаемых, производитель нефтегазового оборудования GE Oil&Gas использует индустриальный интернет вещей и машинное обучение. Платформа компании собирает данные о состоянии нефтедобычи, а затем составляет расписание диагностических проверок и помогает выявлять неисправности до того, как они произойдут. Эта же платформа помогла Кувейтской нефтяной компании увеличить добычу газа на 2–5%, а нефтяной компании из Малайзии Petronas — снизить расходы на техобслуживание на 10%.Создание системы управления производством. С помощью датчиков и машинного обучения можно не только выполнять узкие задачи, например предотвращать поломки, но и управлять всем производством:
- снижать процент бракованных деталей: анализировать, почему происходит брак и как его избежать;
- оптимизировать отдельные этапы, чтобы они занимали меньше времени;
- использовать меньше материалов для производства, а значит, сократить расходы;
- отслеживать состояние оборудования, фиксировать его КПД и загруженность;
- автоматизировать отдельные этапы производства.
Производитель микроконтроллеров Simatic использует платформу на базе IoT и машинного обучения. Она помогает собирать и анализировать информацию с датчиков на оборудовании в реальном времени. Это помогло на 75% автоматизировать производство тысяч видов продукции, в 9 раз увеличить объем производства при тех же площадях и персонале и почти на 100% сократить брак.
Аналогичную IoT-платформу можно подключить в Mail.ru Cloud Solutions. Она позволяет собирать, обрабатывать и анализировать данные с миллионов любых устройств, использовать машинное обучение для прогнозирования работы оборудования и других задач.Выявление угроз безопасности. Машинное обучение помогает сделать производство безопаснее: выявлять незначительные изменения в работе оборудования и вовремя оповещать о возможной катастрофе.
Например, энергетическая компания Shell использует машинное обучение, нейронные сети и IoT, чтобы автоматически выявлять угрозы безопасности и оповещать о них сотрудников. Так они успевают среагировать на проблему еще до того, как произойдет катастрофа. Кстати, Shell также использует machine learning для оптимизации производства и добычи полезных ископаемых.Разведка новых месторождений. Одна из главных проблем нефтегазовой и горнодобывающей промышленности — сложность в обнаружении новых месторождений.
Машинное обучение помогает ускорить этот процесс. На основе данных о прошлых месторождениях искусственный интеллект строит модели, которые с высокой точностью предсказывают, где искать новые залежи газа или руды.
У компании «Газпром» есть проект «Цифровой керн». Это цифровая лаборатория, где анализируют пробы пласта с помощью технологий машинного обучения. Алгоритмы моделируют условия там, откуда взята проба, и помогают создать цифровой двойник месторождения. С его помощью оценивают запасы полезных ископаемых и подбирают индивидуальный подход к разработке. Это позволяет в 1,5-2 раза увеличить добычу полезных ископаемых из конкретного месторождения, а также искать новые.
10 курсов по машинному обучению на лето / Блог компании Университет ИТМО / Хабр
За последние десятилетия с помощью машинного обучения создали самоуправляемые автомобили, системы распознавание речи и эффективный поиск. Сейчас это одна из самых быстроразвивающихся и перспективных сфер на стыке компьютерных наук и статистики, которая активно используется в искусственном интеллекте и data science. Методы машинного обучения используются в науке, технике, медицине, ритейле, рекламе, генерации мультимедиа и других областях.Команда Университета ИТМО собрала десять курсов по машинному обучению, которые можно успеть пройти до конца лета. Одним они помогут войти в профессию, а другим — углубиться в нее.
1. «Введение в машинное обучение»
Площадка: Coursera
Автор: Высшая школа экономики, Школа анализа данных Яндекс
Длительность: 7 недель, 3-5 часов в неделю
Стоимость: бесплатно
Язык: русский
На курсе рассказывает преимущественно про основные типы задач машинного обучения: классификацию, регрессию и кластеризацию. Преподаватели из Яндекса и Высшей школы экономики объясняют основные методы и рассказывают про их особенности, учат оценивать качество моделей и понимать, для решения какой задачи подходит каждая из них. Программа рассчитана на семь недель, но если постараться, то можно закончить курс до 1 сентября. Курс ориентирован на слушателей, которые знакомы с Python, так как используются его библиотеки numpy, pandas и scikit-learn.
2. Введение в машинное обучение от GL4G
Площадка: Great Learning
Автор: Great Learning
Длительность: 1,5 часа
Стоимость: бесплатно
Язык: английский
Короткий курс предназначен для тех, кто интересуется машинным обучением, но пока еще не знает, с чего начать. Программа состоит из 12 видеоуроков и объясняет, что такое машинное обучение и как алгоритм может учиться, рассказывает основную терминологию и методы, а также дает практические упражнения.
3. Машинное обучения от А до Я: применение Python и R в науке о данных
Площадка: Udemy
Автор: Кирилл Еременко,, Хаделин де Понтевес, команда SuperDataScience
Длительность: 41 час видеолекций
Стоимость: $10,99
Язык: английский
Курс разработан двумя дата-сайентистами, чтобы объяснить сложную теорию, алгоритмы и программирование с использованием библиотек машинного обучения. Программа состоит из десяти частей, в которых рассматривается обработка данных, регрессия, классификация, кластеризация, обучение с подкреплением, обработка естественного языка и глубокое обучение. На курсе есть практические упражнения и шаблоны кода для Python и R. Большое внимание уделяется выбору правильной модели для каждого типа задач.
4. Bootcamp-тренировка: Python для науки о данных и машинного обучения
Площадка: Udemy
Автор: Хосе Портилья
Длительность: 21,5 часов видеолекций
Стоимость: $10,99
Язык: английский
Программа курса помогает понять, как использовать Python для анализа данных, создания визуализации и использования алгоритмов машинного обучения. На курсе используются NumPy, Seaborn, Matplotlib, Pandas, Scikit-Learn, Machine Learning, Plotly, Tensorflow и другие инструменты. Также слушателям расскажут про обработку естественного языка, искусственный интеллект и глубокое обучение.
5. Наука о данных, глубокое обучение и машинное обучение с помощью Python
Площадка: Udemy
Автор: Фрэнк Кейн
Длительность: 12 часов видеолекций
Стоимость: $10,99
Язык: английский
На курсе рассказывается об использовании искусственного интеллекта и машинного обучения для решения бизнес-задач. Преподаватель Фрэнк Кейн девять лет работал в Amazon и IMDb, создавая рекомендательные системы. Каждая концепция описывается на простом языке без сложных математических терминов. После вводной части демонстрируется использование кода на Python. Основное внимание уделяется практическому пониманию и применению алгоритмов машинного обучения. В конце курса слушателям предлагают работу над итоговым проектом, чтобы применить новые знания.
6. Курс машинного обучения от Google
Площадка: Google
Автор: Google
Длительность: 15 часов видеолекций
Стоимость: бесплатно
Язык: английский
Компания предлагает быстрое и практическое введение в машинное обучение с использованием API TensorFlow. Курс включает серию уроков с видеолекциями, реальными задачами и практическими упражнениями. Всего слушателям необходимо прослушать 25 уроков и выполнить 40 упражнений. Для всех алгоритмов предлагается интерактивная визуализация.
7. Структурирование проектов по машинному обучению
Площадка: Coursera
Автор: deeplearning.ai
Длительность: две недели
Стоимость: подписка на Coursera 3 039 ₽ в месяц
Язык: английский
Преподаватели курса из Стэнфордского университета расскажут, как построить работу команды по машинному обучения. За две недели слушатели научатся находить ошибки в системе машинного обучение, расставлять приоритеты в направлении работы и понимать сложные детали машинного обучения, например, невалидные обучающие наборы данных.
8. Использование глубокого обучения в творчестве с помощью TensorFlow
Площадка: Kadenze
Автор: Google Magenta
Длительность: пять сессий по 12 часов
Стоимость: бесплатно
Язык: английский, русские субтитры
Курс создан при поддержке проекта Magenta от Google, в рамках которого компания пытается создать «творческий компьютер». Преподаватели рассказывают про основные компоненты глубокого обучения, которые необходимы для построения алгоритмов: сверточные сети, вариационные автокодеры, генеративные состязательные сети и рекурсивные нейросети. Внимание уделяется творчеству нейросетей. Например, работе с изображением и созданию контента, который будет соответствовать эстетике или содержимому другого изображения.
9. Статистическое машинное обучение
Площадка: YouTube
Автор: Университет Карнеги — Меллона
Длительность: 24 лекции по 1,5 часа
Стоимость: бесплатно
Язык: английский, русские субтитры
На YouTube есть запись цикла лекций профессора Департамента статистики и факультета машинного обучения Университета Карнеги-Меллона Ларри Вассермана. Курс рассчитан на людей с продвинутыми знаниями математики и программирования, так как ориентирован на интеграцию статистики и машинного обучения. Предпосылкой к курсу служат лекции «Промежуточная статистическая теория» и «Введение в машинное обучение».
10. «Принципы машинного обучения»
Площадка: EdX
Автор: Microsoft
Длительность: 6 недель, 2–4 часа в неделю
Стоимость: бесплатно, сертификат $99
Язык: английский
Курс входит в сертификацию Microsoft в области науки о данных. На нем рассказывают, как создавать и работать с моделями машинного обучения с использованием Python, R и Azure Machine Learning. Преподаватели рассказывают о классификации, регрессии в машинном обучении, контролируемых моделях, системах нелинейного моделирования, кластеризации и разработке рекомендаций.
Для тех, кому ближе оффлайн-встречи, Университет ИТМО со 2 по 15 августа проводит в Санкт-Петербурге Летнюю школу машинного обучения на базе Центра речевых технологий. Слушатели получат практический опыт применения методов и алгоритмов глубокого обучения для анализа аудиовизуальных данных для распознавания эмоций.
Требования к участникам:
— студенты старших курсов;
— владение Python;
— имеют опыт применения современных методов машинного обучения;
— огромное желание развиваться в области аудио- и видеоаналитики.
Прием заявок продлится до 23 июля. Зарегистрироваться можно на сайте. Участие в Школе бесплатное. Также организаторы оплачивают проживание в общежитии Университета ИТМО. А за лучшее решение тестового задания — и транспортные расходы.
Введение в машинное обучение — Основы и Примеры
Перевод статьи разработчика алгоритмов машинного обучения, бизнес-консультанта и популярного автора Ганта Лаборде «Machine Learning: from Zero to Hero».
Начнешь c “Зачем?”, придешь к “Я готов!”
Если вы мало знаете об основах машинного обучения, то эта статья как раз для вас. Я буду постепенно излагать введение в машинное обучение, склеивая дружелюбный текст с вдохновляющими примерами. Присядь и расслабься, это займет некоторое время.
Почему машинное обучение сейчас в тренде
Искусственный интеллект (далее ИИ) всегда имел применение, начиная от перемещения ракетки в пинг понге и заканчивая выполнением комбо в Street Fighter.
ИИ опирается на представление программиста о том, как программа должна себя вести. Но как часто становится понятно, не все программисты талантливы в программировании искусственного интеллекта. Стоит только погуглить “эпичные фейлы в играх” и наткнуться на глюки в физике, даже у опытных разработчков.
Несмотря на это, компьютер поддается обучению для игры в видеоигры, понимания языка и распознавания людей и предметов. Этот навык исходит из старой концепции, которая только недавно получила необходимые вычислительные мощности для существования вне теории. Я имею в виду машинное обучение (ML, Machine learning).
Не продумывайте сложные алгоритмы самостоятельно — обучите компьютер создавать собственные сложные алгоритмы. Как это будет работать? Алгоритм не столько написан, сколько выведен. Посмотри это короткое видео, с помощью анимации оно должно дать понимание общего принципа создания ИИ.
И как возможно такое, что мы даже не понимаем устройство рабочего алгоритма? Прекрасным визуальным примером был ИИ, написанный для прохождения игр Марио. Люди хорошо знают, как нужно играть в сайд-скроллеры, но это безумие пытаться определить стратегию игры для ИИ.
Впечатлены? Как это возможно? К счастью, Элон Маск представил некоммерческую компанию, которая предоставляет возможность подключения ИИ к любым играм и задачам с помощью дюжины строк кода. Посмотрите, как это работает.
Зачем следует использовать машинное обучение?
У меня два ответа на вопрос, почему вас должно это заботить. Во-первых, с помощью машинного обучения компьютеры выполняют задачи, которые раньше они не выполняли. Если хотите создать что-то новое для всего мира, вы можете сделать это, используя машинное обучение.
Во-вторых, если не влияете на мир, мир повлияет на вас. Компании инвестируют в ML, и эти инвестиции уже меняют мир. Лидеры мысли предупреждают, что нельзя позволить алгоритмам машинного обучения быть в тени. Представьте себе, если бы монополия из нескольких корпораций контролировала Интернет. Если мы не “возьмемся за оружие”, наука не будет нашей.
Christian Heilmann высказал правильную мысль в беседе о машинном обучении:
“Можно надеяться, что остальные будут использовать эту мощь только в мирных целях. Я, например, не рассчитываю на эту милость. Предпочитаю играть и быть частью этой революции. И вы присоединяйтесь”.
Хорошо, теперь я заинтересован…
Концепт полезный и веселый. Но что за дичь там в действительности творится? Как это работает? Если хочешь сразу погрузиться, советую пропустить раздел и перейти к следующему “С чего мне начать?”. Если вы уже мотивированы делать модели ML, эти видео не понадобятся.
Если ты все еще пытаешься понять, как такое вообще возможно, следующее видео проведет тебя через логику работы алгоритмов, используя классическую задачу ML — проблему распознавания рукописного текста.
Классно, не правда ли? Видео демонстрирует, что каждый новый слой становится проще, а не сложнее. Будто бы функция пережевывает данные в более мелкие кусочки, которые потом выстраиваются в задуманный концепт. Поиграйтесь с этим процессом здесь.

Занятно наблюдать, как данные проходят через натренированную модель, но ты также можешь пронаблюдать тренировку собственной нейронной сети.
Классический пример машинного обучения в действии — датасет прямиком из 1936-го года, называемый ирисами Фишера. На презентации эксперта JavaFX, посвященной машинному обучению, я узнал, как использовать этот инструмент, чтобы визуализировать прикрепление и обратное распространение весов к нейронам в нейронной сети. Понаблюдайте за тем, как тренируется нейронная сеть.
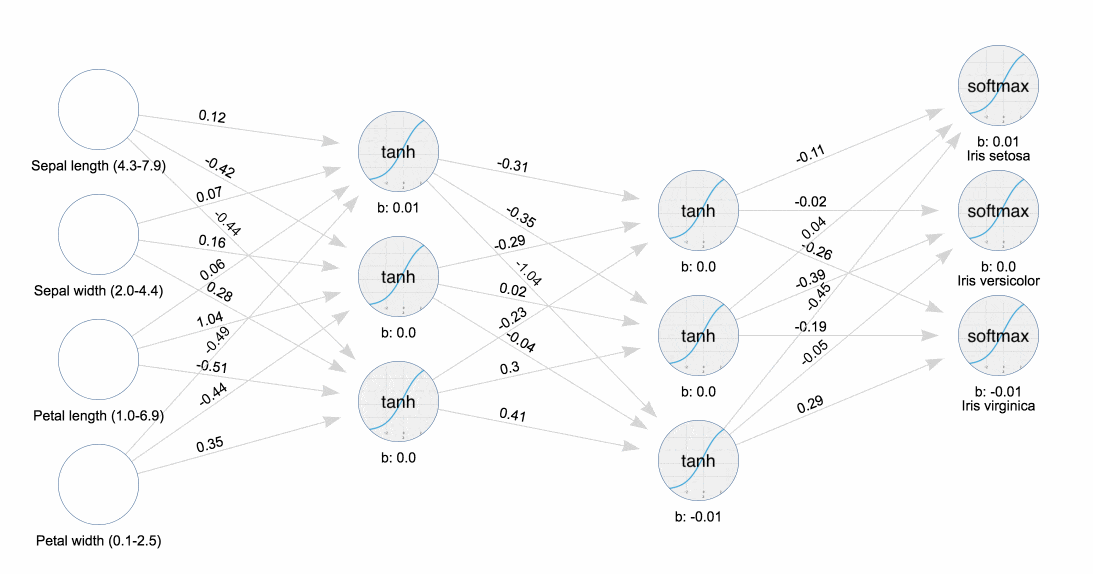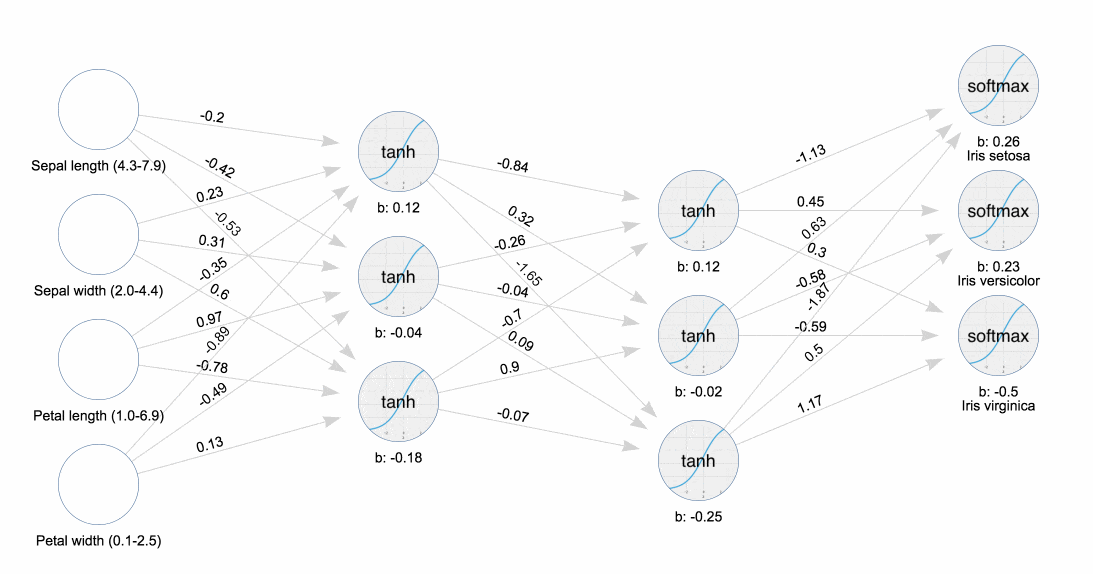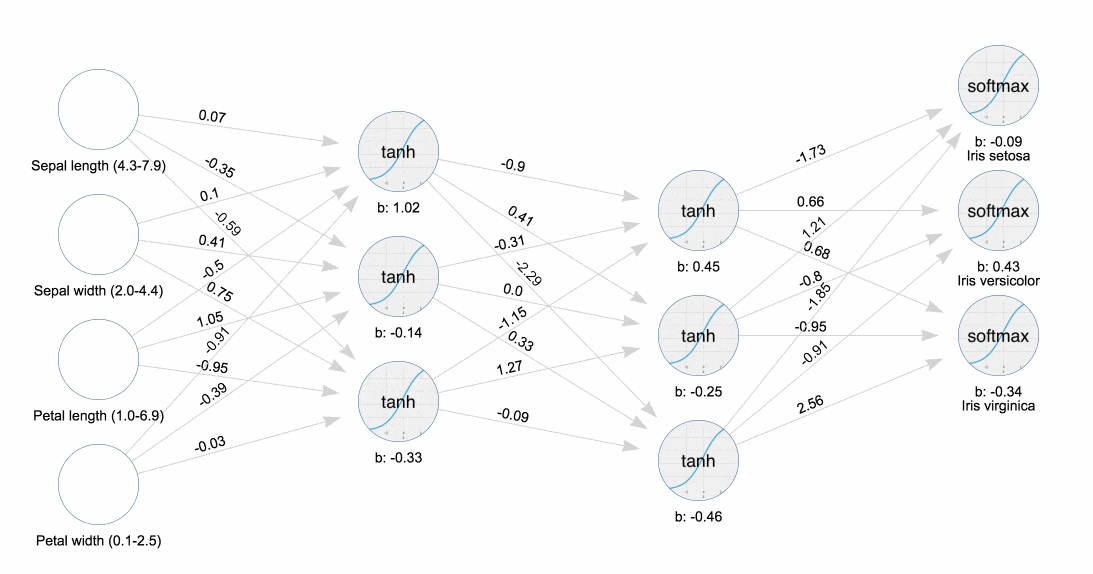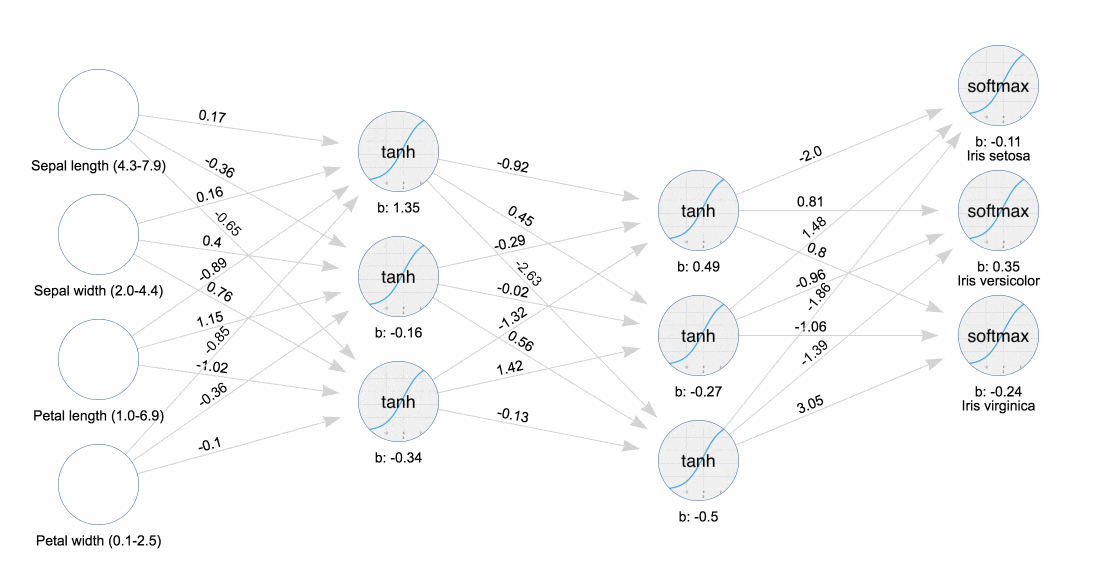 Обучение нейронной сети Ирисы
Обучение нейронной сети ИрисыГотовы стать Эйнштейном новой эры? Прорывы происходят каждый день, поэтому начинайте сейчас.
С чего мне начать?
Доступных ресурсов много. Я рекомендую два подхода.
Основы
С этим подходом вы поймете машинное обучение вплоть до алгоритмов и математики. Знаю, этот путь кажется тяжким, но зато как круто будет по-настоящему проникнуться в детали и кодить с нуля!
Если хочешь получить силу в этой сфере и вести серьезные обсуждения о ML, то этот путь для тебя. Советую пройти курс по искусственным нейронным сетям. Этот подход позволит вам изучать ML на вашем телефоне, убивая время, например, в очереди. Одновременной проходите курс о машинном обучении.

Курсы могут показаться слишком сложными. Для многих это причина не начинать, но для других это повод пройти это испытание и получить сертификат о том, что вы справились. Все вокруг будут впечатлены, если справитесь, потому что это действительно не просто. Но если вы это сделаете, получите понимание о работе ML, которое позволит вам успешно применять его.
Гонщик
Если вы не заинтересованы в написании алгоритмов, но хотите использовать их для создания сайтов и приложений, то используйте TensorFlow и погрузитесь в crash course.
TensorFlow — это библиотека с открытым исходным кодом для машинного обучения. Ее можно использовать любым способом, даже с JavaScript. А вот crash source.
Услуги ML
Если проходить курсы не ваш стиль, то пользуйтесь ML как услугой. Технические гиганты владеют натренированными моделями, а сектор услуг по машинному обучению растет.
Предупреждаю, что нет гарантии, что ваши данные будут в безопасности или вообще останутся вашими, но предложения услуг по ML очень привлекательны, если вы заинтересованы в результате и имеете возможность загрузить данные на Amazon/Microsoft/Google.
Давайте быть созидателями
Я все еще новичок в мире ML и счастлив осветить путь для других, путь, который даст нам возможность завоевать эру, в которой мы оказались.
Курсы по data science
Крайне важно быть на связи со знающими людьми, если изучаете это ремесло. Без дружеских лиц и ответов, любая задача покажется трудной. Возможность спросить и получить ответ кардинально облегчает ситуацию. Дружелюбные люди всегда помогут дельными советами.
Надеюсь, эта статья вдохновила вас и ваше окружение изучать ML!
Машинное обучение для начинающих. Машинное обучение определялось в 90-х… | Дивянш Двиведи
Машинное обучение было определено в 90-х годах Артуром Самуэлем , описанным как: « — это область обучения, которая дает компьютеру возможность самообучения без явного программирования », это означает передачу знаний машинам без жесткого программирования.
«Считается, что компьютерный алгоритм / программа учится на основе показателя производительности P и испытывает E с некоторым классом задач T, если его производительность в задачах в T, измеренная с помощью P, улучшается с опытом E. — Том М. Митчелл.
Машинное обучение в основном ориентировано на разработку компьютерных программ, которые могут научиться расти и меняться при взаимодействии с новыми данными. Машинное обучение изучает алгоритмы самообучения. Он может быстрее обрабатывать массивные данные с помощью алгоритма обучения. Например, он будет заинтересован в том, чтобы научиться выполнять задачу, делать точные прогнозы или вести себя разумно.
Объем данных растет день ото дня, и невозможно понять все данные с более высокой скоростью и большей точностью.Более 80% данных неструктурированы, то есть аудио, видео, фотографии, документы, графики и т. Д. Человеческий мозг не может найти закономерности в данных на планете Земля. Данных было очень много, время, необходимое для вычислений, увеличилось бы, и именно здесь приходит на помощь машинное обучение, чтобы помочь людям с важными данными за минимальное время.
Машинное обучение — это подраздел искусственного интеллекта. Применяя ИИ, мы хотели создавать более совершенные и интеллектуальные машины. Это похоже на то, как новый ребенок учится у самого себя.Таким образом, в машинном обучении появилась новая возможность для компьютеров. И теперь машинное обучение присутствует во многих сегментах технологий, что мы даже не осознаем этого, используя его.
Машинное обучение в основном делится на три категории, а именно:
Типы машинного обученияКонтролируемое обучение — это первый тип машинного обучения, в котором помечает данные , используемые для обучения алгоритмов. При обучении с учителем алгоритмы обучаются с использованием отмеченных данных, где вход и выход известны.Мы вводим данные в алгоритм обучения как набор входных данных, которые называются функциями, обозначенными X, вместе с соответствующими выходными данными, которые обозначены Y, и алгоритм учится, сравнивая свое фактическое производство с правильными выходными данными, чтобы найти ошибки. . Затем он соответствующим образом изменяет модель. Необработанные данные разделены на две части. Первая часть предназначена для обучения алгоритма, а другая область используется для тестирования обученного алгоритма.
Машинное обучение с учителемОбучение с учителем использует шаблоны данных для прогнозирования значений дополнительных данных для меток.Этот метод обычно используется в приложениях, где исторические данные предсказывают вероятные предстоящие события. Пример: — Он может предвидеть, когда транзакции могут быть мошенническими или какой страховой клиент, как ожидается, подаст иск.
Контролируемое обучение в основном разделено на две части, а именно:
Типы контролируемого обученияРегрессия — это тип контролируемого обучения, в котором используются помеченные данные, и эти данные используются для прогнозирования в непрерывной форме. .Вывод входных данных всегда продолжается, а график является линейным. Регрессия — это форма метода прогнозного моделирования, который исследует взаимосвязь между зависимой переменной [ Outputs ] и независимой переменной [ Inputs ]. Этот метод используется для прогнозирования погоды, моделирования временных рядов, оптимизации процессов. Пример: — Одним из примеров метода регрессии является прогноз цен на дом, где цена дома будет прогнозироваться на основе таких входных данных, как количество комнат, местонахождение, удобство транспорта, возраст дома, площадь дома.
Типы алгоритмов регрессии: —
В машинном обучении присутствует множество алгоритмов регрессии, которые будут использоваться для различных приложений регрессии. Вот некоторые из основных алгоритмов регрессии:
1.1.1. Простая линейная регрессия: —
В простой линейной регрессии мы прогнозируем оценки одной переменной на основе оценок второй переменной. Переменная, которую мы прогнозируем, называется критериальной переменной и обозначается буквой Y. Переменная, на которой мы основываем наши прогнозы, называется переменной-предиктором и обозначается как X.
1.1.2. Множественная линейная регрессия: —
Множественная линейная регрессия — это один из алгоритмов метода регрессии и наиболее распространенная форма анализа линейной регрессии. В качестве прогнозного анализа множественная линейная регрессия используется для объяснения взаимосвязи между одной зависимой переменной с двумя или более чем двумя независимыми переменными. Независимые переменные могут быть непрерывными или категориальными.
1.1.3. Полиномиальная регрессия: —
Полиномиальная регрессия — это еще одна форма регрессии, в которой максимальная степень независимой переменной больше единицы.В этом методе регрессии наиболее подходящая линия не является прямой линией, а имеет форму кривой.
1.1.4. Поддерживающая векторная регрессия: —
Опорная векторная регрессия может применяться не только к задачам регрессии, но также использоваться в случае классификации. Он содержит все функции, которые характеризуют алгоритм максимальной маржи. Машинное отображение с линейным обучением превращает нелинейную функцию в многомерное пространство функций, индуцированное ядром. Емкость системы контролировалась параметрами, не зависящими от размерности пространства признаков.
1.1.5. Регрессия по гребню: —
Регрессия по гребню — один из алгоритмов, используемых в технике регрессии. Это метод анализа данных множественной регрессии, страдающих мультиколлинеарностью. Добавление степени смещения к расчетам регрессии снижает стандартные ошибки. В конечном итоге расчет будет более надежным.
1.1.6. Лассо-регрессия: —
Лассо-регрессия — это тип линейной регрессии, в которой используется усадка.Сжатие — это сужение значений данных к центральной точке, например к среднему значению. Процедура лассо поощряет простые разреженные модели (то есть модели с меньшим количеством параметров). Этот конкретный тип регрессии хорошо подходит для моделей, демонстрирующих высокий уровень мультиколлинеарности, или когда вы хотите автоматизировать определенные части выбора модели, такие как выбор переменных / исключение параметров.
1.1.7. Регрессия ElasticNet: —
Эластичная чистая регрессия объединила нормы L1 (LASSO) и нормы L2 (гребенчатая регрессия) в модель со штрафами для обобщенной линейной регрессии, что придает ей разреженность (L1) и надежность (L2) свойства.
1.1.8. Байесовская регрессия: —
Байесовская регрессия позволяет разумно естественному механизму выжить при недостаточном количестве или плохо распределенных данных. Это позволит вам установить коэффициенты на априорность и шум, чтобы априорные значения могли взять верх при отсутствии данных. Что еще более важно, вы можете спросить байесовскую регрессию, в каких частях (если таковые имеются) ее соответствия данным, она уверена, а какие части очень неопределенны.
1.1.9. Регрессия дерева решений: —
Дерево решений строит форму, подобную древовидной структуре, из регрессионных моделей.Он разбивает данные на более мелкие подмножества, и в то же время постепенно развивается связанное дерево решений. В результате получается дерево с узлами решений и листовыми узлами.
1.1.10. Регрессия случайного леса: —
Случайный лес также является одним из алгоритмов, используемых в технике регрессии, и это очень гибкий и простой в использовании алгоритм машинного обучения, который производит даже без настройки гиперпараметров. Кроме того, этот алгоритм широко используется из-за своей простоты и того факта, что его можно использовать как для задач регрессии, так и для классификации.Лес, который он строит, представляет собой ансамбль деревьев решений, большую часть времени тренируемый с помощью метода «мешков».
Классификация — это тип контролируемого обучения, в котором могут использоваться помеченные данные, и эти данные используются для прогнозирования в прерывистой форме. Вывод информации не всегда является непрерывным, а график является нелинейным. В методе классификации алгоритм учится на вводимых ему данных, а затем использует это обучение для классификации нового наблюдения. Этот набор данных может быть просто двухклассовым, а может быть и многоклассовым.Пример: — Одним из примеров проблем классификации является проверка того, является ли электронное письмо спамом или нет, путем обучения алгоритма для различных слов спама или писем.
Типы алгоритмов классификации: —
В машинном обучении присутствует множество алгоритмов классификации, которые используются для различных приложений классификации. Вот некоторые из основных алгоритмов классификации:
1.2.1. Логистическая регрессия / Классификация: —
Логистическая регрессия подпадает под категорию обучения с учителем; он измеряет взаимосвязь между зависимой переменной, которая является категориальной с одной или несколькими независимыми переменными, путем оценки вероятностей с использованием логистической / сигмоидной функции.Логистическая регрессия обычно может использоваться, когда зависимая переменная является двоичной или дихотомической. Это означает, что зависимая переменная может принимать только два возможных значения, например «Да или Нет», «Живой или мертвый».
1.2.2.K-Nearest Neighbours: —
Алгоритм KNN — один из самых простых алгоритмов классификации и один из наиболее часто используемых алгоритмов обучения. Большинство голосов за объект классифицируется его соседями с целью присвоения классу, наиболее распространенному среди его k ближайших соседей.Его также можно использовать для регрессии — вывод — это значение объекта (предсказывает непрерывные значения). Это значение является средним (или медианным) преимуществом k ближайших соседей.
1.2.3. Машины опорных векторов: —
Машина опорных векторов — это тип классификатора, в котором дискриминантный классификатор формально определяется разделяющей гиперплоскостью. Алгоритм выводит оптимальную гиперплоскость, которая классифицирует новые примеры. В двухмерном пространстве эта гиперплоскость представляет собой линию, разделяющую плоскость на две части, причем каждый класс располагается по обе стороны.
1.2.4. Машины опорных векторов ядра: —
Алгоритм Kernel-SVM — это один из алгоритмов, используемых в методике классификации, и это набор математических функций, который определяется как ядро. Цель ядра — принять данные на вход и преобразовать их в требуемую форму. В разных алгоритмах SVM используются разные типы функций ядра. Эти функции могут быть разных типов. Например, линейные и нелинейные функции, полиномиальные функции, радиальная базисная функция и сигмоидальные функции.
1.2.5. Наивный Байес: —
Наивный Байесовский метод — это тип техники классификации, которая основана на теореме Байеса с предположением независимости между предсказателями. Проще говоря, наивный байесовский классификатор предполагает, что наличие определенной функции в классе не связано с наличием какой-либо другой функции. Наивная байесовская модель доступна для построения и особенно полезна для обширных наборов данных.
1.2.6. Дерево решений Классификация: —
Дерево решений создает модели классификации в виде древовидной структуры.Связанное дерево решений постепенно развивается и в то же время разбивает большой набор данных на более мелкие подмножества. Конечный результат — дерево с узлами решений и листовыми узлами. Узел принятия решения (например, Root) имеет две или более ветвей. Листовой узел представляет собой классификацию или решение. Первый узел решения в дереве, который соответствует лучшему предиктору, называется корневым узлом. Деревья решений могут обрабатывать как категориальные, так и числовые данные.
1.2.7. Классификация случайного леса: —
Случайный лес — это алгоритм обучения с учителем.Он создает лес и делает его чем-то случайным. Древесина, которую он строит, представляет собой ансамбль деревьев решений, причем большую часть времени алгоритм дерева решений, обученный методом «мешков», который представляет собой комбинацию моделей обучения, увеличивает общий результат.
Неконтролируемое обучение — это второй тип машинного обучения, в котором немаркированные данные используются для обучения алгоритма, что означает, что он применяется к данным, не имеющим исторических меток. То, что показывается, должно вычисляться алгоритмом.Цель состоит в том, чтобы изучить данные и найти в них некую структуру. При обучении без учителя данные не маркируются, и ввод необработанной информации непосредственно в алгоритм без предварительной обработки данных и без знания вывода данных и данных не может быть разделен на последовательность или тестовые данные. Алгоритм определяет данные и в соответствии с сегментами данных создает кластеры данных с новыми метками.
Неконтролируемое машинное обучениеЭтот метод обучения хорошо работает с транзакционными данными.Например, он может идентифицировать сегменты клиентов со схожими атрибутами, с которыми затем можно обращаться одинаково в маркетинговых кампаниях. Или он может найти основные качества, которые отделяют потребительские сегменты друг от друга. Эти алгоритмы также используются для сегментирования тем текста, рекомендаций по элементам и выявления выбросов в данных.
Неконтролируемое обучение в основном разделено на две части, а именно:
Кластеризация — это тип обучения без учителя, в котором используются немаркированные данные, и это процесс группировки похожих объектов вместе, а затем сгруппированные данные используются для создания кластеры.Цель этого метода машинного обучения без учителя — найти сходства в точках данных и сгруппировать похожие точки данных вместе, а также выяснить, к какому кластеру должны принадлежать новые данные.
Типы алгоритмов кластеризации: —
В машинном обучении присутствует множество алгоритмов кластеризации, которые используются для различных приложений кластеризации. Вот некоторые из основных алгоритмов кластеризации:
2.1.1.Кластеризация K-средств: —
Кластеризация K-средств — это один из алгоритмов метода кластеризации, в котором похожие данные группируются в кластер.K-means — это итеративный алгоритм кластеризации, целью которого является поиск локальных максимумов на каждой итерации. Он начинается с K в качестве ввода, который указывает количество групп, которые вы хотите увидеть. Введите k центроидов в случайных местах вашего пространства. Теперь, используя метод евклидова расстояния, вычислите расстояние между точками данных и центроидами и назначьте точку данных кластеру, который находится близко к нему. Пересчитайте центры кластера как среднее значение точек данных, прикрепленных к нему. Повторяйте до тех пор, пока не перестанут изменяться.
Кластеризация K-средних, показывающая 3 кластера2.1.2. Иерархическая кластеризация: —
Иерархическая кластеризация — это один из алгоритмов техники кластеризации, при котором похожие данные группируются в кластер. Это алгоритм, который строит иерархию кластеров. Этот алгоритм начинается со всех точек данных, назначенных отдельной группе. Затем две ближайшие группы объединяются в один кластер. В конце концов, этот алгоритм завершается, когда остается только один кластер. Начните с назначения каждой точки данных ее группе. Теперь найдите ближайшую пару в группе, используя евклидово расстояние, и объедините их в единый кластер.Затем вычислите расстояние между двумя ближайшими кластерами и объедините, пока все элементы не сгруппируются в один кластер.
Уменьшение размерности — это тип обучения без учителя, при котором размеры данных уменьшаются для удаления нежелательных данных из входных данных. Этот метод используется для удаления нежелательных свойств данных. Он относится к процессу преобразования набора данных, имеющих большие размеры, в данные с одинаковыми данными и небольшими размерами. Эти методы используются при решении задач машинного обучения для получения лучших функций.
Типы алгоритмов уменьшения размерности: —
В машинном обучении присутствует множество алгоритмов уменьшения размерности, которые применяются для различных приложений уменьшения размерности. Вот некоторые из основных алгоритмов уменьшения размерности:
2.2.1. Анализ главных компонентов: —
Анализ главных компонентов — это один из алгоритмов уменьшения размерности, в этом методе он преобразован в новый набор переменных из старых переменные, которые представляют собой линейную комбинацию вещественных переменных.Конкретный новый набор переменных известен как главные компоненты. В результате преобразования первый первичный компонент имеет наиболее значительную возможную дисперсию, а каждый последующий элемент имеет самую высокую разность потенциалов при ограничении, что он ортогонален вышеуказанным ингредиентам. Сохранение только первых компонентов m Линейный дискриминантный анализ является одним из алгоритмов уменьшения размерности, в котором он также создает линейные комбинации ваших исходных характеристик.Однако, в отличие от PCA, LDA не максимизирует объясненную дисперсию. Вместо этого он оптимизирует разделимость между классами. LDA может улучшить прогнозируемые характеристики извлеченных функций. Кроме того, LDA предлагает различные варианты решения конкретных проблем. Анализ основных компонентов ядра — это один из алгоритмов уменьшения размерности и переменных, которые преобразуются в переменные нового набора, которые представляют собой нелинейную комбинацию исходных переменных. означает нелинейную версию PCA, называемую анализом основных компонентов ядра (KPCA).Он может собирать часть статистики высокого порядка, таким образом предоставляя больше информации из исходного набора данных. Обучение с подкреплением — это третий тип машинного обучения, в котором необработанные данные не используются в качестве входных данных, вместо этого алгоритм обучения с подкреплением должен самостоятельно определять ситуацию. Обучение с подкреплением часто используется в робототехнике, играх и навигации. При обучении с подкреплением алгоритм методом проб и ошибок обнаруживает, какие действия приносят наибольшую выгоду.Этот тип обучения состоит из трех основных компонентов: агента, который можно описать как учащегося или принимающего решения, среды, которая описывается как все, с чем взаимодействует агент, и действий, которые представлены как то, что агент может делать. Цель состоит в том, чтобы агент предпринял действия, которые максимизируют ожидаемое вознаграждение в течение заданного периода времени. Агент достигнет цели намного быстрее, если будет придерживаться правильной политики. Итак, цель обучения с подкреплением — усвоить лучший план. В машинном обучении присутствует множество алгоритмов обучения с подкреплением, которые применяются для различных приложений обучения с подкреплением. Вот некоторые из основных алгоритмов: Q-Learning — это один из алгоритмов обучения с подкреплением, в котором агент пытается изучить оптимальную стратегию на основе своей истории общения с окружающей средой. . Запись агента — это последовательность действий-наград.Q-Learning изучает оптимальную политику независимо от того, какой процедуре следует агент, если нет ограничений на количество попыток выполнения действия в любом состоянии. Поскольку он изучает оптимальную политику независимо от того, какую стратегию он выполняет, он называется внеполитическим методом. SARSA — это один из алгоритмов обучения с подкреплением, в котором он определяет, что он обновлен до значений действия. Это небольшая разница между реализациями SARSA и Q-Learning, но она оказывает существенное влияние.Метод SARSA принимает еще один параметр, action2, который представляет собой действие, выполненное агентом из второго состояния. Это позволяет агенту явно определять будущую величину вознаграждения. Далее, это следовало, вместо того, чтобы предполагать, что будет использовано оптимальное действие и что будет наиболее значимая награда. Deep Q-Network — один из алгоритмов обучения с подкреплением, хотя Q-обучение — очень надежный алгоритм, его главный недостаток — отсутствие общности. Если вы рассматриваете Q-обучение как обновление чисел в двумерном массиве (пространство действия * пространство состояний), оно фактически следует динамическому программированию.Это указывает на то, что для состояний, которые агент Q-Learning не видел раньше, он не знает, какое действие предпринять. Другими словами, агент Q-Learning не может оценить значение для невидимых состояний. Чтобы справиться с этой проблемой, DQN избавляется от двумерного массива, вводя нейронную сеть. Марковские процессы принятия решений — это один из алгоритмов обучения с подкреплением, в котором он содержит * набор возможных состояний мира S. * набор моделей. * Набор возможных действий А.* Действительная функция вознаграждения R (s, a). * Политика решение Марковского процесса принятия решений. Для достижения цели используется Марковский процесс принятия решений, который представляет собой простую формулировку проблемы обучения на основе взаимодействия. Агент выбирал действия и среду, реагирующую на эти действия, а агент и среда постоянно взаимодействуют и представляют агенту новые ситуации. Глубинный детерминированный градиент политики — это один из алгоритмов обучения с подкреплением, в котором он основан на схеме «субъект-критик» с двумя одноименными компонентами: субъект и критик.Актер используется для настройки параметра 𝜽 для функции политики, т.е. принятия решения о наилучшем действии для определенного состояния. Идеи отдельной целевой сети и воспроизведения опыта также заимствованы из DQN. Другой проблемой для DDPG является то, что геологоразведочные работы проводятся редко. Решением для этого является добавление шума в пространство параметров или пространство действий. Полу-контролируемое обучение — это четвертый тип машинного обучения, в котором используются оба типа необработанных данных. Полу-контролируемое обучение — это гибрид машинного обучения с учителем и без учителя.Полу-контролируемое обучение используется для тех же целей, что и контролируемое обучение, где используются как помеченные, так и немаркированные данные для обучения, как правило, небольшой объем помеченных данных со значительным объемом немаркированных данных. Этот тип обучения можно использовать с такими методами, как классификация, регрессия и прогнозирование. Этот метод полезен по нескольким причинам. Во-первых, процесс маркировки больших объемов данных для контролируемого обучения часто является чрезмерно трудоемким и дорогостоящим.Более того, слишком частое навешивание ярлыков может навязать модели человеческие предубеждения. Это означает, что включение большого количества немаркированных данных в процессе обучения имеет тенденцию повышать точность окончательной модели, сокращая время и затраты на ее построение. Машинное обучение широко используется в различных областях, некоторые из них — медицина, оборона, технологии, финансы, безопасность и т. Д. Эти области относятся к различным приложениям контролируемого, неконтролируемого обучения и обучения с подкреплением. Некоторые из областей, в которых используются эти алгоритмы машинного обучения, следующие: Этот блог предназначен для новичков, которые хотят начать свою карьеру в области машинного обучения, изучая все или основы, такие как — что такое машинное обучение, его типы, некоторые важные алгоритмы и принципы их работы. Testing SAP Обязательно учите! Big Data Теперь мы переходим к тому, что часто считается основной частью машинного обучения, — к обучению . На этом этапе мы будем использовать наши данные для постепенного улучшения способности нашей модели предсказывать, является ли данный напиток вином или пивом. В некотором смысле это похоже на то, как кто-то впервые учится водить машину. Сначала они не знают, как работают педали, ручки и переключатели и когда их следует использовать.Однако после долгой практики и исправления своих ошибок появляется лицензированный водитель. Более того, за год вождения они стали довольно искусными. Вождение и реакция на данные из реального мира адаптировали их навыки вождения, оттачивая навыки. Мы сделаем это в гораздо меньших масштабах с нашими напитками. В частности, формула для прямой линии имеет вид y = m * x + b, где x — входные данные, m — наклон этой линии, b — точка пересечения с y, а y — значение линии в позиции Икс.Доступные нам значения для корректировки или «обучения» — это m и b. Другого способа повлиять на положение строки нет, поскольку единственными другими переменными являются x, наш ввод, и y, наш вывод. В машинном обучении много m, поскольку может быть много функций. Набор этих m значений обычно формируется в матрицу, которую мы обозначим W для матрицы «весов». Аналогично для b мы объединяем их вместе и называем это смещениями. Процесс обучения включает в себя инициализацию некоторых случайных значений для W и b и попытку предсказать результат с этими значениями.Как вы могли догадаться, это довольно плохо. Но мы можем сравнить прогнозы нашей модели с результатами, которые она должна получить, и скорректировать значения в W и b так, чтобы у нас были более правильные прогнозы. Затем этот процесс повторяется. Каждая итерация или цикл обновления весов и смещений называется одним обучающим «шагом». Давайте посмотрим, что это означает в данном случае, более конкретно, для нашего набора данных. Когда мы впервые начинаем обучение, мы как будто проводим случайную линию через данные.Затем по мере продвижения каждого шага обучения линия шаг за шагом приближается к идеальному разделению вина и пива. Вычислительная мощность, необходимая для обучения машинному обучению и модели глубокого обучения на больших наборах данных, всегда была огромным препятствием для энтузиастов машинного обучения. Но с jupyter notebook, который работает в облаке, любой, кто хочет учиться, может тренироваться и добиваться отличных результатов. В этом посте я предоставлю информацию о различных сервисах, которые дают нам вычислительную мощность для обучения моделей. Colaboratory — это исследовательский проект Google, созданный для распространения образования и исследований в области машинного обучения. Colaboratory (colab) предоставляет бесплатную среду для ноутбуков Jupyter, которая не требует настройки и работает полностью в облаке. Она поставляется с предустановленной большинством библиотек машинного обучения, она действует как идеальное место, где вы можете подключать и играть и опробовать то, что зависит от и вычисление не проблема. Ноутбуки подключены к вашему диску Google, поэтому вы можете получить к нему доступ в любое время, а также загрузить или загрузить блокнот с github. Во-первых, вам нужно включить GPU или TPU для ноутбука. Перейдите в меню «Правка» → «Настройки ноутбука» и выберите TPU в раскрывающемся списке «Аппаратный ускоритель». код для проверки, включен ли TPU print ('TPU devices:') Colab поставляется с большинством установленных библиотек ml, но вы также можете легко добавлять библиотеки, которые не установлены заранее. Colab поддерживает менеджеры пакетов apt command обе команды работают в colab, не забывайте ! (восклицательный) перед командой. Существует множество способов загрузки наборов данных в ноутбук Код для загрузки с локального вы можете просмотреть и выбрать файл. Загрузка файлов с диска Google Библиотека PyDrive используется для загрузки файлов и файлов с диска Google Вы можете получить идентификатор файл, который вы хотите загрузить, и используйте указанный выше код. Дополнительные ресурсы для загрузки файлов из сервисов Google. Загрузка набора данных из kaggle Нам нужно установить kaggle api и добавить файл аутентификации json, который вы можете загрузить с веб-сайта kaggle (API_TOKEN). загрузить файл json в ноутбук, загрузив файл с локального компьютера. создать каталог /.kaggle скопировать файл json в каталог kaggle изменить разрешение файла Теперь вы можете использовать команду для загрузки любого набора данных из kaggle Теперь вы можете использовать приведенную ниже ссылку для загрузки набора данных о соревнованиях из kaggle, но для этого вы должны участвовать в конкурсе. Здесь вы можете тренироваться и запускать fashion_mnist онлайн без каких-либо зависимостей. Colab — отличный инструмент для всех, кто интересуется машинным обучением. Все образовательные ресурсы и фрагменты кода для использования colab представлены на официальном сайте с примерами записных книжек. Kaggle Kernels — это облачная вычислительная среда, которая обеспечивает воспроизводимый и совместный анализ. В ядре kaggle можно запускать как код Python, так и R. Ядро Kaggle запускается в удаленной вычислительной среде.Они предоставляют необходимое оборудование. На момент написания каждому сеансу редактирования ядра предоставляются следующие ресурсы: Характеристики ЦП 4 ядра ЦП 17 ГБ ОЗУ Время выполнения 6 часов 5 ГБ автоматически сохраняемого диска пространство (/ kaggle / working) 16 гигабайт временного дискового пространства блокнота (вне / kaggle / рабочее) Характеристики графического процессора 2 ядра процессора 14 гигабайт ОЗУ После создания учетной записи на kaggle .com, мы можем выбрать набор данных для экспериментов и запустить новое ядро всего за несколько щелчков мышью. Нажмите «Создать новое ядро» 2.2.2. Линейный дискриминантный анализ: —
2.2.3. Анализ основных компонентов ядра: —
Типы алгоритмов обучения с подкреплением: —
3.1.Q-Learning: —
3.2.SARSA [State Action Reward State Action]: —
3.3.Deep Q-Network: —
3.4.Марковские процессы принятия решений: —
3.5.DDPG [Глубокий детерминированный градиент политики]: —
. Machine Learning Tutorial для начинающих
Apache
. 9000 Встроенные системы
7 шагов машинного обучения. От выявления рака кожи до сортировки… | by Yufeng G
Training
Обучение моделей машинного обучения онлайн бесплатно (GPU, TPU) !!! | by Maithreyan Surya
GPU и TPU для включения
import os
import pprint
import tensorflow as tfif ‘COLAB_TPU_ADDR’ not in os.Environment:
print ('ОШИБКА: не подключен к среде выполнения TPU; инструкции см. в первой ячейке в этой записной книжке!')
else:
tpu_address = 'grpc: //' + os.environ ['COLAB_TPU_ADDR']
print ('TPU address is', tpu_address) с tf.Session (tpu_address) as session:
devices = session.list_devices ()
pprint.pprint (devices) Установка библиотек
pip и apt .! Pip install torch
! Apt-get install graphviz -y
Загрузка наборов данных
из Google.colab import files
uploaded = files.upload () ! Pip install -U -q PyDrivefrom pydrive.auth импортировать GoogleAuth
из pydrive.drive импортировать GoogleDrive
из google.colab import auth
из oauth3client.client import GoogleCredentials # 1. Выполните аутентификацию и создайте клиент PyDrive.
авт.Authenticate_user ()
gauth = GoogleAuth ()
gauth.credentials = GoogleCredentials.get_application_default ()
drive = GoogleDrive (gauth) # Ссылка PyDrive:
# https://gsuitedevs.github.io/PyDrive/docs/build/html/ index.html # 2. Создайте и загрузите текстовый файл.
uploaded = drive.CreateFile ({'title': 'Sample upload.txt'})
uploaded.SetContentString ('Образец содержимого загружаемого файла')
uploaded.Upload ()
print ('Загруженный файл с идентификатором {}'. формат (uploaded.get ('id'))) # 3.Загрузите файл по ID и распечатайте его содержимое.
загружено = drive.CreateFile ({'id': uploaded.get ('id')})
print ('Загруженное содержимое "{}"'. Format (loaded.GetContentString ())) ! Pip install kaggle
! Mkdir -p ~ / .kaggle
! Cp kaggle.json ~ / .kaggle /
! Chmod 600 ~ / .kaggle / kaggle.json kaggle datasets download -d lazyjustin / pubgplayerstats
! Соревнования kaggle загрузить -c tgs-salt-identify-challenge