Введение в машинное обучение | Coursera
Не так давно получил распространение термин «большие данные», обозначивший новую прикладную область — поиск способов автоматического быстрого анализа огромных объёмов разнородной информации. Наука о больших данных ещё только оформляется, но уже сейчас она очень востребована — и в будущем будет востребована только больше.

Введение в машинное обучение / Хабр
Полный курс на русском языке можно найти по этой ссылке.
Выход новых лекций запланирован каждые 2-3 дня.
Интервью с Себастьяном Труном, CEO Udacity
— И снова всем привет, с вами я, Пейдж и сегодня со мной гость — Себастьян.
— Привет, я Себастьян!
— … человек у которого невероятная карьера, успевшего сделать множество потрясающих вещей! Вы являетесь со-основателем Udacity, вы основали Google X, вы професcор в Стэнфорде. Вы занимались невероятными исследованиями и глубоким обучением на всём протяжении своей карьеры. Что приносило вам наибольшее удовлетворение и в какой из областей вы получали наибольшее вознаграждение за проделанную работу?
— Скажу честно, я очень люблю находиться в Кремниевой долине! Мне нравится находится рядом с людьми, которые значительно умнее меня, и я всегда рассматривал технологии, как инструмент менющий правила игры различными способами — начиная от образования и заканчивая логистикой, здравохранением и т.

— Ну что ж, это очень оптимистичный взгляд на технологии! Какой момент на протяжении всей вашей карьеры был самой большой «эврикой»?
— Или, например, если вам звонит Ларри Пейдж и говорит, — «Хэй, сделай крутую вещь вроде Google X» и получается нечто достаточно крутое!
— Потрясающе! Итак, этот курс полностью о работе с TensorFlow. У вас есть опыт использования TensorFlow или может быть вы знакомы (слышали) с ним?
— Да! Я, в буквальном смысле, люблю TensorFlow, конечно! В моей собственной лаборатории мы используем его часто и много, одна из самых значимых работ на основе TensorFlow вышла около двух лет назад. Мы узнали, что iPhone и Android могут быть эффективнее в определении рака кожи, чем лучшие дерматологи в мире. Своё исследование мы опубликовали в Nature и это произвело своего рода переполох в медицине.
 0?
0?— Нет, к сожалению пока не успел.
— Он будет просто восхитителен! Все студенты этого курса будут работать с этой версией.
— Я завидую им! Обязательно попробую!
— Прекрасно! На нашем курсе очень много студентов, которые в своей жизни ни разу не занимались машинным обучение, от слова «совсем». Для них область может быть нова, возможно для кого-то само программирование будет вновинку. Какой у вас совет для них?
— Это невероятно интересно! Мне не терпится рассказать студентам этого курса немного больше о машинном обучении! Себастьян, благодарю, что нашел время и пришёл сегодня к нам!
Что такое машинное обучение?
Итак, давайте начнём со следующей задачи — даны входные и выходные значения.
Когда в качестве входного значения у вас значение 0, то в качестве выходного значения — 32. Когда в качестве входного значения у вас 8, то в качестве выходного значения — 46.4. Когда в качестве входного значения у вас 15, то в качестве выходного значения — 59 и так далее.
Присмотритесь к этим значениям и позвольте мне задать вам вопрос. Можете ли вы определить, каким будет выходное значение, если на входе мы получим 38?
Если вы ответили 100.4, то оказались правы!
Итак, как мы могли решить эту задачу? Если присмотреться внимательнее к значениям, то можно заметить, что они связаны выражением:
Где С — градусы Цельсия (входные значения), F — Фаренгейта (выходные значения).
То, что сейчас сделал ваш мозг — сопоставил входные значения и выходные значения и нашел общую модель (связь, зависимость) между ними, — именно это и делает машинное обучение.
По входным и выходным значениям алгоритмы машинного обучения найдут подходящий алгоритм преобразования входных значений в выходные. Это можно представить следующим образом:
Давайте разберём на примере. Представим себе, что мы хотим разработать программу, которая будет преобразовывать градусы Цельсия в градусы Фаренгейта используя формулу
Решение, при подходе с точки зрения традиционной разработки программного обеспечения, может быть реализовано на любом языке программирования с использованием функции:
Итак, что мы имеем? Функция принимает входное значение C, затем вычисляет выходное значение F используя явно заданный алгоритм, а затем возвращает вычисленное значение.
С другой стороны, в подходе с машинным обучением, у нас есть только входные и выходные значения, но не сам алгоритм:
Подход с машинным обучением основывается на использовании нейронных сетей для нахождения отношений между входными и выходными значениями.
Вы можете думать о нейронных сетях, как о стопке слоёв, каждый из которых состоит из заранее известной математики (формул) и внутренних переменных. Входное значение поступает в нейронную сеть и проходит сквозь стопку слоёв нейронов. Во время прохождения через слои, входное значение преобразовывается согласно математике (заданным формулам) и значениям внутренних переменных слоёв, производя выходное значение.
Для того, чтобы нейронная сеть смогла обучиться и определить правильные отношения между входными и выходными значениями, нам необходимо её обучить — натренировать.
Мы тренируем нейронную сеть через повторяющиеся попытки сопоставить входные значения выходным.
В процессе тренировки происходит «подгонка» (подбор) значений внутренних переменных в слоях нейронной сети до тех пор, пока сеть не научится генерировать соответствующие выходные значения соответствующим входным значениям.
Как мы увидим в последующем, для того чтобы обучить нейронную сеть и позволить ей подобрать наиболее подходящие значения внутренних переменных, производят тысячи или десятки тысяч итераций (тренировок).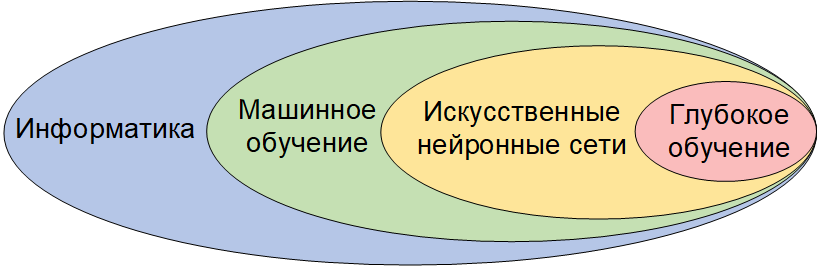
В качестве упрощенного варианта понимания машинного обучения вы можете представить себе алгоритмы машинного обучения как функции, которые подбирают значения внутренних переменных таким образом, чтобы соответствующим входным значениям соответствовали корректные выходные значения.
Существует множество типов архитектур нейронных сетей. Однако, вне зависимости от того, какую архитектуру вы выберете, математика внутри (какие вычисления выполняются и в каком порядке) останется неизменной в процессе тренировки. Вместо изменения математики, меняются внутренние переменные (веса и смещения) во время тренировки.
Например, в задаче конвертации из градусов Цельсия в Фаренгейты, модель начинает с умножения входного значения на некоторое число (вес) и добавления другого значения (смещения). Обучение модели заключается в нахождении подходящих значений для этих переменных, без изменения выполняемых операций умножения и сложения.
А вот одна крутая вещь над которой стоит задуматься! Если вы решили задачу преобразования градусов Цельсия в Фаренгейты, которая обозначена в видео и в тексте ниже, вы, вероятно, решили её потому, что обладали неким предыдущим опытом или знанием, как производить подобного рода преобразования из градусов Цельсия в Фаренгейты. Например, вы могли просто знать, что 0 градусов Цельсия соответствуют 32 градусам по Фаренгейту. С другой стороны, системы основанные на машинном обучении не обладают предыдущими вспомогательными знаниями для решения поставленной задачи. Они учатся решать подобного рода задачи не основываясь на предыдущих знаниях и при их полном отсутствии.
Довольно разговоров — переходим к практической части лекции!
CoLab: преобразуем градусы Цельсия в градусы Фаренгейта
Русская версия CoLab исходного кода и английская версия CoLab исходного кода.
Основы: обучение первой модели
Добро пожаловать в CoLab, где мы будем тренировать нашу первую модель машинного обучения!
Мы постараемся сохранять простоту преподносимого материала и ввести только базовые понятия необходимые для работы. Последующие CoLabs будут содержать более продвинутые техники.
Последующие CoLabs будут содержать более продвинутые техники.
Задача, которую мы будем решать — преобразование градусов Цельсия в градусы Фаренгейта. Формула преобразования выглядит следующим образом:
Безусловно, было бы проще просто написать функцию конвертации на Python или любом другом языке программирования, которая бы выполняла непосредственные вычисления, но в таком случае это не было бы машинным обучением 🙂
Вместо этого мы подадим на вход TensorFlow имеющиеся у нас входные значения градусов Цельсия (0, 8, 15, 22, 38) и их соответствующие градусы по Фаренгейту (32, 46, 59, 72, 100). Затем мы натренируем модель таким образом, чтобы та примерно соответствовала приведённой выше формуле.
Импорт зависимостей
Первым делом импортируем
TensorFlow. Здесь и в последующем мы сокращённо называем его tf. Мы так же настраиваем уровень логгирования — только ошибки.Далее, импортируем NumPy как np. Numpy помогает нам представить наши данные в виде высокоэффективных списков.
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
tf.logging.set_verbosity(tf.logging.ERROR)
import numpy as np
Подготовка данных для тренировки
Как мы уже видели ранее, методика машинного обучения с учителем основывается на поиске алгоритма преобразования входных данных в выходные. Так как задачей этого CoLab является создание модели, которая может выдать результат преобразования градусов Цельсия в градусы Фаренгейта, создадим два списка —
celsius_q и fahrenheit_a, которые мы используем при обучении нашей модели.celsius_q = np.array([-40, -10, 0, 8, 15, 22, 38], dtype=float)
fahrenheit_a = np.array([-40, 14, 32, 46, 59, 72, 100], dtype=float)
for i,c in enumerate(celsius_q):
print("{} градусов Цельсия = {} градусов Фаренгейта".format(c, fahrenheit_a[i]))
-40. 0 градусов Цельсия = -40.0 градусов Фаренгейта
0 градусов Цельсия = -40.0 градусов Фаренгейта
-10.0 градусов Цельсия = 14.0 градусов Фаренгейта
0.0 градусов Цельсия = 32.0 градусов Фаренгейта
8.0 градусов Цельсия = 46.0 градусов Фаренгейта
15.0 градусов Цельсия = 59.0 градусов Фаренгейта
22.0 градусов Цельсия = 72.0 градусов Фаренгейта
38.0 градусов Цельсия = 100.0 градусов Фаренгейта
 0 градусов Цельсия = -40.0 градусов Фаренгейта
0 градусов Цельсия = -40.0 градусов ФаренгейтаНекоторая терминология машинного обучения:
- Свойство — входное(ые) значение нашей модели. В данном случае единичное значение — градусы Цельсия.
- Метки — выходные значения, которые наша модель предсказывает. В данном случае единичное значение — градусы Фаренгейта.
- Пример — пара входных-выходных значений используемых для тренировки. В данном случае это пара значений из
celsius_qиfahrenheit_aпод определённым индексом, например, (22,72).
Создаём модель
Далее мы создаём модель. Мы будем использовать максимально упрощенную модель — модель полносвязной сети (
Dense-сеть). Так как задача достаточно тривиальна, то и сеть будет состоять из единственного слоя с единственным нейроном.Строим сеть
Мы назовём слой
l0 (layer и ноль) и создадим его, инициализировав tf.keras.layers.Dense со следующими параметрами:input_shape=[1]— этот параметр определяет размерность входного параметра — единичное значение. Матрица размером 1×1 с единственным значением. Так как это первый (и единственный) слой, то и размерность входных данных соответствует размерности всей модели. Единственное значение — значение с плавающей запятой, представляющее градусы Цельсия.-
units=1— этот параметр определяет количество нейронов в слое. Количество нейронов определяет то, как много внутренних переменных слоя будет использовано для обучения при поиске решения поставленной задачи. Так как это последний слой, то его размерность равна размерности результата — выходного значения модели — единственного числа с плавающей запятой представляющего собой градусы Фаренгейта. (В многослойной сети размеры и форма слоя input_shapeдолжны соответствовать размерам и формам следующего слоя).
 Так как это последний слой, то его размерность равна размерности результата — выходного значения модели — единственного числа с плавающей запятой представляющего собой градусы Фаренгейта. (В многослойной сети размеры и форма слоя
Так как это последний слой, то его размерность равна размерности результата — выходного значения модели — единственного числа с плавающей запятой представляющего собой градусы Фаренгейта. (В многослойной сети размеры и форма слоя l0 = tf.keras.layers.Dense(units=1, input_shape=[1])
Преобразуем слои в модель
Как только слои определены их необходимо преобразовать в модель.
Sequential-модель принимает в качестве аргументов перечень слоёв в том порядке в котором их необходимо применять — от входного значения до выходного значения.У нашей модели всего один слой — l0.
model = tf.keras.Sequential([l0])
Примечание
Достаточно часто вы будете сталкиваться с определением слоёв прямо в функции модели, нежели с их предварительным описанием и последующим использованием:
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1])
])
Компилируем модель с функцией потерь и оптимизаций
Перед тренировкой модель должна быть скомпилирована (собрана). При компиляции для тренировки необходимы:
- функция потерь — способ измерения того, насколько далеко предсказываемое значение от желаемого выходного значения (измеримая разница называется «потерей»).
- функция оптимизации — способ корректировки внутренних переменных для уменьшения потерь.
model.compile(loss='mean_squared_error',
optimizer=tf.keras.optimizers.Adam(0.1))
Функция потерь и функция оптимизации используются во время тренировки модели (
model.fit(...) упоминаемая ниже) для выполнения первичных вычислений в каждой точке и последующей оптимизации значений.Действие вычисления текущих потерь и последующее улучшение этих значений в модели — это именно то, чем является тренировка (одна итерация).
Во время тренировки, функция оптимизации используется для подсчета корректировок значений внутренних переменных. Цель — подогнать значения внутренних переменных таким образом в модели (а это, по сути, математическая функция), чтобы те отражали максимально приближённо существующее выражение конвертации градусов Цельсия в градусы Фаренгейта.
TensorFlow использует численный анализ для выполнения подобного рода операций оптимизации и вся эта сложность скрыта от наших глаз, поэтому мы не будем вдаваться в детали в этом курсе.
Что полезно знать об этих параметрах:
Функция потерь (среднеквадратичная ошибка) и функция оптимизации (Adam), используемые в этом примере, являются стандартными для подобных простых моделей, но кроме них доступно множество других. На данном этапе нам не важно каким образом работают эти функции.
На что стоит обратить внимание, так это на функцию оптимизации и параметр — коэффициент скорости обучения (learning rate), который в нашем примере равен 0.1. Это используемый размер шага при корректировке внутренних значений переменных. Если значение слишком маленькое — понадобится слишком много обучающих итераций для обучения модели. Слишком большое — точность падает. Нахождение хорошего значения коэффициента скорости обучения требует некоторых проб и ошибок, оно обычно находится в интервале от 0.01 (по-умолчанию) до 0.1.
Тренируем модель
Тренировка модели осуществляется методом
fit.Во время тренировки модель получает на вход значения градусов Цельсия, выполняет преобразования используя значения внутренних переменных (называемые «весами») и возвращает значения, которые должны соответствовать градусами по Фаренгейту. Так как первоначальные значения весов установлены произвольными, то и результатирующие значения будут далеки от корректных значений. Разница между необходимым результатом и фактическим вычисляется с использованием функции потерь, а функция оптимизации определяет каким образом должны быть подкорректированы веса.
Этот цикл вычислений, сравнений и корректировки контролируется внутри метода fit. Первый аргумент — входные значения, второй аргумент — желаемые выходные значения. Аргумент epochs определяет какое количество раз этот обучающий цикл должен быть выполнен. Аргумент verbose контролирует уровень логгирования.
history = model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False)
print("Завершили тренировку модели")
В последующих видео мы погрузимся в детали того, каким образом это всё работает и как именно работают полносвязные слои (
Dense-слои) «под капотом».Отображаем статистику тренировок
Метод
fit возвращает объект, который содержит информацию об изменении потерь с каждой последующей итерацией. Мы можем воспользоваться этим объектом для построения соответствующего графика потерь. Высокая потеря означает, что значение градусов Фаренгейта, которые предсказала модель, далеки от истинных значений в массиве fahrenheit_a.Для визуализации воспользуемся Matplotlib. Как вы можете увидеть, наша модель улучшается очень быстро в самом начале, а затем приходит к стабильному и медленному улучшению до тех пор, пока результаты не становятся «около»-идеальными в самом конце обучения.
import matplotlib.pyplot as plt
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.plot(history.history['loss'])
Используем модель для предсказаний
Теперь у нас есть модель, которая была обучена на входных значениях
celsius_q и выходных значениях fahrenheit_a для определения взаимосвязи между ними. Мы можем воспользоваться методом предсказания для вычисления тех значений градусов Фаренгейта по которым ранее нам неизвестны были соответствующие градусы Цельсия.Например, сколько будет 100.0 градусов Цельсия по Фаренгейту? Попробуйте угадать перед тем как запускать код ниже.
print(model. predict([100.0]))
 predict([100.0]))
predict([100.0]))
Вывод:
[[211.29639]]
Правильный ответ 100×1.8+32=212, так что наша модель справилась достаточно хорошо!
Ревью
- Мы создали модель с использованием
Dense-слоя - Мы обучили её на 3500 примерах (7 пар значений, 500 обучающих итераций)
Наша модель подогнала значения внутренних переменных (весов) в
Dense-слое таким образом, чтобы возвращать правильные значения градусов Фаренгейта на произвольное входное значение градусов Цельсия.Смотрим на веса
Давайте отобразим значения внутренних переменных
Dense-слоя.print("Это значения переменных слоя: {}".format(l0.get_weights()))
Вывод:
Это значения переменных слоя: [array([[1.8261501]], dtype=float32), array([28.681389], dtype=float32)]
Значение первой переменной близко к ~1.8, а второй к ~32. Эти значения (1.8 и 32) являются непосредственными значениями в формуле конвертации градусов Цельсия в градусы Фаренгейта.
Это действительно очень близко к фактическим значениям в формуле! Мы рассмотрим этот момент подробнее в последующих видео, где мы покажем, каким образом работает Dense-слой, а пока стоит знать лишь то, что один нейрон с единственным входом и выходом, содержит в себе простую математику — y = mx + b (как уравнение прямой), которая представляет собой не что иное, как нашу с вами формулу преобразования градусов Цельсия в градусы Фаренгейта, f = 1.8c + 32.
Так как представления одинаковые, то и значения внутренних переменных модели должны были сойтись к тем, которые представлены в фактической формуле, что и произошло в итоге.
При наличии дополнительных нейронов, дополнительных входных значений и выходных значений, формула становится немного сложнее, но суть остаётся той же.
Немного экспериментов
Ради веселья! Что будет, если мы создадим больше
Dense-слоёв с большим количеством нейронов, которые, в свою очередь, будут содержать больше внутренних переменных?l0 = tf. keras.layers.Dense(units=4, input_shape=[1])
l1 = tf.keras.layers.Dense(units=4)
l2 = tf.keras.layers.Dense(units=1)
model = tf.keras.Sequential([l0, l1, l2])
model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1))
model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False)
print("Закончили обучение модели")
print(model.predict([100.0]))
print("Модель предсказала, что 100 градусов Цельсия соответствуют {} градусам Фаренгейта".format(model.predict([100.0])))
print("Значения внутренних переменных слоя l0: {}".format(l0.get_weights()))
print("Значения внутренних переменных слоя l1: {}".format(l1.get_weights()))
print("Значения внутренних переменных слоя l2: {}".format(l2.get_weights()))
 keras.layers.Dense(units=4, input_shape=[1])
l1 = tf.keras.layers.Dense(units=4)
l2 = tf.keras.layers.Dense(units=1)
model = tf.keras.Sequential([l0, l1, l2])
model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1))
model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False)
print("Закончили обучение модели")
print(model.predict([100.0]))
print("Модель предсказала, что 100 градусов Цельсия соответствуют {} градусам Фаренгейта".format(model.predict([100.0])))
print("Значения внутренних переменных слоя l0: {}".format(l0.get_weights()))
print("Значения внутренних переменных слоя l1: {}".format(l1.get_weights()))
print("Значения внутренних переменных слоя l2: {}".format(l2.get_weights()))
keras.layers.Dense(units=4, input_shape=[1])
l1 = tf.keras.layers.Dense(units=4)
l2 = tf.keras.layers.Dense(units=1)
model = tf.keras.Sequential([l0, l1, l2])
model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1))
model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False)
print("Закончили обучение модели")
print(model.predict([100.0]))
print("Модель предсказала, что 100 градусов Цельсия соответствуют {} градусам Фаренгейта".format(model.predict([100.0])))
print("Значения внутренних переменных слоя l0: {}".format(l0.get_weights()))
print("Значения внутренних переменных слоя l1: {}".format(l1.get_weights()))
print("Значения внутренних переменных слоя l2: {}".format(l2.get_weights()))
Вывод:
Закончили обучение модели
[[211.74748]]
Модель предсказала, что 100 градусов Цельсия соответствуют [[211.74748]] градусам Фаренгейта
Значения внутренних переменных слоя l0: [array([[-0.5972079 , -0.05531882, -0.00833384, -0.10636603]],
dtype=float32), array([-3.0981746, -1.8776944, 2.4708805, -2.9092448], dtype=float32)]
Значения внутренних переменных слоя l1: [array([[ 0.09127654, 1.1659832 , -0.61909443, 0.3422218 ],
[-0.7377194 , 0.20082018, -0.47870865, 0.30302727],
[-0.1370897 , -0.0667181 , -0.39285263, -1.1399261 ],
[-0.1576551 , 1.1161333 , -0.15552482, 0.39256814]],
dtype=float32), array([-0.94946504, -2.9903848 , 2.9848468 , -2.9061244 ], dtype=float32)]
Значения внутренних переменных слоя l2: [array([[-0.13567649],
[-1.4634581 ],
[ 0.68370366],
[-1.2069695 ]], dtype=float32), array([2.9170544], dtype=float32)]
Как вы могли уже заметить, текущая модель тоже способна достаточно хорошо предсказывать соответствующие значения градусов Фаренгейта. Однако, если взглянуть на значения внутренних переменных (веса) нейронов по слоям, то никаких значений похожих на 1.8 и 32 мы уже не увидим. Добавленная сложность модели скрывает «простую» форму преобразования градусов Цельсия в градусы Фаренгейта.

Оставайся на связи и в следующей части мы рассмотрим то, каким образом работают Dense-слои «под капотом».
Краткое резюме
Поздравляем! Вы только что обучили свою первую модель. Мы на практике увидели, каким образом по входным и выходным значениям модель научилась умножать входное значение на 1.8 и прибавлять к нему 32 для получения корректного результата.
Это было по-настоящему впечатляюще, учитывая то, сколько строчек кода нам понадобилось написать:
l0 = tf.keras.layers.Dense(units=1, input_shape=[1])
model = tf.keras.Sequential([l0])
model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1))
history = model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False)
model.predict([100.0])
Приведённый выше пример — общий план для всех программ машинного обучения. Вы будете использовать подобные конструкции для создания и обучения нейронных сетей и для решения последующих задач.
Процесс тренировки
Процесс тренировки (происходящий в методе
model.fit(...)) состоит из весьма простой последовательности действий, результатом которых должны стать значения внутренних переменных дающих максимально близкий к исходному результаты. Процесс оптимизации, благодаря которому достигаются такие результаты, называется градиентным спуском, использует численный анализ для поиска максимально подходящих значений для внутренних переменных модели.Чтобы заниматься машинным обучением вам, в принципе, нет необходимости разбираться в этих деталях. Но для тех, кому всё-таки интересно узнать больше: градиентный спуск посредством итераций изменяет значения параметров по-немногу, «вытягивая» их в нужном направлении, до тех пор пока не будут получены наилучшие результаты. В данном случае «лучшие результаты» (лучшие значения) означают, что любое последующее изменение параметра только ухудшит результат модели. Функция, которая измеряет насколько хороша или плоха модель на каждой итерации называется «функцией потерь», и цель каждого «вытягивания» (корректировки внутренних значений) — уменьшить значение функции потерь.
Процесс тренировки начинается с блока «прямое распространение», при котором входные параметры поступают на вход нейронной сети, следуют к скрытым нейронам и затем идут к выходным. Затем модель применяет внутренние преобразования над входными значениями и внутренними переменными для предсказания ответа.
В нашем примере, входным значением является температура в градусах Цельсия и модель предсказывала соответствующее значение в градусах Фаренгейта.
Как только значение предсказано, происходит вычисление разности между предсказанным значением и корректным. Разница называется «потерей» и является формой измерения того, насколько хорошо модель сработала. Значение потери вычисляется функцией потерь, которую мы определили одним из аргументов при вызове метода model.compile(...).
После вычисления значения потери, внутренние переменные (веса и смещения) всех слоёв нейронной сети подвергаются корректировке для минимизации значения потери с целью приближения выходного значения к корректному исходному эталонному значению.
Этот процесс оптимизации носит название градиентного спуска. Конкретный алгоритм оптимизации используется для вычисления нового значения для каждой внутренней переменной при вызове метода model.compile(...). В приведённом выше примере мы использовали алгоритм оптимизации Adam.
Для этого курса не является обязательным понимание принципов работы процесса тренировки, однако, если вы достаточно любопытны, то можете найти больше информации в Google Crash Course (перевод и практическая часть всего курса заложены у автора в планах к публикации).
К этому моменты вы уже должны быть знакомы со следующими терминами:
- Свойство: входное значение нашей модели;
- Примеры: пары входное+выходное значений;
- Метки: выходные значения модели;
- Слои: коллекция узлов объединенных вместе в рамках нейронной сети;
- Модель: представление вашей нейронной сети;
- Плотный и полностью связный: каждый узел в одном слое связан с каждым узлом из предыдущего слоя.
- Веса и смещения: внутренние переменные модели;
- Потери: разница между желаемым выходным значением и фактическим выходным значением модели;
- MSE: среднеквадратичное отклонение, тип функции потерь, которые считают малое количество больших ошибок вариантом хуже, чем большое количество малых.
- Градиентный спуск: алгоритм, который изменяет внутренние переменные по-немногу при каждой итерации с целью уменьшения значения функции потерь;
- Оптимизатор: конкретная реализация алгоритма градиентного спуска;
- Коэффициент скорости обучения: размер «шага» при снижении потерь во время градиентного спуска;
- Серия: набор данных для обучения нейронной сети;
- Эпоха: полный проход по всей серии исходных данных;
- Прямое распространение: вычисление выходных значение по входным значениям;
- Обратное распространение: вычисление значений внутренних переменных согласно алгоритму оптимизации, начинающегося с выходного слоя и по направлению к входному слою через все промежуточные слои.
Dense-слои
В предыдущей части мы создали модель, которая конвертирует градусы Цельсия в градусы Фаренгейта, используя простую нейронную сеть для нахождения зависимости между градусами Цельсия и градусами Фаренгейта.
Наша сеть состоит из единственного полносвязного слоя. Но что такое полносвязный слой? Чтобы в этом разобраться давайте создадим более сложную нейронную сеть у которой 3 входных параметра, один скрытый слой с двумя нейронами и один выходной слой с единственным нейроном.
Напомним, что нейронную сеть можно представить себе как набор слоёв, каждый из которых состоит из узлов, называемых нейронами. Нейроны на каждом уровне могут быть соединены с нейронами каждого последующего слоя. Тип слоёв, в котором каждый нейрон одного слоя соединён с каждым другим нейроном следующего слоя, называется полностью связным (полносвязным) или плотным слоем (Dense-слой).
Таким образом, когда мы используем полносвязные слои в keras, мы как бы сообщаем, что нейроны этого слоя должны быть связаны со всеми нейронами предыдущего слоя.
Чтобы создать приведенную выше нейронную сеть нам достаточно следующих выражений:
hidden = tf.keras.layers.Dense(units=2, input_shape=[3])
output = tf.keras.layers.Dense(units=1)
model = tf.keras.Sequential([hidden, output])
Итак, мы разобрались с тем, что такое нейроны и как они связаны между собой. Но как на самом деле работают полносвязные слои?
Чтобы понять, что же на самом деле там происходит и что они делают, нам понадобится заглянуть «под капот» и разобрать внутреннюю математику нейронов.
Представим, что наша модель принимает на вход три параметра — х1, х2, х3, а а1, а2 и а3 — нейроны нашей сети. Помните мы говорили, что у нейрона есть внутренние переменные? Так вот, w* и b* являются теми самыми внутренними переменными нейрона, так же известными как веса и смещения. Именно значения этих переменных подвергаются корректировке в процессе обучения для получения максимально точных результатов сопоставления входных значений выходным.
Что обязательно стоит иметь ввиду — внутренняя математика нейрона остаётся неизменной. Другими словами, в процессе тренировки меняются только веса и смещения.
Когда начинаешь изучать машинное обучение это может показаться странным — тот факт, что это действительно работает, но именно так работает машинное обучение!
Давайте теперь вернёмся к нашему примеру конвертации градусов Цельсия в градусы Фаренгейта.
С единственным нейроном у нас есть только один вес и одно смещение. Знаете что? Это именно то, как выглядит формула конвертации градусов Цельсия в градусы Фаренгейта. Если мы подставим под w11 значение 1.8, а вместо b1 — 32, то получим конечную модель преобразования!
Если мы вернёмся к результатам работы нашей модели из практической части, то обратим внимание на то, что показатели веса и смещения были «откалиброваны» таким образом, что примерно соответствуют значениям из формулы.
Мы целенаправленно создали именно такой практический пример, чтобы наглядно показать точное сопоставление между весами и смещениями. Применяя машинное обучение на практике, мы никогда не сможем подобным образом сопоставить значения переменных с целевым алгоритмом, как в приведённом выше примере. Как мы сможем это сделать? Никак, потому что мы даже не знаем целевого алгоритма!
Решая задачи машинного обучения мы тестируем различные архитектуры нейронных сетей с различным количеством нейронов в них — методом проб и ошибок находим наиболее точные архитектуры и модели и надеемся, что они решат поставленную задачу в процессе обучения. В следующей практической части мы сможем изучить конкретные примеры такого подхода.
Оставайтесь на связи, потому что сейчас начнётся самое интересное!
Итоги
В этом уроке мы научились базовым подходам в машинном обучении и узнали как работают полносвязные слои (
Dense-слои). Вы обучили свою первую модель преобразовывать градусы Цельсия в градусы Фаренгейта. Вы так же изучили основные термины используемые в машинном обучении, такие как свойства, примеры, метки. Вы, ко всему прочему, написали основные строчки кода на Python, которые являются костяком любого алгоритма машинного обучения. Вы увидели, что в несколько строчек кода можно создать, обучить и запросить предсказание у нейронной сети с использованием TensorFlow и Keras.… и стандартные call-to-action — подписывайся, ставь плюс и делай share 🙂
Видео-версия статьиYouTube: https://youtube.com/channel/ashmig
Telegram: https://t.me/ashmig
ВКонтакте: https://vk.com/ashmig
Введение в машинное обучение. Перевод статьи из блога Algorithmia… | by Roman Ponomarev | Maria Machine
Перевод статьи из блога Algorithmia: Introduction to Machine Learning
Машинное обучение — о том, как делать предсказания.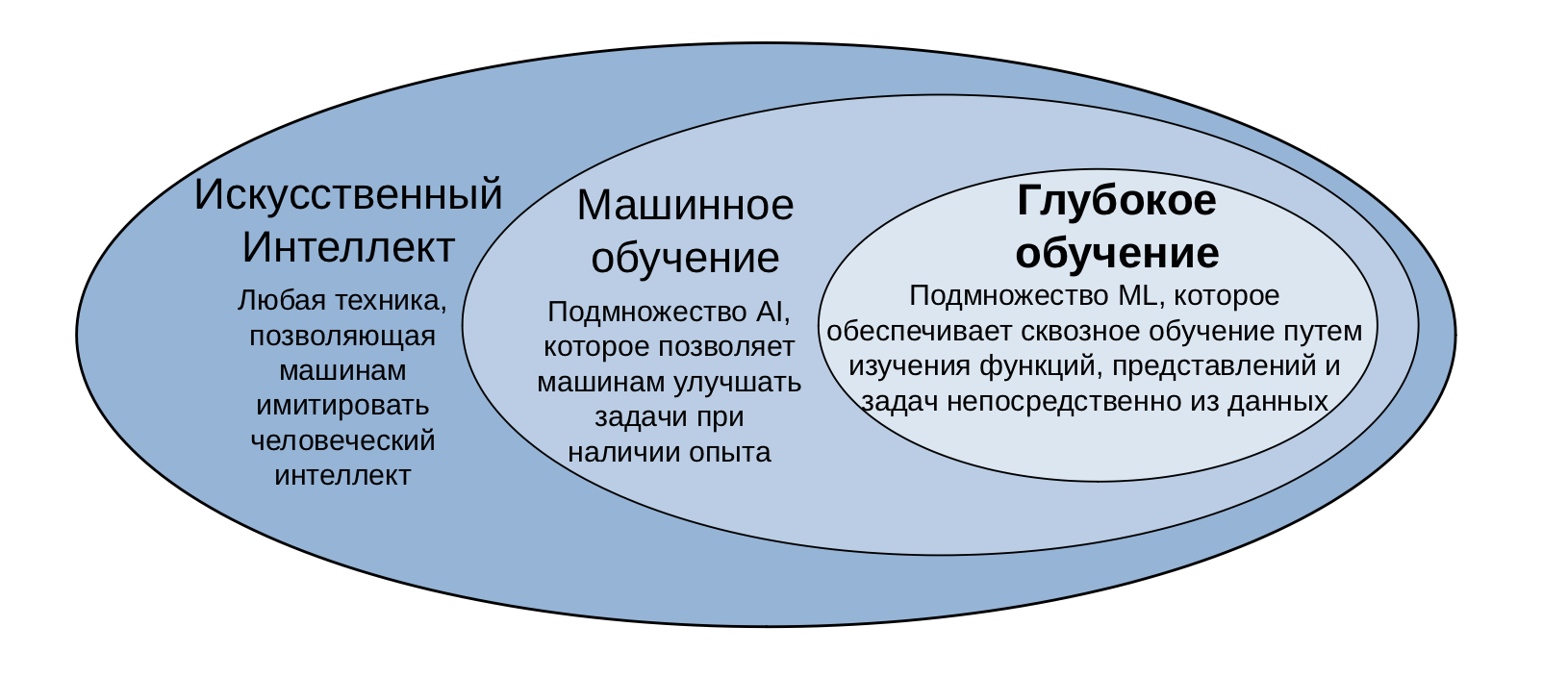 В данной статье будет дано введение в машинное обучение через проблему, с которой сталкивается большинство коммерческих предприятий: прогнозирование оттока клиентов. ML способно предсказать, кто из ваших клиентов рискует уйти, и дать вам возможность предпринять все необходимые действия дабы не допустить этого.
В данной статье будет дано введение в машинное обучение через проблему, с которой сталкивается большинство коммерческих предприятий: прогнозирование оттока клиентов. ML способно предсказать, кто из ваших клиентов рискует уйти, и дать вам возможность предпринять все необходимые действия дабы не допустить этого.
Машинное обучение лучше всего понимать, взглянув на него с различных углов.
- Широкий: машинное обучение — это процесс предсказания, обычно основанный на прошлом.
- Практический: машинное обучение пытается найти взаимосвязи в данных, чтобы помочь предсказать, что будет дальше.
- Технический: машинное обучение использует статистические методы для прогнозирования значения целевой переменной с использованием набора входных данных.
- Математический: машинное обучение пытается предсказать значение переменной Y с учетом ввода набора X.
Машинное обучение позволяет точно прогнозировать, используя простые статистические методы, алгоритмы и современные вычислительные мощности.
Пример оттока: машинное обучение поможет нам понять, почему клиенты уйдут и когда. Наши входные значения могут включать:
- Как часто пользователи взаимодействуют с продуктом
- Что их удерживает
- Насколько пользователи связаны друг с другом
Мы предполагаем, что эти данные скажут что-то важное о клиенте.
Любой тип машинного обучения можно разбить на две основные части:
- Данные
- Алгоритм
Любые другие усложнения, которые вы можете услышать — глубокое обучение, градиентный спуск, обучение с подкреплением — это всего лишь вариации этих двух фундаментальных частей. Если вы когда-нибудь запутаетесь во всех этих терминах, просто спросите себя, имеет ли это вообще отношение к вашим данным или вашему алгоритму. Все остальное — шелуха.
Ваши данные
Часть о данных в машинном обучении является самой простой. Данные — это все то, что вы пытаетесь предсказать, и как вы планируете обучать компьютер этому.
Пример оттока: данными может стать прошлая активность пользователя. Данные обычно организованы в виде строк со столбцами, представляющими их особенности (диаграмма выше).
Методы машинного обучения будут пытаться найти закономерности в этих данных. Мы могли бы найти несколько разных типов отношений:
- Пользователи с большим интервалом между заказами, скорее всего, скоро уйдут
- Пользователи с большим количеством заказов вряд ли будут уходить
В данных может существовать любое количество отношений. Машинам нужны лишь эти данные, они обработают их и выделят отношения.
Ваш алгоритм
В машинном обучении алгоритм — это просто метод, который вы будете использовать для поиска связей в ваших данных. Алгоритмы могут быть сложными или простыми, большими или маленькими, но, по сути, это всего лишь способы выяснить, что движет изменениями, которые вы пытаетесь предсказать. Вы слышали о глубоком обучении? Это (в основном) тип алгоритма. Подобно тому, как алгоритм MergeSort эффективен при сортировке массивов, алгоритмы машинного обучения эффективны при выявлении отношений и ассоциаций.
Разные типы алгоритмов помогут вам достичь разных целей. Если вы хотите объяснить отношения в человеческом общении, возможно, стоит воспользоваться таким простым алгоритмом, как линейная регрессия. Если вас больше всего интересует точность (и объяснимость не слишком важна), нейронные сети могут достичь более высоких показателей точности. Это часто называют компромиссом между точностью и объясняемостью, и это серьезный выбор, который приходится делать многим специалистам по данным.
Все остальное, с чем вы сталкиваетесь в мире ML, связано с одним из этих двух: данные или алгоритм. Нормализация свойств? Изменение ваших данных. Глубокое обучение? Тип алгоритма. Перекрестная проверка? Способ улучшить ваш алгоритм. Поверьте, зуб даю.
Верьте или нет, концепции, лежащие в основе машинного обучения, на самом деле очень просты, даже если алгоритмы могут оказаться сложными. Большинство алгоритмов ML используют один метод, чтобы найти отношения, о которых мы говорили, и они буквально нащупывают их вслепую. Технически это называется градиентным спуском, но сам метод прост — мы начинаем с некоторой случайной точки и пытаемся улучшить наши прогнозы.
Большинство алгоритмов ML используют один метод, чтобы найти отношения, о которых мы говорили, и они буквально нащупывают их вслепую. Технически это называется градиентным спуском, но сам метод прост — мы начинаем с некоторой случайной точки и пытаемся улучшить наши прогнозы.
Мы начнем с функции потерь — способа оценить, насколько хорошо мы справляемся с поиском отношений. Другими словами, это помогает нам определить, насколько плохи наши прогнозы, чтобы мы могли работать над их улучшением. Функция потерь зависит от того, какой алгоритм вы используете. Для линейной регрессии она представляет собой следующее:
Это может показаться сложным на первый взгляд, но давайте сосредоточимся на функции. Она определяет разницу между тем, что предсказывает алгоритм — hO(x(i)) — и действительным значением целевой переменной — y(i). Наша цель в минимизации функции потерь, потому что мы хотим, чтобы прогнозируемые значения были как можно ближе к фактическим целевым значениям переменных.
Как же это сделать? Мы начнем со случайного набора предсказаний и постараемся двигаться в сторону улучшения. Если наши прогнозы окажутся слишком высокими, мы подстроимся. Если слишком низкими — мы тоже подстроимся. Алгоритм в основном движется вслепую и медленно, пока не находит то, что ищет. Самое смешное, что градиентный спуск фактически сам по себе является алгоритмом — мы используем алгоритм для улучшения нашего алгоритма. Довольно круто! Для получения более подробной информации о том, как реализован алгоритм градиентного спуска (в дополнение к другим решениям для оптимизации функции потерь), ознакомьтесь с Введением в оптимизаторы.
Давайте еще раз сложим все вместе: мы используем градиентный спуск, чтобы оптимизировать нашу функцию потерь, и именно так алгоритм находит основную связь в данных. Мы делаем это, начиная с случайных предсказаний и постепенно калибруя наш подход, пока не подойдем как можно ближе к искомым значениям.
Обучение с учителем и без
На практике существует два основных типа машинного обучения, в которых алгоритм и данные связаны по-разному: обучение с учителем и обучение без учителя. Различия между ними деликатные, но важные. Основное различие в том, как вы представляете свои данные для алгоритма.
Различия между ними деликатные, но важные. Основное различие в том, как вы представляете свои данные для алгоритма.
В обучении с учителем вы определяете возможные результаты. В примере с погодой мы можем сказать, что данный день может быть жарким, холодным или умеренным. Затем мы передаем данные в алгоритм, и он выясняет, что (если что-нибудь) приводит к жарким дням, что приводит к холодным дням и что приводит к умеренным дням. Поскольку мы определили варианты — горячие, холодные и умеренные — алгоритм будет выдвигать прогнозы в рамках этой структуры.
Но иногда мы не знаем, какие есть варианты или какими мы хотим их видеть. Обучение без учителя берет данные и пытается выяснить, каковы различные потенциальные группировки. Алгоритм обучения без учителя может обнаружить, что группы с наиболее отчетливыми особенностями — это очень жаркие, умеренные и облачные дни. Вместо того, чтобы заранее определять группы результатов и пытаться сопоставить с ними отношения, мы позволяем алгоритму найти те, которые он считает наиболее органичными.
По сути, разница между этими двумя типами машинного обучения заключается в модели ввода-вывода. В обучении с учителем вы предоставляете алгоритму X и Y и пытаетесь выяснить отношения между ними. В обучении без учителя нет Y — вы просто пытаетесь понять основную организацию данных самих по себе.
На практике элементарное машинное обучение легко получить. Существуют наборы инструментов на любой вкус: от людей, никогда раньше не писавших ни строчки кода, до специалистов по машинному обучению, стремящихся идеально оптимизировать каждый параметр.
Инструменты
Некоторые инструменты позволяют запускать машинное обучение для набора данных без написания кода. Если вы эксперт в конкретной области знаний и не имеете какого-либо опыта программирования, эти инструменты помогут вам привнести ML в ваши задумки:
Популярные фреймворки / Пакеты
Фреймворки объединяют основные функции на определенном языке программирования во что-то более простое в использовании и мощное. Практически, вместо того, чтобы писать математику и статистику выбранного вами алгоритма вручную (однако некоторые люди предпочитают это!), вы можете просто реализовать его на своем любимом языке программирования.
Практически, вместо того, чтобы писать математику и статистику выбранного вами алгоритма вручную (однако некоторые люди предпочитают это!), вы можете просто реализовать его на своем любимом языке программирования.
На самом деле, используя популярный фреймворк scikit-learn на Python, мы можем быстро обучить метод опорных векторов (тип алгоритма).
#Import the support vector machine module from the sklearn frameworkfrom sklearn import svm#Label x and y variables from our datasetx = ourData.featuresy = ourData.labels#Initialize our algorithmclassifier = svm.SVC()#Fit model to our dataclassifier.fit(x,y)
Scikit-learn — один из многих пакетов, используемых разработчиками для облегчения работы с машинным обучением и повышения его эффективности. Но есть и другие не менее популярные:
- TensorFlow
- Caffe (для глубокого обучения)
- MLlib (для больших данные)
- Torch (прежде всего GPU)
Онлайн курсы и видео
К счастью, в 2018 году появилось несколько отличных онлайн-ресурсов, которые помогут вам быстро освоиться с машинным обучением.
Практическое машинное обучение с Scikit-Learn и Tensorflow (O’Reilly) — «Благодаря серии последних достижений глубокое обучение расширило всю область машинного обучения. Теперь даже программисты, которые почти ничего не знают об этой технологии, могут использовать простые эффективные инструменты для реализации программ, способных учиться на данных. Эта практическая книга покажет вам как».
Машинное обучение в реальном мире (Мэннинг) — «Машинное обучение в реальном мире — это практическое руководство, предназначенное для обучения работающих разработчиков искусству создания ML. Без передозировки академической теорией и сложной математики она знакомит с повседневной практикой машинного обучения, подготавливая вас к успешному созданию и внедрению мощных систем ML».
Программируя коллективный интеллект (O’Reilly) — «Хотите использовать всю мощь поисковых рейтингов, рекомендаций по продуктам, социальных закладок и онлайн-знакомств? Эта увлекательная книга демонстрирует, как вы можете создавать приложения web 2. 0 для извлечения огромного количества данных, созданных людьми в интернете. С помощью сложных алгоритмов, описанных в этой книге, вы cможете создавать интеллектуальные программы для доступа к интересным наборам данных с других веб-сайтов и сбора данных от пользователей ваших собственных приложений».
0 для извлечения огромного количества данных, созданных людьми в интернете. С помощью сложных алгоритмов, описанных в этой книге, вы cможете создавать интеллектуальные программы для доступа к интересным наборам данных с других веб-сайтов и сбора данных от пользователей ваших собственных приложений».
Введение в статистическое обучение — «Введение в статистическое обучение предоставляет доступный обзор области статистического обучения, необходимый набор инструментов для понимания обширных и сложных наборов данных, появившихся в различных областях в последние двадцать лет: от биологии к финансам, от маркетинга к астрофизике. В этой книге представлены некоторые из наиболее важных методов моделирования и прогнозирования, а также соответствующие приложения».
Ваш первый проект машинного обучения на Python, шаг за шагом (Jason Brownlee) — «Хотите заниматься машинным обучением с использованием Python, но сложно уже в самом начале? В этом посте вы сделаете свой первый проект машинного обучения с использованием Python. Если вы новичок в машинном обучении и хотите наконец начать использовать Python, это руководство было разработано специально для вас».
Машинное обучение на Python: руководство по Scikit-Learn (Datacamp) — «Машинное обучение — это отрасль компьютерных наук, которая изучает проектирование алгоритмов, способных к обучению. Типичными задачами являются формирование понятий, прогнозирование, кластеризация и поиск моделей прогнозирования. Эти задачи реализуются на основе имеющихся данных, полученных в ходе наблюдения, эксперимента или инструкций».
Машинное обучение на Python: руководство (Dataquest) — «В этом учебном руководстве мы познакомим вас с основными принципами машинного обучения и с тем, как начать использовать машинное обучение с Python. К счастью для нас, в Python есть удивительная экосистема библиотек, с которой легко начать работать с машинным обучением. В этом руководстве мы будем использовать отличные библиотеки Scikit-learn, Pandas и Matplotlib».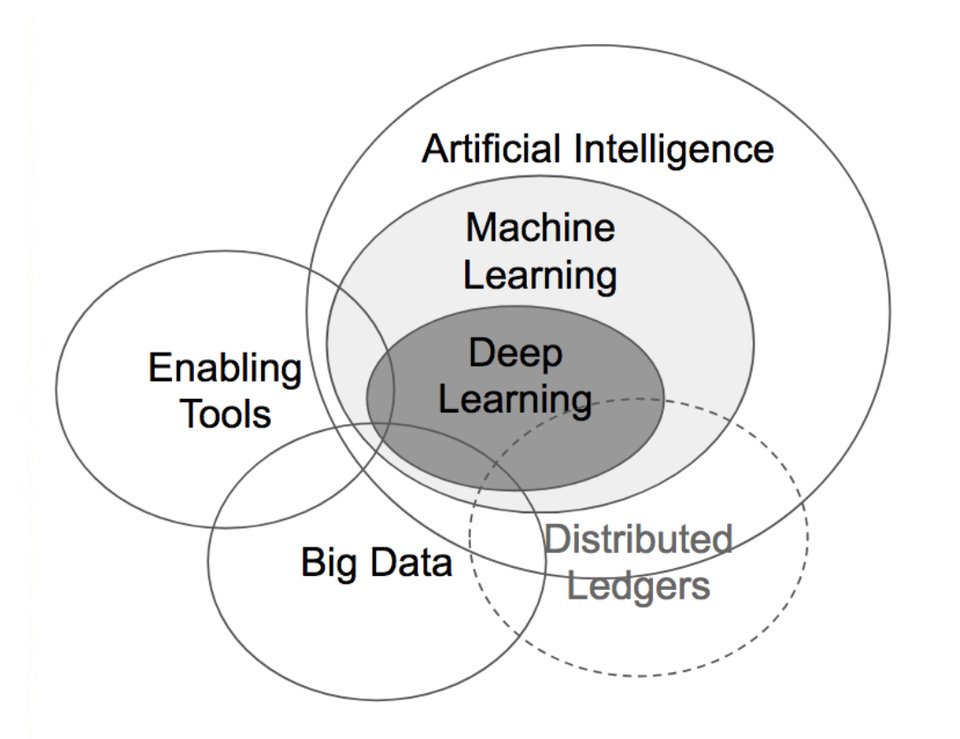
Машинное обучение на R для начинающих (Datacamp) — «Это небольшое руководство призвано познакомить вас с основами машинного обучения на R: оно покажет вам, как использовать R для работы с хорошо известным алгоритмом машинного обучения под названием «KNN» или метод k-ближайших соседей».
Введение в машинное обучение: полное руководство
Дата публикации Dec 3, 2018
Это первая из серии статей, в которых я опишу концепции, типы, алгоритмы машинного обучения и реализации Python.
Основными целями этой серии являются:
- Создание исчерпывающего руководства по теории и интуиции машинного обучения.
- Совместное использование и объяснение проектов машинного обучения, разработанных на python, для практического представления объясненных концепций и алгоритмов, а также того, как их можно применять в реальных задачах.
- Оставляя цифровой след моих знаний по предмету и вдохновляя других учиться и применять машинное обучение в своих областях.
Информация, представленная в этой серии, поступает из нескольких источников, являющихся основными:
- Инженер машинного обучения NanoDegree (Udacity)
- Книга «Машинное обучение Python» (Себастьян Рашка и Вахид Мирджалили)
- Книга глубокого обучения с Python (Франсуа Шоле)
- Мастерство машинного обучения с книгой Python (Джейсон Браунли)
- Курс Data Science и машинного обучения Python от Хосе Портилья (Удеми)
- Машинное обучение y Data Science и Python, курс Мануэля Гарридо (Удеми)
Благодаря значительному снижению цен на технологии и датчики, мы можем создавать, хранить и отправлять больше данных, чем когда-либо в истории. До девяноста процентов данных в мире сегодня было создано только за последние два года. Есть2,5 квинтиллиона байтов данныхсоздается каждый день в нашем текущем темпе, и ожидается, что этот темп будет только расти. Эти данные служат основой для моделей машинного обучения и являются основной движущей силой бума, который эта наука пережила в последние годы.
Эти данные служат основой для моделей машинного обучения и являются основной движущей силой бума, который эта наука пережила в последние годы.
Машинное обучение является одним из подполей искусственного интеллекта и может быть описано как:
«Машинное обучение — это наука о том, как заставить компьютеры учиться и действовать так, как это делают люди, и совершенствовать свое обучение с течением времени автономно, предоставляя им данные и информацию в форме наблюдений и взаимодействий в реальном мире». — Дэн Фагелла
Машинное обучение предлагает эффективный способ сбора знаний в данных для постепенного повышения производительности прогностических моделей и принятия решений на основе данных. Это стало повсеместной технологией, и мы пользуемся ее преимуществами в: фильтрах спама в электронной почте, автомобилях с автоматическим управлением, распознавании изображений и голоса иигроки мирового класса,
Следующее видео показывает обнаружение событий в реальном времени для приложения машинного обучения видеонаблюдения.
Как правило, в машинном обучении для обозначения данных используются матричные и векторные обозначения. Эти данные обычно используются в матричной форме, где:
- Каждая отдельная строка матрицы представляет собой образец, точку наблюдения или точку данных.
- Каждый столбец является признаком (или атрибутом) этого наблюдения.
- Обычно есть один столбец (или функция), который мы назовем целью, меткой или ответом, и это значение или класс, который мы пытаемся предсказать.
Обучение модели машинного обучения означает предоставление алгоритма машинного обучения с обучающими данными для его изучения.
Что касается алгоритмов машинного обучения, они обычно имеют некоторые внутренние параметры. То есть: в деревьях решений есть такие параметры, как глубина, количество узлов, количество листьев … Эти внутренние параметры называются гиперпараметрами.
Обобщение — это способность модели прогнозировать новые данные.
Типы машинного обучения, которые будут изучены в этой серии:
- Контролируемое обучение
- Неконтролируемое обучение
- Глубокое обучение
В этой серии мы рассмотрим и изучим все перечисленные типы машинного обучения, а также углубимся в методику глубокого обучения, называемую «обучение с подкреплением».
Контролируемое обучение относится к типу моделей машинного обучения, которые обучаются с помощью набора выборок, где желаемые выходные сигналы (или метки) уже известны. Модели учатся на основе этих уже известных результатов и вносят коррективы в свои внутренние параметры, чтобы приспособиться к входным данным. Как только модель должным образом обучена, она может делать точные прогнозы относительно невидимых или будущих данных.
Обзор общего процесса:
Существует два основных применения контролируемого обучения: классификация и регрессия.
- Classsification:
Классификация — это подкатегория контролируемого обучения, цель которой состоит в том, чтобы предсказать категориальные метки классов (дискретные, неупорядоченные значения, членство в группах) новых экземпляров на основе прошлых наблюдений. Типичным примером является обнаружение спама в электронной почте, который представляет собой двоичную классификацию (либо электронное письмо имеет значение -1-, либо не является -0- спамом). Существует также многоклассовая классификация, такая как распознавание рукописных символов (где классы идут от 0 до 9).
Пример бинарной классификации: есть 2 класса, круги и кресты, и 2 объекта, X1 и X2 Модель способна найти взаимосвязь между объектами каждой точки данных и ее классом и установить границу между ними, поэтому при предоставлении новых данных она может оценить класс, к которому она относится, с учетом ее характеристик.
В этом случае новая точка данных попадает в подпространство окружности, и, следовательно, модель предсказывает, что ее класс будет окружностью.
2. Регрессия:
Регрессия также используется для присвоения категорий немеченым данным. В этом типе обучения нам дают ряд предикторных (объяснительных) переменных и переменную непрерывного отклика (результат), и мы пытаемся найти взаимосвязь между этими переменными, которая позволяет нам прогнозировать непрерывный результат.
Пример линейной регрессии: с учетом X и Y мы подбираем прямую линию, которая минимизирует расстояние (с некоторыми критериями, например, среднеквадратичное расстояние (SSE)) между точками выборки и подобранной линией. Затем мы воспользуемся перехваченным и изученным наклоном подгоночной линии, чтобы предсказать исход новых данных.
В неконтролируемом обучении мы имеем дело с немаркированными данными неизвестной структуры, и цель состоит в том, чтобы исследовать структуру данных для извлечения значимой информации без ссылки на известную переменную результата.
Существует две основные категории: кластеризация и уменьшение размерности.
- Кластеризация:
Кластеризация — это исследовательский метод анализа данных, используемый для организации информации в значимые кластеры или подгруппы без каких-либо предварительных знаний о ее структуре. Каждый кластер — это группа похожих объектов, которая отличается от объектов других кластеров.
2. Уменьшение размерности:
Обычно работают с данными, в которых каждое наблюдение имеет большое количество признаков, другими словами, которые имеют высокую размерность. Это может быть проблемой для вычислительной производительности алгоритмов машинного обучения, поэтому уменьшение размерности является одним из методов, используемых для решения этой проблемы.
Методы уменьшения размерности работают путем нахождения корреляций между элементами, что означает, что существует избыточная информация, поскольку некоторые функции могут быть частично объяснены другими. Он удаляет шум из данных (что также может снизить производительность модели) и сжимает данные в меньшее подпространство, сохраняя при этом большую часть соответствующей информации.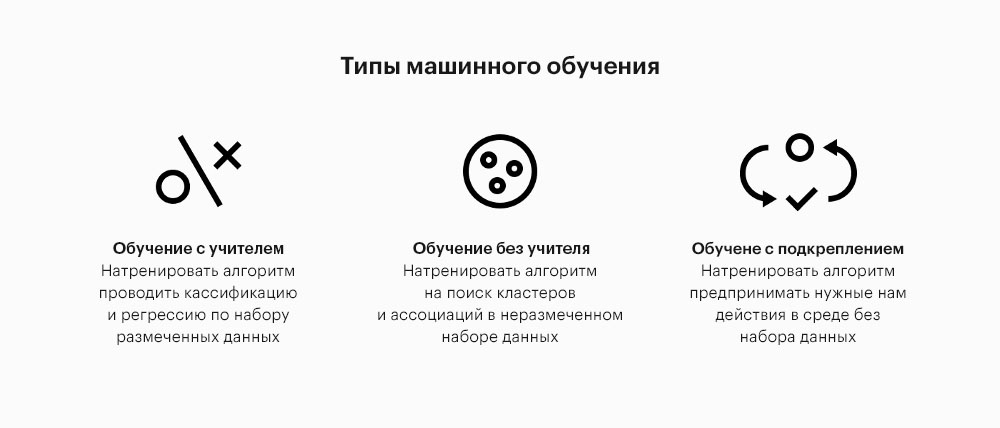
Глубокое обучение — это подполе машинного обучения, в котором используется иерархическая структура искусственных нейронных сетей, которые построены аналогично человеческому мозгу с узлами нейронов, соединенными в сеть. Эта архитектура позволяет выполнять анализ данных нелинейным способом.
Первый уровень нейронной сети принимает необработанные данные в качестве входных данных, обрабатывает их, извлекает некоторую информацию и передает ее на следующий уровень в качестве выходных данных. Каждый уровень затем обрабатывает информацию, предоставленную предыдущим, и повторяется до тех пор, пока данные не достигнут последнего уровня, который делает прогноз.
Этот прогноз сравнивается с известным результатом, а затем с помощью метода, называемого обратным распространением, модель может узнать весовые коэффициенты, которые дают точные результаты.
Усиленное обучение является одним из наиболее важных направлений глубокого обучения. Цель состоит в том, чтобы создать модель, в которой есть агент, который предпринимает действия, и целью которого является повышение его производительности. Это улучшение достигается путем предоставления определенного вознаграждения каждый раз, когда агент выполняет действие, которое относится к набору действий, которые разработчик хочет, чтобы агент выполнил.
Награда — это измерение того, насколько хорошо было действие для достижения заранее определенной цели. Затем агент использует эту обратную связь, чтобы скорректировать свое будущее поведение с целью получения наибольшего вознаграждения.
Одним из распространенных примеров является шахматный движок, где агент выбирает из ряда возможных действий, в зависимости от расположения доски (которая является состоянием среды), и вознаграждение дается при победе или проигрыше в игре.
Предварительная обработка:
Это один из самых важных шагов в любом приложении машинного обучения. Обычно данные поступают в формате, который не является оптимальным (или даже неадекватным) для модели для его обработки. В этом случае предварительная обработка является обязательной задачей.
В этом случае предварительная обработка является обязательной задачей.
Многие алгоритмы требуют, чтобы функции были в одном масштабе (например: в диапазоне [0,1]) для оптимизации его производительности, и это часто делается путем применения методов нормализации или стандартизации данных.
В некоторых случаях мы также можем обнаружить, что выбранные функции взаимосвязаны и, следовательно, избыточны для извлечения из них значимой информации. Затем мы должны использовать методы уменьшения размерности, чтобы сжать элементы в меньшие размерные подпространства.
Наконец, мы случайным образом разделим наш исходный набор данных на подмножества обучения и тестирования.
Обучение и выбор модели
Важно сравнить кучу разных алгоритмов, чтобы обучить и выбрать наиболее эффективный. Для этого необходимо выбрать метрику для измерения производительности модели. Одной из часто используемых в задачах классификации является точность классификации, которая представляет собой долю правильно классифицированных случаев. В задачах регрессии одной из самых популярных является среднеквадратичная ошибка (MSE), которая измеряет среднеквадратичную разницу между расчетными и реальными значениями.
Наконец, мы будем использовать метод перекрестной проверки, чтобы убедиться, что наша модель будет хорошо работать на реальных данных до использования подмножества тестирования для окончательной оценки модели.
Этот метод делит набор обучающих данных на меньшие обучающие и проверяющие подмножества, а затем оценивает способность модели к обобщению, другими словами, оценивая, насколько хорошо она может предсказать результаты при предоставлении новых данных. Затем он повторяет процесс,Ки вычисляет среднюю производительность модели путем деления суммы показателей, полученных междуКколичество итераций.
В целом, параметры по умолчанию алгоритмов машинного обучения, предоставляемые библиотеками, не являются лучшими для использования с нашими данными, поэтому мы будем использовать методы оптимизации гиперпараметров, чтобы помочь нам точно настроить производительность модели.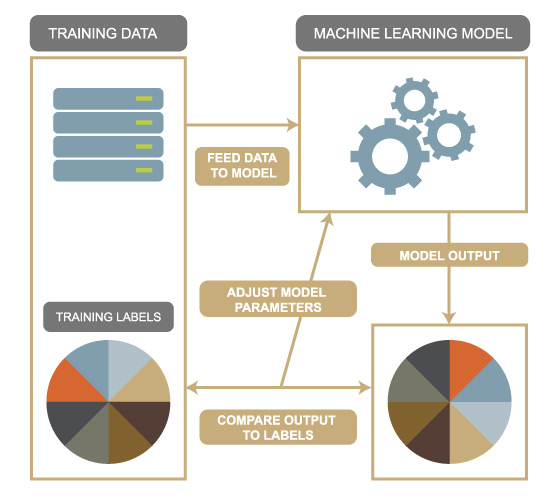
Оценка моделей и прогнозирование с использованием новых данных
После того, как мы выбрали и приспособили модель к нашему набору данных для обучения, мы можем использовать набор данных для тестирования, чтобы оценить производительность на этих невидимых данных, чтобы мы могли оценить ошибку обобщения модели. Или оцените это, используя другую метрику.
Если мы удовлетворены значением полученной метрики, мы можем использовать модель для прогнозирования будущих данных.
В этой статье мы узнали, что такое машинное обучение, рисует большую картину своей природы, мотивации и применения.
Мы также изучили некоторые основные обозначения и терминологию, а также различные виды алгоритмов машинного обучения:
- Контролируемое обучение с проблемами классификации и регрессии.
- Обучение без учителя, с кластеризацией и уменьшением размерности.
- Укрепление обучения, где агент учиться из своего окружения.
- Глубокое обучение и их искусственные нейронные сети.
Наконец, мы сделали введение в типичную методологию построения моделей машинного обучения и объяснили ее основные задачи:
- Предварительная обработка.
- Обучение и тестирование.
- Выбор модели.
- Оценка.
Как указывалось в начале статьи, это первая из серии статей, и это было общее введение. Это будет захватывающее путешествие, так как мы научимся применять множество мощных техник.
Это будет технический ряд, и поэтому мы рассмотрим некоторые понятия исчисления, линейной алгебры, статистики и питона, так как они будут необходимы для понимания основных понятий и работы алгоритмов. Но не волнуйтесь, мы будем осторожно подходить ко всем этим концепциям, поэтому, даже если у вас нет технического опыта, вы не будете чувствовать себя подавленным.
В следующих статьях будет объяснено, как настроить среду программирования Python с соответствующими библиотеками. И тогда мы будем готовы начать с глубокого изучения контролируемого обучения.
Следите за обновлениями!
Оригинальная статья
tyz910/hse-shad-ml: Введение в машинное обучение. Курс от ВШЭ и ШАД на coursera.org
GitHub — tyz910/hse-shad-ml: Введение в машинное обучение. Курс от ВШЭ и ШАД на coursera.org🎓 Введение в машинное обучение. Курс от ВШЭ и ШАД на coursera.org
Files
Permalink Failed to load latest commit information.Type
Name
Latest commit message
Commit time
В процессе прохождения курса слушатель изучает основные типы задач, решаемых с помощью машинного обучения — в основном речь идёт о классификации, регрессии и кластеризации. Узнает об основных методах машинного обучения и их особенностях, учится оценивать качество моделей — и решать, подходит ли модель для решения конкретной задачи. Наконец, знакомится с современными библиотеками, в которых реализованы обсуждаемые модели и методы оценки их качества.
Слушателю нужно знать об основных понятиях математики: функциях, производных, векторах, матрицах. Для выполнения практических заданий потребуются базовые навыки программирования. Желательно знать Python.
Неделя 1. Введение. Примеры задач. Логические методы: решающие деревья и решающие леса.
- Предобработка данных в Pandas
- Важность признаков
Неделя 2. Метрические методы классификации. Линейные методы, стохастический градиент.
- Выбор числа соседей
- Выбор метрики
- Нормализация признаков
Неделя 3.
 Метод опорных векторов (SVM). Логистическая регрессия. Метрики качества классификации.
Метод опорных векторов (SVM). Логистическая регрессия. Метрики качества классификации.- Опорные объекты
- Анализ текстов
- Логистическая регрессия
- Метрики качества классификации
Неделя 4. Линейная регрессия. Понижение размерности, метод главных компонент.
- Линейная регрессия: прогноз оклада по описанию вакансии
- Составление фондового индекса
Неделя 5. Композиции алгоритмов, градиентный бустинг. Нейронные сети.
- Размер случайного леса
- Градиентный бустинг над решающими деревьями
Неделя 6. Кластеризация и визуализация. Частичное обучение.
- Уменьшение количества цветов изображения
Неделя 7. Прикладные задачи анализа данных: постановки и методы решения.
- Проект: предсказания победителя в онлайн-игре
About
🎓 Введение в машинное обучение. Курс от ВШЭ и ШАД на coursera.org
Resources
You can’t perform that action at this time. You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session.Введение в машинное обучение: люди и изобретения, способствовавшие его зарождению и развитию — Статьи и полезные материалы на тему «»
На чтение 8 мин. Просмотров 100 Обновлено
Когда видишь заголовки статей о машинном обучении, кажется, что человечество только что сделало важное открытие. На самом деле, эта технология почти так же стара, как и необходимость в вычислениях. Этот материал — введение в машинное обучение. Вы узнаете, как оно зародилось и развивалось. Это поможет вам лучше понять, что это за технология.
Этот материал — введение в машинное обучение. Вы узнаете, как оно зародилось и развивалось. Это поможет вам лучше понять, что это за технология.
Закладка фундамента в области машинного обучения (1642—1936 гг)
Без этих мыслителей и мастеров не появились бы вычислительные машины, а тем более машинное обучение.
Хотите освоить машинное обучение и стать востребованным специалистом? Записывайтесь на «Курс по Machine Learning».[course id=1062]
1642 г. Юноша из Франции создает первый механический калькулятор. Его изобрел в 19 лет Блез Паскаль, чтобы облегчить работу отцу — сборщику налогов. Она может складывать, вычитать, умножать и делить.
Суммирующая машина «Паскалина»1679 г. Появляется современная двоичная система счисления. Немецкий математик, философ и языковед Готфрид Вильгельм Лейбниц разработал двоичную систему счисления, которая стала основой современных вычислительных машин.
1770 г. Появляется первый шахматный автомат, который дурачил Европу десятки лет. Механическое устройство под названием «Турок», которое обмануло самого Наполеона. Внутри прятался сильный шахматист и управлял шахматным автоматом. Со стороны казалось, что это чудо-машина, которая наделена разумом. Обман раскрылся только в 1857 году, когда последний владелец устройства показал, где прятался человек и как он управлял «Турком». Сегодня шахматная программа — уже не обман, а реальность. И заслуга в этом принадлежит машинному обучению.
«Турок» на гравюре современника. 1789 г1834 г. «Отец компьютера» придумывает программируемую вычислительную машину. Чарлз Бэббидж начинает проектировать аналитическую машину. Он так и не успел ее построить. Тем не менее его задумка стала основой архитектуры современных компьютеров.
1842 г. Алгоритм Ады Лавлейс делает ее первым программистом в истории. В 27 лет Ада создала последовательность операций для решения математических задач на аналитической машине Чарлза Бэббиджа. В ее честь Министерство обороны США назвала язык программирования для встроенных систем.
В ее честь Министерство обороны США назвала язык программирования для встроенных систем.
1847 г. Элементарная алгебра определяет работу процессоров за сто лет до их изобретения. Математик и логик Джордж Буль создал раздел алгебры, в котором все значения сводятся к одному из двух понятий: истина (true) или ложь (false). В современных компьютерах алгебра логики помогает процессору решить, как обрабатывать данные.
1927 г. Искусственный интеллект дебютировал на экране. Фриц Ланг снимает немой научно-фантастический художественный фильм «Метрополис», в котором знакомит зрителя с идеей разумной машины. Лже-Мария, один из персонажей фильма, стала первым роботом, запечатленном на кинопленке.
1936 г. Алан Тьюринг придумывает абстрактную вычислительную машину (машину Тьюринга). Вдохновленный протекающими в человеке процессами при решении задач, английский математик, логик и криптограф Алан Тьюринг представил процесс, как машина может расшифровывать и исполнять инструкции. Этот труд вошел в основу информатики.
[course id=1046]
От задумки к воплощению машинного обучения (1943—1999 гг)
Эта часть введения в машинное обучение посвящена предметам, которые за полвека из фантастики превратились в реальность.
1943 г. Биологическая нейронная сеть представляется как электрическая цепь. В этом году была сформулирована теория того, как работают нейроны. Для иллюстрации нейронные сети изобразили в виде электрической цепи. В 1950-х годах ученые из области информатики стали применять эту теорию в своих работах.
1952 г. Компьютер научился самосовершенствоваться в игре «Шашки». Первопроходец в машинном обучении Артур Сэмюэл создал программу, которая помогала компьютеру IBM играть в шашки с каждой партией все лучше и лучше. Ученые из области машинного обучения часто используют настольные игры, потому что они понятные и комплексные.
1959 г. Искусственная нейронная сеть научилась удалять помехи во время телефонных разговоров. Искусственная нейронная сеть представляет собой подобие нервной системы человека. Первая нейронная сеть, которую использовали для решения реальной проблемы, стала MADALINE. Она с помощью адаптивного фильтра удаляла эхо-сигналы на телефонных линиях. Эта нейронная сеть используется по сей день.
1968 г. Кубрик задает высокую планку для искусственного интеллекта 2001 года. Когда Стэнли Кубрик снимал «Космическую одиссею 2001 года», то консультировался с Марвином Ли Минским, сооснователем Лаборатории искусственного интеллекта в Массачусетском технологическом институте. Он спросил его, возможно ли, что к 2001 году появятся компьютеры, обладающие интеллектом, как у человека, и способные различать эмоции. Минский ответил, что это возможно.
1979 г. Стэнфордская тележка катится медленно, но верно. В 1960 году студент Стэнфордского университета Джеймс Адамс решил избавиться от проблем, которые возникают при управлении луноходом с Земли. Для этого он оснастил тележку камерой и дистанционным управлением. Спустя двадцать лет стэнфордская тележка смогла передвигаться по комнате с препятствиями (не задевая их) без участия человека.
Стэнфордская тележка1985 г. NETtalk научилась выговаривать слова. Эта нейронная сеть, разработанная Терри Сейновски и Чарльзом Розенбергом, за неделю научилась правильно произносить 20 000 слов. Первые слова звучали как тарабарщина, но с тренировкой ее речь стала более ясной и похожей на человеческую.
1997 г. Deep Blue побеждает чемпиона мира по шахматам. Когда шахматный компьютер Deep Blue, разработанный компанией IBM, обыграл Гарри Каспарова, это был первый случай, когда компьютер оказался в шахматах лучше человека.
Deep Blue1999 г. Компьютерная диагностика выявляет рак лучше докторов. Компьютеры не могут излечить от рака, но могут его диагностировать. Рабочая система в САПР, разработанная Чикагским университетом, отсканировала 22 000 маммограмм и обнаружила рак на 52% точнее радиологов.
Рабочая система в САПР, разработанная Чикагским университетом, отсканировала 22 000 маммограмм и обнаружила рак на 52% точнее радиологов.
[course id=1073]
Современное машинное обучение (2006—2017 гг)
В этой части введения в машинное обучение рассказывается, как машинное обучение вышло из лабораторий и стало проникать в нашу жизнь через разные отрасли.
2006 г. Изучение нейронной сети перерастает в «глубокое обучение». Когда нейронные сети вышли из лабораторий и стали применяться в жизни, специалист в области информатики Джеффри Хинтон переименовал изучение нейронных сетей в глубокое обучение. Сегодня влиятельные лица интернета используют этот метод, чтобы улучшить программы по распознаванию голоса и разметки изображений.
2009 г. BellKor’s Pragmatic Chaos выигрывает 1 млн. долларов в конкурсе от Netflix. В 2006 году Netflix предложила 1 млн. долларов тому, кто улучшит алгоритмы рекомендательной системы Cinematch. Эта система предлагает клиентам новые фильмы, основываясь на их мнении о просмотренных ранее кинолентах. Победитель определился только через три года. Им оказалась команда BellKor’s Pragmatic Chaos. Улучшить алгоритмы сумела и команда Ensemble. Однако она отправила результаты на 20 минут позже команды BellKor’s Pragmatic Chaos, поэтому и не выиграла.
2011 г. Суперкомпьютер IBM Watson побеждает в телевикторине Jeopardy (российский аналог — Своя игра). IBM Watson удалось обыграть двух самых сильных участников телевикторины. В планах у IBM развить эту технологию, чтобы она могла стать автоматизированным ассистентом врача и помогала в диагностировании и лечении болезней.
2012 г. Google Brain распознает человеческие лица на картинках. Нейронная сеть научилась распознавать людей и кошек в роликах на YouTube. Лица она распознает с точностью 81.7%, а кошек — с точностью 74.8%.
2014 г. Чатбот Женя Густман проходит тест Тьюринга. Он убеждает 33% экспертов в том, что является 13-летним мальчиком из Одессы.
Теста Тьюринга: эксперты пять минут переписываются одновременно с живым человеком и роботом, находясь в разных комнатах и не видя друг друга. Потом каждый эксперт говорит, кто был человеком, а кто — программой[read id=817]
2014 г. Компьютеры помогают улучшить приемные отделения больниц. Здравоохранение начинает использовать машинное обучение, чтобы предсказать время ожидания в приемных отделениях, опираясь на данные: укомплектованность персонала больницы, истории болезней и план больницы. Такие прогнозы помогают больницам сокращать время ожидания приема.
2015 г. Машины и люди объединяются для борьбы с мошенничеством в интернете. Когда PayPal собрался бороться с мошенничеством и отмыванием денег через сервис, он применил смешанный подход. Детективы задают параметры преступного поведения, а машина с помощью этих параметров выявляет мошенников на сайте PayPal.
2016 г. Компьютер выигрывает у человека в самой сложной настольной игре. AlphaGo стала первой программой, которая сумела обыграть самого лучшего игрока в го — Ли Седоля. Теперь можно официально утверждать, что компьютеры смогли обыграть человека в каждой классической настольной игре.
Матч AlphaGo — Ли Седоль2016 г. Компьютер научился читать по губам. HAL 9000, вымышленный компьютер из «Космической одиссеи 2001 года», умел читать по губам. Команда из Оксфорда сумела создать нейросеть LipNet, которая распознает слова по движениям губ с точностью 93.4%. Таким образом она превратила научную фантастику в реальность.
2016 г. Обработка естественного языка дает жизнь цифровому персональному консультанту. North Face стала первым продавцом, которая использовала IBM Watson для обработки естественного языка в мобильном приложении. Цифровой персональный консультант общается с клиентами и помогает им найти нужную вещь. То есть с такой программой у компании отпадает необходимость держать продавцов-консультантов.
Обработка естественного языка дает жизнь цифровому персональному консультанту. North Face стала первым продавцом, которая использовала IBM Watson для обработки естественного языка в мобильном приложении. Цифровой персональный консультант общается с клиентами и помогает им найти нужную вещь. То есть с такой программой у компании отпадает необходимость держать продавцов-консультантов.
2017 г. Машина научилась пресекать онлайн-троллинг. Компания Jigsaw создала систему, которая научилась определять троллинг, прочитав миллион комментариев на сайте. Алгоритмы системы могут пригодится владельцам сайтов, у которых не хватает ресурсов на модерацию.
[read id=552]
Что дальше ожидать от машинного обучения
На этом мы заканчиваем введение в машинное обучение. Точно не скажем, куда и насколько продвинется технология, — это покажет время. Однако уже сейчас заметно, что она пробралась почти во все сферы нашей жизни. Она помогает увеличивать продажи, повышает безопасность с помощью биометрических данных, предсказывает и диагностирует болезни и делает много чего еще.
Перевод статьи A history of machine learning.
Курс по Machine LearningКурс по нейронным сетям и deep learning совместно с NVIDIA
Курс по Python для анализа данных
Курс Data Science и Machine Learning (машинное обучение) Python для начинающих
Data science: курсы для начинающих
Наука о данных — это сочетание различных инструментов, алгоритмов и принципов машинного обучения с целью обнаружения скрытых закономерностей в данных. В чем её отличие от статистики, которая успешно использовалась на протяжении многих лет?
Специалист по data science не только проводит исследовательский анализ, чтобы извлечь из него выводы, но также использует различные алгоритмы машинного обучения для определения наступления конкретного события в будущем. Используя науку о данных, можно довольно быстро решать аналитически сложные задачи.
Data science набирает популярность во всех отраслях бизнеса: производство, энергетика, банки, здравоохранение и многие другие отрасли используют науку о данных и могут анализировать изменения и действия, которые необходимо предпринять. Используя эти данные, можно предлагать лучшие услуги и правильно анализировать рынок, что позволяет с минимальными затратами завоевать доверие заказчиков.
Более подробно познакомиться с наукой о данных, используемых методах и инструментах можно на курсе дата сайнс на питоне для начинающих. В этом курсе изучаются основы науки о данных и машинного обучения с подробным разбором популярных алгоритмов. Вы рассмотрите часто используемые термины и напишете код на Python.
Обучение разделено на несколько модулей, где большая часть курса data science занимает практика на python. На данном курсе будущий специалист по data science проходит обучение с нуля и получает базовые знания в области науки о данных и машинному обучению.
Курсы по машинному обучению (ml) на языке Python помогут разобраться в том, что такое Data Science и где оно применимо. Вы изучите терминологию науки о данных и основные алгоритмы машинного обучения на практических примерах и отработаете навыки на реальных отраслевых задачах в области науки о данных.
Курс машинного обучения с нуля — это возможность освоить азы по данному направлению под руководством специалистов-практиков, которые расскажут о различных сферах применимости науки о данных и инструментах, которые вам понадобятся для начала работы.
Курсы по нейронным сетям и машинному обучению могут пройти слушатели, успешно закончившие курс «Основы программирования на языке Python».
Введение в машинное обучение
Введение
Машинное обучение — это подраздел искусственного интеллекта (ИИ). Обычно цель машинного обучения — понять структуру данных и приспособить эти данные к моделям, которые могут быть поняты и использованы людьми.
Обычно цель машинного обучения — понять структуру данных и приспособить эти данные к моделям, которые могут быть поняты и использованы людьми.
Хотя машинное обучение — это область компьютерных наук, оно отличается от традиционных вычислительных подходов. В традиционных вычислениях алгоритмы — это наборы явно запрограммированных инструкций, используемых компьютерами для вычислений или решения проблем.Вместо этого алгоритмы машинного обучения позволяют компьютерам обучаться на вводе данных и использовать статистический анализ для вывода значений, которые попадают в определенный диапазон. Благодаря этому машинное обучение помогает компьютерам создавать модели на основе выборочных данных, чтобы автоматизировать процессы принятия решений на основе вводимых данных.
Любой пользователь технологий сегодня может извлечь выгоду из машинного обучения. Технология распознавания лиц позволяет платформам социальных сетей помогать пользователям отмечать и обмениваться фотографиями друзей.Технология оптического распознавания символов (OCR) преобразует изображения текста в подвижный шрифт. Системы рекомендаций, основанные на машинном обучении, предлагают, какие фильмы или телешоу смотреть дальше, в зависимости от предпочтений пользователя. Автомобили с автоматическим управлением, которые используют машинное обучение для навигации, вскоре могут стать доступными для потребителей.
Машинное обучение — постоянно развивающаяся область. В связи с этим необходимо учитывать некоторые факторы, когда вы работаете с методологиями машинного обучения или анализируете влияние процессов машинного обучения.
В этом руководстве мы рассмотрим распространенные методы машинного обучения с учителем и без учителя, а также общие алгоритмические подходы к машинному обучению, включая алгоритм k-ближайшего соседа, обучение по дереву решений и глубокое обучение. Мы выясним, какие языки программирования чаще всего используются в машинном обучении, и расскажем о положительных и отрицательных характеристиках каждого из них. Кроме того, мы обсудим предубеждения, которые сохраняются в алгоритмах машинного обучения, и рассмотрим, что можно иметь в виду, чтобы предотвратить эти предубеждения при построении алгоритмов.
Методы машинного обучения
В машинном обучении задачи обычно делятся на широкие категории. Эти категории основаны на том, как происходит обучение или как обратная связь об обучении передается в разработанную систему.
Двумя наиболее широко применяемыми методами машинного обучения являются контролируемое обучение , которое обучает алгоритмы на основе примеров входных и выходных данных, помеченных людьми, и неконтролируемое обучение , которое предоставляет алгоритм без помеченных данных, чтобы позволить ему найти структуру в своих входных данных.Давайте рассмотрим эти методы более подробно.
Обучение с учителем
При обучении с учителем компьютеру предоставляются примеры входов, которые помечены желаемыми выходными данными. Цель этого метода состоит в том, чтобы алгоритм мог «обучаться», сравнивая свой фактический результат с «обученными» выходными данными, чтобы находить ошибки и соответствующим образом изменять модель. Поэтому контролируемое обучение использует шаблоны для прогнозирования значений меток для дополнительных немаркированных данных.
Например, при обучении с учителем в алгоритм могут подаваться данные с изображениями акул, обозначенными как , рыба, , и изображениями океанов, обозначенными как , вода, .Обучаясь на этих данных, контролируемый алгоритм обучения должен иметь возможность позже идентифицировать немаркированные изображения акул как рыб и немаркированные изображения океана как вода .
Распространенным вариантом использования контролируемого обучения является использование исторических данных для прогнозирования статистически вероятных будущих событий. Он может использовать историческую информацию о фондовом рынке, чтобы предвидеть предстоящие колебания, или использоваться для фильтрации спама. При обучении с учителем фотографии собак с тегами могут использоваться в качестве входных данных для классификации фотографий собак без тегов.
При обучении с учителем фотографии собак с тегами могут использоваться в качестве входных данных для классификации фотографий собак без тегов.
Обучение без учителя
При обучении без учителя данные не маркируются, поэтому алгоритму обучения остается найти общие черты среди входных данных. Поскольку немаркированные данные более многочисленны, чем маркированные, методы машинного обучения, которые облегчают обучение без учителя, особенно ценны.
Цель обучения без учителя может быть такой же простой, как обнаружение скрытых закономерностей в наборе данных, но также может преследовать цель изучения функций, что позволяет вычислительной машине автоматически обнаруживать представления, необходимые для классификации необработанных данных.
Обучение без учителя обычно используется для транзакционных данных. У вас может быть большой набор данных о клиентах и их покупках, но как человек вы, скорее всего, не сможете понять, какие похожие атрибуты можно извлечь из профилей клиентов и их типов покупок. С помощью этих данных, введенных в алгоритм обучения без учителя, можно определить, что женщины определенного возраста, покупающие мыло без запаха, вероятно, будут беременны, и поэтому маркетинговая кампания, связанная с беременностью и товарами для детей, может быть нацелена на эту аудиторию, чтобы увеличить количество покупок.
Без получения «правильного» ответа методы обучения без учителя могут рассматривать сложные данные, которые являются более обширными и, казалось бы, не связанными друг с другом, чтобы систематизировать их потенциально значимым образом. Неконтролируемое обучение часто используется для обнаружения аномалий, в том числе для мошеннических покупок по кредитным картам, и для рекомендательных систем, которые рекомендуют, какие продукты покупать дальше. При обучении без учителя немаркированные фотографии собак могут использоваться в качестве входных данных для алгоритма, чтобы находить сходства и классифицировать фотографии собак вместе.
Подходит к
Как область, машинное обучение тесно связано с вычислительной статистикой, поэтому наличие базовых знаний в области статистики полезно для понимания и использования алгоритмов машинного обучения.
Для тех, кто, возможно, не изучал статистику, может быть полезно сначала определить корреляцию и регрессию, поскольку они являются обычно используемыми методами для исследования взаимосвязи между количественными переменными. Корреляция — это мера связи между двумя переменными, которые не обозначены как зависимые или независимые. Регрессия на базовом уровне используется для изучения взаимосвязи между одной зависимой и одной независимой переменной. Поскольку статистику регрессии можно использовать для прогнозирования зависимой переменной, когда независимая переменная известна, регрессия обеспечивает возможности прогнозирования.
Подходы к машинному обучению постоянно развиваются. Для наших целей мы рассмотрим несколько популярных подходов, которые используются в машинном обучении на момент написания статьи.
k-ближайший сосед
Алгоритм k-ближайшего соседа — это модель распознавания образов, которую можно использовать как для классификации, так и для регрессии. Часто обозначаемый как k-NN, k в k-ближайшем соседе является положительным целым числом, которое обычно невелико. При классификации или регрессии входные данные будут состоять из k ближайших обучающих примеров в пространстве.
Мы остановимся на классификации k-NN. В этом методе выходом является членство в классе.Это назначит новый объект классу, наиболее часто встречающемуся среди его ближайших k соседей. В случае k = 1 объект относится к классу единственного ближайшего соседа.
Давайте посмотрим на пример k-ближайшего соседа. На приведенной ниже диаграмме изображены объекты с голубыми ромбами и объекты оранжевой звезды. Они относятся к двум отдельным классам: классу бриллиантов и классу звезд.
Когда в пространство добавляется новый объект — в данном случае зеленое сердце — мы хотим, чтобы алгоритм машинного обучения классифицировал сердце по определенному классу.
Когда мы выбираем k = 3, алгоритм найдет трех ближайших соседей зеленого сердца, чтобы отнести его к классу бриллиантов или классу звезд.
На нашей диаграмме три ближайших соседа зеленого сердца — это один ромб и две звезды. Следовательно, алгоритм отнесет сердце к звездному классу.
Среди самых основных алгоритмов машинного обучения k-ближайший сосед считается типом «ленивого обучения», поскольку обобщение за пределами обучающих данных не происходит до тех пор, пока в систему не будет сделан запрос.
Обучение дереву решений
Для общего использования деревья решений используются для визуального представления решений и демонстрации принятия решений или информирования о них. При работе с машинным обучением и интеллектуальным анализом данных деревья решений используются в качестве модели прогнозирования. Эти модели сопоставляют наблюдения о данных с выводами о целевом значении данных.
Целью изучения дерева решений является создание модели, которая предсказывает значение цели на основе входных переменных.
В модели прогнозирования атрибуты данных, которые определяются посредством наблюдения, представлены ветвями, а выводы о целевом значении данных представлены в виде листьев.
При «изучении» дерева исходные данные разделяются на подмножества на основе теста значения атрибута, который повторяется рекурсивно для каждого производного подмножества. Как только подмножество в узле получит значение, эквивалентное его целевому значению, процесс рекурсии будет завершен.
Давайте рассмотрим пример различных условий, по которым можно определить, стоит ли кому-то ловить рыбу. Это включает в себя погодные условия, а также условия атмосферного давления.
В упрощенном дереве решений выше пример классифицируется путем сортировки его по дереву до соответствующего конечного узла. Затем возвращается классификация, связанная с конкретным листом, которая в данном случае является либо
Затем возвращается классификация, связанная с конкретным листом, которая в данном случае является либо Да, , либо Нет, . Дерево классифицирует условия дня в зависимости от того, подходит оно для рыбалки.
Настоящий набор данных дерева классификации будет иметь гораздо больше функций, чем указано выше, но отношения должны быть простыми для определения. При работе с изучением дерева решений необходимо сделать несколько определений, в том числе, какие функции выбрать, какие условия использовать для разделения и понять, когда дерево решений достигло четкого конца.
Глубокое обучение
Глубокое обучение пытается имитировать, как человеческий мозг может обрабатывать световые и звуковые стимулы для зрения и слуха. Архитектура глубокого обучения основана на биологических нейронных сетях и состоит из нескольких уровней в искусственной нейронной сети, состоящей из оборудования и графических процессоров.
Глубокое обучение использует каскад уровней нелинейных модулей обработки для извлечения или преобразования функций (или представлений) данных. Выход одного слоя служит входом следующего слоя.В глубоком обучении алгоритмы могут быть либо контролируемыми и служить для классификации данных, либо неконтролируемыми и выполнять анализ шаблонов.
Среди алгоритмов машинного обучения, которые в настоящее время используются и разрабатываются, глубокое обучение поглощает больше всего данных и смогло превзойти людей в некоторых когнитивных задачах. Благодаря этим атрибутам глубокое обучение стало подходом со значительным потенциалом в области искусственного интеллекта
.И в компьютерном зрении, и в распознавании речи были достигнуты значительные успехи благодаря подходам глубокого обучения.IBM Watson — хорошо известный пример системы, использующей глубокое обучение.
Языки программирования
При выборе языка для специализации с машинным обучением вы можете рассмотреть навыки, перечисленные в текущих объявлениях о вакансиях, а также библиотеки, доступные на разных языках, которые можно использовать для процессов машинного обучения.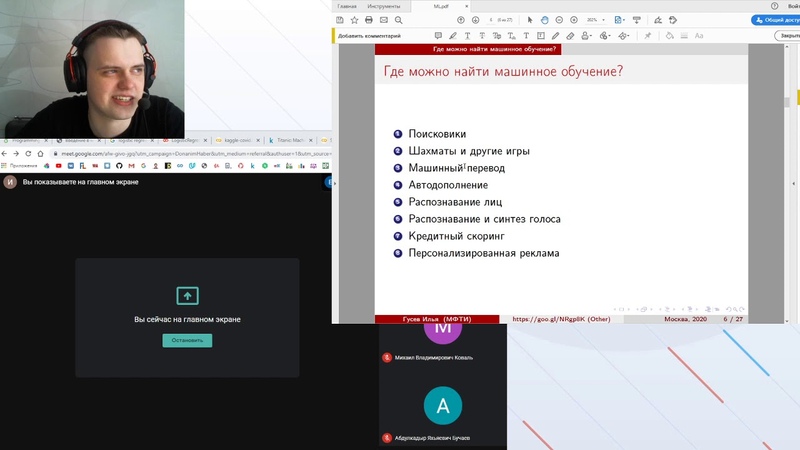
Из данных, взятых из объявлений о вакансиях на сайте Indeed.com в декабре 2016 года, можно сделать вывод, что Python является наиболее востребованным языком программирования в профессиональной сфере машинного обучения.За Python следует Java, затем R, затем C ++.
Популярность Python может быть связана с расширением разработки фреймворков глубокого обучения, доступных в последнее время для этого языка, включая TensorFlow, PyTorch и Keras. Как язык с читаемым синтаксисом и возможностью использования в качестве языка сценариев, Python оказывается мощным и простым как для предварительной обработки данных, так и для непосредственной работы с данными. Библиотека машинного обучения scikit-learn построена на основе нескольких существующих пакетов Python, с которыми разработчики Python, возможно, уже знакомы, а именно NumPy, SciPy и Matplotlib.
Чтобы начать работу с Python, вы можете прочитать нашу серию руководств «Как кодировать на Python 3» или прочитать, в частности, «Как создать классификатор машинного обучения на Python с помощью scikit-learn» или «Как выполнить передачу нейронного стиля» с Python 3 и PyTorch ».
Java широко используется в корпоративном программировании и обычно используется разработчиками интерфейсных настольных приложений, которые также работают над машинным обучением на уровне предприятия. Обычно это не лучший выбор для новичков в программировании, которые хотят узнать о машинном обучении, но те, кто имеет опыт разработки Java, предпочитают применять к машинному обучению.Что касается приложений машинного обучения в промышленности, Java обычно используется больше, чем Python для сетевой безопасности, в том числе в сценариях использования кибератак и обнаружения мошенничества.
Среди библиотек машинного обучения для Java — Deeplearning4j, распределенная библиотека глубокого обучения с открытым исходным кодом, написанная как для Java, так и для Scala; MALLET ( MA chine L заработок для L anguag E T oolkit) позволяет применять приложения машинного обучения для текста, включая обработку естественного языка, моделирование тем, классификацию документов и кластеризацию; и Weka, набор алгоритмов машинного обучения для использования в задачах интеллектуального анализа данных.
R — это язык программирования с открытым исходным кодом, используемый в основном для статистических вычислений. Его популярность за последние годы выросла, и многие в академических кругах предпочитают его. R обычно не используется в промышленных производственных средах, но получил широкое распространение в промышленных приложениях из-за возросшего интереса к науке о данных. Популярные пакеты для машинного обучения в R включают Caret (сокращение от C lassification A nd RE gression T raining) для создания прогнозных моделей, randomForest для классификации и регрессии и e1071, который включает функции для статистики и теории вероятностей. .
C ++ — предпочтительный язык для машинного обучения и искусственного интеллекта в играх или приложениях для роботов (включая перемещение роботов). Разработчики оборудования для встраиваемых вычислений и инженеры-электронщики с большей вероятностью отдают предпочтение C ++ или C в приложениях для машинного обучения из-за их знаний и уровня контроля над языком. Некоторые библиотеки машинного обучения, которые вы можете использовать с C ++, включают масштабируемый mlpack, Dlib, предлагающий широкий спектр алгоритмов машинного обучения, а также модульную Shark с открытым исходным кодом.
Человеческие предубеждения
Хотя данные и вычислительный анализ могут заставить нас думать, что мы получаем объективную информацию, это не так; основание на данных не означает, что результаты машинного обучения нейтральны. Человеческая предвзятость играет роль в том, как данные собираются, организовываются и, в конечном итоге, в алгоритмах, которые определяют, как машинное обучение будет взаимодействовать с этими данными.
Если, например, люди предоставляют изображения для «рыбы» в качестве данных для обучения алгоритма, и эти люди в подавляющем большинстве выбирают изображения золотой рыбки, компьютер может не классифицировать акулу как рыбу.Это создаст предубеждение против акул как рыб, и акулы не будут считаться рыбами.
При использовании исторических фотографий ученых в качестве данных для обучения компьютер может неправильно классифицировать ученых, которые также являются цветными людьми или женщинами. Фактически, недавнее рецензируемое исследование показало, что программы искусственного интеллекта и машинного обучения демонстрируют человеческие предубеждения, включая расовые и гендерные предрассудки. См., Например, «Семантика, полученная автоматически из языковых корпусов, содержит человеческие предубеждения» и «Мужчины также любят ходить по магазинам: уменьшение гендерных предубеждений с помощью ограничений на уровне корпуса» [PDF].
Поскольку машинное обучение все чаще используется в бизнесе, невыявленные предубеждения могут увековечить системные проблемы, которые могут помешать людям иметь право на получение ссуд, показывать объявления о высокооплачиваемых вакансиях или получать варианты доставки в тот же день.
Поскольку человеческая предвзятость может негативно повлиять на других, чрезвычайно важно знать о ней, а также работать над ее устранением в максимально возможной степени. Один из способов добиться этого — убедиться, что над проектом работают разные люди, а разные люди тестируют и проверяют его.Другие призвали регулирующие третьи стороны контролировать и проверять алгоритмы, создавать альтернативные системы, которые могут обнаруживать предвзятость, и проводить этические проверки в рамках планирования проектов по науке о данных. Повышение осведомленности о предубеждениях, осознание наших собственных подсознательных предубеждений и структурирование справедливости в наших проектах и конвейерах машинного обучения могут помочь в борьбе с предвзятостью в этой области.
Заключение
В этом руководстве были рассмотрены некоторые варианты использования машинного обучения, общие методы и популярные подходы, используемые в этой области, подходящие языки программирования для машинного обучения, а также рассмотрены некоторые вещи, которые следует учитывать с точки зрения неосознанных предубеждений, воспроизводимых в алгоритмах.
Поскольку машинное обучение — это область, которая постоянно обновляется, важно помнить, что алгоритмы, методы и подходы будут продолжать меняться.
Помимо чтения наших руководств «Как создать классификатор машинного обучения на Python с помощью scikit-learn» или «Как выполнить передачу нейронного стиля с помощью Python 3 и PyTorch», вы можете узнать больше о работе с данными в технологической отрасли. прочитав наши руководства по анализу данных.
Введение в машинное обучение | MIT Press
Вводный текст по машинному обучению, который дает унифицированное описание методов, основанных на статистике, распознавании образов, нейронных сетях, искусственном интеллекте, обработке сигналов, управлении и интеллектуальном анализе данных.
Цель машинного обучения — запрограммировать компьютеры на использование примеров данных или прошлого опыта для решения данной проблемы. Уже существует множество успешных приложений машинного обучения, в том числе системы, которые анализируют прошлые данные о продажах для прогнозирования поведения клиентов, распознавания лиц или устной речи, оптимизируют поведение роботов, чтобы задача могла быть выполнена с минимальными затратами ресурсов, и извлекают знания из биоинформатических данных. Введение в машинное обучение — это всеобъемлющий учебник по этому предмету, охватывающий широкий круг тем, обычно не включаемых во вводные тексты по машинному обучению.В нем обсуждается множество методов, основанных в различных областях, включая статистику, распознавание образов, нейронные сети, искусственный интеллект, обработку сигналов, управление и интеллектуальный анализ данных, чтобы представить единую трактовку проблем и решений машинного обучения. Все алгоритмы обучения объяснены, чтобы учащийся мог легко перейти от уравнений в книге к компьютерной программе. Книгу могут использовать продвинутые студенты и аспиранты, окончившие курсы компьютерного программирования, теории вероятностей, исчисления и линейной алгебры.Книга также будет интересна инженерам, занимающимся применением методов машинного обучения. После введения, в котором дается определение машинного обучения и приводятся примеры приложений машинного обучения, книга охватывает контролируемое обучение, байесовскую теорию принятия решений, параметрические методы и т. Д. многомерные методы, уменьшение размерности, кластеризация, непараметрические методы, деревья решений, линейная дискриминация, многослойные персептроны, локальные модели, скрытые марковские модели, оценка и сравнение алгоритмов классификации, объединение нескольких учащихся и обучение с подкреплением.
Ресурсы для инструкторов
Доступные для загрузки ресурсы для инструкторов по этому заголовку: слайды, программы Matlab, решения.
Мягкое введение в концепции машинного обучения | Робби Аллен | Машинное обучение на практике
Учитывая внимание, которое уделяется машинному обучению, и сложные проблемы, которые оно решает, это может показаться волшебством. Но это не так. Он построен на основе математики и статистики, разработанной на протяжении многих десятилетий.
Один очень практичный способ думать о машинном обучении — это уникальный способ программирования компьютеров. Большая часть программирования, которое является , а не машинным обучением (и практическими программами, с которыми люди работали больше всего за последние 50 лет), носит процедурный характер — это, по сути, набор правил, определенных человеком. Этот набор правил называется алгоритмом.
В машинном обучении основной алгоритм выбирается или разрабатывается человеком. Однако алгоритмы учатся на данных, а не при непосредственном вмешательстве человека, о параметрах, которые будут формировать математическую модель для прогнозирования.Люди не знают и не задают эти параметры — это знает машина. Другими словами, набор данных используется для обучения математической модели, чтобы, когда он увидит похожие данные в будущем, он знает, что с ними делать. Модели обычно принимают данные в качестве входных данных, а затем выводят прогноз чего-то интересного.
Руководителям не обязательно быть экспертами в области машинного обучения, но даже небольшие знания могут иметь большое значение. Если вы поймете, что можно делать с помощью машинного обучения, вы поймете, с чего начать, и поймете, во что вам следует углубиться.И вам не придется вслепую говорить своей технической команде «сделайте немного волшебства», а затем надеяться, что они добьются успеха. В этом посте мы дадим вам достаточно знаний, чтобы быть опасным. Мы начнем с методов машинного обучения, о которых вы, возможно, слышали, решим фундаментальную проблему машинного обучения, погрузимся в глубокое обучение и обсудим физические и вычислительные реалии, которые делают все это возможным. В целом, мы надеемся, что ваши беседы с специалистами по обработке данных и инженерами будут более продуктивными.
Машины обучаются по-разному с разной степенью «контроля»: контролируемые, неконтролируемые и частично контролируемые.Обучение с учителем — это наиболее распространенная и самая простая форма машинного обучения. Однако обучение без учителя не требует такого количества данных и имеет наиболее практические варианты использования.
Типы машинного обучения по данным и развертываниям. Типы машинного обучения по данным и использованию. Контролируемое обучениеМашины часто обучаются по образцам данных, которые содержат как пример ввода, так и пример вывода. Например, одна пара данных-выборка может быть входными данными о кредитной истории человека, а связанные выходные данные представляют собой соответствующий кредитный риск (либо указанный человеком, либо основанный на исторических результатах).Получив достаточное количество этих выборок ввода-вывода, машина узнает, как построить модель, которая согласуется с образцами, на которых она обучалась.
Оттуда модель может быть применена к новым данным , которых она никогда раньше не видела — в данном случае к кредитным историям новых лиц. После изучения выборочных данных модель применяет полученные знания в реальном мире.
Этот класс машинного обучения называется «обучением с учителем», поскольку дается желаемый прогнозируемый результат, а модель «контролируется» для изучения связанных параметров модели.Люди знают правильный ответ и наблюдают за моделью, пока она учится находить его. Поскольку люди должны маркировать все данные, контролируемое обучение — это трудоемкий процесс.
Задачи контролируемого обучения включают:
Классификация
Цель задачи классификации — определить, к какой группе принадлежит данный ввод. Например, медицинский случай, при котором возможно наличие болезни / отсутствие болезни. Другой классический пример — разделение изображений животных на группы кошек и собак.
Машина обучается на данных с множеством примеров входных данных (например, изображение животного) и соответствующих выходных данных, часто называемых метками (например, «кошка» или «собака»). Обучите модель с помощью миллиона изображений собак и кошек, и она должна уметь классифицировать изображение новой собаки, которого не было в данных для обучения.
Классификация.Регрессия
Как и классификация, регрессия также касается входов и соответствующих выходов. Но выходными данными для классификации обычно являются дискретные типы (кошка, собака), а выходными данными для регрессии — общее число.Другими словами, это не 0 или 1, а скользящая шкала вероятностей. Например, по радиологическому изображению модель может предсказать, сколько еще лет соответствующий человек будет болен или здоров.
Регрессия Обучение без учителяПри обучении без учителя машина учится на данных, результаты которых неизвестны. Даны входные выборки, но нет выходных.
Например, представьте, что у вас есть набор документов, который вы хотите систематизировать.Например, одни документы могут быть о спорте, другие — об истории, а третьи — об искусстве. Учитывая только набор документов, цель состоит в том, чтобы автоматически научиться группировать их по типам.
КластеризацияДля кластеризации в примерах данных предоставляется только ввод (данные, которые нужно систематизировать). Явного вывода не предусмотрено. Модель может кластеризовать спортивные документы в одну группу и исторические документы в другую, но в ней никогда не говорилось явно, как выглядел спортивный или исторический документ, так как он никогда не отображался в виде выходных данных.Фактически, после завершения кластеризации модель по-прежнему не будет знать, что такое спортивный или исторический документ. Модель «знает» только то, что входные данные в группе A похожи друг на друга, как и входные данные в группе B. Люди должны смотреть на кластеры и решать, имеют ли они смысл и насколько это возможно.
Обучение без учителя менее распространено в практических деловых условиях, но оно привлекательно: вам не нужны маркированные данные, и вы можете избежать человеческих усилий и затрат на это. Обучение без учителя потенциально применимо во многих других областях, поскольку оно не ограничивается только приложениями с помеченными данными.
Полу-контролируемое обучениеКак мы видели, контролируемые и неконтролируемые задачи имеют разные требования к данным: контролируемое обучение обычно требует сбора данных для обучения, в то время как обучение без учителя относительно просто. В полууправляемом обучении специалисты по обработке данных объединяют и то, и другое. Модель использует немаркированные данные, чтобы получить общее представление о структуре данных, а затем использует небольшой объем помеченных данных, чтобы научиться группировать и организовывать данные в целом.Иногда это называют «слабым обучением».
Преимущество этого подхода состоит в том, что часто количество помеченных данных, необходимых для изучения хорошей модели, может быть уменьшено, поскольку есть возможность учиться на контекстной информации, предоставляемой немаркированными данными.
Трансферное обучениеТрансферное обучение — это, по сути, передача знаний от одной задачи к другой. Люди очень хороши в этом — если ребенок научится играть в бейсбол, некоторые аспекты того, что они изучают, также помогут ему играть в кикбол.
Пример машинного обучения — обучение модели для классификации изображений кошек, собак, столов и т. Д., Возможно, с использованием известного набора данных ImageNet из миллионов изображений. После того, как модель обучена этому, значительную часть модели можно будет использовать для совершенно другой задачи, такой как идентификация опухолей на рентгеновском изображении.
В этом случае можно повторно использовать значительную часть предыдущей модели, а затем специализировать оставшуюся часть модели для конкретной новой интересующей задачи. Оказывается, функции, изученные для одной задачи, такие как классификация кошек и собак, также могут быть полезны, скажем, для обнаружения опухолей.Конечно, требуется точная настройка, корректировка весов, чтобы они больше подходили для новой задачи. Но при трансферном обучении, начиная от решения до первой задачи, вы получите лучшее и более быстрое решение, чем при запуске с нуля.
Трансферное обучение может существенно сократить объем данных, необходимых для новой задачи, что является потенциальной выгодой для бизнеса. Скажите руководителю, что у вас есть замечательный детектор изображений, который требует обучения на миллионе изображений, и руководитель может отчаяться, что у него нет миллиона изображений, не говоря уже о возможности маркировать их все.Преимущество трансферного обучения в том, что вам не нужен миллион изображений. Вместо этого вы можете быть только в тысячах или десятках тысяч. Используя предварительно обученную сеть, мы все равно можем получить хорошее решение быстрее и лучше, чем если бы мы просто пытались обучить его только на ваших данных.
Другой пример трансферного обучения происходит с обработкой естественного языка, когда машины обрабатывают текст. После того, как первоначальная модель изучает язык, грамматику, орфографию и т. Д., Это обучение можно перенести на такие задачи, как тональность или классификация.
Однако небольшое предостережение: не думайте, что задачи, для которых человека могут легко передать свое обучение, обязательно созрели для машинного обучения. Это не всегда очевидно. Хотя человеку очень легко превратить машины в человека, машины — это не люди, и они учатся совершенно по-другому.
Обучение с подкреплениемНапомним, что контролируемое обучение требует ввода и вывода примеров. Обучение с подкреплением похоже на обучение без учителя в том смысле, что результаты обычно не выдаются.
Центральная концепция обучения с подкреплением основана на «агенте» (компьютере или роботе), который взаимодействует с «окружающей средой» (здесь определяется как все, что не является агентом).
Агент выполняет действия со средой (например, робот делает шаг вперед). Затем среда предоставит агенту своего рода обратную связь, обычно в форме, называемой «вознаграждение».
Под «наградой» мы не подразумеваем, что мы даем машине толчок электронов.Мы буквально просто добавляем к счетчику вознаграждений программы. Цель агента — увеличить число на этом счетчике. Однако критично то, что никто не говорит агенту , как максимизировать вознаграждение, и не объясняет , почему получает вознаграждение. Это то, что агент понимает для себя, предпринимая действия и наблюдая за окружающей средой.
Во многих формах обучения с подкреплением агент не знает, какова цель, потому что у него нет примеров успеха. Все, что он знает, — получит ли он награду или нет.
Обучение с подкреплением имеет отголоски человеческой психологии: мозг переживает что-то хорошее, а выброс дофамина заставляет человека хотеть этого еще больше. Плохой опыт, например прикосновение к горячей плите, вызывает боль, которая отбивает у человека желание повторить такое поведение. Однако, несмотря на параллели с человеческой психологией, слишком гуманизировать ее — ошибка.
Специалисты по обработке данных изо всех сил стараются сделать данные обучения как можно более репрезентативными для реального мира. В противном случае можно построить модель, которая максимизирует производительность для обучающих данных, но не подходит для чего-либо еще.Это называется переобучением.
Для пояснения рассмотрим крайний пример. Ленивый специалист по анализу данных может создать детектор изображений собаки / кошки с простой поисковой таблицей: учитывая этот конкретный ввод, произведите этот конкретный результат. Если бы специалист по данным имел тысячу помеченных изображений собак / кошек и поместил каждое из них в справочную таблицу, он мог бы создать «идеальную» систему классификации без необходимости машинного обучения. Когда система увидит точную комбинацию пикселей, она будет знать, как ее обозначить.
Таблица поиска может идентифицировать только то, что ей уже известно.Излишне говорить, что это была бы ужасная система — она будет работать только с данными изображения, которые она уже знает.Измените всего один пиксель, и система больше не распознает собаку. Это перебор: модель идеально соответствует тренировочным данным (1000 помеченных изображений), но не соответствует реальному миру (любым другим изображениям собаки).
К счастью, у нас нет таких специалистов по данным. На практике переоснащение не так очевидно, но по-прежнему вызывает серьезную озабоченность.
Рассмотрим график с площадью дома в квадратных футах по оси X и его ценой по оси Y. Представьте себе несколько точек данных, нанесенных на график.Соотношение между площадью и ценой проще всего представить в виде прямой линии.
Базовая подгонка данныхНо эта линия не будет идеальной — фактически, она может пропустить все фактические точки данных. Вернемся к уроку алгебры: вы помните, что эту линейную функцию можно представить как y = mx + b. m и b называются параметрами — измените их, и вы измените характер линии.
Вы можете добавить больше параметров, чтобы создать более сложную функцию, которая лучше соответствует данным.Например, вот функция, где y = ax2 + bx + c. Вы можете видеть, что с тремя параметрами кривая более точно соответствует вашим данным.
Более сложная подгонка данныхУчитывая эту тенденцию, вы, естественно, могли бы продолжать увеличивать количество параметров, пока ваша линия не будет точно соответствовать каждой точке ваших тренировочных данных.
Явное переоснащение данныхНо здравый смысл подсказывает вам, что эта линия не является истинным отображением цен на жилье в реальном мире. Мы построили модель, которая работает только с нашими обучающими данными, но не является обобщающей.Реальные данные не будут точно ложиться на сглаженную кривую. Это может показаться безупречным решением, но это немного лучше, чем справочная таблица для собак и кошек.
Чтобы избежать переобучения, специалисты по обработке данных обычно разделяют данные на три набора: обучение, проверка и тестирование. Они случайным образом скремблируют данные в этих наборах, потому что хотят, чтобы они имели одинаковое распределение.
Обучающий набор может содержать 70% данных. Это единственные данные, которые используются в качестве обратной связи для модели, на которой можно учиться.Специалисты по обработке данных хотят оптимизировать модель за счет уменьшения потерь, то есть уменьшения того, насколько плохо модель описывает обучающие данные. По мере продолжения оптимизации обучающих данных потери должны уменьшаться.
Проверка (около 10% данных) — это данные, на которых модель не обучена. Скорее, он используется для поиска правильной модели, точной настройки параметров и предотвращения переобучения. По мере развития нашей модели специалисты по обработке данных должны также видеть сокращение потерь для набора для проверки. Но в какой-то момент модель будет оптимизироваться для обучающих данных, но не для данных проверки.Потери на обучение будут продолжать уменьшаться, но потери на валидацию начнут постепенно увеличиваться. Вот как специалисты по данным могут обнаружить переоснащение или то, что они выбрали неправильную модель. Если модель работает только с обучающими данными, но не с данными проверки, она не является должным образом обобщающей.
Но проблема все еще есть. Если модель соответствует набору обучающих данных , а — к набору проверки, все еще есть шанс, что ей просто «повезло», что набор проверки оказался похож на обучающий набор.Несмотря на то, что наборы данных являются случайными, все же существует вероятность, что модель просто подходит для ваших данных обучения и проверки, но все равно не будет хорошо работать в реальном мире.
Итак, как определить, насколько хороша модель на самом деле ? Введите тестовый набор данных — оставшиеся 20% данных. Теоретически тестирование следует проводить только один раз, хотя на практике машинное обучение может нарушить это правило. Но причина сделать это только один раз заключается в том, что в идеале, как только модель будет завершена, этот набор тестов дает хорошую оценку того, как модель будет работать в реальном мире.
На практике, конечно, реальные данные могут не совпадать с данными обучения, тестирования или проверки. Если это так (либо из-за того, что исходные данные были плохими, либо из-за того, что реальный мир меняется), после развертывания модель может перестать работать. Данные, с которыми модель сталкивается при развертывании, могут быть возвращены в модель и улучшены, но для этого может потребоваться надзор со стороны человека и переподготовка. Предоставленная самой себе устройство, модель может не работать с реальными данными и отклоняться от идеальной производительности.
Машинное обучение происходит не только в эфире. Все эти вычисления должны где-то происходить. Независимо от того, выполняете ли вы вычисления на месте или в облаке, машинное обучение — это не только математическая реальность, но и физическая реальность. Вот несколько ключевых концепций, которые следует знать, когда вы разговариваете с специалистами по обработке данных и инженерами о своих возможностях машинного обучения. Как вы можете догадаться, ваши потребности в машинном обучении будут зависеть от таких факторов, как скорость ответа, количество прогнозов и внешний вид этих запросов.
Вычисления / обработкаЭто процессоры, которые обучают и обслуживают вашу модель машинного обучения. Популярным вариантом здесь являются графические процессоры (GPU), которые изначально были созданы для видеоигр. Затем эксперты обнаружили, что графические процессоры могут обучать сети глубокого обучения намного быстрее, чем центральные процессоры (ЦП). Хотя технолог может возразить против такой характеристики, вы можете думать о графическом процессоре как о действительно быстром процессоре.
Итак, если графические процессоры быстрее, они всегда должны быть лучше, верно?
Не во всех случаях.Во-первых, графические процессоры дороже процессоров. Во-вторых, вам нужны специализированные программы, которые действительно могут их использовать. Графические процессоры хороши для простых задач, но центральные процессоры лучше для сложных. И графические процессоры не всегда имеют большое значение. Если вы тренируете алгоритм на 10 миллионах записей, может быть важно иметь возможность двигаться в 100 раз быстрее. Но если после обучения вы делаете только одно предсказание за раз, то переход от 100 миллисекунд к 1 миллисекунде будет незаметной разницей для конечного пользователя и, следовательно, пустой тратой денег.Прежде чем принять резкое решение о покупке или аренде графических процессоров, убедитесь, что у вас есть много данных и очевидная потребность.
Машины с графическим процессоромчасто более полезны во время части обучения процесса машинного обучения, когда они необходимы для обработки больших объемов данных и установки весов и параметров данной модели машинного обучения. Вычислительные ресурсы, необходимые для запуска уже обученной модели в производственной среде, обычно менее мощны.
Гипотетические требования: обучение vs.ПроизводствоОбучение
- ОЗУ 64 ГБ
- Диск 500 ГБ
- 2x GPU
Производство
- 2 ГБ RAM
- Диск 500 ГБ
- 2x CPU
RAM
Это память компьютера. Обычно он вмещает меньше жесткого диска для длительного хранения, но он быстрее. ОЗУ ограничивает количество вещей, которые могут обрабатываться одновременно.Его также называют энергозависимым, потому что после перезагрузки компьютера он исчезает.
Хорошая аналогия — поднос авиакомпании. Если вы кладете на него ноутбук, но вам подадут напиток, вам придется закрыть ноутбук и снять его, если вам нужно место для напитка. Когда вы выключаете компьютер, оперативная память очищается — точно так же, как ваш лоток в конце полета.
Больше оперативной памяти полезно в тех случаях, когда вы потенциально можете обрабатывать большие объемы одновременных запросов. Если в этом нет необходимости, вам не понадобится столько оперативной памяти.
Долгосрочное хранилище / дисковое пространствоЭто жесткий диск, на котором постоянно хранятся данные. Дисковое пространство — это место, где вы храните вещи вечно, например, картотечный шкаф. Вы загружаете вещи из этого и на свой «поднос для авиалиний», когда будете готовы взглянуть на них. В мире машинного обучения хранилище обычно содержит вашу модель машинного обучения и ваш набор данных.
Стандартные фреймворкиЕсли все, что вам нужно, это что-то готовое, вам совсем не обязательно беспокоиться о базовой инфраструктуре вашего проекта машинного обучения.Как и видео по запросу, машинное обучение может быть предоставлено вам как услуга. Точно так же, как вам не нужно знать, какие процессоры лежат в основе ваших последних потоковых разгул-часов, вам не нужно беспокоиться о том, стоят ли за вашим инструментом машинного обучения графические процессоры или процессоры. Просто загрузите данные, выберите некоторые параметры и дайте ему поработать.
Итак, как узнать, нужна ли вам индивидуальная разработка или можно полагаться на существующую структуру? Это зависит от сложности проблемы, которую вы пытаетесь решить, и от ваших знаний о том, как ее решить.Стандартные каркасы просты в использовании, но они лучше всего подходят для решения относительно простых задач.
Но большая часть машинного обучения, особенно глубокого обучения, — это , а не plug-and-play. Простая настройка скорости обучения так или иначе почти таким образом, что не обязательно в точности с использованием вашей интуиции, может иметь большое значение. Конечно, со временем эти рамки будут улучшаться и станут все более полезными для решения сложных проблем. Но на данный момент готовые фреймворки по-прежнему предназначены для решения простейших, наиболее четко определенных и легко структурируемых задач.Это по определению проблемы, которые кто-то уже решил. Чем больше ваша конкретная задача требует уникальной настройки, тем меньше вы сможете полагаться на что-то из имеющихся.
Опять же, ключевая фраза — «пока». Эти фреймворки продолжают совершенствоваться, поэтому, даже если вы по праву откажетесь от них сейчас, вы можете периодически пересматривать их возможности, чтобы видеть, могут ли их достижения удовлетворить ваши потребности.
Правильно ли вы оптимизируете?Вам не обязательно нужны самые передовые технологии в мире.Например, для вас, скорее всего, никогда не будет иметь значения, что ваша машина не разгоняется до 200 миль в час. Другие факторы, такие как безопасность или количество мест, могут быть более важными ежедневно.
Часто бывает выгоднее иметь более быстрый графический процессор или более быструю память, более быстрое хранилище или более быструю сеть. Но это не значит, что оно того стоит в контексте вашей основной бизнес-проблемы.
Вы можете потратить время и деньги на неправильную оптимизацию. Например, оптимизация того, насколько быстро табель складывает количество часов, не исправит того факта, что человеку требуется 20 минут, чтобы заполнить его.Можно сделать процесс намного быстрее, при этом общий результат не изменится.
Локальная или облачная средаВ конце концов, вам придется решить, размещать ли вашу инфраструктуру самостоятельно («локально» или «локально») или искать существующие варианты в облако (сервис вроде AWS или Azure).
При традиционной разработке программного обеспечения облако обычно является разумным выбором. Большинству компаний не имеет смысла размещать собственные центры обработки данных или покупать серверы, чтобы держать их в офисе.AWS претендует на клиентов от НАСА до Netflix.
Однако машинное обучение изменило этот расчет. Хотя вышеупомянутые готовые варианты, скорее всего, будут предоставляться через облако, другие типы машинного обучения могут иметь смысл локально. Вы захотите посмотреть на общую стоимость владения, сравнив ежемесячную стоимость облачного провайдера с вашими внутренними ИТ-затратами, мощностью, пространством и т. Д. Хотя эта структура может в конечном итоге указать, что всем лучше пользоваться облаком, это не случай сегодня.Осенью 2018 года предприниматель в области искусственного интеллекта Джефф Чен написал, что «создание собственного компьютера для глубокого обучения в 10 раз дешевле, чем AWS».
Разумеется, все дело в том, чтобы решить, что лучше всего для вашего бизнеса, в сотрудничестве с вашей технической командой. Если вы тренируетесь только раз в год, облако может быть лучшим вариантом, чем самостоятельное обслуживание оборудования. Вы можете воспользоваться снижением цен по мере того, как они происходят. Если Amazon снизит цены, а вы уже пользуетесь Amazon, вы получите более низкие цены.
В облаке нет затрат на обслуживание или безопасность, а также нет обновлений оборудования — вы автоматически пользуетесь преимуществами новейших машин, и вам не нужно продавать графические процессоры, если проект завершится.
Плюс такие организации, как AWS и Azure, заработали репутацию «разумных» вариантов, которые, возможно, будет легче одобрить руководству. Кроме того, было бы неплохо иметь стороннюю организацию, на которую можно было бы указать, если что-то не работает. Фактически, когда вышеупомянутая статья Чена о затратах на AWS была размещена на сайте Hacker News Y Combinator, главный комментарий гласил: «Вы забываете о стоимости борьбы с ИТ в бюрократической корпорации, чтобы заставить их позволить вам покупать / запустить нестандартное оборудование.С другой стороны, в некоторых случаях конфиденциальность данных может подтолкнуть проекты к локальному развертыванию, даже если поставщики облачных услуг обеспечивают безопасность.
В этом посте мы затронули много вопросов: методы машинного обучения, переоснащение и проблемы с инфраструктурой. Возможно, вы также начали понимать некоторые сложности, с которыми сталкиваются специалисты по обработке данных и инженеры при создании систем, использующих машинное обучение, особенно в организациях, которые никогда этого раньше не делали. Наука о данных — это не волшебство, и теперь, когда вы увидели это за кулисами, вы лучше подготовлены, чтобы помочь применить это на практике.
Введение в машинное обучение
Термин машинное обучение был придуман Артуром Сэмюэлем в 1959 году, американским пионером в области компьютерных игр и искусственного интеллекта, и заявил, что «он дает компьютерам возможность учиться без явного программирования».
И в 1997 году Том Митчелл дал «корректное» математическое и реляционное определение, что «компьютерная программа, как говорят, учится на опыте E в отношении некоторой задачи T и некоторого показателя производительности P, если ее производительность на T, как измерено на P, улучшается с опытом E.
Машинное обучение — это последнее модное словечко. Это заслуживает того, поскольку это одна из самых интересных областей компьютерных наук. Так что же на самом деле означает машинное обучение?
Давайте попробуем разобраться в машинном обучении с точки зрения непрофессионала. Представьте, что вы пытаетесь выбросить газету в мусорное ведро.
После первой попытки вы понимаете, что приложили слишком много усилий. После второй попытки вы понимаете, что находитесь ближе к цели, но вам нужно увеличить угол броска.То, что здесь происходит, заключается в том, что в основном после каждого броска мы чему-то учимся и улучшаем конечный результат. Мы запрограммированы учиться на собственном опыте.
Это означает, что задачи, связанные с машинным обучением, предлагают принципиально рабочее определение, а не определение области в когнитивных терминах. Это следует за предложением Алана Тьюринга в его статье «Вычислительные машины и интеллект», в которой был задан вопрос «Могут ли машины думать?» заменяется вопросом «Могут ли машины делать то, что можем делать мы (как мыслящие сущности)?»
В области анализа данных машинное обучение используется для разработки сложных моделей и алгоритмов, которые поддаются прогнозированию; при коммерческом использовании это называется предиктивной аналитикой.Эти аналитические модели позволяют исследователям, специалистам по обработке данных, инженерам и аналитикам «принимать надежные, повторяемые решения и результаты» и выявлять «скрытые идеи» путем изучения исторических взаимосвязей и тенденций в наборе данных (входных данных).
Предположим, вы решили проверить это предложение на отдых. Вы просматриваете сайт туристического агентства и ищете отель. Когда вы смотрите на конкретный отель, сразу под его описанием есть раздел под названием «Вам также могут понравиться эти отели».Это распространенный вариант использования машинного обучения, называемый «механизм рекомендаций». Опять же, многие точки данных использовались для обучения модели, чтобы предсказать, какие отели будут лучше всего показывать вам в этом разделе, на основе большого количества информации, которую они уже знают о вас.
Итак, если вы хотите, чтобы ваша программа предсказывала, например, модели трафика на оживленном перекрестке (задача T), вы можете запустить ее через алгоритм машинного обучения с данными о прошлых моделях трафика (опыт E) и, если он успешно «Научился», тогда он будет лучше предсказывать будущие модели трафика (показатель эффективности P).
Очень сложная природа многих реальных проблем, однако, часто означает, что изобретение специализированных алгоритмов, которые будут идеально их решать каждый раз, непрактично, если не невозможно. Примеры проблем с машинным обучением: «Это рак?», «Кто из этих людей дружит друг с другом?», «Понравится ли этому человеку этот фильм?» такие задачи — отличные цели для машинного обучения, и на самом деле машинное обучение применяло такие задачи с большим успехом.
Классификация машинного обучения
Реализации машинного обучения подразделяются на три основные категории, в зависимости от характера обучающего «сигнала» или «ответа», доступного для обучающей системы, а именно: —
- под контролем Learning: Когда алгоритм учится на примере данных и связанных целевых ответов, которые могут состоять из числовых значений или строковых меток, таких как классы или теги, чтобы впоследствии предсказать правильный ответ при постановке с новыми примерами, попадает в категорию контролируемого обучения. .Этот подход действительно похож на человеческое обучение под наблюдением учителя. Учитель дает ученику хорошие примеры для запоминания, а затем ученик выводит общие правила из этих конкретных примеров.
- Обучение без учителя: В то время как, когда алгоритм учится на простых примерах без какого-либо связанного ответа, оставляя алгоритму определять шаблоны данных самостоятельно. Этот тип алгоритма имеет тенденцию реструктурировать данные во что-то другое, например, новые функции, которые могут представлять класс или новую серию некоррелированных значений.Они весьма полезны, поскольку дают людям понимание значения данных и новые полезные входные данные для контролируемых алгоритмов машинного обучения.
Как вид обучения, он напоминает методы, которые люди используют для определения того, что определенные объекты или события принадлежат к одному классу, например, путем наблюдения за степенью сходства между объектами. Некоторые системы рекомендаций, которые вы найдете в Интернете в форме автоматизации маркетинга, основаны на этом типе обучения. - Обучение с подкреплением: Когда вы представляете алгоритм с примерами без меток, как при обучении без учителя.Тем не менее, вы можете сопровождать пример положительной или отрицательной обратной связью в соответствии с решением, предлагаемым алгоритмом, которое относится к категории обучения с подкреплением, которое связано с приложениями, для которых алгоритм должен принимать решения (так что продукт является предписывающим, а не просто описательным, как при обучении без учителя), и решения влекут за собой последствия. В человеческом мире это похоже на обучение методом проб и ошибок.
Ошибки помогают вам учиться, потому что к ним добавляется штраф (стоимость, потеря времени, сожаление, боль и т. Д.), Показывая вам, что определенный образ действий с меньшей вероятностью приведет к успеху, чем другие.Интересный пример обучения с подкреплением возникает, когда компьютеры сами учатся играть в видеоигры.
В этом случае приложение представляет алгоритм с примерами конкретных ситуаций, например, когда игрок застревает в лабиринте, избегая врага. Приложение позволяет алгоритму знать результат предпринимаемых им действий, и обучение происходит при попытке избежать того, что он считает опасным, и стремиться к выживанию. Вы можете посмотреть, как компания Google DeepMind создала программу обучения с подкреплением, которая воспроизводит старые видеоигры Atari.При просмотре видео обратите внимание на то, что программа изначально неуклюжая и неквалифицированная, но постепенно улучшается с тренировками, пока не станет чемпионом. - Полу-контролируемое обучение: , где дается неполный обучающий сигнал: обучающий набор с отсутствующими некоторыми (часто многими) целевыми выходными данными. Существует особый случай этого принципа, известный как преобразование, когда весь набор проблемных примеров известен во время обучения, за исключением того, что часть целей отсутствует.
- больше классов, и учащийся должен создать модель, которая назначает невидимые входные данные одному или нескольким (классификация с несколькими метками) этих классов.Обычно это решается под наблюдением. Фильтрация спама является примером классификации, где входными данными являются сообщения электронной почты (или другие), а классы — «спам» и «не спам».
- Регрессия: Что также является контролируемой проблемой. Случай, когда выходы являются непрерывными, а не дискретными.
- Кластеризация: Когда набор входов должен быть разделен на группы. В отличие от классификации, группы не известны заранее, что обычно делает эту задачу неконтролируемой.
Машинное обучение появляется тогда, когда проблемы не могут быть решены с помощью типичных подходов.
Автор статьи: Siddharth Pandey . Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на [email protected]. Посмотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, напишите комментарий, если вы обнаружите что-то неправильное, или если вы хотите поделиться дополнительной информацией по теме, обсуждаемой выше.
Введение в машинное обучение
Термин машинное обучение впервые был придуман в 1950-х годах, когда пионер искусственного интеллекта Артур Сэмюэл создал первую самообучающуюся систему для игры в шашки. Он заметил, что чем больше играла система, тем лучше она работала.
Благодаря достижениям в статистике и информатике, а также улучшенным наборам данных машинное обучение действительно начало развиваться к концу 20 века.
Сегодня, понимаете вы это или нет, машинное обучение повсюду — автоматический перевод, распознавание изображений, технологии голосового поиска и многое другое.
В этом руководстве мы объясним, как работает машинное обучение и как вы можете использовать его в своем бизнесе. Мы также познакомим вас с инструментами машинного обучения и покажем, как начать работу с машинным обучением без кода.
Прочтите, перейдите к разделу или добавьте этот пост в закладки для дальнейшего использования:
- Что такое машинное обучение?
- Алгоритмы машинного обучения
- Приложения машинного обучения
- Библиотеки машинного обучения на Python
- Программное обеспечение машинного обучения
Что такое машинное обучение?
Машинное обучение (ML) — это ветвь искусственного интеллекта (AI), которая позволяет компьютерам самообучаться и совершенствоваться с течением времени без явного программирования.Короче говоря, алгоритмы машинного обучения способны обнаруживать закономерности в данных, извлекать уроки из них и делать собственные прогнозы.
В традиционном программировании кто-то пишет серию инструкций, чтобы компьютер мог преобразовать входные данные в желаемый результат. Инструкции в основном основаны на структуре IF-THEN: при выполнении определенных условий программа выполняет определенное действие.
С другой стороны, машинное обучение — это автоматизированный процесс, который позволяет машинам решать проблемы и предпринимать действия на основе прошлых наблюдений.
В основном процесс машинного обучения включает в себя следующие этапы:
Подача в алгоритм машинного обучения примеров входных данных и ряд ожидаемых тегов для этих входных данных.
Входные данные преобразуются в текстовых вектора , массив чисел, которые представляют различные характеристики данных.
Алгоритмы учатся связывать векторы признаков с тегами на основе вручную помеченных образцов и автоматически делают прогнозы при обработке невидимых данных.
Хотя искусственный интеллект и машинное обучение часто используются как взаимозаменяемые, это две разные концепции. ИИ — это более широкая концепция: машины принимают решения, осваивают новые навыки и решают проблемы аналогично людям, тогда как машинное обучение — это подмножество ИИ, которое позволяет интеллектуальным системам автономно изучать новые вещи из данных.
Вместо программирования алгоритмов машинного обучения для выполнения задач вы можете передать им примеры помеченных данных (известных как данные обучения), которые помогут им выполнять вычисления, обрабатывать данные и автоматически определять закономерности.
Еще один способ помочь вам понять это: главный специалист по решениям Google описывает машинное обучение как причудливую этикетировочную машину. После того, как машины научат маркировать такие вещи, как яблоки и груши, показывая им образцы фруктов, в конечном итоге они начнут маркировать яблоки и груши без какой-либо помощи — помня, что мы показываем им правильные примеры!
Алгоритмы машинного обучения
Чтобы понять, как работает машинное обучение, вам нужно изучить различные типы алгоритмов машинного обучения, которые в основном представляют собой наборы правил, которые машины используют для принятия решений.Ниже вы найдете наиболее распространенные типы алгоритмов машинного обучения:
Обучение с учителем
Алгоритмы обучения с учителем делают прогнозы на основе размеченных данных обучения. Каждая обучающая выборка включает входные и желаемые выходные данные. Алгоритм контролируемого обучения анализирует эти образцы данных и делает вывод — по сути, обоснованное предположение при определении меток для невидимых данных.
Это наиболее распространенный и популярный подход к машинному обучению. Он находится под «контролем», потому что в эти модели необходимо вводить вручную размеченные образцы данных, чтобы они могли учиться на них.Например, если вы хотите автоматически обнаруживать спам, вам нужно будет передать алгоритму машинного обучения примеры писем, которые вы классифицируете как спам, и тех, которые являются важными.
Это подводит нас к следующему пункту. Существует два типа контролируемых учебных задач: классификация и регрессия .
Классификация
В задачах классификации выходным значением является категория с конечным числом вариантов. Например, с помощью этой бесплатной онлайн-модели анализа настроений вы можете классифицировать данные как положительные, отрицательные или нейтральные.
Допустим, вы хотите проанализировать разговоры о поддержке, чтобы понять эмоции вашего клиента: счастливы они или разочарованы после обращения в вашу службу поддержки? Классификатор анализа тональности может автоматически помечать ответы для вас, как в этом примере ниже:
В этом примере модель анализа настроений помечает разочаровывающее обслуживание клиентов как «Отрицательное».
Регрессия
В задачах регрессии ожидаемый результат — непрерывное число.Эта модель используется для прогнозирования таких величин, как вероятность того, что событие произойдет. Прогнозирование стоимости недвижимости в определенном районе или распространение COVID19 в конкретном регионе являются примерами проблем регрессии.
Обучение без учителя
Алгоритмы обучения без учителя раскрывают понимание и взаимосвязь в немаркированных данных. В этом случае модели получают входные данные, но желаемые результаты неизвестны, поэтому им приходится делать выводы на основе косвенных свидетельств, без каких-либо указаний или обучения.
Одним из наиболее распространенных типов обучения без учителя является кластеризация, которая состоит из группировки похожих данных. Этот метод в основном используется для исследовательского анализа и может помочь вам обнаружить скрытые закономерности или тенденции.
Например, отдел маркетинга компании электронной коммерции может использовать кластеризацию для улучшения сегментации клиентов. Учитывая набор данных о доходах и расходах, модель машинного обучения может идентифицировать группы клиентов со схожим поведением.
Сегментация позволяет маркетологам адаптировать стратегии для каждого ключевого рынка.Они могут предлагать акции и скидки для клиентов с низким доходом, которые много тратят на сайте, как способ вознаградить лояльность и улучшить удержание.
Полу-контролируемое обучение
При полу-контролируемом обучении данные обучения разделяются на две части. Небольшой объем помеченных данных и больший набор немаркированных данных.
В этом случае модель использует помеченные данные в качестве входных, чтобы делать выводы о немаркированных данных, обеспечивая более точные результаты, чем обычные модели контролируемого обучения.
Этот подход набирает популярность, особенно для задач, связанных с большими наборами данных, таких как классификация изображений. Полу-контролируемое обучение не требует большого количества помеченных данных, поэтому его можно быстрее настроить, более рентабельно, чем методы контролируемого обучения, и он идеально подходит для предприятий, которые получают огромные объемы данных.
Обучение с подкреплением
Обучение с подкреплением (RL) касается того, как программный агент (или компьютерная программа) должен действовать в ситуации, чтобы максимизировать вознаграждение.Короче говоря, усиленные модели машинного обучения пытаются определить наилучший путь, которым они должны следовать в данной ситуации. Они делают это методом проб и ошибок. Поскольку данных для обучения нет, машины учатся на своих ошибках и выбирают действия, которые приводят к лучшему решению или максимальной награде.
Этот метод машинного обучения в основном используется в робототехнике и играх. Видеоигры демонстрируют четкую взаимосвязь между действиями и результатами и могут измерять успех, ведя счет.Следовательно, это отличный способ улучшить алгоритмы обучения с подкреплением.
Вкратце, алгоритмы контролируемого обучения учатся делать прогнозы на основе набора помеченных примеров (каждый ввод имеет правильный вывод). С другой стороны, модели обучения без учителя и обучения с подкреплением не учатся на размеченных данных. Разница между этими двумя моделями обучения заключается в том, что одна прогнозирует результаты на основе шаблонов (без учителя), а другая использует метод проб и ошибок (подкрепление).
Распространенные модели машинного обучения
Существует множество моделей машинного обучения на выбор, каждая со своим набором правил, в зависимости от того, как вы хотите делать выводы.
Машины опорных векторов (SVM)
Машины опорных векторов (SVM) — это контролируемый алгоритм машинного обучения, который в основном используется для решения задач классификации. Учитывая набор помеченных обучающих данных, модель SVM отображает примеры на плоскости как точки данных, принадлежащие к категориям x или y, и создает между ними гиперплоскость — это действует как граница принятия решения. Затем новые фрагменты данных маркируются в зависимости от того, с какой стороны гиперплоскости они приземляются.
Для SVM лучшей гиперплоскостью является та, которая обеспечивает максимальное расстояние между точками данных в обеих категориях.
Этот алгоритм отличается высокой точностью и особенно эффективен при работе с небольшими наборами данных. При работе с большими наборами данных для обработки результатов может потребоваться время.
Наивный байесовский алгоритм
Одним из самых популярных и простых вероятностных алгоритмов является наивный байесовский алгоритм. Это контролируемый алгоритм, основанный на теореме Байеса с «наивным» предположением, что два случайных события являются условно независимыми при наличии третьей зависимой переменной. Используемый в качестве эталонного теста для задач классификации, он вычисляет вероятность каждого тега или переменной для заданных входных данных и выбирает тег с максимальной вероятностью.
Наивный байесовский классификатор широко используется для таких задач, как анализ тональности, обнаружение спама и построение систем рекомендаций.
Глубокое обучение (DL)
Модели глубокого обучения могут быть управляемыми, частично контролируемыми или неконтролируемыми. Это передовые алгоритмы машинного обучения, и в настоящее время это горячая тема для обсуждения в сфере интеллектуального анализа данных. Технологические гиганты, такие как Google, Microsoft и Amazon, уже наращивают свои исследования в области алгоритмов DL, поэтому ясно, что глубокое обучение никуда не денется — по крайней мере, до тех пор, пока оно не превратится во что-то еще более продвинутое!
Он основан на искусственных нейронных сетях (ИНС), типе компьютерной системы, которая пытается имитировать работу человеческого мозга.Алгоритмы глубокого обучения или нейронные сети построены на нескольких уровнях взаимосвязанных нейронов.
Когда модель получает входные данные — которые могут быть изображением, текстом или звуком — и ее просят выполнить задачу (например, классификацию текста с машинным обучением), данные проходят через каждый уровень, позволяя модели постепенно обучаться. Это как человеческий мозг, который развивается с возрастом и опытом!
Этот подход все чаще используется для распознавания изображений, речи и обработки естественного языка.Модели глубокого обучения обычно работают лучше, чем другие алгоритмы машинного обучения, для сложных проблем и массивных наборов данных. Однако они требуют большого количества обучающих данных.
Приложения машинного обучения
Машинное обучение в финансах, здравоохранении, гостиничном бизнесе, правительстве и других сферах постепенно становится массовым. Компании начинают видеть преимущества использования инструментов машинного обучения для улучшения своих процессов, получения ценной информации из неструктурированных данных и автоматизации задач, которые в противном случае потребовали бы многочасовой ручной работы.
Многие приложения, инструменты и службы, которые мы используем сегодня, не смогли бы работать без машинного обучения. Например, UberEats использует машинное обучение для оценки оптимального времени, в течение которого водители могут забрать заказы на еду, а Spotify использует машинное обучение, чтобы предлагать персонализированный контент.
Как вы думаете, Netflix создает персонализированные рекомендации по фильмам, а Google Maps прогнозирует пики трафика в определенное время дня? Конечно, с помощью машинного обучения.
Существует множество различных приложений машинного обучения, которые могут принести пользу вашему бизнесу во многих отношениях.Вам просто нужно определить стратегию, которая поможет вам решить, как лучше всего внедрить машинное обучение в свои процессы. А пока вот несколько распространенных приложений машинного обучения, которые могут вызвать некоторые идеи:
- Мониторинг социальных сетей
- Распознавание изображений
- Виртуальные помощники
- Обнаружение мошенничества в Интернете
- Рекомендации по продуктам
- Торговля на фондовом рынке
- Медицинское Диагностика
- Обнаружение фейковых новостей
Мониторинг социальных сетей
С помощью машинного обучения вы можете отслеживать упоминания вашего бренда в социальных сетях и быстро определять, требуют ли клиенты срочного внимания.Обнаруживая упоминания разгневанных клиентов в режиме реального времени, вы можете автоматически отмечать отзывы клиентов и немедленно отвечать. Вы также можете проанализировать взаимодействие со службой поддержки в социальных сетях и оценить удовлетворенность клиентов, чтобы увидеть, насколько хорошо работает ваша команда.
Распознавание изображений
Распознавание изображений помогает компаниям идентифицировать и классифицировать изображения. Например, технология распознавания лиц используется как форма идентификации, от разблокировки телефонов до совершения платежей.Беспилотные автомобили также используют распознавание изображений для распознавания пространства и препятствий. Например, они могут научиться распознавать знаки остановки, определять перекрестки и принимать решения на основе того, что видят.
Виртуальные помощники
Виртуальные помощники, такие как Siri, Alexa, Google Now, используют машинное обучение для автоматической обработки и ответа на голосовые запросы. Они полагаются на анализ текста с машинным обучением, чтобы быстро сканировать информацию, запоминать связанные запросы, извлекать уроки из предыдущих взаимодействий и отправлять команды другим приложениям, чтобы они могли собирать информацию и предоставлять наиболее эффективный ответ.
Группы поддержки клиентов уже используют виртуальных помощников для обработки телефонных звонков, автоматической маршрутизации заявок на поддержку в нужные группы и ускорения взаимодействия с клиентами с помощью ответов, сгенерированных компьютером.
Обнаружение мошенничества в Интернете
Методы машинного обучения, такие как обнаружение аномалий, используются для обнаружения мошенничества (а также обнаружения вторжений в системе кибербезопасности), а также могут использоваться для обнаружения погодных аномалий.
Глобальный банк Citi Group, например, внедрила решение машинного обучения для обнаружения выпадающих платежей по кредитным картам.Решение анализирует схемы платежей пользователей, проактивно выявляет «выбросы», такие как платежи в другие регионы, и просит клиентов подтвердить или отклонить эти платежи.
Рекомендации по продукту
Обучение правилам ассоциации — это метод машинного обучения, который можно использовать для анализа покупательских привычек в супермаркете или на сайтах электронной коммерции. Он работает, ища взаимосвязи между переменными и находя общие ассоциации в транзакциях (продукты, которые потребители обычно покупают вместе).Эти данные затем используются для стратегий размещения продукта и аналогичных продуктовых рекомендаций.
Связанные правила также могут быть полезны для планирования маркетинговой кампании или анализа использования Интернета.
Торговля на фондовом рынке
Алгоритмы машинного обучения можно обучить для определения торговых возможностей путем распознавания закономерностей и поведения в исторических данных. Когда дело доходит до инвестиций, людьми часто движут эмоции, поэтому анализ настроений с помощью машинного обучения может сыграть огромную роль в выявлении хороших и плохих инвестиционных возможностей без каких-либо предубеждений.
Медицинский диагноз
Способность машин находить закономерности в сложных данных определяет настоящее и будущее. Возьмите, например, инициативы по машинному обучению во время вспышки COVID-19. Инструменты искусственного интеллекта помогли предсказать, как вирус будет распространяться с течением времени, и сформировали способы борьбы с ним. Он также помогает диагностировать пациентов, анализируя КТ легких и обнаруживая лихорадку с помощью распознавания лиц, и выявляет пациентов с повышенным риском развития серьезных респираторных заболеваний.
Обнаружение поддельных новостей
Недавние исследования показывают, что алгоритмы машинного обучения могут помочь обнаружить поддельные новости и снизить риски использования ложной информации.
Как? Учитывая набор новостных статей, алгоритм идентифицирует различные группы новостей с похожим контентом, называемые тематическими кластерами. Когда новость не может быть идентифицирована как часть какой-либо существующей тематической группы, она рассматривается как потенциально фальшивая новость.
Машинное обучение стимулирует инновации во многих областях, и каждый день мы видим, как появляются интересные варианты использования. В бизнесе общие преимущества машинного обучения:
- Это рентабельность и масштабируемость. Вам нужно обучить модель только один раз, и вы можете увеличивать или уменьшать масштаб в зависимости от низкого или высокого сезона.
- Точность. Модели машинного обучения обучаются с определенным объемом помеченных данных и будут использовать их для прогнозирования невидимых данных. На основе этих данных машины определяют набор правил, которые они применяют ко всем наборам данных, помогая им обеспечивать согласованные и точные результаты.
- Работает в режиме реального времени, 24/7. Модели машинного обучения могут автоматически анализировать данные в режиме реального времени, позволяя немедленно обнаруживать отрицательные мнения или срочные заявки и принимать меры.
Библиотеки и ресурсы Python для машинного обучения
Библиотеки машинного обучения с открытым исходным кодом предлагают коллекции готовых моделей и компонентов, которые разработчики могут использовать для создания своих собственных приложений, вместо того, чтобы писать код с нуля. Они бесплатны, гибки и могут быть настроены в соответствии с конкретными потребностями.
Еще одним преимуществом библиотек с открытым исходным кодом является то, что они регулярно обновляются участниками и имеют активное сообщество, поэтому помощь всегда под рукой.
Python — лучший язык для разработки моделей машинного обучения благодаря его гибкости, доступности и доступности. В Python также есть обширный список библиотек с открытым исходным кодом, поэтому вам никогда не будет сложно найти решение своей проблемы.
Некоторые из самых популярных библиотек с открытым исходным кодом для машинного обучения:
Scikit-learn
Популярная библиотека Python и отличный вариант для тех, кто только начинает заниматься машинным обучением.Почему? Он прост в использовании, надежен и хорошо документирован. Вы можете использовать эту библиотеку для таких задач, как классификация, кластеризация и регрессия, среди прочего.
PyTorch
Разработанная Facebook, PyTorch — это библиотека машинного обучения с открытым исходным кодом, основанная на библиотеке Torch с упором на глубокое обучение. Он используется для компьютерного зрения и обработки естественного языка и намного лучше справляется с отладкой, чем некоторые из его конкурентов. Начните с руководств по PyTorch как для начинающих, так и для опытных программистов.Известный своей гибкостью и скоростью, он идеально подходит, если вам нужно быстрое решение.
Kaggle
Запущенный более десяти лет назад (и приобретенный Google в 2017 году), Kaggle придерживается философии обучения на собственном опыте и известен своими соревнованиями, в которых участники создают модели для решения реальных задач. Ознакомьтесь с этим онлайн-курсом машинного обучения на Python, который поможет вам создать свою первую модель в кратчайшие сроки.
NLTK
The Natural Language Toolkit (NLTK), возможно, самая известная библиотека Python для работы с обработкой естественного языка.Его можно использовать для поиска по ключевым словам, токенизации и классификации, распознавания голоса и многого другого. С упором на исследования и образование, вы найдете множество ресурсов, включая наборы данных, предварительно обученные модели и учебник, которые помогут вам начать работу.
TensorFlow
Библиотека Python с открытым исходным кодом, разработанная Google для внутреннего использования, а затем выпущенная по открытой лицензии, с множеством ресурсов, руководств и инструментов, которые помогут вам отточить свои навыки машинного обучения. Эта удобная платформа, подходящая как для новичков, так и для экспертов, имеет все необходимое для создания и обучения моделей машинного обучения (включая библиотеку предварительно обученных моделей).
Tensorflow более мощный, чем другие библиотеки, и ориентирован на глубокое обучение, что делает его идеальным для сложных проектов с крупномасштабными данными. Однако для овладения им может потребоваться время и навыки. Как и в случае с большинством инструментов с открытым исходным кодом, у него есть сильное сообщество и несколько руководств, которые помогут вам начать работу.
Хотите узнать больше о машинном обучении, прежде чем погрузиться в инструменты с открытым исходным кодом? Вот несколько курсов и книг, которые помогут вам на этом пути:
Лучшие курсы машинного обучения
Онлайн-курс — отличный способ получить дополнительные знания о машинном обучении.Вот несколько вариантов, в зависимости от ваших целей и уровня:
Курс машинного обучения Эндрю Нг (Стэнфордский университет) на Coursera: самый популярный курс для начинающих, настоятельно рекомендуемый теми, кто его прошел. Этот курс под руководством бывшего исследователя Google Brain, профессора Стэнфорда и соучредителя Coursera Эндрю Нг предлагает систематический подход к машинному обучению, примеры реальных вариантов использования и практические рекомендации о том, как заставить алгоритмы работать.
Джон У.Курс машинного обучения Пейсли (Колумбийский университет) на edX: — это углубленный теоретический подход к машинному обучению с упором на математику, лежащую в основе алгоритмов, а не на практическое применение машинного обучения. Программа охватывает контролируемое и неконтролируемое обучение, вероятностные и не вероятностные методы. Этот 12-недельный курс предназначен для продвинутых учащихся, знакомых с математическим расчетом, линейной алгеброй, вероятностью, статистикой и кодированием.
Ускоренный курс машинного обучения: практическое введение в основы машинного обучения, разработанное Google.Этот курс включает видеоуроки, тематические исследования и упражнения, чтобы вы могли применить полученные знания на практике и создать свои собственные модели машинного обучения в TensorFlow. Никаких предварительных знаний в области машинного обучения не требуется, но вам необходимо иметь базовые навыки программирования и опыт работы с Python.
Лучшие книги по машинному обучению
Машинное обучение повсюду, и быстро становится незаменимым бизнес-решением. Независимо от того, работаете ли вы в розничной торговле, медицине, финансах или программном обеспечении, машинное обучение может помочь улучшить и автоматизировать внутренние процессы и расширить возможности принятия решений.
Хотя машинное обучение может быть сложным, существует множество готовых инструментов, которые позволяют легко реализовать машинное обучение прямо сейчас.
Инструменты MLaaS (машинное обучение как услуга), например, делают машинное обучение доступным для всех благодаря готовым решениям, требующим небольших экспертных знаний.
Эти инструменты машинного обучения легко подключаются к Zendesk, и вы даже можете использовать их для выполнения машинного обучения в Excel. Если у вас ограниченные ресурсы или вы не хотите вкладывать слишком много усилий и времени в разработку сложной инфраструктуры, инструменты MLaaS идеально подходят.
Узнайте разницу между созданием и покупкой собственного программного обеспечения.
Практически нет необходимости в настройке, а готовое программное обеспечение для машинного обучения позволяет создавать мощные модели машинного обучения, которые можно легко подключать к своим любимым приложениям через API или интеграции. Да, даже без предыдущего опыта машинного обучения!
Monkeylearn, например, представляет собой простую в использовании платформу, которая позволяет создавать модели машинного обучения для выполнения задач анализа текста, таких как классификация тем, анализ тональности, извлечение ключевых слов и многое другое.
Готовы сделать первые шаги с помощью простого решения MonkeyLearn без кода. Запросите демонстрацию и начните создавать ценность из ваших данных.
Введение в машинное обучение | Основы машинного обучения
Введение в машинное обучение:Несомненно, машинное обучение — самая востребованная технология на сегодняшнем рынке. Его приложения варьируются от беспилотных автомобилей до прогнозирования смертельных заболеваний, таких как БАС. Этот блог мотивирован высоким спросом на навыки машинного обучения.В этом блоге, посвященном введению в машинное обучение, вы поймете все основные концепции машинного обучения и практическую реализацию машинного обучения с использованием языка R.
Чтобы получить более глубокие знания о Data Science, вы можете записаться на онлайн-курс Data Science Certification Training от Edureka с круглосуточной поддержкой и пожизненным доступом.
В этом блоге «Введение в машинное обучение» рассматриваются следующие темы:
- Потребность в машинном обучении
- Что такое машинное обучение?
- Определения машинного обучения
- Процесс машинного обучения
- Типы машинного обучения
- Типы проблем, решаемых с помощью машинного обучения
- Практическая реализация машинного обучения
Со времен технической революции мы генерируют неизмеримое количество данных.Согласно исследованиям, мы генерируем около 2,5 квинтиллионов байтов данных каждый день! По оценкам, к 2020 году для каждого человека на Земле каждую секунду будет создаваться 1,7 МБ данных.
Благодаря наличию такого большого количества данных, наконец, стало возможным создавать прогностические модели, которые могут изучать и анализировать сложные данные, чтобы находить полезные идеи и предоставлять более точные результаты.
Компании высшего уровня, такие как Netflix и Amazon, создают такие модели машинного обучения, используя тонны данных, чтобы определить выгодные возможности и избежать нежелательных рисков.
Вот список причин, почему машинное обучение так важно:
- Увеличение объема генерации данных: Из-за чрезмерного производства данных нам нужен метод, который можно использовать для структурирования, анализа и извлечения полезной информации из данных. Здесь на помощь приходит машинное обучение. Оно использует данные для решения проблем и поиска решений самых сложных задач, с которыми сталкиваются организации.
- Улучшение принятия решений: Машинное обучение можно использовать для принятия более эффективных бизнес-решений с помощью различных алгоритмов.Например, машинное обучение используется для прогнозирования продаж, предсказания падений на фондовом рынке, выявления рисков и аномалий и т. Д.
Важность машинного обучения — Введение в машинное обучение — Edureka
- Раскрыть закономерности и тенденции в данных : поиск скрытых закономерностей и извлечение ключевых идей из данных — самая важная часть машинного обучения. Создавая прогнозные модели и используя статистические методы, машинное обучение позволяет вам копать под поверхностью и исследовать данные в минутном масштабе.На понимание данных и извлечение шаблонов вручную уйдут дни, тогда как алгоритмы машинного обучения могут выполнять такие вычисления менее чем за секунду.
- Решайте сложные проблемы: Машинное обучение можно использовать для решения самых сложных проблем — от обнаружения генов, связанных со смертельным заболеванием БАС, до создания беспилотных автомобилей.
Чтобы лучше понять, насколько важно машинное обучение, давайте перечислим несколько приложений машинного обучения:
- Механизм рекомендаций Netflix : Ядром Netflix является его печально известный механизм рекомендаций.Netflix рекомендует более 75% того, что вы смотрите, и эти рекомендации сделаны путем внедрения машинного обучения.
- Функция автоматической пометки Facebook: Логика системы проверки лиц DeepMind в Facebook — это машинное обучение и нейронные сети. DeepMind изучает черты лица на изображении, чтобы отметить ваших друзей и семью.
- Amazon Alexa: Печально известная Alexa, основанная на обработке естественного языка и машинном обучении, представляет собой виртуальный помощник продвинутого уровня, который делает больше, чем просто воспроизводит песни в вашем плейлисте.Он может забронировать вам Uber, подключиться к другим устройствам IoT дома, отслеживать ваше здоровье и т. Д.
- Фильтр спама Google: Gmail использует машинное обучение для фильтрации спам-сообщений. Он использует алгоритмы машинного обучения и обработки естественного языка для анализа электронных писем в режиме реального времени и классификации их как спам или не спам.
Это несколько примеров того, как машинное обучение реализовано в компаниях высшего уровня. Вот блог о 10 лучших приложениях машинного обучения. Прочтите его, чтобы узнать больше.
Теперь, когда вы знаете, почему машинное обучение так важно, давайте посмотрим, что такое машинное обучение.
Введение в машинное обучениеТермин «машинное обучение» впервые был введен Артуром Самуэлем в 1959 году. Оглядываясь назад, можно сказать, что этот год был, вероятно, самым значительным с точки зрения технологических достижений.
Если вы просмотрите Интернет о том, «что такое машинное обучение», вы найдете как минимум 100 различных определений. Однако самое первое формальное определение было дано Томом М.Mitchell:
«Считается, что компьютерная программа учится на опыте E в отношении некоторого класса задач T и показателя производительности P, если ее производительность при выполнении задач в T, измеренная с помощью P, улучшается с опытом E.»
Проще говоря, машинное обучение — это подмножество искусственного интеллекта (ИИ), которое дает машинам возможность учиться автоматически и совершенствоваться на основе опыта, не будучи явно запрограммированными на это. В некотором смысле, это практика заставлять Машины решать проблемы, обретая способность думать.
Но подождите, может ли машина думать или принимать решения? Что ж, если вы загрузите в машину достаточное количество данных, она научится интерпретировать, обрабатывать и анализировать эти данные с помощью алгоритмов машинного обучения для решения реальных проблем.
Прежде чем двигаться дальше, давайте обсудим некоторые из наиболее часто используемых терминов в машинном обучении.
Определения машинного обученияАлгоритм: Алгоритм машинного обучения — это набор правил и статистических методов, используемых для изучения закономерностей из данных и извлечения из них важной информации.Это логика модели машинного обучения. Примером алгоритма машинного обучения является алгоритм линейной регрессии.
Модель: Модель является основным компонентом машинного обучения. Модель обучается с использованием алгоритма машинного обучения. Алгоритм отображает все решения, которые должна принимать модель, на основе заданных входных данных, чтобы получить правильный результат.
Переменная-предиктор: Это функция (и) данных, которая может использоваться для прогнозирования выходных данных.
Переменная ответа: Это характеристика или выходная переменная, которую необходимо предсказать с помощью переменных-предикторов.
Данные обучения: Модель машинного обучения построена с использованием данных обучения. Данные обучения помогают модели определять ключевые тенденции и закономерности, необходимые для прогнозирования результатов.
Данные тестирования: После обучения модели ее необходимо протестировать, чтобы оценить, насколько точно она может предсказать результат. Это делается с помощью набора данных тестирования.
Что такое машинное обучение? — Введение в машинное обучение — Edureka
Подводя итог, взгляните на рисунок выше. Процесс машинного обучения начинается с подачи в машину большого количества данных, с помощью которых машина обучается обнаруживать скрытые идеи и тенденции. Эти идеи затем используются для построения модели машинного обучения с использованием алгоритма для решения проблемы.
Следующая тема в этом блоге «Введение в машинное обучение» — это процесс машинного обучения.
Процесс машинного обученияПроцесс машинного обучения включает построение прогнозной модели, которую можно использовать для поиска решения для постановки проблемы. Чтобы понять процесс машинного обучения, предположим, что вам поставили задачу, которую необходимо решить с помощью машинного обучения.
Процесс машинного обучения — Введение в машинное обучение — Edureka
Проблема состоит в том, чтобы предсказать появление дождя в вашем районе с помощью машинного обучения.
Следующие ниже шаги выполняются в процессе машинного обучения:
Шаг 1: Определите цель Постановления проблемы
На этом шаге мы должны понять, что именно нужно предсказать. В нашем случае цель состоит в том, чтобы предсказать возможность дождя путем изучения погодных условий. На этом этапе также важно сделать мысленные заметки о том, какие данные можно использовать для решения этой проблемы или какой подход вы должны использовать, чтобы найти решение.
Шаг 2: Сбор данных
На этом этапе вы должны задавать такие вопросы, как:
- Какие данные необходимы для решения этой проблемы?
- Доступны ли данные?
- Как я могу получить данные?
После того, как вы узнаете типы данных, которые требуются, вы должны понять, как вы можете получить эти данные. Сбор данных может производиться вручную или с помощью веб-скрейпинга. Однако, если вы новичок и просто хотите изучить машинное обучение, вам не нужно беспокоиться о получении данных.В Интернете есть тысячи ресурсов данных, вы можете просто загрузить набор данных и приступить к работе.
Возвращаясь к рассматриваемой проблеме, данные, необходимые для прогнозирования погоды, включают такие показатели, как уровень влажности, температура, давление, местность, независимо от того, живете ли вы на горной станции и т. Д. Такие данные должны быть собраны и сохранены для анализа .
Шаг 3 : Подготовка данных
Собранные вами данные почти никогда не имеют правильного формата. Вы столкнетесь с множеством несоответствий в наборе данных, таких как отсутствующие значения, избыточные переменные, повторяющиеся значения и т. Д.Устранение таких несоответствий очень важно, поскольку они могут привести к ошибочным вычислениям и прогнозам. Поэтому на этом этапе вы просматриваете набор данных на предмет любых несоответствий и исправляете их тут же.
Шаг 4: Исследовательский анализ данных
Хватайте свои детективные очки, потому что этот этап посвящен глубокому погружению в данные и поиску всех скрытых тайн данных. EDA или исследовательский анализ данных — это этап мозгового штурма машинного обучения. Исследование данных предполагает понимание закономерностей и тенденций в данных.На этом этапе делается вся полезная информация и выясняются корреляции между переменными.
Например, в случае прогнозирования дождя мы знаем, что существует большая вероятность дождя, если температура упала. Такие корреляции необходимо понять и нанести на карту на данном этапе.
Шаг 5: Построение модели машинного обучения
Все идеи и шаблоны, полученные в ходе исследования данных, используются для построения модели машинного обучения.Этот этап всегда начинается с разделения набора данных на две части: данные обучения и данные тестирования. Данные обучения будут использоваться для построения и анализа модели. Логика модели основана на реализуемом алгоритме машинного обучения.
В случае прогнозирования дождя, поскольку результат будет в форме Истина (если завтра будет дождь) или Ложь (завтра дождя не будет), мы можем использовать алгоритм классификации, такой как логистическая регрессия.
Выбор правильного алгоритма зависит от типа проблемы, которую вы пытаетесь решить, набора данных и уровня сложности проблемы.В следующих разделах мы обсудим различные типы проблем, которые можно решить с помощью машинного обучения.
Шаг 6: Оценка и оптимизация модели
После построения модели с использованием обучающего набора данных, наконец, пришло время протестировать модель. Набор данных тестирования используется для проверки эффективности модели и того, насколько точно она может предсказать результат. После расчета точности любые дальнейшие улучшения модели могут быть реализованы на этом этапе.Такие методы, как настройка параметров и перекрестная проверка, могут использоваться для повышения производительности модели.
Шаг 7: Прогнозы
После того, как модель оценена и улучшена, она, наконец, используется для прогнозирования. Конечный результат может быть категориальной переменной (например, True или False) или непрерывным количеством (например, прогнозируемой стоимостью акции).
В нашем случае для прогнозирования выпадения дождя на выходе будет категориальная переменная.
Итак, это был весь процесс машинного обучения.Пришло время узнать о различных способах обучения машин.
Типы машинного обученияМашина может научиться решать проблему, следуя любому из следующих трех подходов. Вот способы, которыми машина может обучаться:
- Обучение с учителем
- Обучение без учителя
- Обучение с подкреплением
Обучение с учителем — это метод, с помощью которого мы обучаем или обучаем машину с использованием данных, которые хорошо обозначен.
Чтобы понять контролируемое обучение, давайте рассмотрим аналогию. В детстве всем нам требовалось руководство для решения математических задач. Наши учителя помогли нам понять, что такое сложение и как оно делается. Точно так же вы можете думать о контролируемом обучении как о типе машинного обучения, которое включает в себя руководство. Помеченный набор данных — это учитель, который научит вас понимать закономерности в данных. Помеченный набор данных — это не что иное, как набор обучающих данных.
Обучение с учителем — Введение в машинное обучение — Edureka
Обратите внимание на приведенный выше рисунок.Здесь мы загружаем машинные изображения Тома и Джерри, и цель состоит в том, чтобы машина идентифицировала и классифицировала изображения на две группы (изображения Тома и изображения Джерри). Набор обучающих данных, который передается в модель, помечен, как мы говорим машине: «Вот как выглядит Том, а это Джерри». Таким образом вы тренируете машину, используя размеченные данные. В контролируемом обучении есть четко определенная фаза обучения, выполняемая с помощью помеченных данных.
Обучение без учителяОбучение без учителя включает обучение с использованием немаркированных данных и позволяет модели действовать на основе этой информации без руководства.
Думайте об обучении без учителя как о умном ребенке, который учится без какого-либо руководства. В этом типе машинного обучения модель не снабжается помеченными данными, поскольку в модели нет подсказки, что « это изображение — Том, а это Джерри », она самостоятельно определяет закономерности и различия между Томом и Джерри. принимая тонны данных.
Неконтролируемое обучение — Введение в машинное обучение — Edureka
Например, он определяет характерные черты Тома, такие как заостренные уши, больший размер и т. Д., Чтобы понять, что это изображение относится к типу 1.Точно так же он находит такие особенности у Джерри и знает, что это изображение типа 2. Поэтому он классифицирует изображения на два разных класса, не зная, кто такие Том или Джерри.
Обучение с подкреплениемОбучение с подкреплением — это часть машинного обучения, когда агент помещается в среду, и он учится вести себя в этой среде, выполняя определенные действия и наблюдая за вознаграждением, которое он получает от этих действий.
Этот тип машинного обучения сравнительно отличается.Представьте, что вас высадили на изолированном острове! Чтобы ты делал?
Паника? Да, конечно, поначалу все были бы. Но со временем вы научитесь жить на острове. Вы исследуете окружающую среду, поймете климатические условия, тип пищи, которая там растет, опасности острова и т. Д. Именно так работает обучение с подкреплением, оно включает агента (вы, застрявшего на острове), который в неизвестной среде (острове), где он должен учиться, наблюдая и выполняя действия, которые приводят к наградам.
Обучение с подкреплением в основном используется в продвинутых областях машинного обучения, таких как беспилотные автомобили, AplhaGo и т. Д.
Чтобы лучше понять разницу между контролируемым, неконтролируемым и обучением с подкреплением, вы можете просмотреть это короткое видео.
Контролируемое против неконтролируемого против обучения с подкреплением | Тренинг по сертификации в области науки о данных | EdurekaВ этом видео, посвященном обучению с учителем, неконтролируемому и обучению с подкреплением, мы будем обсуждать типы машинного обучения и различать их по нескольким ключевым параметрам.
Итак, мы суммируем типы машинного обучения. Теперь давайте посмотрим, какие проблемы решаются с помощью машинного обучения.
Типы проблем в машинном обученииТипы проблем, решаемых с помощью машинного обучения — Введение в машинное обучение — Edureka
Рассмотрим приведенный выше рисунок, есть три основных типа проблем, которые могут быть решены в машине. Обучение:
- Регрессия: В задачах этого типа выход является непрерывной величиной.Так, например, если вы хотите предсказать скорость автомобиля с учетом расстояния, это проблема регрессии. Проблемы регрессии можно решить с помощью алгоритмов контролируемого обучения, таких как линейная регрессия.
- Классификация: Выходные данные этого типа являются категориальными значениями. Классификация электронных писем на два класса: спам и не спам — это проблема классификации, которую можно решить с помощью алгоритмов классификации с контролируемым обучением, таких как Support Vector Machines, Naive Bayes, Logistic Regression, K Nearest Neighbor и т. Д.
- Кластеризация: Этот тип проблемы включает распределение входных данных в два или более кластеров на основе сходства функций. Например, объединение зрителей в похожие группы на основе их интересов, возраста, географии и т. Д. Может быть выполнено с помощью алгоритмов неконтролируемого обучения, таких как кластеризация K-средних.
Вот таблица, в которой суммируются различия между регрессией, классификацией и кластеризацией.
Регрессия против классификации против кластеризации — Введение в машинное обучение — Edureka
Теперь, чтобы сделать вещи интересными, я оставлю несколько формулировок проблемы ниже, а ваша домашняя работа — угадать тип проблемы (регрессия, классификация или Кластеризация) это:
- Постановка проблемы 1: Изучите набор данных о банковских кредитах и примите решение о том, одобрять ли ссуду заявителю, исходя из его социально-экономического профиля.
- Постановка задачи 2: Изучить набор данных «Продажи дома» и построить модель машинного обучения, которая прогнозирует индекс цен на жилье.
- Постановка проблемы 3: Сгруппировать набор фильмов как хорошие или средние на основе их охвата в социальных сетях.
Не забудьте оставить свой ответ в разделе комментариев.
Теперь, когда у вас есть хорошее представление о том, что такое машинное обучение и какие процессы в нем задействованы, давайте запустим демонстрацию, которая поможет вам понять, как на самом деле работает машинное обучение.
Машинное обучение в RКороткий отказ от ответственности: я буду использовать язык R, чтобы показать, как работает машинное обучение. R — это язык статистического программирования, который в основном используется для обработки данных и машинного обучения. Чтобы узнать больше о R, вы можете посетить следующие блоги:
- R Tutorial — A Beginner’s Guide to Learn R Programming
- R Programming — Beginners Guide to R Programming Language
- Top 50 R Interview Questions you must prepare in 2019
- Полное руководство по R для науки о данных
Теперь приступим.
Постановка проблемы: Для изучения набора данных прогноза погоды в Сиэтле и построения модели машинного обучения, которая может предсказать вероятность дождя.
Описание набора данных: Набор данных был собран путем исследования и наблюдения за погодными условиями в международном аэропорту Сиэтл-Такома. Набор данных содержит следующие переменные:
- DATE = дата наблюдения
- PRCP = количество осадков в дюймах
- TMAX = максимальная температура для этого дня в градусах Фаренгейта
- TMIN = минимальная температура для этого дня, в градусов по Фаренгейту
- RAIN = TRUE, если в этот день наблюдался дождь, FALSE, если он не был
Целевая переменная или ответная переменная в данном случае — RAIN.Если вы заметили, эта переменная является категориальной по своей природе, то есть ее значение бывает двух категорий: True или False. Следовательно, это проблема классификации, и мы будем использовать алгоритм классификации, называемый логистической регрессией.
Несмотря на то, что название предполагает, что это алгоритм «регрессии», на самом деле это не так. Он принадлежит к семейству GLM (обобщенная линейная модель) и, следовательно, называется логистической регрессией.
Следуйте этому всестороннему руководству по логистической регрессии в блоге R, чтобы узнать больше о логистической регрессии.
Логика: Для построения модели логистической регрессии, чтобы предсказать, будет ли дождь в конкретный день на основе погодных условий.
Теперь, когда вы знаете цель этой демонстрации, давайте заставим наш мозг работать и приступим к программированию.
Шаг 1. Установка и загрузка библиотек
R предоставляет тысячи пакетов для запуска алгоритмов машинного обучения и математических моделей. Итак, первый шаг — установить и загрузить все соответствующие библиотеки.
# Загрузить необходимые библиотеки
библиотека (тидиверс)
библиотека (загрузка)
install.packages ('прогноз')
библиотека (прогноз)
библиотека (серия)
install.packages ('каретка')
библиотека (каретка)
install.packages ('ROCR')
библиотека (ROCR)
Каждая из этих библиотек служит определенной цели, вы можете узнать больше о библиотеках в официальной документации R.
Шаг 2. Импортируйте набор данных
К счастью, я нашел набор данных в Интернете, и мне не нужно собирать его вручную.В приведенном ниже фрагменте кода я загрузил набор данных в переменную с именем ‘data.df’ с помощью функции ‘read.csv ()’, предоставленной R. Эта функция предназначена для загрузки файла версии, разделенной запятыми (CSV). .
# Импорт набора данных
data.df <- read.csv ("/ Users / Zulaikha_Geer / Desktop / Data / seattleWeather_1948-2017.csv", header = TRUE)
Шаг 3. Изучение набора данных
Давайте взглянем на пару наблюдений в наборе данных. Для этого мы можем использовать функцию head (), предоставляемую R.Это перечислит первые 6 наблюдений в наборе данных.
> голова (data.df) ДАТА & nbsp; & nbsp; & nbsp; PRCP & nbsp; & nbsp; TMAX & nbsp; & nbsp; TMIN & nbsp; ДОЖДЬ 1 1 января 1948 & nbsp; & nbsp; 0,47 & nbsp; & nbsp; & nbsp; & nbsp; 51 & nbsp; & nbsp; & nbsp; 42 & nbsp; & nbsp; ПРАВДА 2 1948-01-02 & nbsp; & nbsp; 0,59 & nbsp; & nbsp; & nbsp; 45 & nbsp; & nbsp; & nbsp; 36 & nbsp; & nbsp; ПРАВДА 3 1948-01-03 & nbsp; & nbsp; 0.42 & nbsp; & nbsp; & nbsp; 45 & nbsp; & nbsp; & nbsp; 35 & nbsp; & nbsp; ПРАВДА 4 1948-01-04 & nbsp; & nbsp; 0,31 & nbsp; & nbsp; & nbsp; 45 & nbsp; & nbsp; & nbsp; 34 & nbsp; & nbsp; & nbsp; ИСТИНА 5 1948-01-05 & nbsp; & nbsp; 0,17 & nbsp; & nbsp; & nbsp; 45 & nbsp; & nbsp; & nbsp; 32 & nbsp; & nbsp; & nbsp; ИСТИНА 6 1948-01-06 & nbsp; & nbsp; 0,44 & nbsp; & nbsp; & nbsp; 48 & nbsp; & nbsp; & nbsp; 39 & nbsp; & nbsp; & nbsp; ИСТИНА
Теперь давайте посмотрим на структуру набора данных с помощью функции str ().
# Изучение структуры набора данных > str (data.df) 'data.frame': 25551 набл. из 5 переменных: $ DATE: Фактор с 25551 уровнями "1948-01-01", "1948-01-02", ..: 1 2 3 4 5 6 7 8 9 10 ... $ PRCP: число 0,47 0,59 0,42 0,31 0,17 0,44 0,41 0,04 0,12 0,74 ... $ TMAX: внутренний 51 45 45 45 45 48 50 48 50 43 ... $ TMIN: int 42 36 35 34 32 39 40 35 31 34 ... $ RAIN: logi ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ...
В приведенном выше коде вы можете видеть, что тип данных для переменных «DATE» и «RAIN» отформатирован неправильно.Переменная «DATE» должна иметь тип Date, а переменная «RAIN» должна быть фактором.
Шаг 4. Очистка данных
Приведенный ниже фрагмент кода при форматировании переменных «ДАТА» и «ДОЖДЬ»:
# Форматирование переменных date и rain data.df $ DATE <- as.Date (data.df $ DATE) data.df $ RAIN <- as.factor (data.df $ RAIN)
Как я уже упоминал ранее, важно проверить наличие каких-либо отсутствующих значений или значений NA в наборе данных, приведенный ниже фрагмент кода проверяет значения NA в каждой переменной:
# Проверка значений NA в переменной "DATE" > который (есть.na (data.df $ DATE)) целое число (0) # Проверка значений NA в переменной 'TMAX' > который (is.na (data.df $ TMAX)) целое число (0) # Проверка значений NA в переменной TMIN > который (is.na (data.df $ TMIN)) целое число (0) # Проверка значений NA в переменной 'PRCP' > который (is.na (data.df $ PRCP)) [1] 18416 18417 21068 # Проверка значений NA в переменной 'rain' > который (is.na (data.df $ RAIN)) [1] 18416 18417 21068
Если вы заметили приведенный выше фрагмент кода, вы увидите, что переменные TMAX, TMIN и DATE не имеют значений NA, тогда как переменные «PRCP» и «RAIN» имеют 3 пропущенных значения, эти значения необходимо удалить.
# Удаляем строки с отсутствующим значением RAIN > data.df <- data.df [-c (18416, 18417, 21068),]
Значения успешно удалены!
Шаг 5: Объединение данных
Объединение данных - еще один причудливый термин для разделения набора данных на набор для обучения и тестирования. Набор данных для обучения должен быть больше, поскольку для обучения модели и помощи в изучении тенденций требуется гораздо больше данных. В приведенном ниже фрагменте кода набор данных разбивается на наборы для обучения и тестирования в соотношении 7: 3.Это означает, что 70% данных используется для обучения, а 30% - для тестирования.
# Объединение данных #Data Partitioning: создать набор данных для поезда и тестирования (0,7: 0,3) index <- createDataPartition (data.df $ RAIN, p = 0.7, list = FALSE) # Обучающий набор train.df <- data.df [индекс,] # Тестирование набора данных test.df <- data.df [-index,]
Вы можете проверить сводку набора данных тестирования и обучения с помощью функции summary () в R:
> резюме (поезд.df) > сводка (test.df)
Шаг 6: Исследование данных
Этот этап включает в себя обнаружение закономерностей в данных и выяснение корреляций между переменными-предикторами и переменной ответа. В приведенном ниже фрагменте кода я использовал функцию cor.test (), предоставленную R.
Этот тест корреляции показывает значимость переменных-предикторов при построении модели. Кроме того, функция cor.test () требует наличия переменных числового типа, поэтому в приведенном ниже коде я отформатировал переменную «Rain» как числовую.
# Установка переменной дождя как числовой для вычисления корреляции train.df $ RAIN <- as.numeric (train.df $ RAIN) # Корреляция между переменной Rain и TMAX> cor.test (train.df $ TMAX, train.df $ RAIN) Корреляция продукта и момента Пирсона данные: train.df $ TMAX и train.df $ RAIN t = -55,492, df = 17882, значение p <2,2e-16 Альтернативная гипотеза: истинная корреляция не равна 0 95-процентный доверительный интервал: -0,3957173 -0,3707104 выборочные оценки: cor -0,3832841> # Корреляция между переменной 'Rain' и TMIN кор.тест (train.df $ TMIN, train.df $ RAIN) Корреляция продукта и момента Пирсона данные: train.df $ TMIN и train.df $ RAIN t = -18,163, df = 17882, значение p <2,2e-16 альтернативная гипотеза: истинная корреляция не равна 0 95-процентный доверительный интервал: -0,1489493 -0,1201678 примерные оценки: кор -0,1345869
Приведенные выше выходные данные показывают, что и TMIN, и TMAX являются важными переменными-предикторами. Обратите внимание на значение p для обеих переменных. Значение p или значение вероятности является наиболее важным параметром для понимания значимости модели.
Если p-значение переменной меньше 0,05, это считается важной характеристикой при прогнозировании результата. В нашем случае значение p для каждой из этих переменных намного ниже 0,05, что хорошо.
Прежде чем двигаться дальше, давайте снова преобразуем переменную «RAIN» в тип «factor»:
# Установка переменной дождя как фактора для построения модели train.df $ RAIN <- as.factor (train.df $ RAIN)
Шаг 7. Построение модели машинного обучения
После понимания корреляций пора построить модель.Мы будем использовать алгоритм логистической регрессии для построения модели. R предоставляет функцию glm (), которая содержит алгоритм логистической регрессии. Синтаксис функции glm ():
glm (формула, данные, семейство)
В приведенном выше синтаксисе:
- Формула: Формула представляет связь между зависимыми и независимыми переменными.
- Данные: набор данных, к которому применяется формула.
- Семейство: в этом поле указывается тип регрессионной модели.В нашем случае это бинарная модель логистической регрессии.
> # Построение модели логической регрессии > # GLM логистическая регрессия > модель <- glm (RAIN ~ TMAX + TMIN, data = train.df, family = binomial)> summary (model) Вызов: glm (формула = RAIN ~ TMAX + TMIN, family = binomial, data = train.df) Остаточные отклонения: Мин. 1 квартал Медиана 3 квартал Макс. -2,4700 -0,8119 -0,2557 0,8490 3,2691 Коэффициенты: Расчетная Станд. Ошибка z значение Pr (> | z |) (Перехват) 2,808373 0,098668 28,46 <2e-16 *** TMAX -0.250859 0,004121 -60,87 <2e-16 *** TMIN 0,259747 0,005036 51,57 <2e-16 *** --- Сигниф. коды: 0 & lsquo; *** & rsquo; 0,001 & lsquo; ** & rsquo; 0,01 & lsquo; * & rsquo; 0,05 & lsquo;. & Rsquo; 0,1 & lsquo; & rsquo; 1 (Параметр дисперсии для биномиального семейства принят равным 1) Нулевое отклонение: 24406 на 17883 степенях свободы Остаточное отклонение: 17905 по 17881 степени свободы АИК: 17911 Количество итераций подсчета очков Фишера: 5
Мы успешно построили модель с использованием переменных «TMAX» и «TMIN», поскольку они имеют сильную корреляцию с целевой переменной («Rain»).
Шаг 8: Оценка модели
На этом этапе мы собираемся проверить эффективность модели машинного обучения, используя набор данных тестирования.
#Model Evaluation
# Сохранение прогнозируемых значений
> predicted_values <- predicted (model, test.df, type = "response")> head (predicted_values)
2 4 5 8 9 18
0,7048729 0,5868884 0,4580049 0,4646309 0,1567753 0,8585068
# Создание таблицы, содержащей фактические значения RAIN в наборе тестовых данных
> таблица (test.df $ RAIN)
FALSE TRUE
4394 & nbsp; & nbsp; & nbsp; 3270
> nrows_prediction <-nrow (test.df) # Создание кадра данных, содержащего предсказанные значения 'Rain'> prediction <- data.frame (c (1: nrows_prediction))> colnames (prediction) <- c ("RAIN") > str (прогноз)
'data.frame': 7664 набл. из 1 переменной:
$ RAIN: int 1 2 3 4 5 6 7 8 9 10 ...
# Преобразование переменной 'Rain' в символ, который хранит либо (T / F)
прогноз $ RAIN <- as.character (прогноз $ RAIN)
# Установка порогового значения
прогноз $ RAIN <- "ИСТИНА"
прогноз $ RAIN [predicted_values <0.5] <- "ЛОЖЬ" # прогноз [предсказанные_значения> 0,5] <- "ИСТИНА"
прогноз $ RAIN <- as.factor (прогноз $ RAIN)
См. Комментарии к коду, он легко понятен.
# Сравнение прогнозируемых значений и фактических значений > таблица (прогноз $ RAIN, test.df $ RAIN) FALSE TRUE ЛОЖЬ & nbsp; & nbsp; 3460 & nbsp; & nbsp; 931 ИСТИНА & nbsp; & nbsp; & nbsp; & nbsp; 934 & nbsp; & nbsp; 2339
В приведенном ниже фрагменте кода мы используем матрицу путаницы для оценки точности модели.
# Матрица путаницы > confusionMatrix (прогноз $ RAIN, test.df $ RAIN) Матрица неточностей и статистика Справка Прогноз FALSE TRUE ЛОЖЬ 3460 931 ИСТИНА 934 2339 Точность: 0,7567 95% ДИ: (0,7469, 0,7662) Нет информации Скорость: 0,5733 Значение P [Acc> NIR]: <2e-16 Каппа: 0,5027 Значение P теста Макнемара: 0,9631 Чувствительность: 0,7874 Специфичность: 0,7153 Предполагаемое значение позиции: 0,7880 Отрицательное прогнозное значение: 0,7146 Распространенность: 0,5733 Скорость обнаружения: 0,4515 Распространенность обнаружения: 0,5729 Сбалансированная точность: 0.7514 "Положительный" класс: ЛОЖЬ
Согласно вышеприведенному выводу, модель может предсказать вероятность дождя с точностью примерно 76%, что является довольно хорошим показателем. Подводя итог, давайте построим график, показывающий кривую логистической регрессии, известную как сигмовидная кривая, между переменной-предиктором TMAX и целевой переменной RAIN.
# Выходной график, показывающий разницу между TMAX и Rainfall ggplot (test.df, aes (x = test.df $ TMAX, y = predicted_values)) + geom_point () + # добавить точки geom_smooth (method = "glm", # построить регрессию... method.args = list (family = "binomial"))
ggplot - Введение в машинное обучение - Edureka
Теперь, когда вы знакомы с основами машинного обучения, я уверен, что вам интересно узнать больше о различных алгоритмах машинного обучения. Вот список блогов, в которых подробно рассматриваются различные типы алгоритмов машинного обучения:
Итак, на этом мы подошли к концу блога «Введение в машинное обучение». Я надеюсь, что вы все нашли этот блог информативным.Если у вас есть какие-либо мысли, прокомментируйте их ниже. Следите за новостями, чтобы увидеть больше подобных блогов!
Если вы ищете структурированное онлайн-обучение по Data Science, edureka! имеет специально подобранный курс Data Science, который поможет вам получить опыт в области статистики, обработки данных, исследовательского анализа данных, алгоритмов машинного обучения, таких как кластеризация K-средних, деревья решений, случайный лес, наивный байесовский анализ. Вы изучите концепции временных рядов, интеллектуального анализа текста, а также познакомитесь с глубоким обучением.Новые партии для этого курса скоро начнутся !!
7 отличных книг о машинном обучении для начинающих
Машинное обучение и искусственный интеллект - растущие области и постоянно растущие темы изучения. Хотя продвинутые реализации машинного обучения, о которых мы слышим в новостях, могут показаться пугающими и недоступными, основные концепции на самом деле довольно легко понять. В этой статье мы рассмотрим некоторые из самых популярных ресурсов для новичков в области машинного обучения (или всех, кому просто интересно узнать).Некоторые из этих книг потребуют знания некоторых языков программирования и математики, но мы обязательно упомянем об этом, когда это произойдет.
Автор: Оливер Теобальд
Веб-сайт: Amazon
Название носит пояснительный характер, не так ли? Если вам нужно полное введение в машинное обучение для начинающих, это может быть хорошим началом. Когда Теобальд говорит «абсолютные новички», он абсолютно уверен в этом. Не требуется ни математического образования, ни опыта программирования - это самое базовое введение в тему для всех, кто интересуется машинным обучением.
Здесь очень ценится «простой» язык, чтобы новички не были перегружены техническим жаргоном. Четкие, доступные объяснения и наглядные примеры сопровождают различные алгоритмы, чтобы упростить выполнение действий. Также предлагается простое программирование, чтобы поместить машинное обучение в контекст.
Авторы: Джон Пол Мюллер и Лука Массарон
Веб-сайт: Amazon
Пока мы собираемся «абсолютные новички», популярная серия «Чайников» - еще одна полезная отправная точка.Эта книга призвана познакомить читателей с основными концепциями и теориями машинного обучения и их применением в реальном мире. В нем представлены языки программирования и инструменты, являющиеся неотъемлемой частью машинного обучения, и показано, как превратить, казалось бы, эзотерическое машинное обучение в нечто практическое.
Книга вводит небольшое кодирование на Python и R, используемое для обучения машин поиску закономерностей и анализу результатов. На основе этих небольших задач и шаблонов мы можем экстраполировать, насколько машинное обучение полезно в повседневной жизни, с помощью веб-поиска, интернет-рекламы, фильтров электронной почты, обнаружения мошенничества и т. Д.С помощью этой книги вы сможете сделать небольшой шаг в сферу машинного обучения.
Авторы: Джон Д. Келлехер, Брайан Мак Нейм и Аойф Д'Арси
Веб-сайт: Amazon
Эта книга охватывает все основы машинного обучения, углубляясь в теорию предмета и используя практические приложения, рабочие примеры и тематические исследования для распространения знаний. «Основы» лучше всего читают люди с некоторыми знаниями в области аналитики.
В нем представлены различные подходы к обучению с помощью машинного обучения и каждая концепция обучения сопровождается алгоритмами и моделями, а также рабочими примерами, демонстрирующими концепции на практике.
Автор: Тоби Сегаран
Веб-сайт: О'Рейли | Amazon
Это скорее практическое руководство по внедрению машинного обучения, а не введение в машинное обучение. Из этой книги вы узнаете, как создавать алгоритмы машинного обучения для сбора данных, полезных для конкретных проектов. Он учит читателей, как создавать программы для доступа к данным с веб-сайтов, сбора данных из приложений и выяснения значения этих данных после того, как вы их собрали.
«Программирование коллективного разума» также демонстрирует методы фильтрации, методы обнаружения групп или шаблонов, алгоритмы поисковых систем, способы прогнозирования и многое другое. Каждая глава включает упражнения для отображения уроков в приложении.
Авторы: Дрю Конвей и Джон Майлз Уайт
Веб-сайт: O’Reilly | Amazon
Здесь слово «хакеры» используется в более техническом смысле: программисты, которые собирают код для конкретных целей и практических проектов.Для тех, кто плохо разбирается в математике, но имеет опыт работы с языками программирования и кодирования, подойдет «Машинное обучение для хакеров». Машинное обучение обычно основано на большом количестве математических операций из-за алгоритмов, необходимых для его синтаксического анализа. данных, но многие опытные программисты не всегда развивают эти математические навыки.
В книге используются практические тематические исследования, чтобы представить материал в реальных практических приложениях, а не углубляться в математическую теорию. В нем представлены типичные проблемы машинного обучения и способы их решения с помощью языка программирования R.Приложения для машинного обучения бесконечны: от сравнения сенаторов США на основе их голосований до создания системы рекомендаций для подписчиков в Твиттере и обнаружения спам-писем на основе текста электронного письма.
Автор: Питер Харрингтон
Веб-сайт: Amazon
«Машинное обучение в действии» - это руководство, которое знакомит новичков с методами, необходимыми для машинного обучения, а также с концепциями, лежащими в основе этих практик. Он действует как учебное пособие, чтобы научить разработчиков программировать свои собственные программы для сбора данных для анализа.
Из этой книги вы познакомитесь с методами, используемыми на практике, с уделением особого внимания самим алгоритмам. Фрагменты кода языка программирования содержат примеры кода и алгоритмов, которые помогут вам начать работу и увидеть, как они развивают машинное обучение. Знакомство с языком программирования Python полезно, поскольку он используется в большинстве примеров.
Авторы: Ян Х. Виттен, Эйбе Франк и Марк А. Холл
Веб-сайт: Amazon
В статье «Интеллектуальный анализ данных» авторы сосредотачиваются на технической работе в области машинного обучения и на том, как собрать необходимые данные с помощью определенных методов интеллектуального анализа данных.Они рассматривают технические детали машинного обучения, обучение методам получения данных, а также то, как использовать различные входные и выходные данные для оценки результатов.
Поскольку машинное обучение постоянно меняется, в книге также обсуждаются вопросы модернизации и нового программного обеспечения, которые формируют эту сферу.